原始数据File
数据块Block
hdfs上数据存储的一个单元,同一个文件中块的大小都是相同的
因为数据存储到HDFS上不可变,所以有可能块的数量和集群的计算能力不匹配 我们需
要一个动态调整本次参与计算节点数量的一个单位
切片 Split
切片是一个逻辑概念 在不改变现在数据存储的情况下,可以控制参与计算的节点数目
通过切片大小可以达到控制计算节点数量的目的
有多少个切片就会执行多少个Map任务
一般切片大小为Block的整数倍(2 1/2)
防止多余创建和很多的数据连接
如果Split>Block,计算节点少了
如果Split
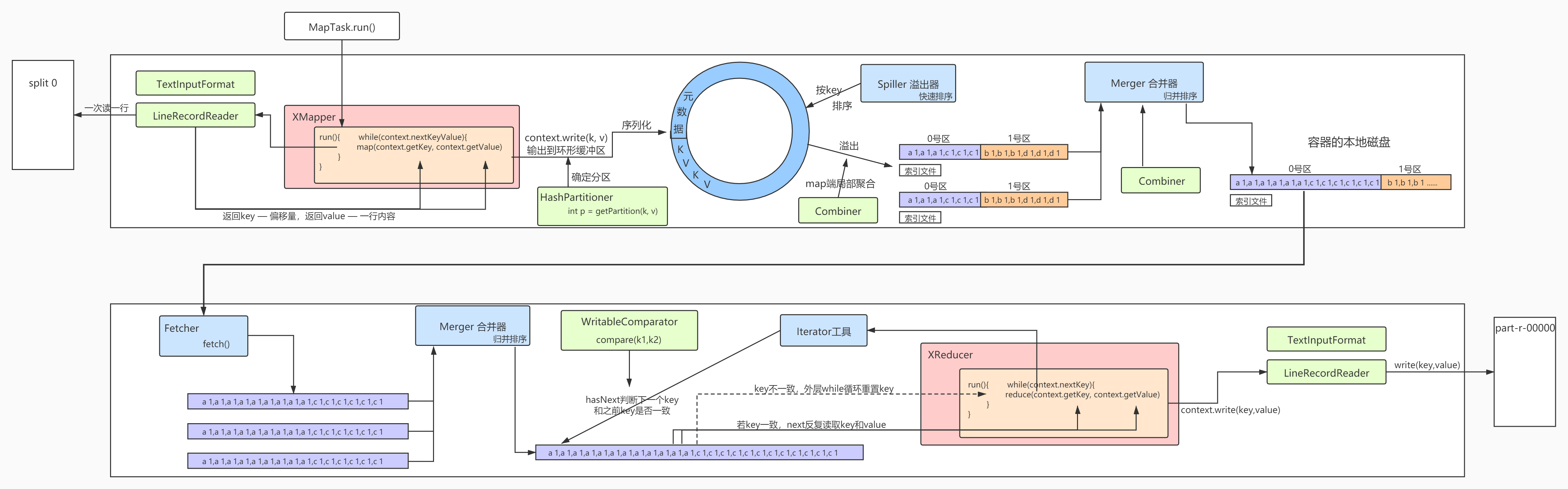
MapTask
map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中
我们可以根据自己书写的分词逻辑(空格分隔) 计算每个单词出现的次数 这是就会产生
(Map
但是内存大小是有限的,如果多个任务同时执行有可能内存溢出(OOM) 如果把数据都直接存放到硬盘,效率太低
我们需要在OOM和效率低之间提供一个有效方案
可以现在内存中写入一部分,然后写出到硬盘
环形数据缓冲区
可以循环利用这块内存区域,减少数据溢写时map的停止时间
每一个Map可以独享的一个内存区域
在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M
设置缓冲区的阈值为80%,当缓冲区的数据达到80M开始向外溢写到硬盘
溢写的时候还有20M的空间可以被使用效率并不会被减缓 而且将数据循环写到硬盘,不用担心OOM问题
分区Partation
根据Key直接计算出对应的Reduce分区的数量和Reduce的数量是相等的
hash(key)%partation=num
默认分区的算法是Hash然后取余
Object的hashCode()—-equals()
如果两个对象equals,那么两个对象的hashcode一定相等
如果两个对象的hashcode相等,但是对象不一定equlas
排序Sort
对要溢写的数据进行排序(QuickSort)
按照先Partation后Key的顺序排序—->相同分区在一起,相同Key的在一起
我们将来溢写出的小文件也都是有序的
溢写Spill
将内存中的数据循环写到硬盘,不用担心OOM问题
每次会产生一个80M的文件
如果本次Map产生的数据较多,可能会溢写多个文件
合并Merge
因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定
后面向reduce传递数据带来很大的问题
所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
合并小文件的时候同样进行排序(归并排序),最终产生一个有序的大文件
组合器combiner
集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间
的数据传输 hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数
(如同map函数和reduce函数一般), 其逻辑一般和reduce函数一样,combiner的输入是map
的输出,combiner的输出作为reduce的输入,很多情况下可以直接将reduce函数作为conbiner函数来使用
(job.setCombinerClass(FlowCountReducer.class);).
combiner属于优化方案,所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用
combiner函数,也可以在溢出的小文件合并成大文件时调用combiner.但是要保证不管调用几次combiner
函数都不会影响最终的结果,所以不是所有处理逻辑都可以使用combiner组件,有些逻辑如果在使用了
combiner函数后会改变最后reduce的输出结果(如求几个数的平均值,就不能先用combiner求一次各个map
输出结果的平均值,再求这些平均值的平均值,这将导致结果错误)
combiner的意义就是对每一个maptask的输出进行局部汇总 以减小网络传输量
原先传给reduce的数据是a1 a1 a1 a1 a1
第一次combiner组合之后变为a{1,1,1,1…}
第二次combiner后传给reduce的数据变为a{4,2,3,5…}
拉取Fetch
我们需要将Map的临时结果拉取到Reduce节点
原则:
相同的key必须拉取到同一个Reduce节点
但是一个Reduce节点可以有多个Key
未排序前拉取数据的时候必须对Map产生的最终的合并文件做全序遍历
而且每一个reduce都要做一个全序遍历
如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需即可
合并Merge
因为reduce拉取的时候,会从多个map拉取数据 那么每个map都会产生一个小文件
这些小文件(文件与文件之间无序,文件内部有序)为了方便计算(没必要读取N个小文件)
需要合并文件 归并算法合并成2个 相同的key都在一起
归并Reduce
将文件中的数据读取到内存中 一次性将相同的key全部读取到内存中
直接将相同的key得到结果—->最终结果
写出Output
每个reduce将自己计算的最终结果都会存放到HDFS上
Shuffle机制
- map方法之后,Reduce方法之前的数据处理过程称之为Shuffle
- MapTask收集map()方法输出的k v对,放到环形缓冲区
- 从环形缓冲区不断溢出到本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
- ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
- ReduceTask将取到的来自同一个分区不同MapTask的结果文件进行归并排序
- 合并成大文件后,shuffle过程也就结束了,进入reduce方法

若有收获,就点个赞吧
0 人点赞
