一:什么是分区(Partition)?
分区是将一个表或索引物理地分解为多个更小、更可管理的部分。
分区对应用透明,即对访问数据库的应用而言,逻辑上讲只有一个表或一个索引(相当于应用“看到”的只是一个表或索引),但在物理上这个表或索引可能由数十个物理分区组成。
每个分区都是一个独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
—————————————Tips:分表与分区表—————————————
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表(子表);
比如一个订单表 ORDER,采用年月分表后可能就会除 ORDER 本身外还生成许多如 ORDER_201601、ORDER_201602、ORDER_201603… 等的子表。
分表在逻辑上是多张不同的表,而分区表在逻辑上是一张表。
——————————————————————————————————
二:什么时候需要分区?
来自官网的两个建议:
1. Tables greater than 2GB should always be considered for partitioning.(表数据量大于2GB时应该考虑使用分区)
2. Tables containing historical data, in which new data is added into the newest partition. A typical example is a historical table where only the current month’s data is updatable and the other 11 months are read only.(新数据均加入至最新分区中的用于存储历史数据的表)
三:分区带来的好处
1. 提高数据可用性
a) 得益于每个分区的独立性,优化器会在查询时有需要的去除未用到的分区(这也叫消除分区)
比如:一个查询如果只用到了一个表三个分区中的其中一个分区的数据,那么Oracle在执行这个查询时只会扫描用到的这个分区的数据,不会扫描其他两个分区的数据。
这在OLAP系统中很有用。
———————————-延伸阅读:OLTP与OLAP系统——————————-
OLTP(On-Line Transaction Processing):
联机事务处理过程,也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,实现对用户操作的快速响应;
这样的系统事务性要求非常高,一般都是高可用的在线系统,以小的事务以及小的查询为主。评估其系统的时候,一般看其每秒执行的 Transaction 以及 Execute SQL 的数量。单个数据库每秒处理的 Transaction 往往超过几百个或是几千个,Select 语句的执行量每秒几千甚至几万个;
OLTP是传统的关系型数据库的主要应用,典型的OLTP系统有电子商务系统、银行、证券系统等。
OLAP(On-Line Analytical Processing):
联机分析处理,是数据仓库系统的主要应用,所谓数据仓库是对于大量已经由OLTP形成的数据的一种分析型的数据库,用于处理商业智能、决策支持等重要的决策信息;
数据仓库是在数据库应用到一定程度之后而对历史数据的加工与分析,读取较多、更新较少;
OLTP与OLAP简单对比: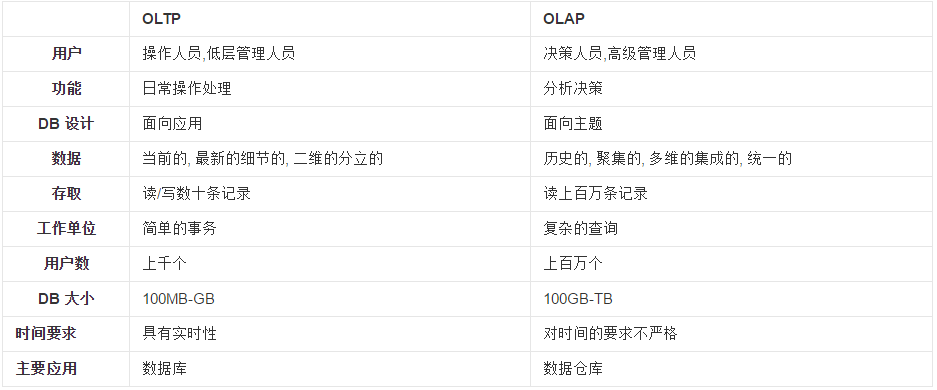
b) 分区还可以通过减少停机时间来提高可用性
例如:一个100GB的表,中间的数据如果遭到损坏,那么恢复起来简直让人抓狂。
如果这100GB的表被划分为了50个2GB的分区,当其中某个分区数据遭到破坏时,只需要恢复一个2GB的分区数据即可。
出现错误时的停机时间将会大大减少,因为恢复所需的工作量大幅减少。
2. 方便管理
将一个大的对象分解为数个小对象,操作这些小对象明显比直接操作原来的大对象更加容易,且占用的资源也更少。
3. 改善语句性能(多针对OLAP系统)
a) 并行DML(Parallel DML):
在 Oracle 9i 以前的版本中,PDML(Parallel DML)要求必须分区;
9i 及以后的版本中这个限制已经放松,只有两个例外:
① 希望在一个表上执行 PDML,而且这个表的一个 LOB列上有一个位图索引,要并行执行操作就必须对这个表分区;
② 对于并行访问分区操作,取需要访问的分区数为并行度
——————————-延伸阅读:PDML(Parallel DML)——————————-
什么是Parallel(并行)技术?
对于一个大的任务,一般的做法是利用一个进程,串行的执行。
但如果系统资源足够,可以采用Parallel(并行)技术,把一个大的任务分成若干个小的任务,同时启用N个进程(或线程),并行的处理这些小的任务,这些并发的进程称为并行执行服务器(parallel executeion server),它们统一由一个称为并发协调进程的进程来管理。
注意:
只有在需要处理一个很大的任务(如需要几个小时的作业),并且要有足够的系统资源(包括CPU、内存、I/O等)的情况下,才应该考虑使用Parallel技术。
否则,在一个多并发用户环境下,系统本身资源负担已经很大,启用Parallel的话,将会导致某一个会话试图占用所有的资源,其他会话不得不等待,从而导致系统性能反而下降的情况。
一般情况下,OLTP系统中不要使用Parallel技术,OLAP系统中可以考虑使用。
PDML分类:
- Parallel Query(并行查询)
- Parallel DML(并行DML语句执行)
- Parallel DDL(并行DDL语句执行)
并行查询:并行查询允许将一个select语句划分为多个较小的查询,每个部分的查询都并发地运行,然后将各个部分的结果组合起来,提供最终的结果。(多用于全表扫描,索引全扫描等)
并行DML:Parallel DML包括 insert、update、delete、merge,在PDML期间,Oracle可以使用多个并行执行服务器(即并发进程)来执行 insert、update、delete、merge,多个会话同时执行,同时每个会话(并发进程)都有自己的undo段,都是一个独立的事务,这些事务要么都由并发协调进程提交,要么都rollback。
———————————————————————————————————-
b) 查询性能:
分区对于不同的系统带来的影响可能不同;
对OLTP系统而言,需要谨慎使用分区操作,因为在传统的OLTP系统中,大多数查询很可能立即返回结果,而且获取大多数数据可能都通过一个很小的索引区间扫描来完成。故分区带来的性能方面的优点在 OLTP 系统中可能根本表现不出来。
在一个OLTP系统中,分区如果应用不当,甚至可能使性能下降(分区可能会提高某些类型查询的性能,但是这些查询通常不在OLTP系统中使用);
所以有一点你必须明白:分区并不总是和“性能提升”联系在一起。
对于OLAP系统而言,分区消除与并行查询将可能带来效率的大幅提升。
四:表分区机制
表分区的四种类型:
- 范围分区(Range)
- 散列分区(Hash)
- 列表分区(List)
- 组合分区(Range – Hash 或者 Range - List)
- 范围分区:
范围(Range)分区将数据基于指定的分区键映射到每一个分区中。
这种分区方式最为常用,且常常采用日期作为分区键。
注意:
① 每一个分区都需要有一个 VALUES LESS THEN 子句,它指定了该分区的上限值(即该分区能接受的分区键的最大值)。记录里分区键的值小于这个上限值时,该记录会被放入该分区;而当记录里分区键的值等于或大于这个上限值时该记录会被放入下一个上限值更高的分区中。
② 所有分区里,除了第一个分区,其他分区其实都有一个隐式的下限值(即该分区能接受的分区键的最小值),这个下限值就是上一个分区的上限值。
③ 在最后一个分区中,可定义上限值为 MAXVALUE(该值可理解为所有分区中的一个最大上限值,包括空值),当记录分区键的值大于之前所有分区的上限值时,这条记录会被放入这最后一个分区中。
建表语句示例:
/**范围分区示例**/
—创建示例表
create table range_example
(
id number(2),
done_date date,
data varchar2(50)
)
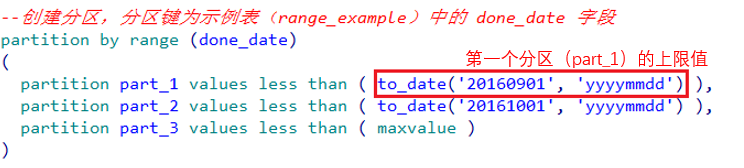
—创建分区,分区键为示例表(range_example)中的 done_date 字段
partition by range (done_date)
(
partition part_1 values less than ( to_date(‘20160901’, ‘yyyymmdd’) ),
partition part_2 values less than ( to_date(‘20161001’, ‘yyyymmdd’) ),
partition part_3 values less than ( maxvalue )
)
—查看range_example表的分区信息
select from user_tab_partitions where table_name = ‘RANGE_EXAMPLE’;
查看表分区信息:
插入数据:
如图,可以看到示例表 range_example 已经分了三个区。
记录1的 done_date 为 2016/8/11,小于分区part_1的上限值,则记录1会被放入part_1分区;
记录2的 done_date 为 2016/9/8 ,大于分区part_1的上限值但小于part_2的上限值,则记录2会被放入part_2分区;
记录3的 done_date 为 2016/10/20,大于前两个分区的上限值,故会被放入最后一个maxvalue的分区(part_3);
part_2的隐式的下限值实际就是上一个分区part_1的上限值;
2. 散列分区:
对一个表执行散列分区时,Oracle会对分区键应用一个散列(Hash)函数,以此确定数据应当放在 N 个分区中的哪一个分区中。
Oracle建议 N 是 2 的一个幂(如 N = 2、4、8、16 等),从而使表数据得到最佳的总体分布。
当列的值没有合适的范围条件时,建议使用散列分区。
注意:
如果改变散列分区的个数 (向一个散列分区表增加或删除一个分区时),数据会在所有分区中重新分布,即所有数据都会被重写,因为现在每一行可能属于一个不同的分区。
为表选择的散列键(分区键)应当是惟一的一个列或一组列(该列应有多个不同的值),以便行能在多个分区上均匀地分布。
如果使用散列分区,你将无法控制一行数据最终会放在哪个分区中(由散列函数控制)。
建表语句示例:
/**散列分区示例*/
—创建示例表
create table hash_example
(
id number(2),
done_date date,
data varchar2(50)
)
—创建散列分区,分区键为示例表(hash_example)中的 done_date 字段
partition by hash (done_date)
(
partition part_1,
partition part_2
)
select from user_tab_partitions where table_name = ‘HASH_EXAMPLE’;
分区信息:
3. 列表分区:
列表分区可以根据分区键的值明确指定哪些值的数据该放在哪个分区。
注意:
列表分区中如果指定了 default 分区,则分区键的值不在任何分区值列表中的记录,会被放入 default 分区;
而一旦创建了一个 default 分区后,就不能再向这个表中增加更多的分区了;
如果未指定 default 分区,则在插入分区键值不在任何分区值列表中的记录时,Oracle会报错(ORA-14400: inserted partition key does not map to any partition)。
建表语句示例:
/**列表分区示例*/
—创建示例表
create table list_example
(
id number(2),
name varchar(30),
data varchar2(50)
)
—创建列表分区,分区键为示例表(list_example)中的 id 字段
partition by list (id)
(
partition part_1 values ( ‘1’, ‘3’, ‘5’, ‘7’ ),
partition part_2 values ( ‘2’, ‘4’, ‘6’, ‘8’ ),
partition part_default values ( default )
)
select from user_tab_partitions where table_name = ‘LIST_EXAMPLE’;
分区信息:
如上,分区键(即list_example表中id字段)值为 1、3、5、7 的记录,会被放入part_1分区;
分区键值为 2、4、6、8 的记录,会被放入part_2分区;
分区键值为其他值的记录,会被放入最后一个part_default分区。
4. 组合分区:
组合分区是范围分区与散列分区的组合,或者是范围分区与列表分区的组合。
在组合分区中,顶层分区机制总是范围分区,第二级分区机制可能是散列分区也可能是列表分区;
数据物理的存储在子分区段上,分区(顶层的范围分区)成为了一个逻辑容器,或者是一个指向实际子分区的容器;
每个顶层分区不需要有相同数目的子分区。
范围-散列组合分区 建表语句示例:
/**范围-散列分区**/
create table range_hash_example
(
id number(2),
done_date date,
data varchar2(*50)
)
—顶层范围分区的分区键为 range_hash_example 表中的 done_date 字段;
—第二层散列分区的分区键为 range_hash_example 表中的 id 字段;
partition by range (done_date) subpartition by hash (id)
(
partition part_1 values less than ( to_date(‘20160901’, ‘yyyymmdd’) )
(
subpartition part_1_sub_1,
subpartition part_1_sub_2
),
partition part_2 values less than ( to_date(‘20161001’, ‘yyyymmdd’) )
(
subpartition part_2_sub_1,
subpartition part_2_sub_2
),
partition part_3 values less than ( maxvalue )
(
subpartition part_3_sub_1,
subpartition part_3_sub_2
)
)
select from user_tab_partitions where table_name = ‘RANGE_HASH_EXAMPLE’;
分区信息:
在如上的范围-散列组合分区中,Oracle会首先应用范围(Range)分区规则,得出数据属于哪个区间,(即先通过 done_date 字段确定记录是属于part_1还是part_2还是part_3);
然后再应用散列(Hash)函数,来确定数据最后要放在哪个子分区(物理分区)中,(即通过 id 字段确定记录是属于一个分区下的哪个子分区中 )
范围-列表组合分区 建表语句示例:
/**范围-列表分区**/
create table range_list_example
(
id number(2),
done_date date,
data varchar2(*50)
)
—顶层范围分区的分区键为 range_list_example 表中的 done_date 字段;
—第二层列表分区的分区键为 range_list_example 表中的 id 字段;
partition by range (done_date) subpartition by list (id)
(
partition part_1 values less than ( to_date(‘20160901’, ‘yyyymmdd’) )
(
subpartition part_1_sub_1 values ( ‘1’, ‘3’, ‘5’ ),
subpartition part_1_sub_2 values ( ‘2’, ‘4’, ‘6’ )
),
partition part_2 values less than ( to_date(‘20161001’, ‘yyyymmdd’) )
(
subpartition part_2_sub_1 values ( ‘11’, ‘13’, ‘15’, ‘17’ ),
subpartition part_2_sub_2 values ( ‘12’, ‘14’ ),
subpartition part_2_sub_3 values ( ‘16’, ‘18’ )
),
partition part_3 values less than ( maxvalue )
(
subpartition part_3_sub_1 values ( ‘21’, ‘23’, ‘25’ ),
subpartition part_3_sub_2 values ( ‘22’, ‘24’, ‘26’ )
)
)
select from user_tab_partitions where table_name = ‘RANGE_LIST_EXAMPLE’;
分区信息:
如图,每个顶层的范围分区可以有不同数目的子分区。
5. 小结
一般来讲,如果需要将数据按照某个值逻辑聚集,多采用范围分区。如基于时间数据的按“年”、“月”等分区就是很典型的例子。在许多情况下,范围分区都能利用到分区消除特性( = >= <= between…and 等筛选条件下)。
如果在表里无法找到一个合适的属性来按这个属性完成范围分区,但你又想享受分区带来的性能与可用性的提升,则可以考虑使用散列分区。(适合使用 = IN 等筛选条件)
如果数据中有一列或有一组离散值,且按这一列进行分区很有意义,则这样的数据就很适合采用列表分区。
如果某些数据逻辑上可以进行范围分区,但是得到的范围分区还是太大,不能有效管理,则可以考虑使用组合分区。
注意:
分区在最开始创建表时被一同创建,如果后期要更改分区策略的话,需要先重建表。
—————————————-延伸阅读:自动递增(自增)分区—————————————-
前面说到基于时间数据的按“年”、“月”进行的典型的范围分区例子,这里再补充一个应用场景:
假如有一张商品销售记录表(products_table),其中简单记录着商品的id号,名称,销售时间;
当按照销售时间进行范围分区时,因为表里的记录是不断增加的(每卖出一个商品就会增加一条记录),这时候就可以考虑创建自增分区;
顾名思义的,当有新记录插入时,Oracle会根据需要自动增加新分区来存储新记录(当新插入的记录里的分区键的值不在任何已有分区范围内时,Oracle会自动创建一个新的分区)
你可以根据需要来指定自增分区的自动递增策略,比如按天自增、按周自增、按月自增、按年自增等等(具体自增语句百度一下即可知道);
商品销售记录表创建按月自增的范围分区示例:
create table products_table
(
id number(2),
name varchar2(50),
sale_date date
)
partition by range(sale_date)
interval (numtoyminterval(1,’month’))
(
partition p_month_1 values less than (to_date(‘2016-01-01’,’yyyy-mm-dd’))
)
如图,取 products_table 中的 sale_date 列作为分区键创建按月自增分区;
所有销售时间在 ‘2016-01-01’之前的记录都会被放入 p_month_1 分区;
销售时间在‘2016-01-01’之后的记录在插入时Oracle会自动创建记录所属月的分区;
比如当有销售时间分别为 2016年1月20日 与 *2016年2月20日 的两条记录插入时,Oracle会分别创建一个上限值为 ‘2016-01-31’的分区和一个上限值为‘2016-02-29’的分区来存储这两条记录

若有收获,就点个赞吧
0 人点赞
