零散
- 如何找main
- 导航栏
- 灰条:数据
- 蓝色:代码
- 反汇编
- arg:参数
- var:局部变量
- general->IDA options
- line prefixes:显示十六进制地址
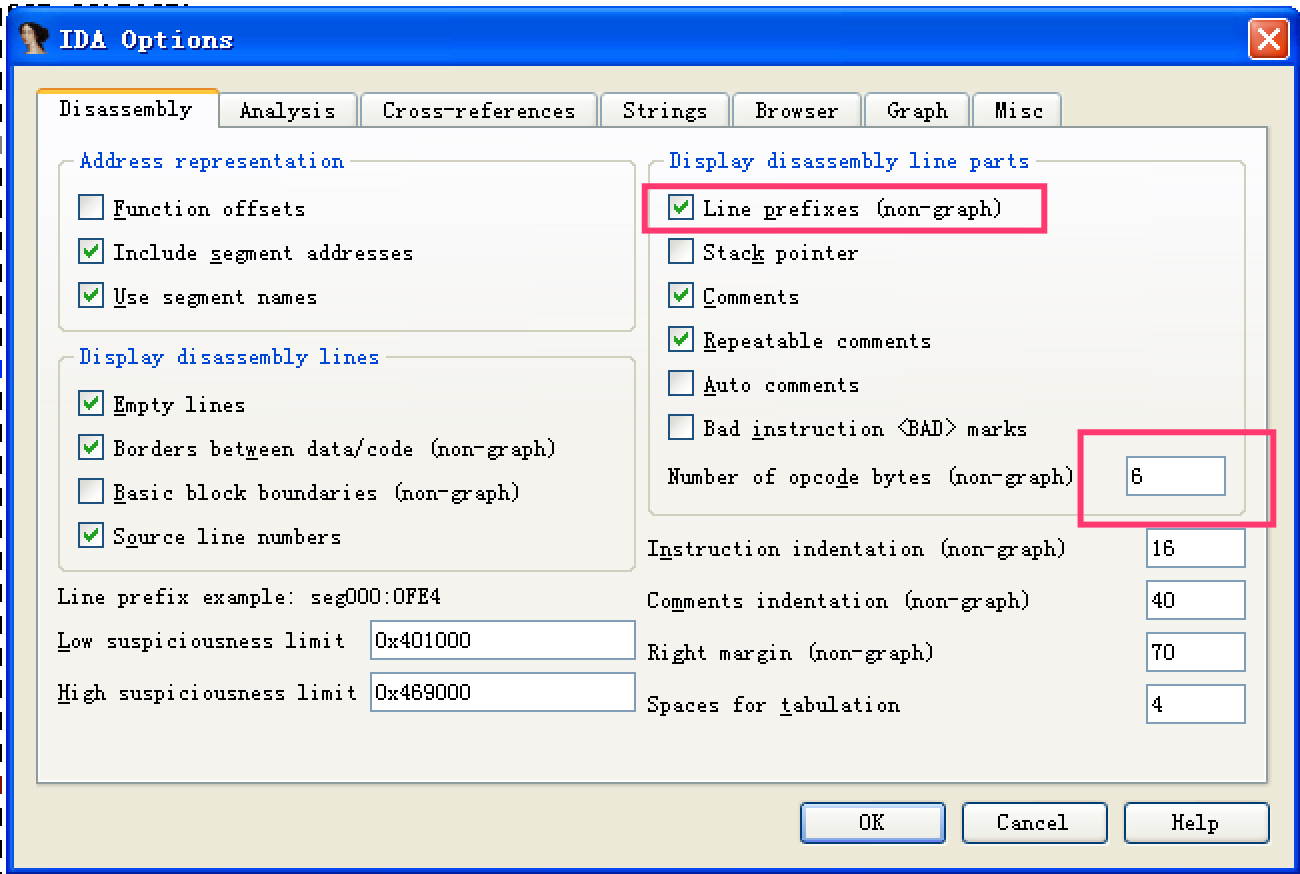
- Auto comments:显示汇编指令含义
- 交叉引用
- 双击上箭头可以跳到交叉引用的位置(x)

快捷键
| 快捷键 | 功能 | |
|---|---|---|
| C | 转换为代码 | 一般在IDA无法识别代码时使用这两个功能整理代码(代码混淆) |
| D | 转换为数据 | |
| A | 转换为字符 | |
| N | 为标签重命名 | 方便记忆,避免重复分析。 |
| ; | 添加注释 | |
| R | 把立即值转换为字符 | 便于分析立即值 |
| H | 把立即值转换为10进制 | |
| Q | 把立即值转换为16进制 | |
| B | 把立即值转换为2进制 | |
| G | 跳转到指定地址 | |
| X | 交叉参考 | 便于查找API或变量的引用 |
| SHIFT+/ | 计算器 | |
| ALT+ENTER | 新建窗口并跳转到选中地址 | 这四个功能都是方便在不同函数之间分析(尤其是多层次的调用)。具体使用看个人喜好 |
| ALT+F3 | 关闭当前分析窗口 | |
| ESC | 返回前一个保存位置 | |
| CTRL+ENTER | 返回后一个保存位置 | |
| Alt+b | 查找 | |
| F5 | 汇编->源码 | |
| shift + F12 | 打开string窗口 | |
| Alt+6(option+6) | 导入表 |
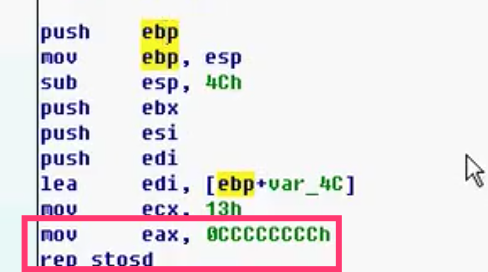
- mov eax,0ccccccch以上的汇编可以忽略分析(debug版本中编译器加上的)
rep stosd:区域填充,给edi的地址填充eax的值,填充次数由ecx决定(数组初始化)
- mov [edi],eax;edi=edi+4;
- 填充方向由方向标志 DF 来决定,可以由指令 cld 和 std 指令设置
cld: 从低地址往高地址传送 std: 从高地址往低地址传送
mov [ebp+edx*4],ecx
- edx是数组下标,一个项占4个字节(32位)
初始化时未使用的变量先不管
- 流程图中折叠分支
- 右键 -> group nodes
IDC脚本(去混淆、解密)
- file->script command
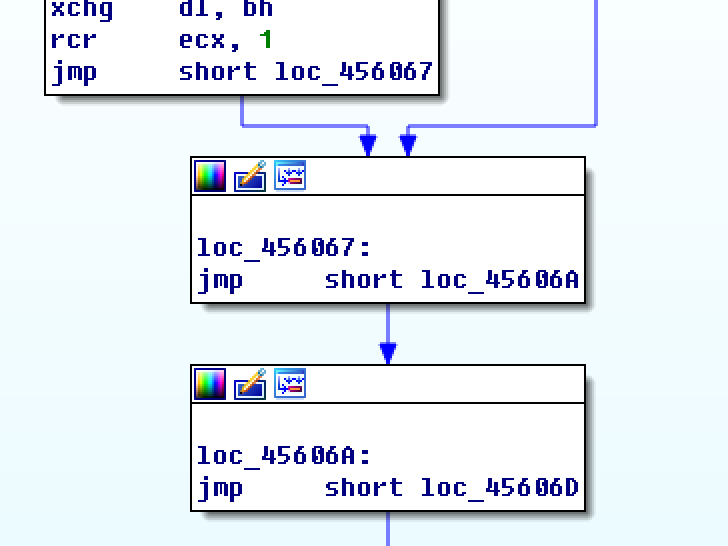
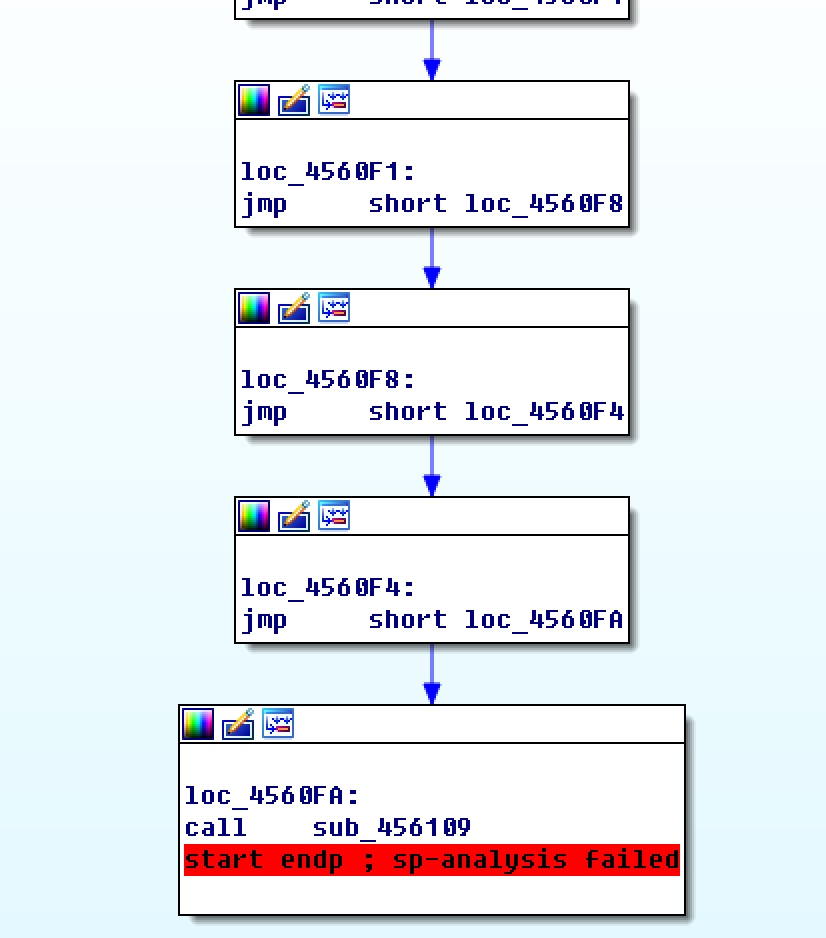
- 动态或静态方法找到与开头pusha对应的popa,发现有花指令,干扰定位,因此无法直接根据popa找OEP
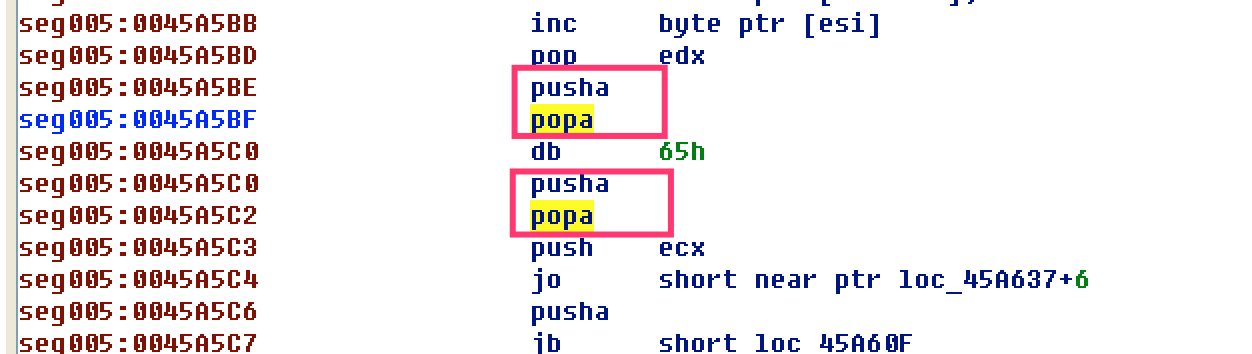
- 修改代码,使IDA在loc_4560FA能继续往下分析
- 红颜色箭头:代码分析有冲突

- 按d,将分析不正确的地方先转为数据
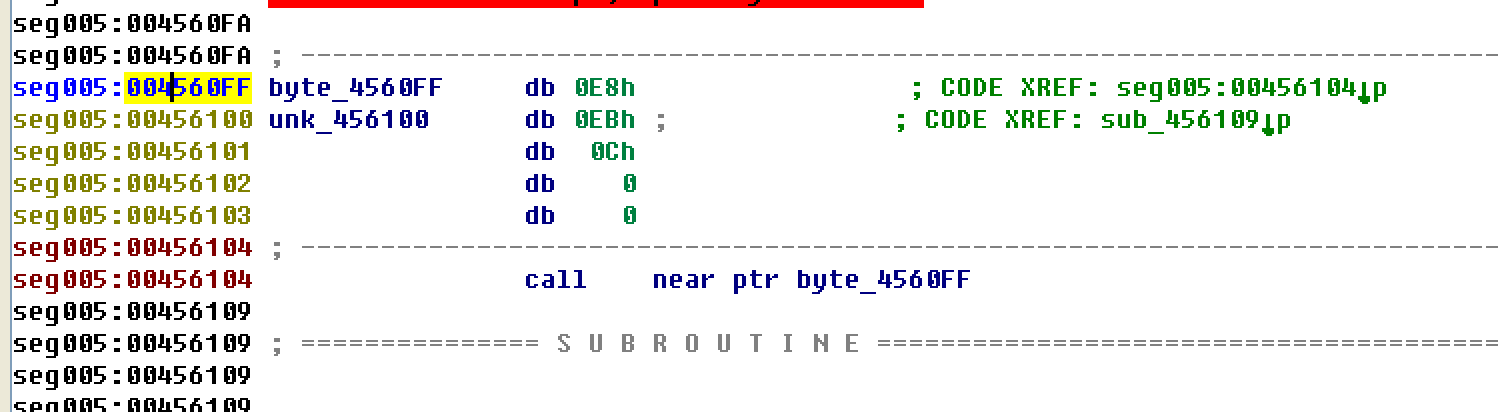
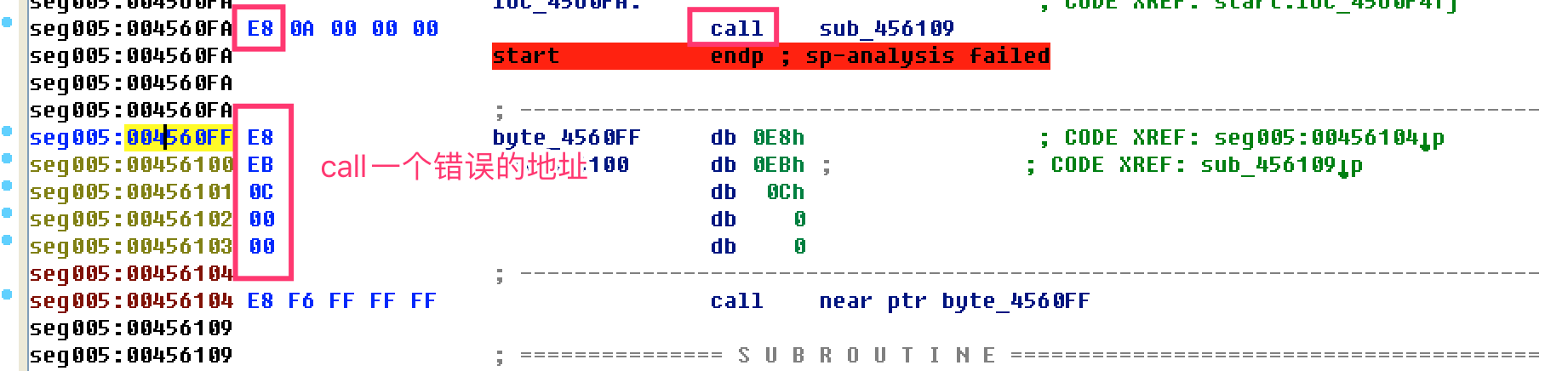
- 再将合理的机器码按c转成代码。
- pushad popad
- jz jnz(后面的jmp一般是花指令)

- call jmp(E8 EB)
- jmp跳转到一个未分析的地址or一个错误的地址(转成d后,在跳转的位置c)

- 有红色标记
- sun eax,[esp-8+arg_4] == sub eax,[esp]
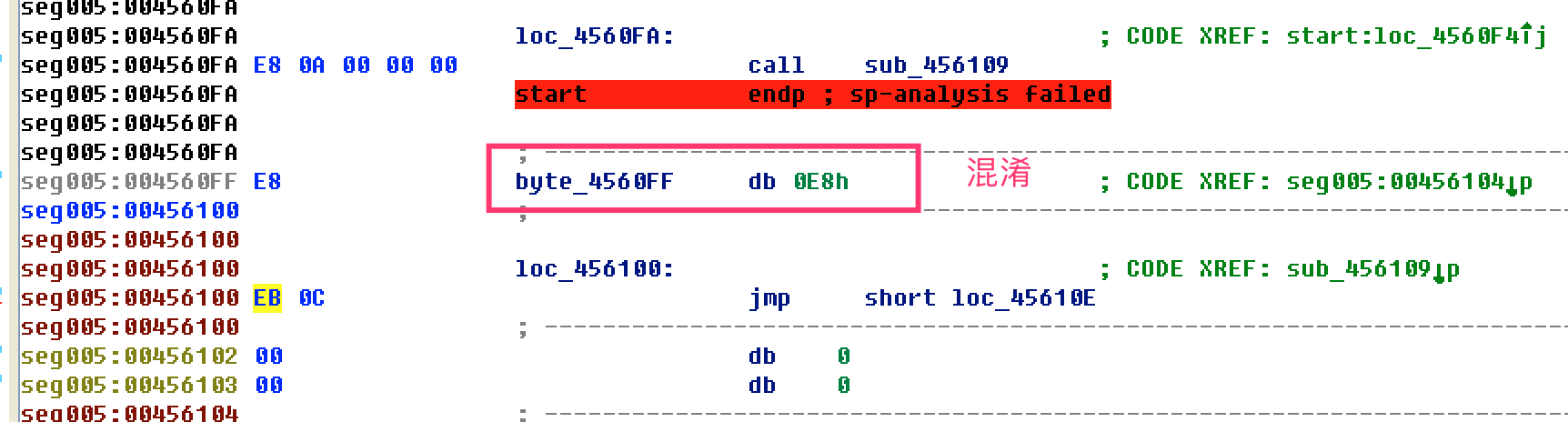
- 继续向下修改混淆(花指令)的地方,发现有重复的模式

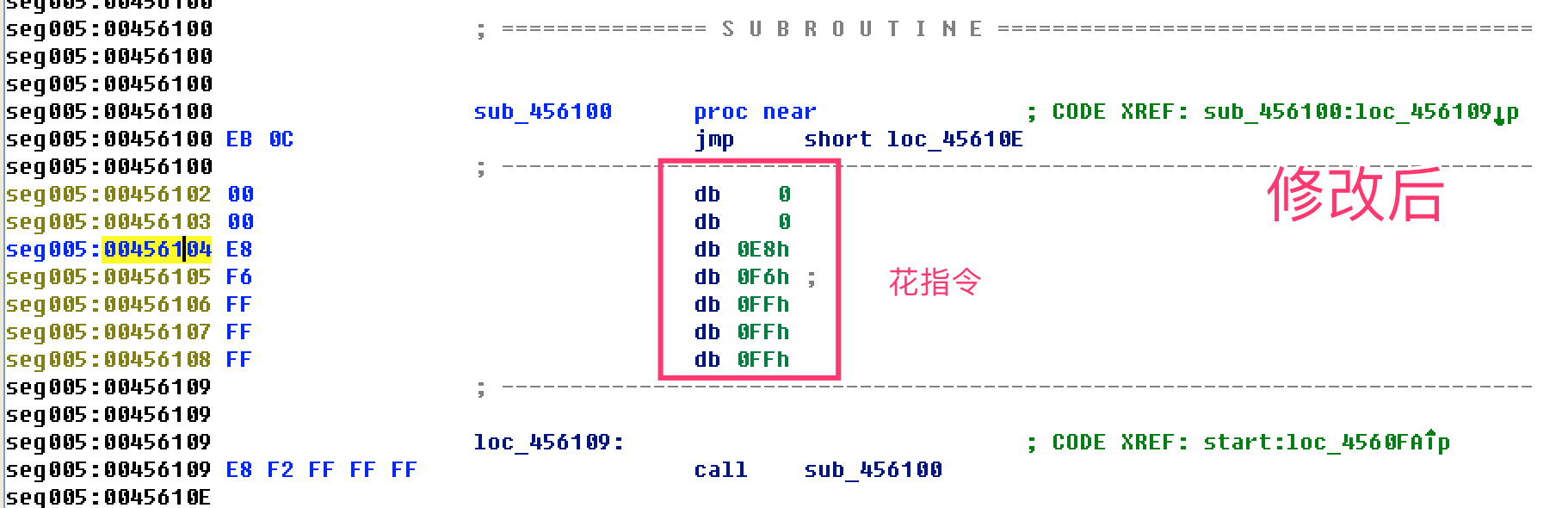
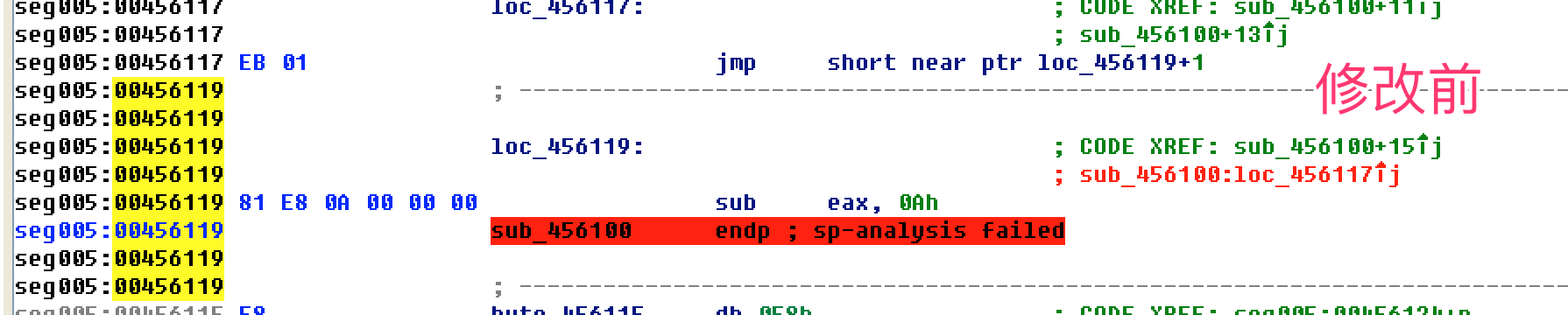
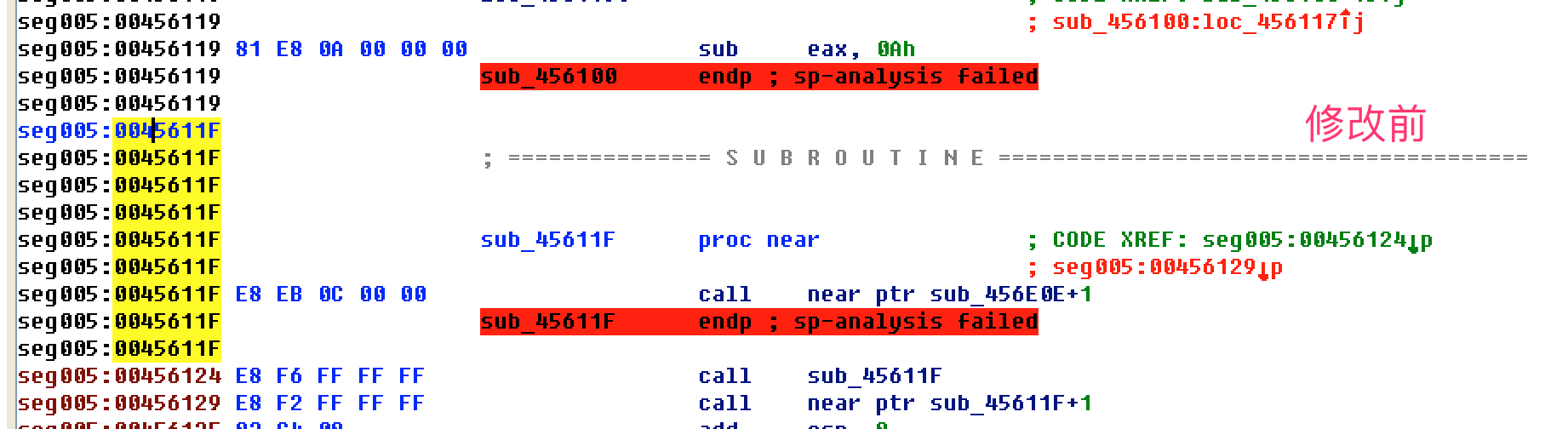


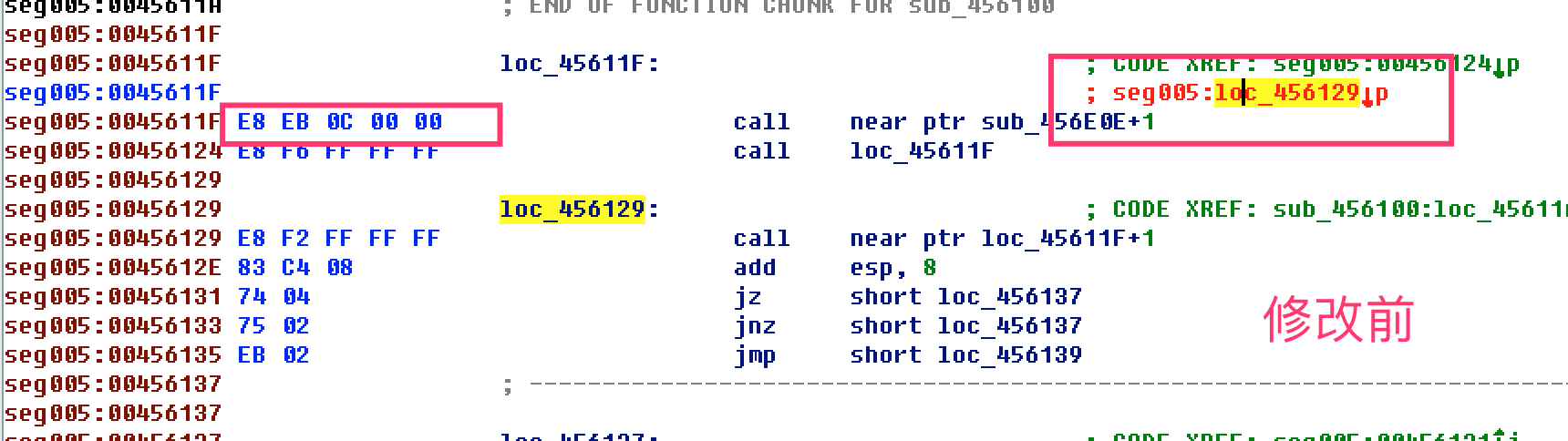
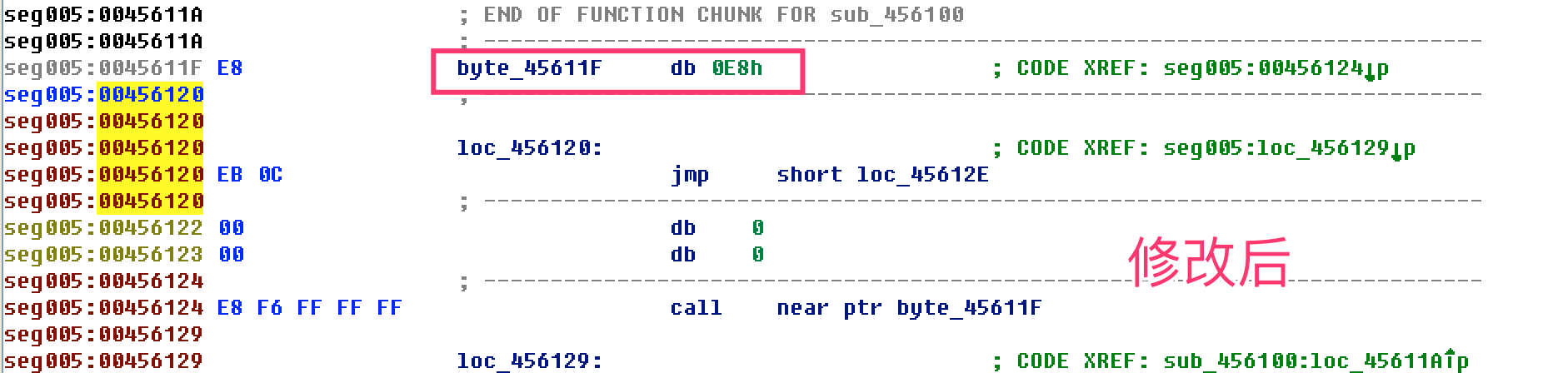
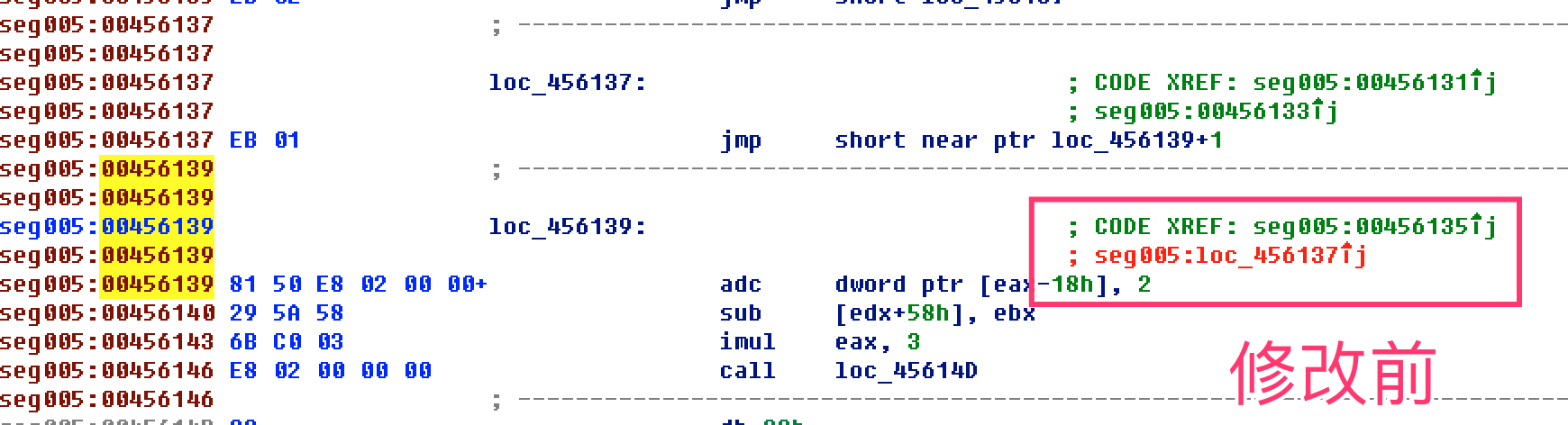

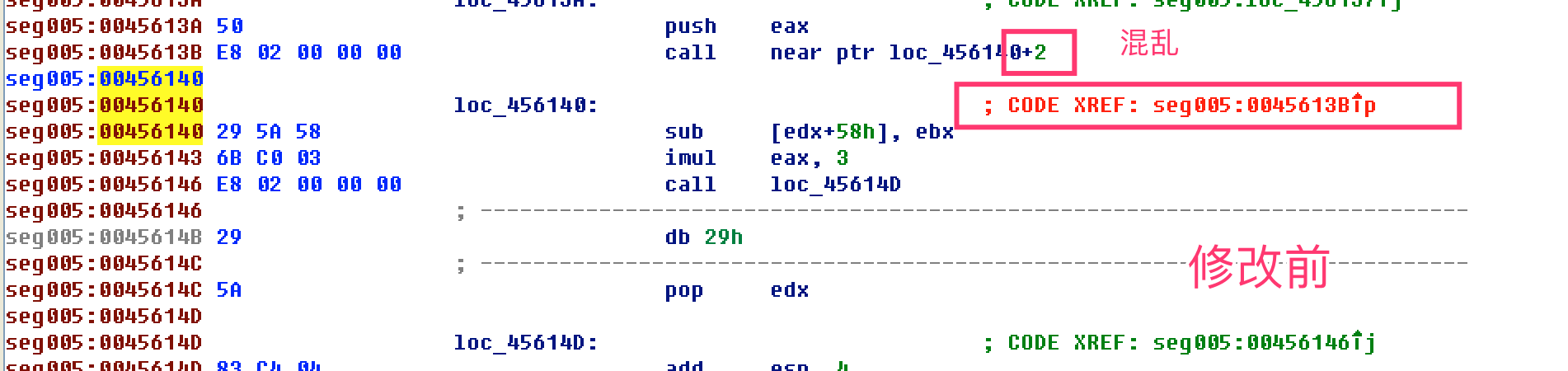

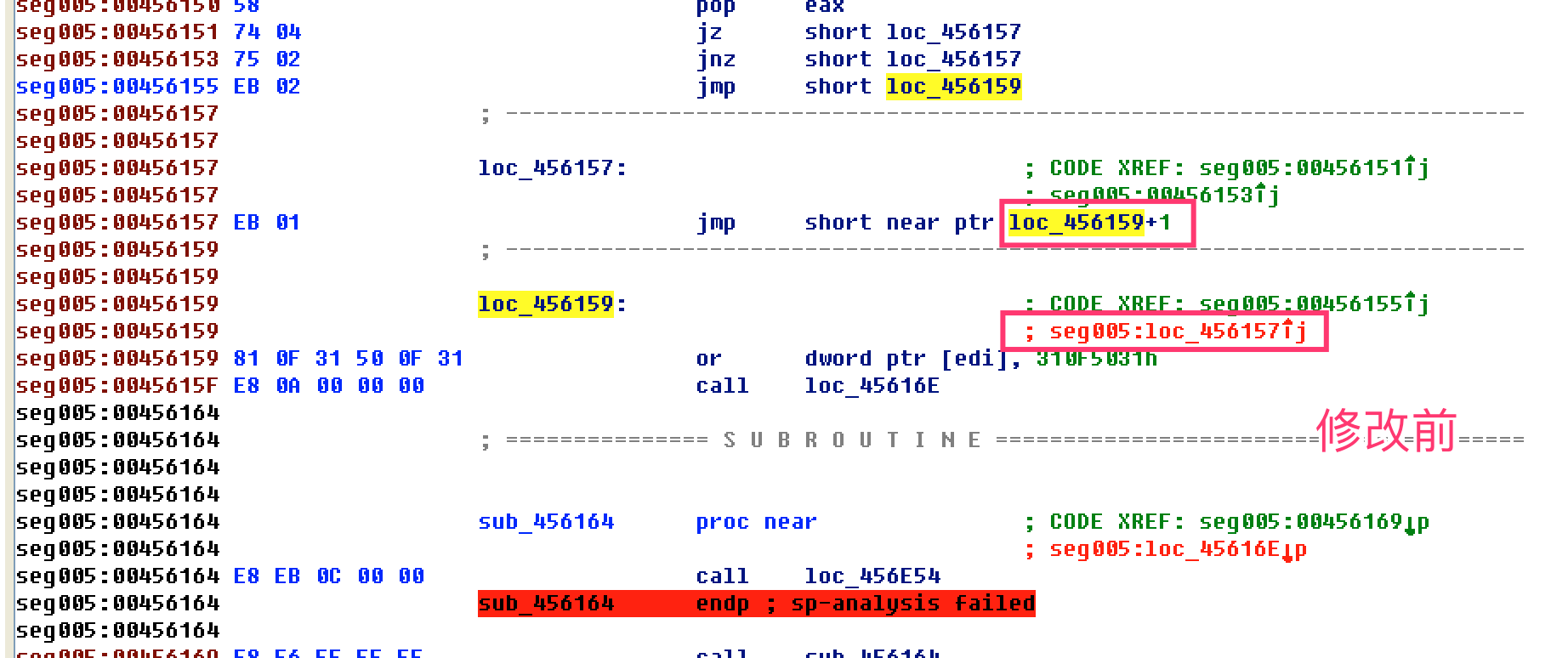

整理修改后的代码逻辑,把花指令直接nop掉(打补丁)
- FindBinary:从给定的地址(arg1,一般是0x3)按指定的方式(arg2)搜索一个数据项(arg3)
- arg2:
- SEARCH_UP,SEARCH_DOWN 用来指明搜索方向
- SEARCH_NEXT 用来获取下一个已经找到的对象
- SEARCH_CASE用来指明是否区分大小写
- SEARCH_NOSHOW 用来指明是否显示搜索的进度
- SEARCH_UNICODE用于将所有搜索字符串视为Unicode
- arg2:
- MinEA()获取可执行文件的最开始的地址
- PatchByte:打一个字节的补丁
- PatchWord:打一个字的补丁
- PatchDword:打一个双字的补丁
BADADDR
static PatchJunkCode(){auto x,FBin,ProcRange;FBin = "E8 0A 00 00 00 E8 EB 0C 00 00 E8 F6 FF FF FF";//无用代码的机器码(无用的call)for(x=FindBinary(MinEA(),0x03,FBin);x!=BADADDR;x=FindBinary(x,0x03,FBin)){x=x+5;//nop E8PatchByte(x,0x90);x+=3;PatchByte(x,0x90);x++;PatchWord(x,0x9090);x+=2;PatchDword(x,0x90909090);}FBin2 = "74 04 75 02 EB 02 EB 01 81";//jnz jzfor(x=FindBinary(MinEA(),0x03,FBin);x!=BADADDR;x=FindBinary(x,0x03,FBin)){}FBin3 = "50 E8 02 00 00 00 29 5A 58 6B C0 03 E8 02 00 00 00 29 5A 83 C4 04"//jmp->call->jmp->call...for(x=FindBinary(MinEA(),0x03,FBin);x!=BADADDR;x=FindBinary(x,0x03,FBin)){}FBin4 = "EB 01 68 EB 02 CD 20 EB 01 E8";//连环jmpfor(x=FindBinary(MinEA(),0x03,FBin);x!=BADADDR;x=FindBinary(x,0x03,FBin)){}}
- FindBinary:从给定的地址(arg1,一般是0x3)按指定的方式(arg2)搜索一个数据项(arg3)
把nop隐藏掉(方便查看其他代码)
- HideArea:隐藏一个区域
- MakeString:转换成字符串
- MakeCode:转换成代码
- MakeUnknow:转换成未知类型(IDA7.0:ida_bytes.del_items)
- arg1:起始地址
- arg2:长度
- HideArea
- arg1:起始
- arg2:结束
- arg3:折叠起来唯一出现的
- arg4:header(展开)
- arg5:footer(展开)
- arg6:color(-1: 默认)
- atoa:Convert address value to a string
static HideJunkCode{auto x,y,FBin;FBin = "E8 0A 00 00 00 E8 EB 0C 00 00 E8 F6 FF FF FF";for(x=FindBinary(MinEA(),0x03,FBin);x!=BADADDR;x=FindBinary(x,0x03,FBin)){//x:起始地址MakeUnknow(x,0x0F,1);//y:结束地址y=x+0x0F;HideArea(x,y,atoa(x),atoa(x),atoa(y),-1);}。。。}
由于花指令的关系,会使IDA错误识别指令,可能隐藏区域的边界刚好在一条指令的机械码中间,这样隐藏的操作便会失败。因此在隐藏指令执行之前,先使用MakeUnknown将目标代码设置为未识别的状态。在完成隐藏和替换之后,再使用分析引擎分析代码。
- AnalyzeArea (IDA7:idc.plan_and_wait)
- Perform full analysis of the range
#include<idc.idc>static main{HideJunkCode();PatchJunkCode();AnalyzeArea(MinEA(),MaxEA());}
- Perform full analysis of the range
- AnalyzeArea (IDA7:idc.plan_and_wait)
SEH
- SEH是window操作系统默认的异常处理机制,逆向分析中,SEH除了基本的异常处理功能外,还大量用于反调试程序
- SEH的反调试原理
- 利用异常处理例程来进行反调试
- 首先安装好一个异常处理例程,然后故意制造一个异常
- 未处理异常用于反跟踪
- UnhandledExceptionFilter在没有debugger attach的时候才会被调用。所以,SetUnhandledExceptionFilter函数还有一个妙用,就是让某些敏感代码避开debugger的追踪。比如你想把一些代码保护起来,避免调试器的追踪,可以采用的方法:
- 常规反调试
- 把代码放到SetUnhandledExceptionFilter设定的函数里面。通过人为触发一个unhandled exception来执行。由于设定的UnhandledExceptionFilter函数只有在调试器没有加载的时
候才会被系统调用,这里巧妙地使用了系统的这个功能来保护代码(UnhandledExceptionFilter是否调用取决于系统内核的判断)
- UnhandledExceptionFilter在没有debugger attach的时候才会被调用。所以,SetUnhandledExceptionFilter函数还有一个妙用,就是让某些敏感代码避开debugger的追踪。比如你想把一些代码保护起来,避免调试器的追踪,可以采用的方法:
- 利用异常处理例程来进行反调试
- cli:关中断
- 关中断后可以任意处理程序4GB空间
- 可以导致调试器异常
- trap to debugger
硬件断点的检查
- 假如没有设置硬件断点,那么ECX的结果应该是0。
seg005:004587B6 mov eax, [esp+0Ch]seg005:004587BA xor ecx, ecxseg005:004587BC xor ecx, [eax+4]seg005:004587BF xor ecx, [eax+8]seg005:004587C2 xor ecx, [eax+0Ch]seg005:004587C5 xor ecx, [eax+10h]
循环
- while:蓝颜色
- do…while:绿颜色
- 执行路径:红色
反汇编片段
1)编译器添加
2)两个数组赋值(找准基地值和下标)

3)0FFFFFFFFh = -1
4)数组初始化(顺序!!)
- char:一个字节(也可以定义为BYTE)

char s[]={0x2,0x3,0x4,0x5,0x4,0x2,0x1,0x2,0x3,0x2C,0x1B};
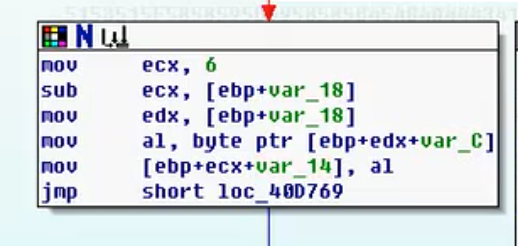
5)数组循环比较
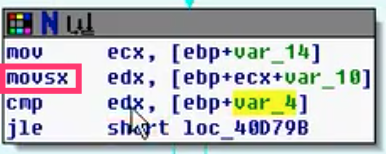
- movsx(数组内每个值赋值)
6))函数调用与清理

7)使用BYTE变量
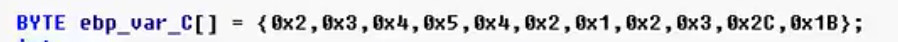
8)数组取值
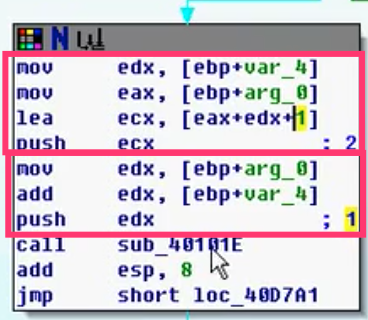
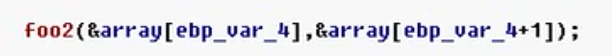
9)交换
(ebp_var_4)=(ebp_arg_0)
(ebp_arg_0)=(ebp_arg_4)
(ebp_arg_4)=(ebp_var_4)
10)双层循环
11)创建结构体
- dd:双字 dw:字
- 特点:连续赋值中几字节的都有,注意观察后续字符串等,可能会提示结构体里有什么
- 在structure页插入结构体后(i),光标在ends上,点击d插入值,然后在外部这个值上按ALT+Q来修改结构
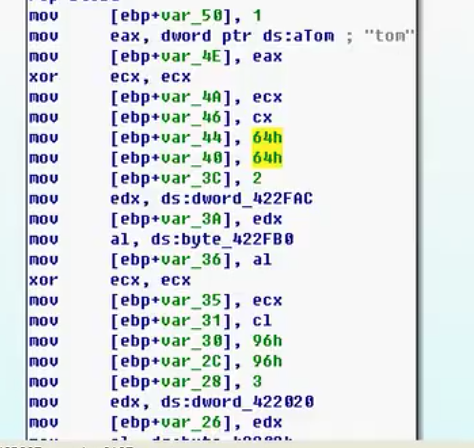
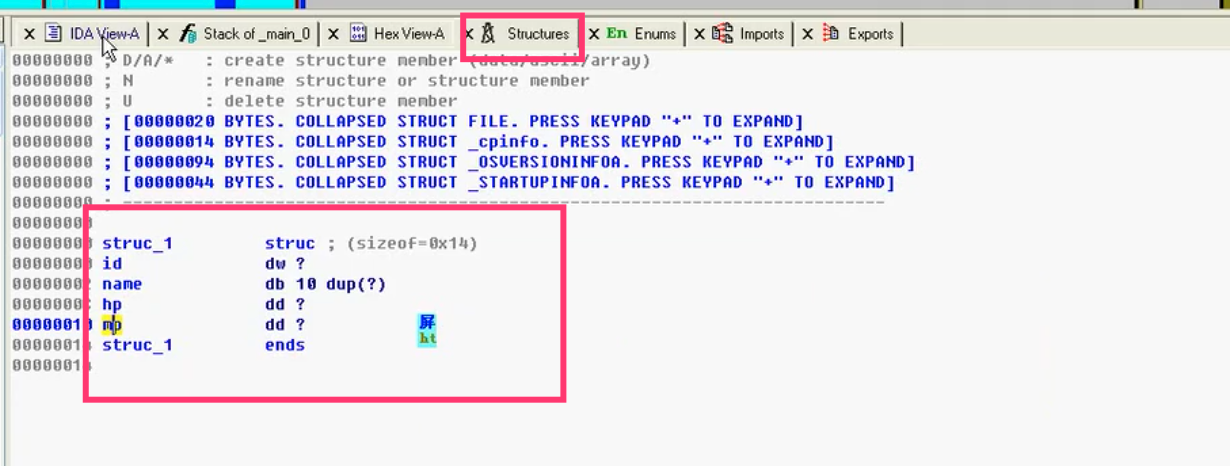
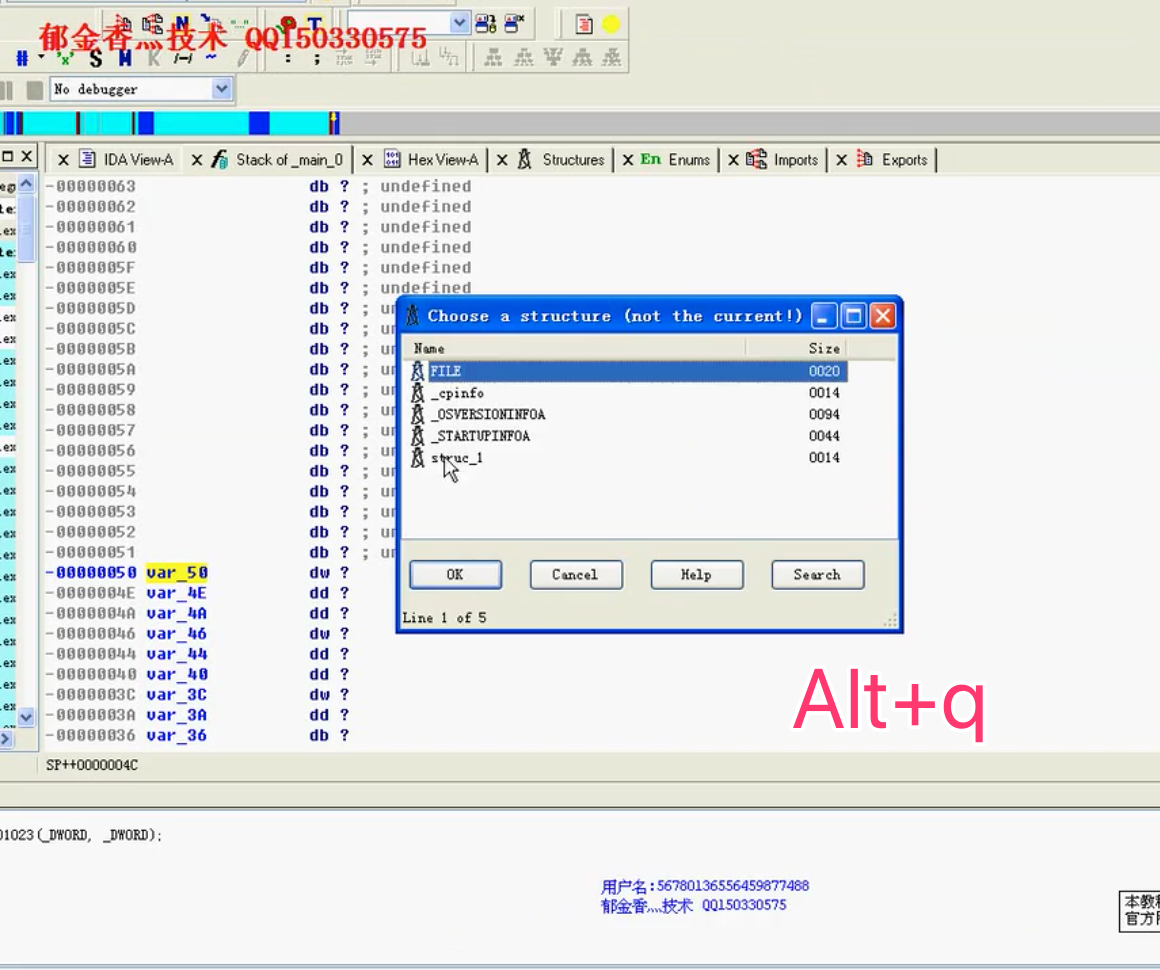

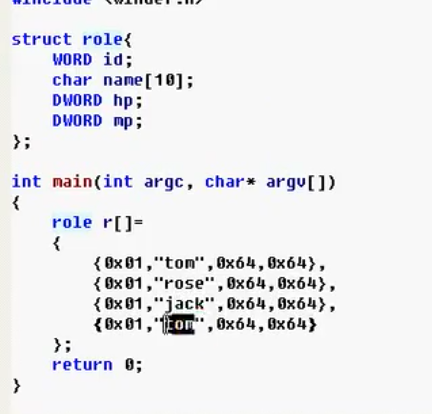
- r[]内元素个数:sizeof(r)/sizeof(role)
- 结构体的遍历(每个结构体元素20个字节 :020 120…):
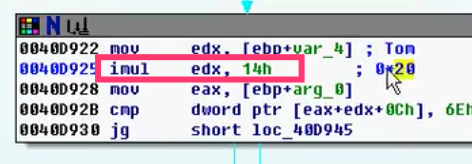
导入C声明的结构体
点击选中你想要转换成数组的一块区域
- 在菜单栏中选择:edit—>array

IDAPython
- 三个python模块
- idaapi:访问核心IDA API
- idc:提供IDA中所有函数功能
- idautils:提供实用函数
- 实例
```cpp
导入包
import idaapi import idc import idautils
获取函数的引用
for addr in XrefsTo(0x00405BF0, flags=0): print hex(addr.frm)
前一句&后一句指令的地址
idc.PrevHead(addr) idc.NextHead(addr)
获得操作码
GetMnem(addr)
获得操作数
GetOpnd(addr, 0)
GetOperandValue(addr, 1)
添加注释
MakeComm(x.frm, dec)
获取pe导出表函数名
pe = pefile.PE(dll_path)
for exp in pe.DIRECTORY_ENTRY_EXPORT.symbols:
if exp.name:
expname.append(exp.name)
找到程序 _start (针对 ELF 而言)
ea = BeginEA()
在.text段中 SegStart() 找到程序地址最小的汇编指令的地址,SegEnd() 找到程序地址最大的汇编指令的地址
for funcea in Functions(SegStart(ea), SegEnd(ea)):
获得函数名
functionName = GetFunctionName(funcea)
```
keypatch
- 打补丁
IDA常见命名意义
- sub 指令和子函数起点
- locret 返回指令
- loc 指令
- off 数据,包含偏移量
- seg 数据,包含段地址值
- asc 数据,ASCII字符串
- byte 数据,字节(或字节数组)
- word 数据,16位数据(或字数组)
- dword 数据,32位数据(或双字数组)
- qword 数据,64位数据(或4字数组)
- flt 浮点数据,32位(或浮点数组)
- dbl 浮点数,64位(或双精度数组)
- tbyte 浮点数,80位(或扩展精度浮点数)
- stru 结构体(或结构体数组)
- algn 对齐指示
- unk 未处理字节
- IDA中有常见的说明符号,如db、dw、dd分别代表了1个字节、2个字节、4个字节
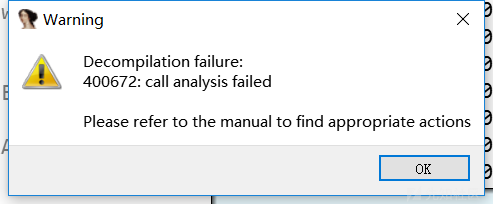
IDA反编译报错(非花的情况)
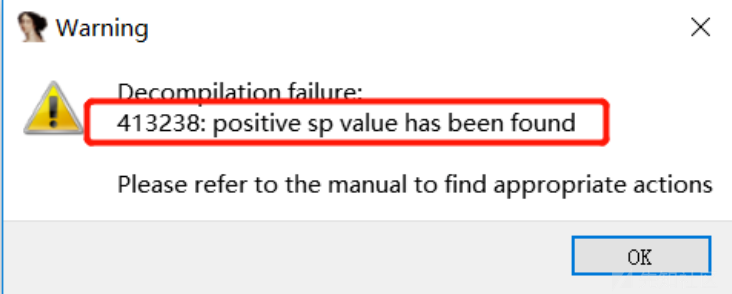
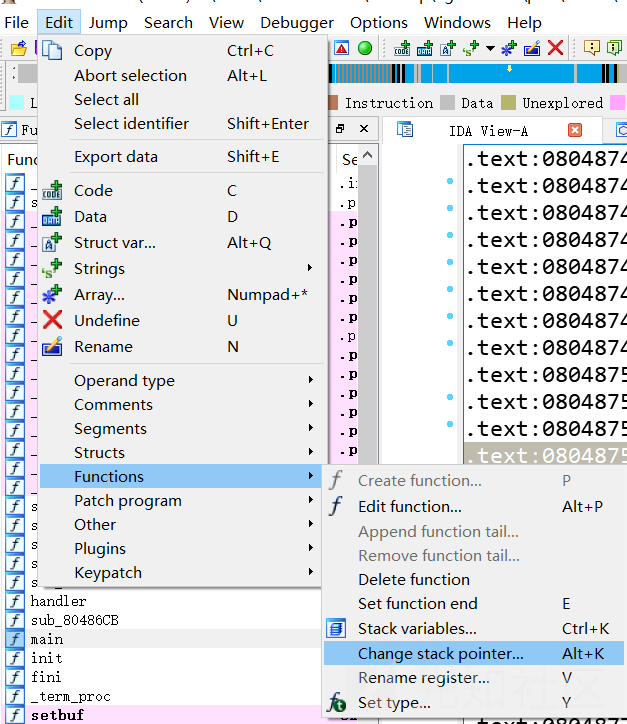
修改报错的地方的汇编语句(改成nop)

若有收获,就点个赞吧
0 人点赞
