1. 文本表示
文本是一种非结构化的数据信息,是不可以直接被计算的。文本表示的作用就是将这些非结构化的信息转化为结构化的信息,这样就可以针对文本信息做计算,来完成我们日常所能见到的文本分类,情感判断等任务。
- 独热编码 | one-hot representation
- 整数编码
- 词嵌入 | word embedding
2. 独热编码(One-Hot Representation)
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是: 猫:[1,0,0,0] 狗:[0,1,0,0] 牛:[0,0,1,0] 羊:[0,0,0,1]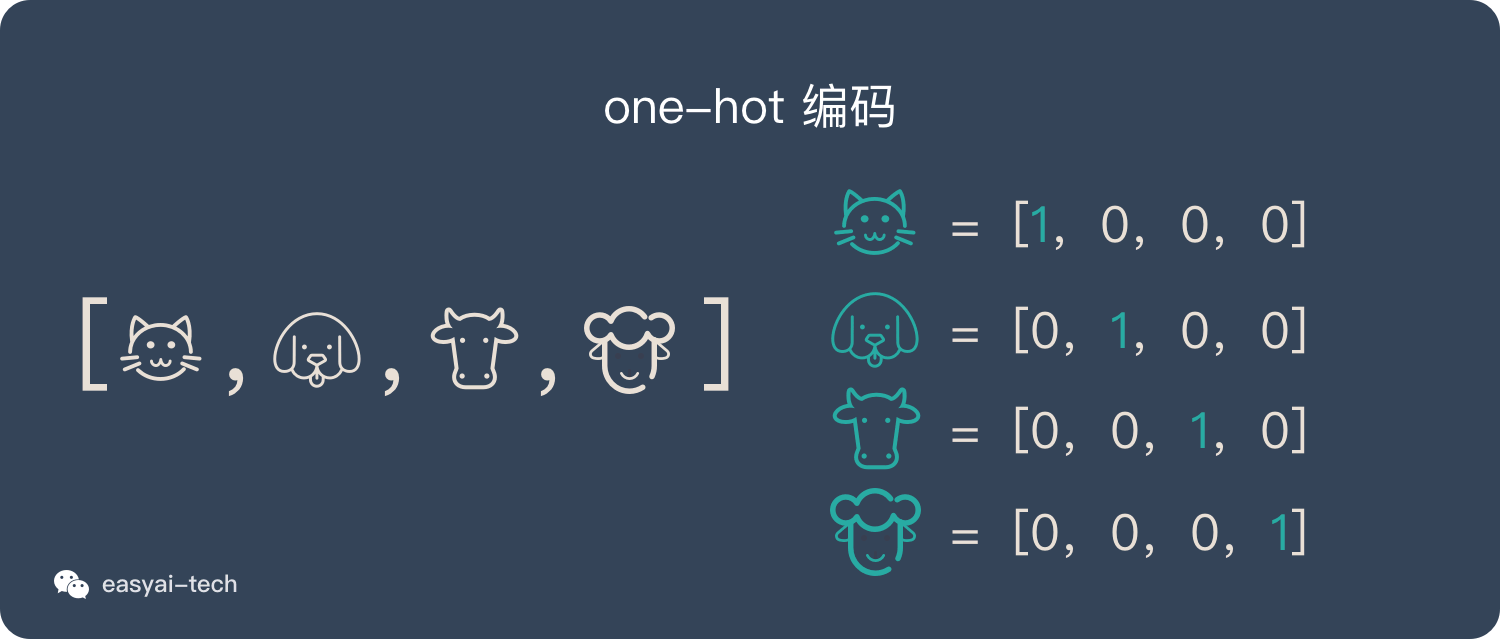
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
3. 整数编码
这种方式也非常好理解,用一种数字来代表一个词,上面的例子则是: 猫:1 狗:2 牛:3 羊:4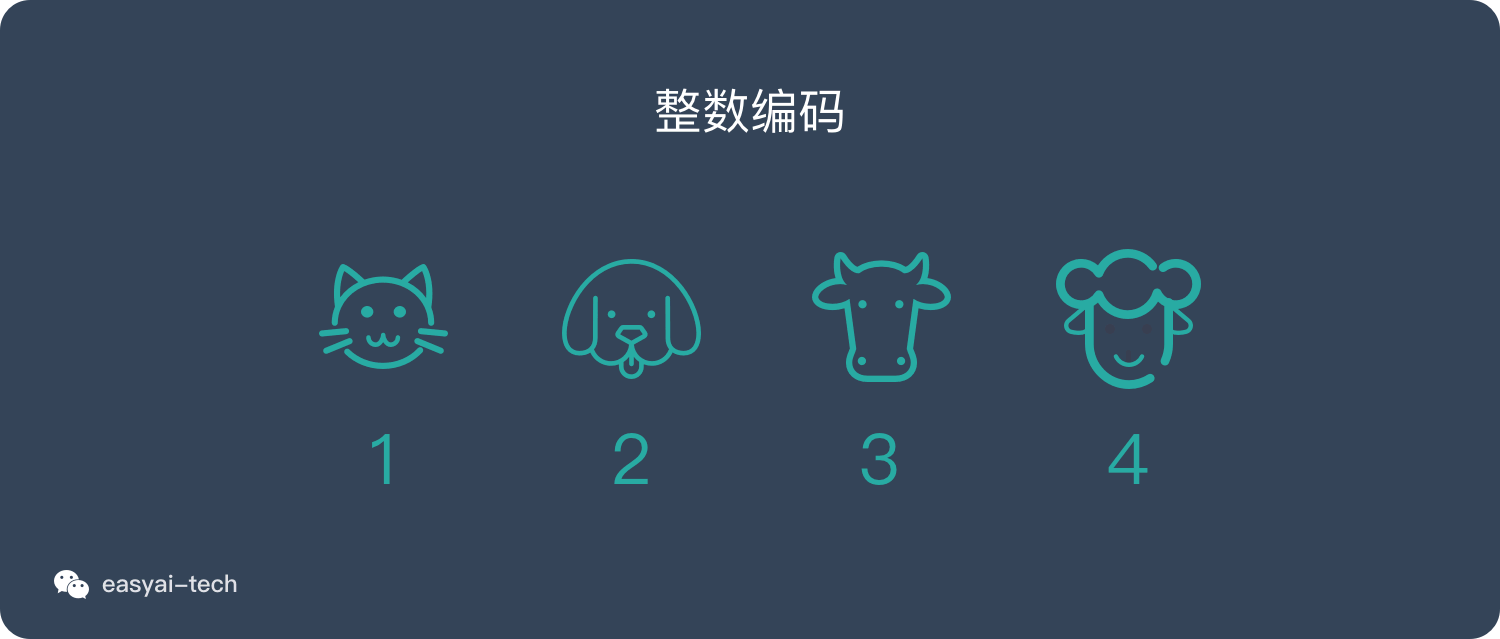
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
4. 词嵌入(Word Embeding)
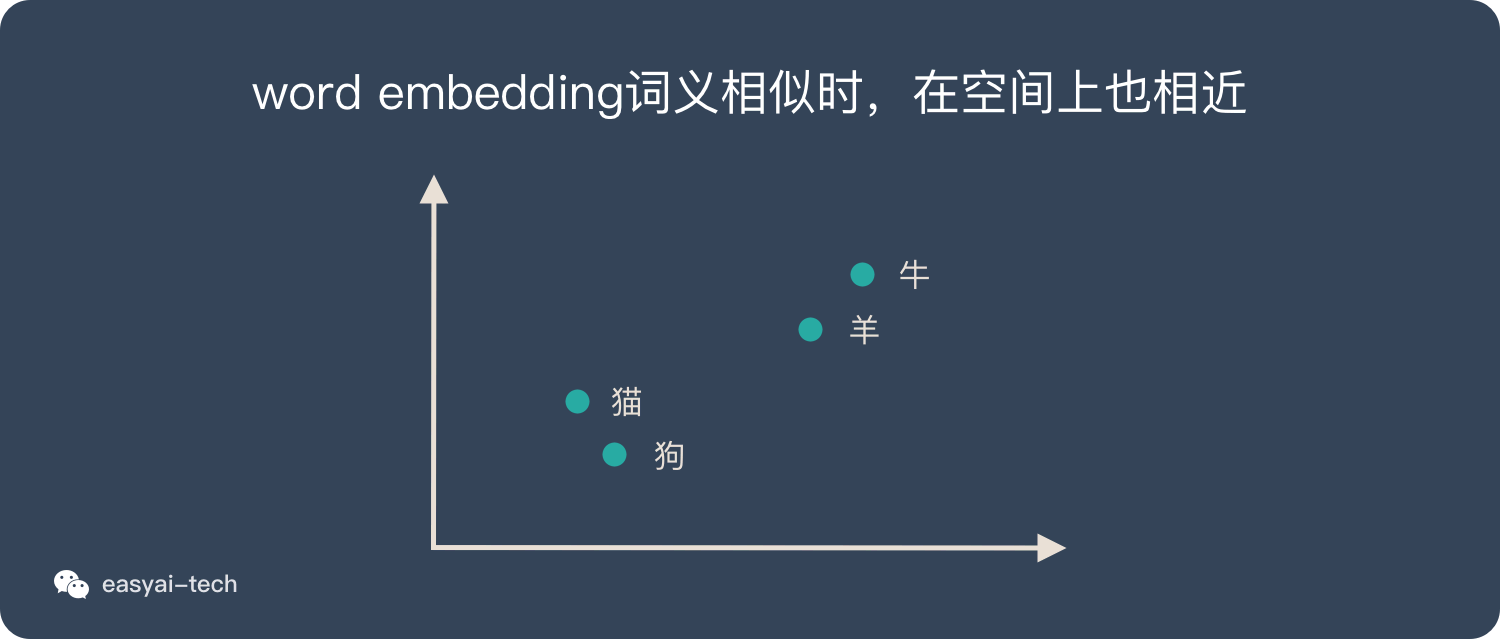
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。 词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:- 他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
4.1 主流的Word Embeding算法

4.1.1 Word2vec
这是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。 这种算法有2种训练模式:- 通过上下文来预测当前词
- 通过当前词来预测上下文
4.1.2 Glove
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。想要了解 GloVe 的 三步实现方式、训练方法、和 w2c 的比较。可以看看这篇文章:《GloVe详解》 词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。 从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。 生成这种映射的方法包括神经网络,单词共生矩阵的降维,概率模型,可解释的知识库方法,和术语的显式表示 单词出现的背景。 当用作底层输入表示时,单词和短语嵌入已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
若有收获,就点个赞吧
0 人点赞
