- 一、Windows Mysql安装
- 二、环境变量配置
- 三、卸载
- 四、启动
- 五、命令行登录
- 六、 MySql的目录结构
- 七、SQL
- 创建学生表
CREATE TABLE student(
sid INT,
sname VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
); - 查询emp表中的前 5条数据
— 参数1 起始值,默认是0 , 参数2 要查询的条数
SELECT FROM emp LIMIT 5;
SELECT FROM emp LIMIT 0 , 5;
# 查询emp表中 从第4条开始,查询6条
— 起始值默认是从0开始的.
SELECT * FROM emp LIMIT 3 , 6;
软件:
mysql-installer-community-5.7.28.0.msi
SQLyog-12.5.0-0_setup.exe
一、Windows Mysql安装
双击安装包文件 进行安装
同意Mysql协议 , 选择 Server Only安装Mysql服务器即可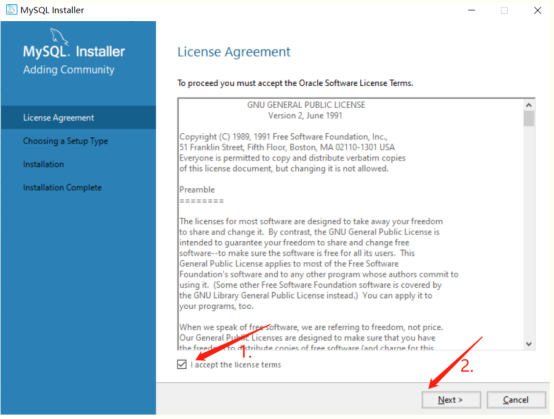
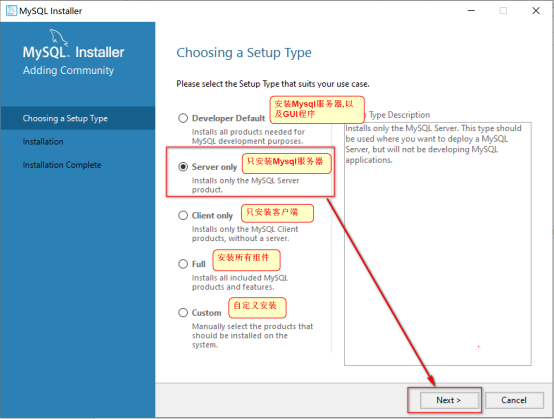
检查,如果提示需要安装一个软件 visual studio ,我们选择安装一下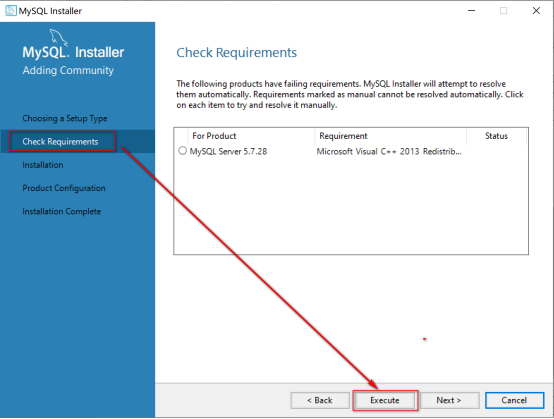
选中同意, Install 安装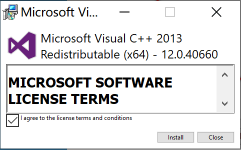
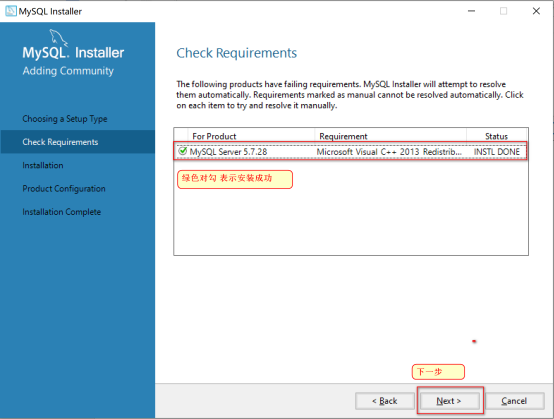
Execut执行安装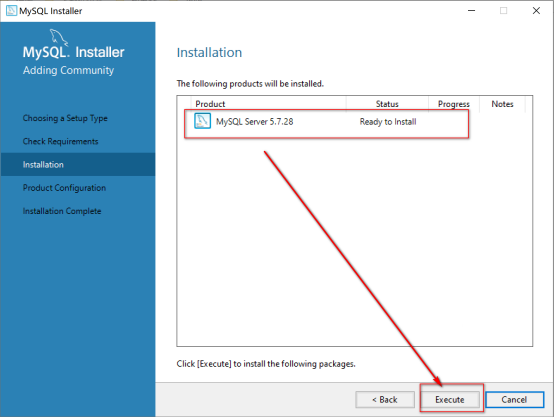
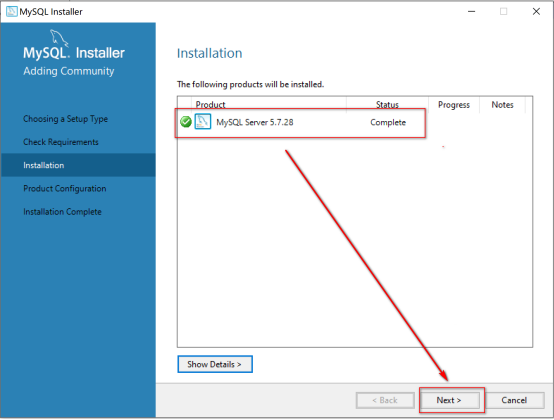
产品配置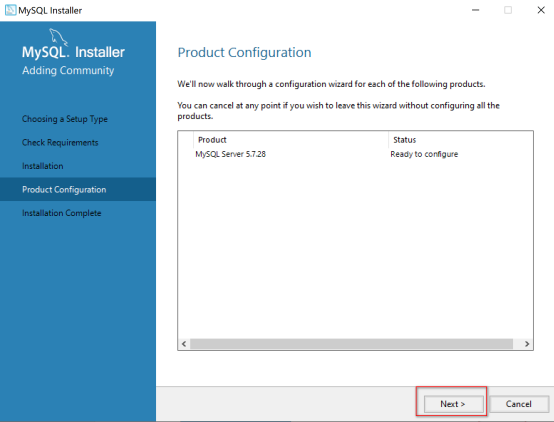
选单机版配置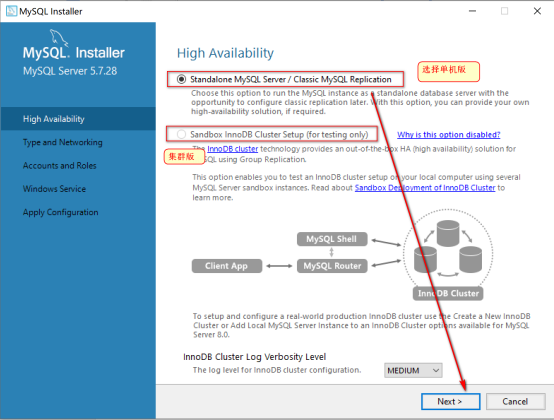
不用改动, 选择下一步即可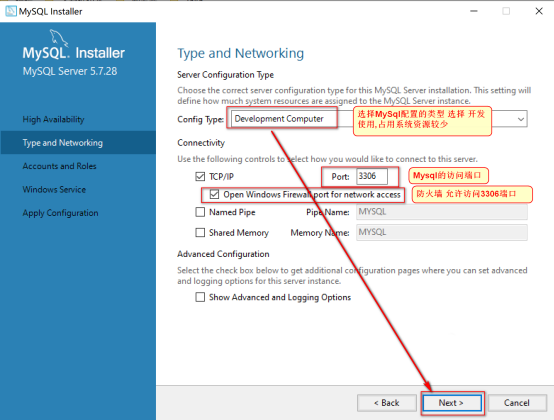
为root用户 添加密码 确认密码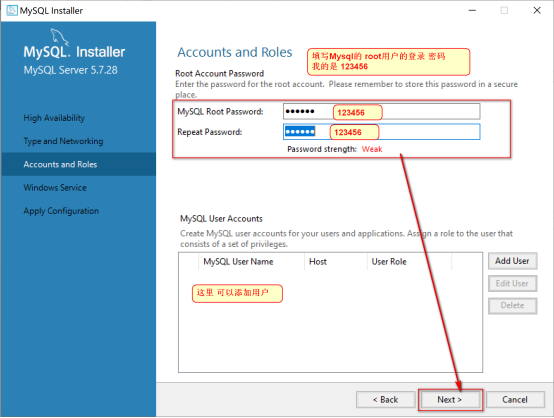
将Mysql添加到服务, 不需要更改,下一步即可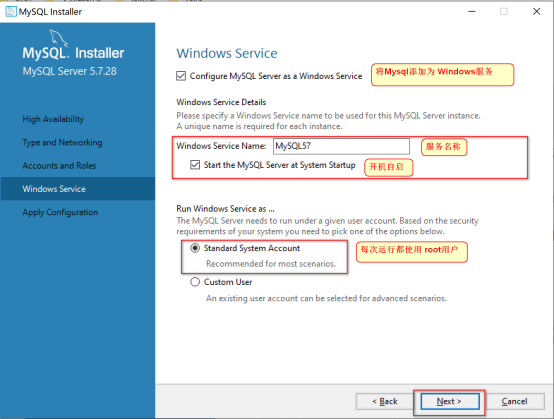
Execute, 进行更改配置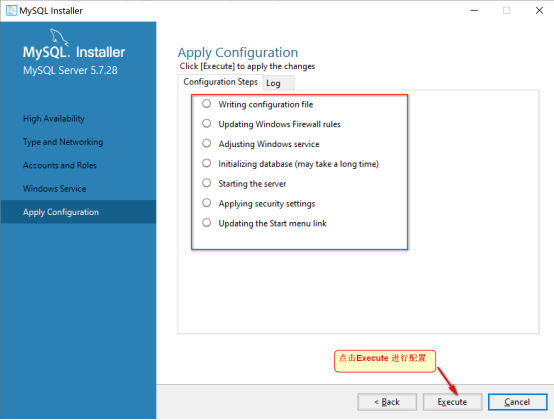
安装完成 Finish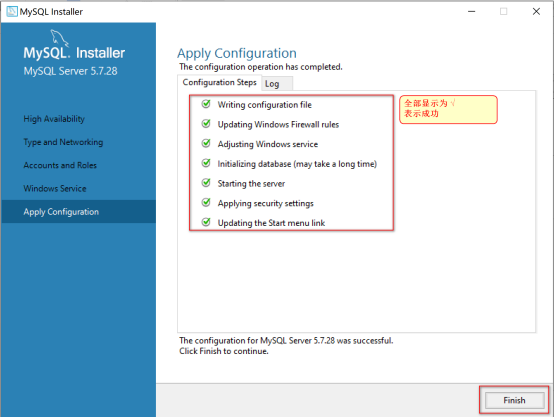
Next
安装完成
点击电脑左下角的开始选项,我们可以看到Mysql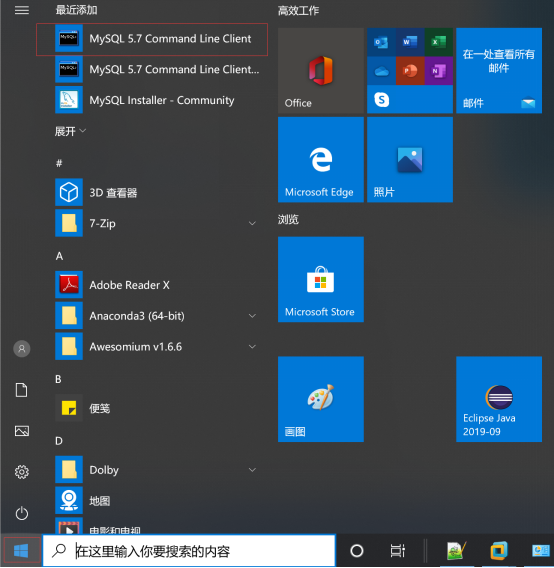
点击连接一下下,输入密码 回车,连接成功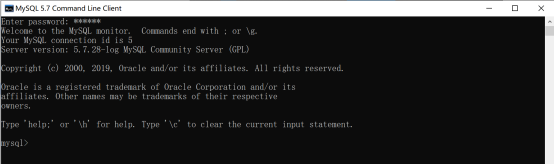
输入命令: show databases
显示 数据库信息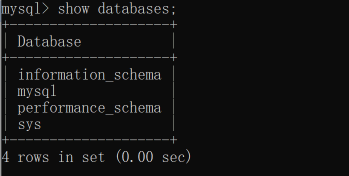
二、环境变量配置
安装好MySQL,为MySQL配置环境变量。MySQL默认安装在C:\Program Files下。
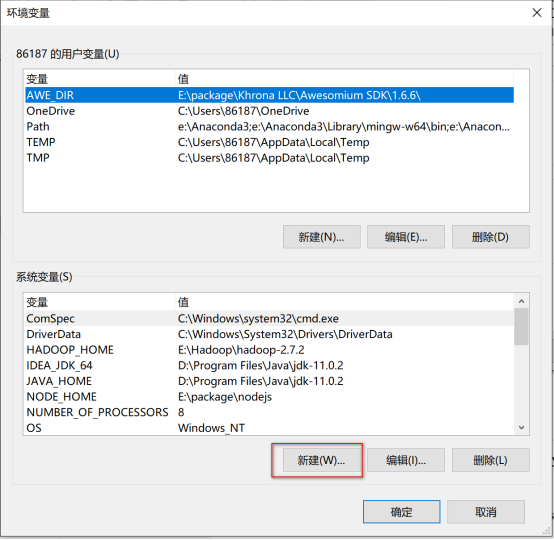
配置环境变量
新建MYSQL_HOME变量,并配置: C:\Program Files\MySQL\MySQL Server 5.7
MYSQL_HOME:C:\Program Files\MySQL\MySQL Server 5.6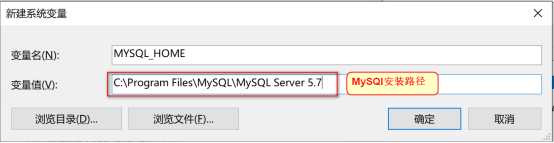
编辑path系统变量,将 %MYSQL_HOME%\bin 添加到path变量后。
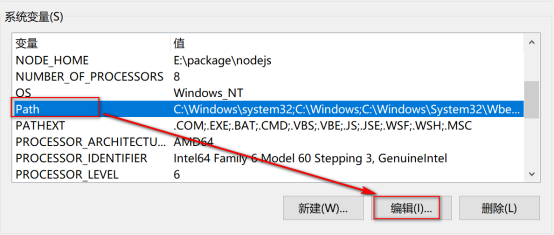
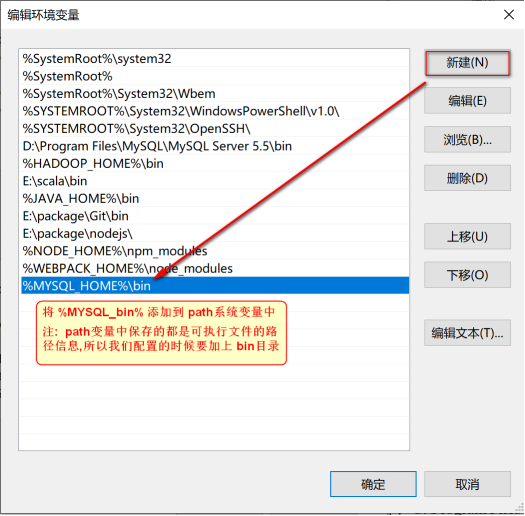
配置path环境变量,也可不新建MYSQL_HOME变量,而是直接将MySQL安装目录下的bin配置到path变量下
即:C:\Program Files\MySQL\MySQL Server 5.7\bin
三、卸载
首先我们找到 Mysql安装目录下的 my.ini 文件.
如果找不到,可以使用搜索工具 对 my.ini文件进行搜索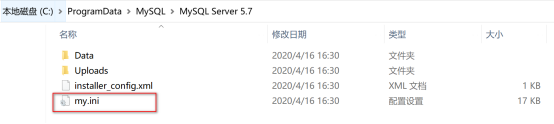
我们打开my.ini 文件,找到这样一段话
这个定义的是mysql的数据库及数据表文件,我们将这段配置复制下来来
datadir=C:/ProgramData/MySQL/MySQL Server 5.7/Data
3.控制面板卸载程序:
4.手动删除残余内容
找到刚才保存数据的mysql文件目录
C:/ProgramData/MySQL/MySQL Server 5.7/Data
直接删除掉Mysql文件夹就可以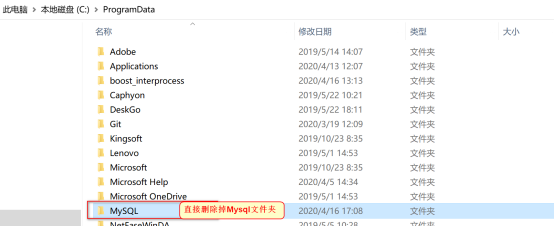
四、启动
window服务启动
右键此电脑 —> 管理—>择服务—> 找到MysQL服务,然后启动即可。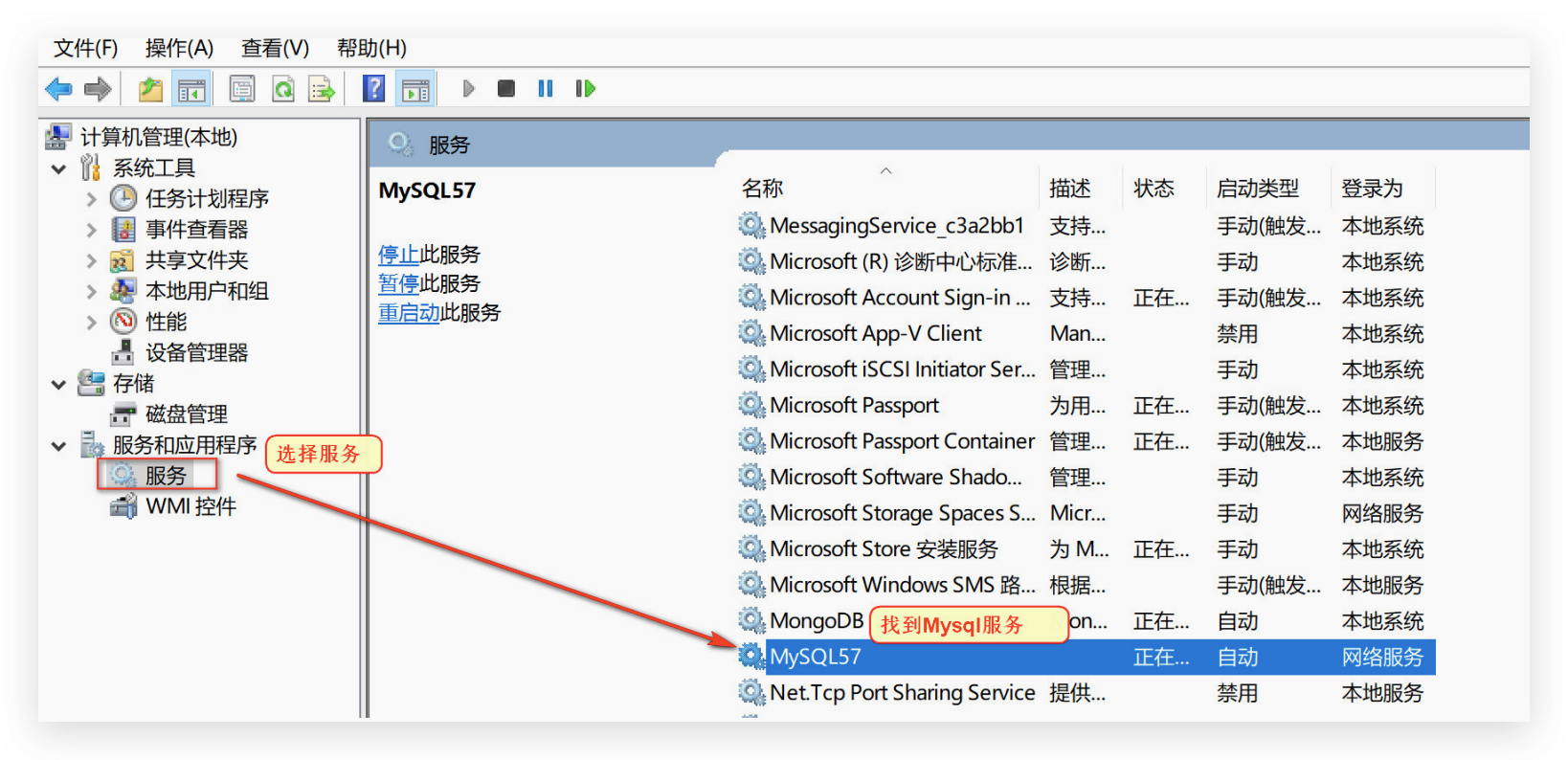
命令行方式启动:
- 首先以管理员身份 打开命令行窗口
- 启动: net start mysql57
- 关闭: net stop mysql57
五、命令行登录
# mysql -u 用户名 -p 密码mysql -uroot -p123456# mysql -h 主机IP -u 用户名 -p 密码# -h 指定IP 方式,进行 登录mysql -h127.0.0.1 -uroot -p123456# 退出命令exit 或者 quit
六、 MySql的目录结构
MySQL安装目录
MySql的默认安装目录在 C:\Program Files\MySQL\MySQL Server 5.7
MySQL配置文件 与 数据库及 数据表所在目录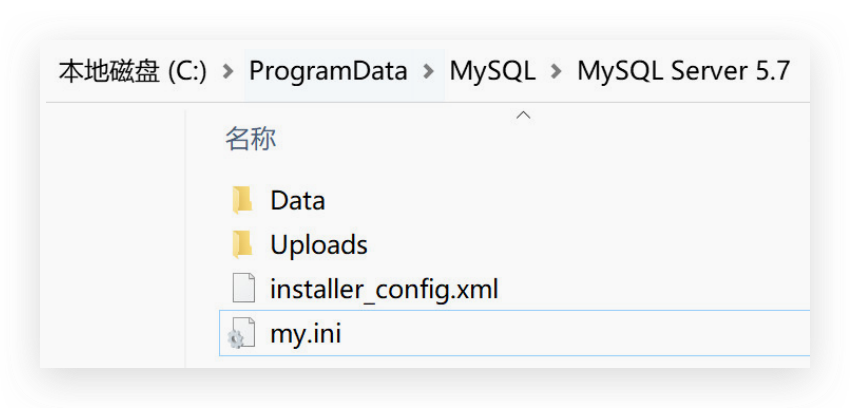
- my.ini 文件 是 mysql 的配置文件,一般不建议去修改
- data<目录> Mysql管理的数据库文件所在的目录
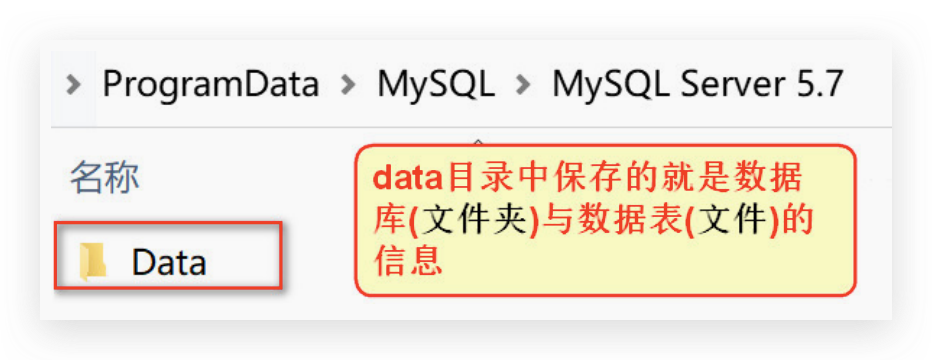
数据库: 文件夹
表: 文件
数据: 文件中的记录
MySql自带数据库:
七、SQL
数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等。
数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新。
数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。
数据控制语言:简称DCL(Date Control Language),用来定义数据库的访问权限和安全级别,及创建用户。(了解)
mysql注释:
# show databases; 单行注释
-- show databases; 单行注释
/*
多行注释
show databases;
*/
01.DDL
DDL 操作数据库
/* 方式1 直接指定数据库名进行创建 默认数据库字符集为:latin1 */
CREATE DATABASE db1;
/* 方式2 指定数据库名称,指定数据库的字符集 一般都指定为 utf8,
与Java中的编码保持一致
*/
CREATE DATABASE db1_1 CHARACTER SET utf8;
-- 切换数据库 从db1 切换到 db1_1
USE db1_1;
-- 查看当前正在使用的数据库
SELECT DATABASE();
-- 查看Mysql中有哪些数据库
SHOW DATABASES;
-- 查看一个数据库的定义信息
SHOW CREATE DATABASE db1_1;
-- 修改数据库字符集
-- 将数据库db1 的字符集 修改为 utf8
ALTER DATABASE db1 CHARACTER SET utf8;
-- 查看当前数据库的基本信息,发现编码已更改
SHOW CREATE DATABASE db1;
-- 删除某个数据库
DROP DATABASE db1_1;
DDL操作数据表
MySQL数据类型:
注意:MySQL中的 char类型与 varchar类型,都对应了 Java中的字符串类型,区别在于:
- char类型是固定长度的: 根据定义的字符串长度分配足够的空间。
- varchar类型是可变长度的: 只使用字符串长度所需的空间
比如:保存字符串 “abc”,
x char(10) 占用10个字节
y varchar(10) 占用3个字节
- char类型适合存储 固定长度的字符串,比如 密码 ,性别一类
- varchar类型适合存储 在一定范围内,有长度变化的字符串
— 切换到数据库 db1
USE db1;
— 创建测试表
CREATE TABLE test1(
tid INT,
tdate DATE
);
— 快速创建一个表结构相同的表(复制表结构)
— 创建一个表结构与 test1 相同的 test2表
CREATE TABLE test2 LIKE test1;
— 查看表结构
DESC test2;
— 查看当前数据库中的所有表名
SHOW TABLES;
— 查看创建表的SQL语句
SHOW CREATE TABLE test2;
— 直接删除 test1 表
DROP TABLE test1;
— 先判断 再删除test2表
DROP TABLE IF EXISTS test2;
— 将category表 改为 category1
RENAME TABLE category TO category1;
— 修改表的字符集,将category表的字符集 修改为gbk
alter table category character set gbk;
— 向表中添加列
# 为分类表添加一个新的字段为 分类描述 cdesc varchar(20)
ALTER TABLE category ADD cdesc VARCHAR(20);
— 修改表中列的 数据类型或长度 , 关键字 MODIFY
— 对分类表的描述字段进行修改,类型varchar(50)
ALTER TABLE category MODIFY cdesc VARCHAR(50);
— 修改列名称 , 关键字 CHANGE
alter table 表名 change 旧列名 新列名 类型(长度);
— 对分类表中的 desc字段进行更换, 更换为 description varchar(30)
ALTER TABLE category CHANGE cdesc description VARCHAR(30);
— 删除列 ,关键字 DROP
alter table 表名 drop 列名;
— 删除分类表中description这列
ALTER TABLE category DROP description;
02.DML
创建学生表
CREATE TABLE student(
sid INT,
sname VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
);
向 学生表中添加数据,3种方式
— 方式1: 插入全部字段, 将所有字段名都写出来
INSERT INTO student (sid,sname,age,sex,address) VALUES(1,’孙悟空’,20,’男’,’花果山’);
— 方式2: 插入全部字段,不写字段名
INSERT INTO student VALUES(2,’孙悟饭’,10,’男’,’地球’);
—方式3:插入指定字段的值
INSERT INTO category (cname) VALUES(‘白骨精’);
注意:
1) 值与字段必须要对应,个数相同&数据类型相同
2)值的数据大小,必须在字段指定的长度范围内
3)varchar char date类型的值必须使用单引号,或者双引号 包裹。
4)如果要插入空值,可以忽略不写,或者插入null
5) 如果插入指定字段的值,必须要上写列名
— 带条件的修改,将sid 为3的学生,性别改为男
UPDATE student SET sex = ‘男’ WHERE sid = 3;
— 一次修改多个列, 将sid为 2 的学员,年龄改为 20,地址改为 北京
UPDATE student SET age = 20,address = ‘北京’ WHERE sid = 2;
— 删除 sid 为 1 的数据
DELETE FROM student WHERE sid = 1;
— 删除所有数据
DELETE FROM student;
— 如果要删除表中的所有数据,有两种做法
1. delete from 表名; 不推荐. 有多少条记录 就执行多少次删除操作. 效率低
2. truncate table 表名: 推荐. 先删除整张表, 然后再重新创建一张一模一样的表. 效率高
truncate table student;
03.DQL
-- 模糊查询 通配符
% 表示匹配任意多个字符串, _ 表示匹配 一个字符
# 查询含有'精'字的所有员工信息
SELECT * FROM emp WHERE ename LIKE '%精%';
# 查询以'孙'开头的所有员工信息
SELECT * FROM emp WHERE ename LIKE '孙%';
# 查询第二个字为'兔'的所有员工信息
SELECT * FROM emp WHERE ename LIKE '_兔%';
limit 关键字的作用
limit是限制的意思,用于 限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
limit 语法是 MySql的方言,用来完成分页
SELECT 字段1,字段2… FROM 表名 LIMIT offset , length;
offset 起始行数, 从0开始记数, 如果省略 则默认为 0.
length 返回的行数
查询emp表中的前 5条数据
— 参数1 起始值,默认是0 , 参数2 要查询的条数
SELECT FROM emp LIMIT 5;
SELECT FROM emp LIMIT 0 , 5;
# 查询emp表中 从第4条开始,查询6条
— 起始值默认是从0开始的.
SELECT * FROM emp LIMIT 3 , 6;
分页操作 每页显示3条数据:
— 分页操作 每页显示3条数据
SELECT FROM emp LIMIT 0,3; — 第1页
SELECT FROM emp LIMIT 3,3; — 第2页 2-1=1 13=3
SELECT FROM emp LIMIT 6,3; — 第三页
— 分页公式 起始索引 = (当前页 - 1) * 每页条数
— limit是MySql中的方言
八、MySQL单表&约束&事务
1. SQL约束
主键约束
1) 需求: 创建一个带主键的表
# 方式1 创建一个带主键的表 **
CREATE TABLE emp2(
— 设置主键 唯一 非空
eid INT PRIMARY KEY,
ename VARCHAR(20),
sex CHAR(1)
);
— 删除表
DROP TABLE emp2;
— 方式2 创建一个带主键的表
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1),
— 指定主键为 eid字段
PRIMARY KEY(eid)
);
— 方式3 创建一个带主键的表
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1)
)
— 创建的时候不指定主键,然后通过 DDL语句进行设置
ALTER TABLE emp2 ADD PRIMARY KEY(eid);
— 查看表的详细信息
DESC emp2;
2) 测试主键的唯一性 非空性
# 正常插入一条数据
INSERT INTO emp2 VALUES(1,'宋江','男');
# 插入一条数据,主键为空
-- Column 'eid' cannot be null 主键不能为空
INSERT INTO emp2 VALUES(NULL,'李逵','男');
# 插入一条数据,主键为 1
-- Duplicate entry '1' for key 'PRIMARY' 主键不能重复
INSERT INTO emp2 VALUES(1,'孙二娘','女');
3) 删除主键约束
-- 使用DDL语句 删除表中的主键
ALTER TABLE emp2 DROP PRIMARY KEY;
DESC emp2;
主键的自增
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
-- 创建主键自增的表
CREATE TABLE emp2(
-- 关键字 AUTO_INCREMENT,主键类型必须是整数类型
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
);
-- 添加数据 观察主键的自增
INSERT INTO emp2(ename,sex) VALUES('张三','男');
INSERT INTO emp2(ename,sex) VALUES('李四','男');
INSERT INTO emp2 VALUES(NULL,'翠花','女');
INSERT INTO emp2 VALUES(NULL,'艳秋','女');
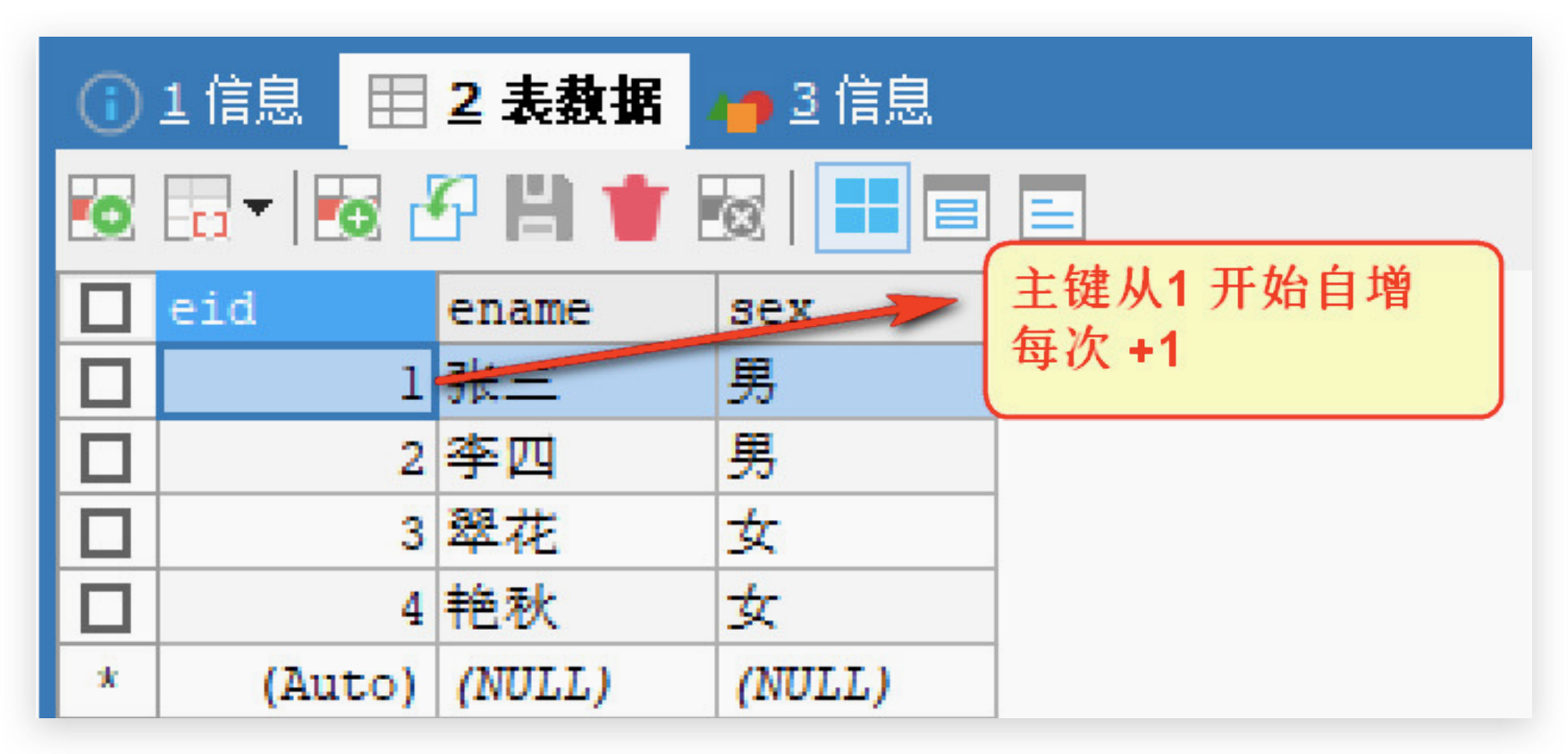
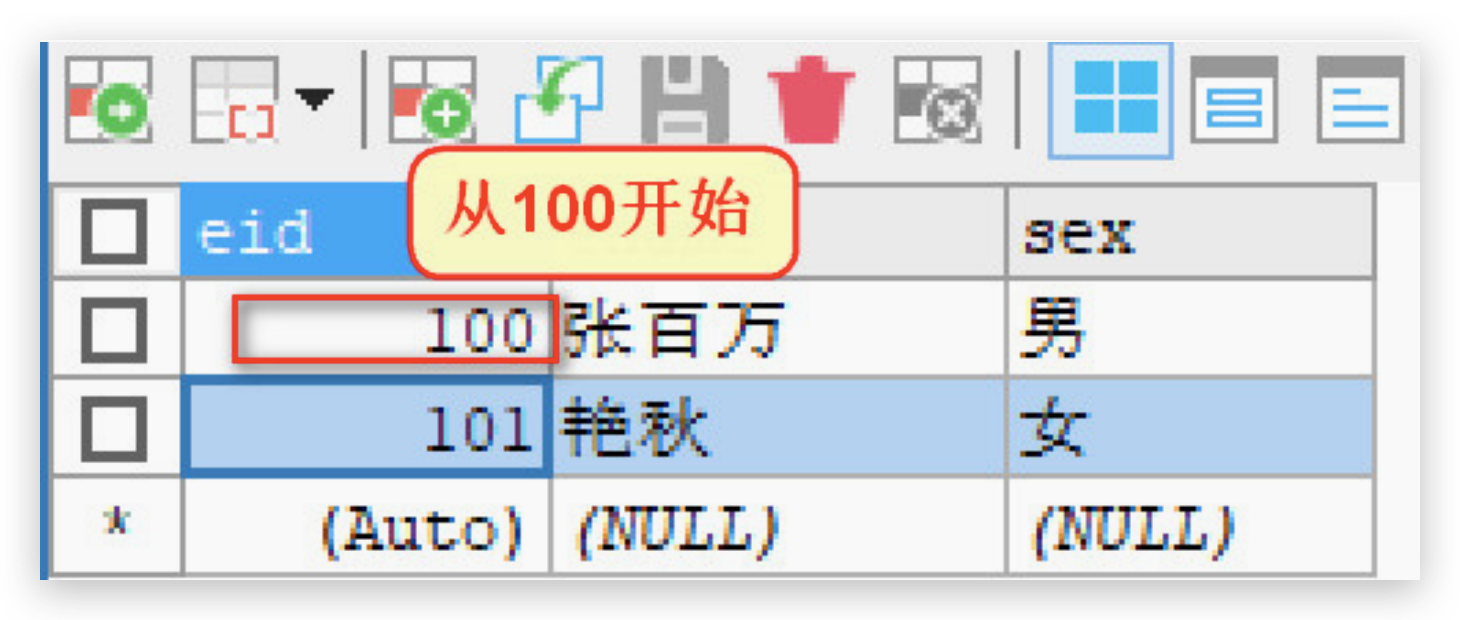
修改主键自增的起始值
默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下面的方式
-- 创建主键自增的表,自定义自增其实值
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
-- 插入数据,观察主键的起始值
INSERT INTO emp2(ename,sex) VALUES('张百万','男');
INSERT INTO emp2(ename,sex) VALUES('艳秋','女');
DELETE和TRUNCATE对自增长的影响
DELETE: 只是删除表中所有数据,对自增没有影响
TRUNCATE:truncate 是将整个表删除掉,然后创建一个新的表,自增的主键,重新从 1开始
非空约束
-- 为 ename 字段添加非空约束
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- 添加非空约束, ename字段不能为空
ename VARCHAR(20) NOT NULL,
sex CHAR(1)
);
唯一约束
唯一约束的特点: 表中的某一列的值不能重复( 对null不做唯一的判断 )
#创建emp3表 为ename 字段添加唯一约束
CREATE TABLE emp3(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20) UNIQUE,
sex CHAR(1)
);
主键约束与唯一约束的区别:
1. 主键约束 唯一且不能够为空
2. 唯一约束,唯一 但是可以为空
3. 一个表中只能有一个主键 , 但是可以有多个唯一约束
默认值
-- 创建带有默认值的表
CREATE TABLE emp4(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- 为ename 字段添加默认值
ename VARCHAR(20) DEFAULT '奥利给',
sex CHAR(1)
);
-- 添加数据 使用默认值
INSERT INTO emp4(ename,sex) VALUES(DEFAULT,'男');
INSERT INTO emp4(sex) VALUES('女');
-- 不使用默认值
INSERT INTO emp4(ename,sex) VALUES('艳秋','女');
2.数据库事务
MYSQL 中可以有两种方式进行事务的操作:
- 手动提交事务
- 自动提交事务
开启事务:start transaction; 或者 BEGIN;这个语句显式地标记一个事务的起始点。
提交事务:commit;表示提交事务,即提交事务的所有操作,具体地说,就是将事务中所有对数据库的更新都写
到磁盘上的物理数据库中,事务正常结束。
回滚事务:rollback;表示撤销事务,即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中
对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态
手动提交事务流程:
执行成功的情况: 开启事务 -> 执行多条 SQL 语句 -> 成功提交事务
执行失败的情况: 开启事务 -> 执行多条 SQL 语句 -> 事务的回滚
模拟sql
-- 创建账户表
CREATE TABLE account(
-- 主键
id INT PRIMARY KEY AUTO_INCREMENT,
-- 姓名
NAME VARCHAR(10),
-- 余额
money DOUBLE
);
-- 添加两个用户
INSERT INTO account (NAME, money) VALUES ('tom', 1000), ('jack', 1000);
-- 模拟tom 给 jack 转 500 元钱,一个转账的业务操作最少要执行下面的 2 条语句:
-- tom账户 -500元
UPDATE account SET money = money - 500 WHERE NAME = 'tom';
-- jack账户 + 500元
UPDATE account SET money = money + 500 WHERE NAME = 'jack';
假设当tom 账号上 -500 元,服务器崩溃了。jack 的账号并没有+500 元,数据就出现问题了。
我们要保证整个事务执行的完整性,要么都成功, 要么都失败. 这个时候我们就要学习如何操作事
务.
-- 1) 命令行 开启事务
start transaction;
-- 2) 插入两条数据
INSERT INTO account VALUES(NULL,'张百万',3000);
INSERT INTO account VALUES(NULL,'有财',3500);
3) 不去提交事务 直接关闭窗口,发生回滚操作,数据没有改变
如果事务中 SQL 语句没有问题,commit 提交事务,会对数据库数据的数据进行改变。 如果事务
中 SQL 语句有问题,rollback 回滚事务,会回退到开启事务时的状态。
自动提交事务
MySQL 默认每一条 DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,语句
执行完毕 自动提交事务,MySQL 默认开始自动提交事务
MySQL默认是自动提交事务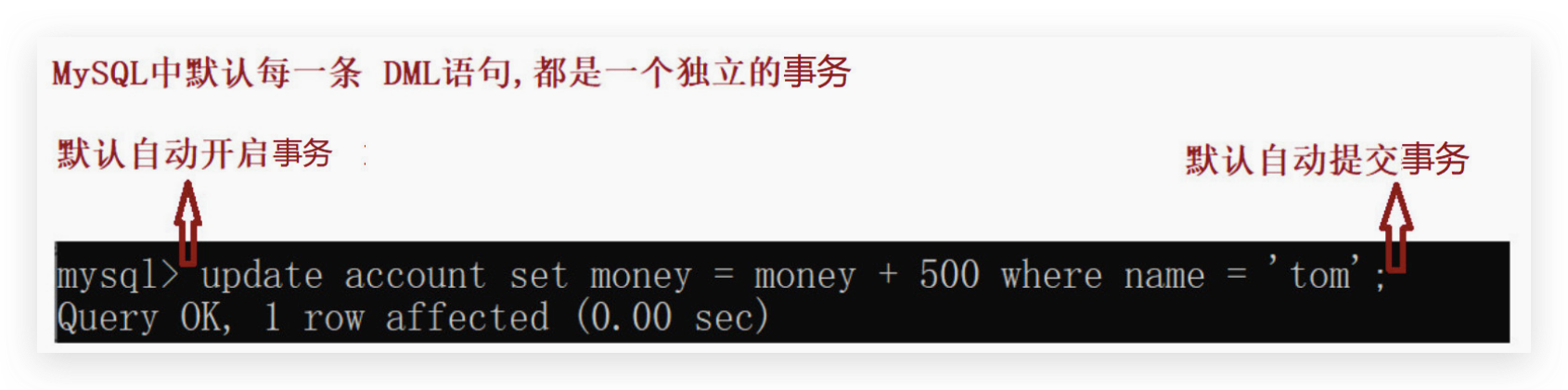
取消自动提交
MySQL默认是自动提交事务,设置为手动提交.
1) 登录mysql,查看autocommit状态。
SHOW VARIABLES LIKE ‘autocommit’;
on :自动提交
off : 手动提交
2) 把 autocommit 改成 off;
SET @@autocommit=off;
事务的四大特性 ACID
原子性:每个事务都是一个整体,不可再拆分,事务中所有的 SQL 语句要么都执行成功, 要么都失败。
一致性:事务在执行前数据库的状态与执行后数据库的状态保持一致。如:转账前2个人的 总金额是 2000,转账后 2 个人总金额也是 2000.
隔离性:事务与事务之间不应该相互影响,执行时保持隔离的状态.
持久性:一旦事务执行成功,对数据库的修改是持久的。就算关机,数据也是要保存下来的.
MySQL 事务隔离级别(了解)
数据并发访问:一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库. 数据库的相同数据可能
被多个事务同时访问,如果不采取隔离措施,就会导致各种问题, 破坏数据的完整性
并发访问会产生的问题:事务在操作时的理想状态: 所有的事务之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个 数据。可能引发并发访问的问题
**
- 脏读:一个事务读取到了另一个事务中尚未提交的数据
- 不可重复读:一个事务中两次读取的数据内容不一致, 要求的是在一个事务中多次读取时数据是一致的. 这是进行 update 操作时引发的问题
- 幻读:一个事务中,某一次的 select 操作得到的结果所表征的数据状态, 无法支撑后续的业务操作. 查询得到的数据状态不准确,导致幻读.
四种隔离级别
通过设置隔离级别,可以防止上面的三种并发问题.MySQL数据库有四种隔离级别 上面的级别最低,下面的级别最高。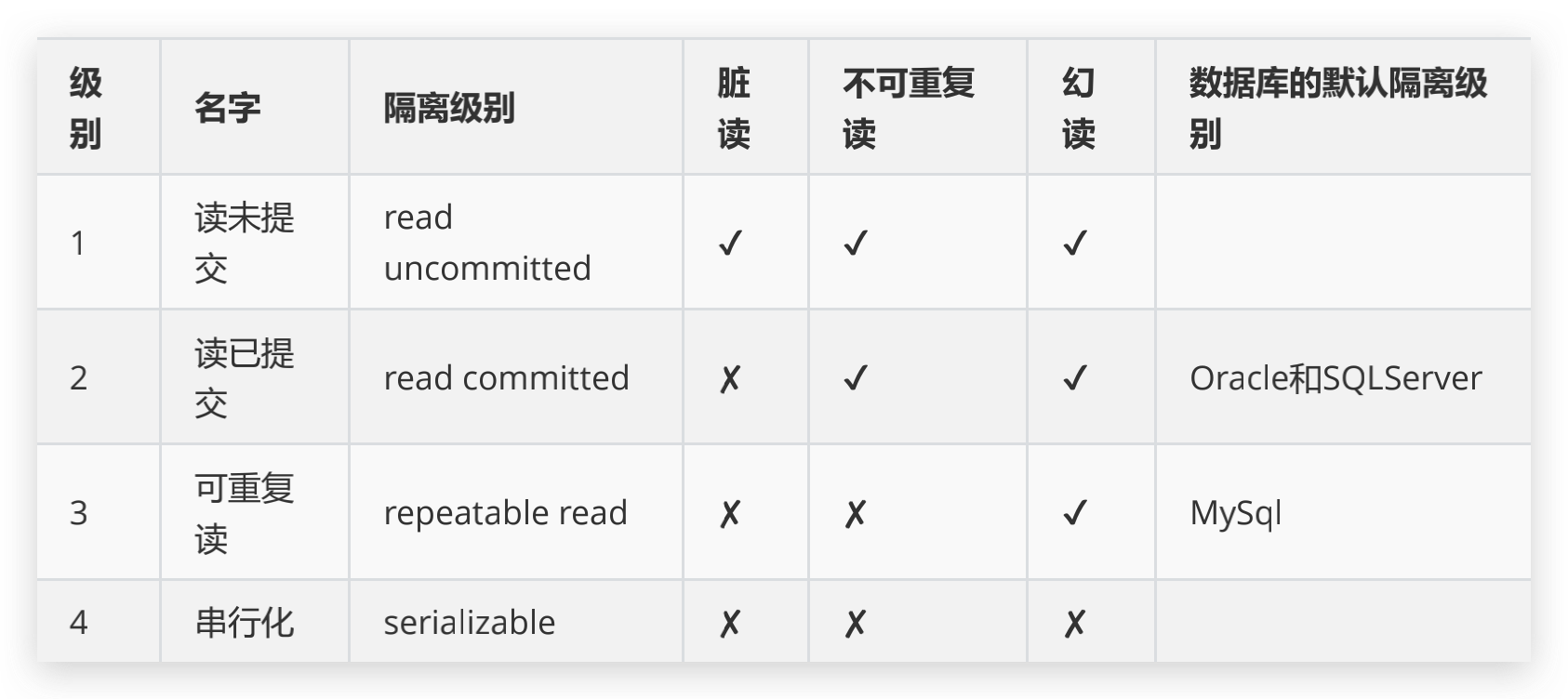
隔离级别相关命令
1) 查看隔离级别
select @@tx_isolation;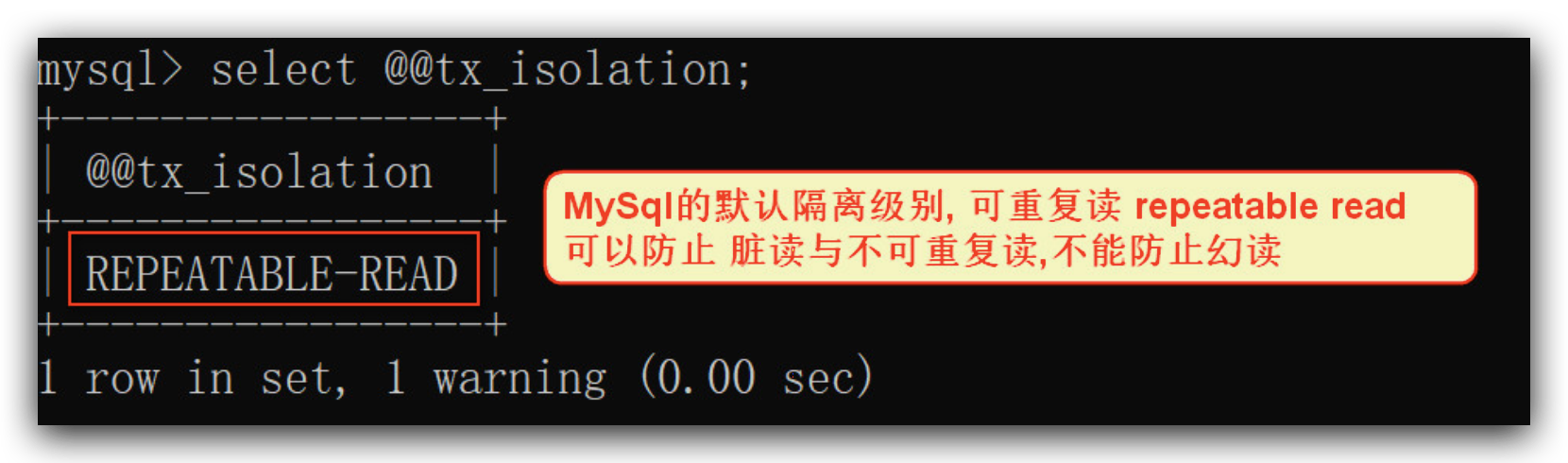
2) 设置事务隔离级别,需要退出 MySQL 再重新登录才能看到隔离级别的变化
set global transaction isolation level 级别名称;
read uncommitted 读未提交
read committed 读已提交
repeatable read 可重复读
serializable 串行化
例如: 修改隔离级别为 读未提交
set global transaction isolation level read uncommitted;
九、数据库设计
数据库三范式(空间最省)
概念: 三范式就是设计数据库的规则.
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式,满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF) , 其余范式以此类推。一般说来,数据库只需满足第三范式(3NF)就行了
第一范式 1NF
原子性, 做到列不可拆分
第一范式是最基本的范式。数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个字段都是不可再分的最小数据单元,则满足第一范式。
地址信息表中, contry这一列,还可以继续拆分,不符合第一范式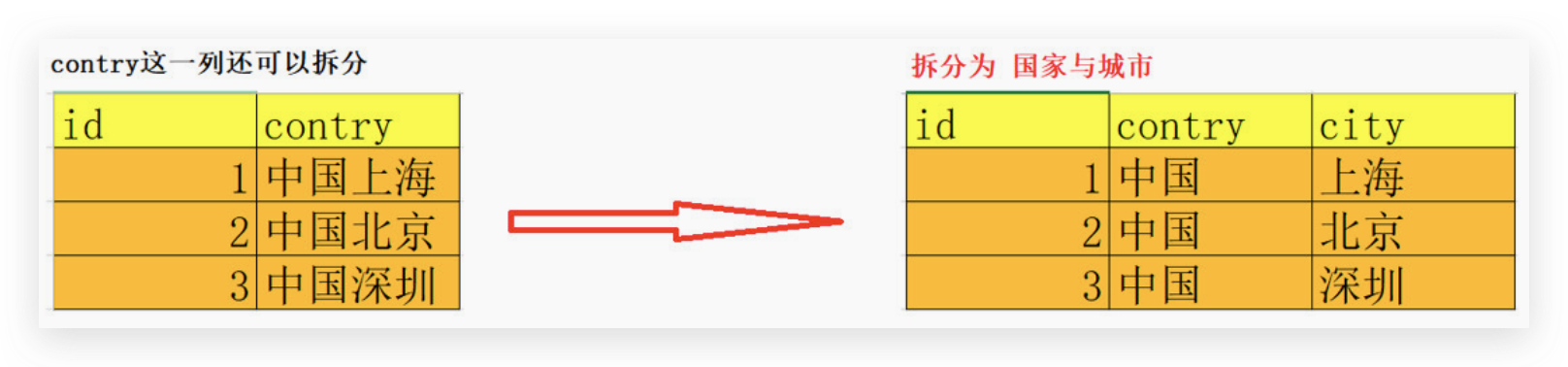
第二范式 2NF
在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。一张表只能描述一件事.
比如,学员信息表中其实在描述两个事物 , 一个是学员的信息,一个是课程信息,如果放在一张表中,会导致数据的冗余,如果删除学员信息, 成绩的信息也被删除了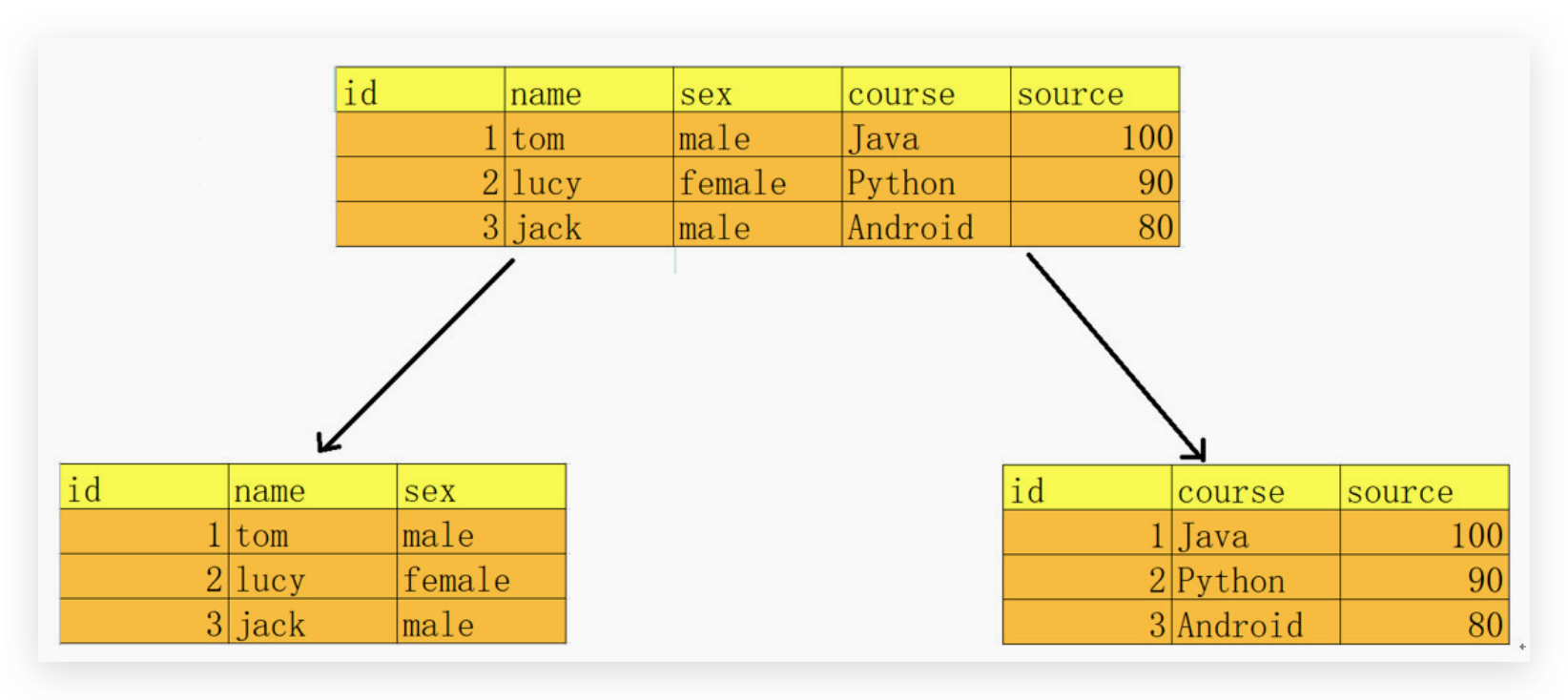
第三范式 3NF
消除传递依赖,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放,
通过number 与 price字段就可以计算出总金额,不要在表中再做记录(空间最省)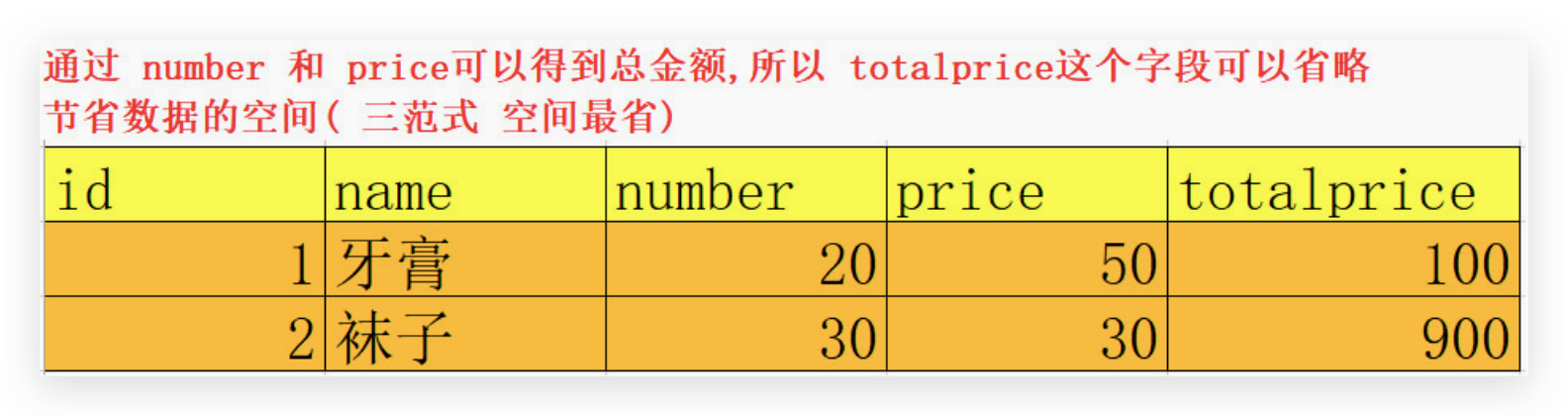
数据库反三范式
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能,浪费存储空间,节省查询时间 (以空间换时间)。
设计数据库时,某一个字段属于一张表,但它同时出现在另一个或多个表,那么这个字段就是一个冗余字段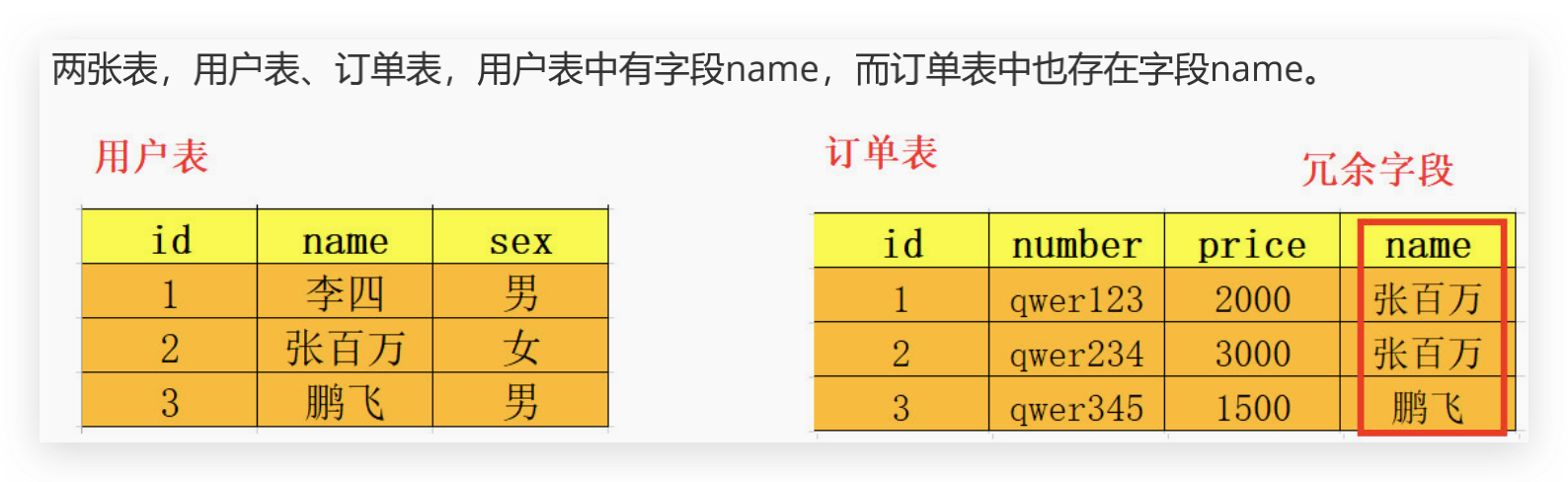
当需要查询“订单表”所有数据并且只需要“用户表”的name字段时, 没有冗余字段 就需要去join连接用户表,假设表中数据量非常的大, 那么这次连接查询就会很大程度上消耗系统性能。这时候冗余的字段就可以派上用场了, 有冗余字段我们查一张表就可以了.
总结
创建一个关系型数据库
1、尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅
2、合理的加入冗余字段,减少join,让数据库执行性能更高更快。
**

若有收获,就点个赞吧
0 人点赞
