org.apache.hadoop.fs.FileSystem 抽象类
- 静态方法 创建子类对象
- static FileSystem newInstance(URI uri,Configuration conf,String user);
- URI uri:统一资源标识符 所有网络地址
- URL统一资源标识符 www.baidu.com 包括URL 迅雷下载
- 指定HDFS位置 namenode位置 hdfs://linux:8020
- Configuration conf:配置对象 空参构造方法创建 默认配置
- String user:访问资源的用户 设置为root
- URI uri:统一资源标识符 所有网络地址
- static FileSystem newInstance(URI uri,Configuration conf,String user);
常用方法
public void copyFromLocalFile(Path src,Path dst)将本地文件上传到文件系统public void copyFromLocalFile(boolean delSrc,Path src,Path dst)将本地文件上传到文件系统public void copyToLocalFile(Path src,Path dst)将文件系统上的文件下载到本地public void copyToLocalFile(boolean delSrc,Path src,Path dst)将文件系统上的文件下载到本地public FileStatus[] listStatus(Path f)列出目录下所有的内容 包括文件文件夹public RemoteIterator<LocatedFileStatus> listFile(Path f,boolean recursive)列出目录下所有的文件public FSDataOutputStream create(Path f,boolean overwrite)获取字节输出流 向文件中写数据public FSDataOutputStream append(Path path)向指定的文件路径中追加写入数据public FSDataInputStream open(Path f) 获取字节输入流 读取文件中数据
上传文件
- public void copyFromLocalFile(Path src,Path dst) 将本地文件上传到文件系统
public void copyFromLocalFile(boolean delSrc,Path src,Pathd dst)
- boolean delSrc:如果值为true则删除源文件 本地文件
- Path src:数据源文件 本地文件
Path dest:目标的文件夹 如果是文件夹 上传到对应的位置
如果是文件 则会上传并改名
下载文件
将文件系统上的文件下载到本地
- public void copyToLocalFile(Path src,Path dst)
public void copyToLocalFile(boolean delSrc,Path src,Path dst)
- boolean delSrc:是否删除源文件 值为true 会删除文件系统上的 文件
- Path src:源文件 文件系统上的文件
Path dest:目标文件 本地目标文件
文件夹:则下载到指定的文件夹下<br /> 文件:下载并改名
遍历文件
- public FileStatus[ ] listStatus(Path f)列出指定目录下所有的内容 包括文件 文件夹
- public RemoteIterator
listFiles(Path f,boolean recursive)列出目录下所有的文件 只获文件 - 方法参数
- Path f:路径
- boolean recursive:是否递归遍历 true false
- 方法返回值
- RemoteIterator 迭代器
- hasNext() 判断是否有元素
- next() 获取元素
- LocatedFileStatus 分布式文件系统上的文件对象 可以获取文件的信息 获取文件大小 副本个数 block块个数 大小等等
- Path getPath()获取路径
- long getLen()获取文件的字节数
- short getReplication()获取副本个数
- long getBlockSize()获取block块的大小
- BlockLocation[ ]getBlockLocations()获取block块数
- BlockLocation 物理切块对象
- String[ ] getHosts() 获取block块在主机的位置
- String[ ] getNames() 获取block块的名称 每个主机上的名称
- long getLenth()获取每个切块的大小
- long getOffset()获取偏移量
- RemoteIterator 迭代器
- 方法参数
写数据
- public FSDataOutputStream create(Path f,boolean overwrite)获取字节输出流 向文件中写数据
- boolean overwrite:如果文件存在 是否覆盖 true 覆盖 false不覆盖
- 追加写入
- FSDataOutputStream append(Path Path)向指定的文件路径中追加写入数据
读数据
public FSDataInputStream open(Path f)获取字节输入流 读取文件中数据
skip和seek
in.skip(1) ;跳过一个字节
- in.seek(0);指定指针标记读取
HDFS的写数据流程

- 客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- 客户端请求第一个block上传到哪几个datanode服务器上
- namenode返回3个datanode节点,分别为dn1 dn2 dn3
- 客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
- dn1 dn2 dn3逐级应答客户端
客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位
dn1收到一个packet就会传给dn2,dn2传给dn3; dn1每传一个packet会放入一个应答队列 等待应答
当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器(重复执行3-7步)
HDFS的读数据流程

- 客户端通过 请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)
客户端以Packet为单位接收,先在本地缓存,然后写入目标文件
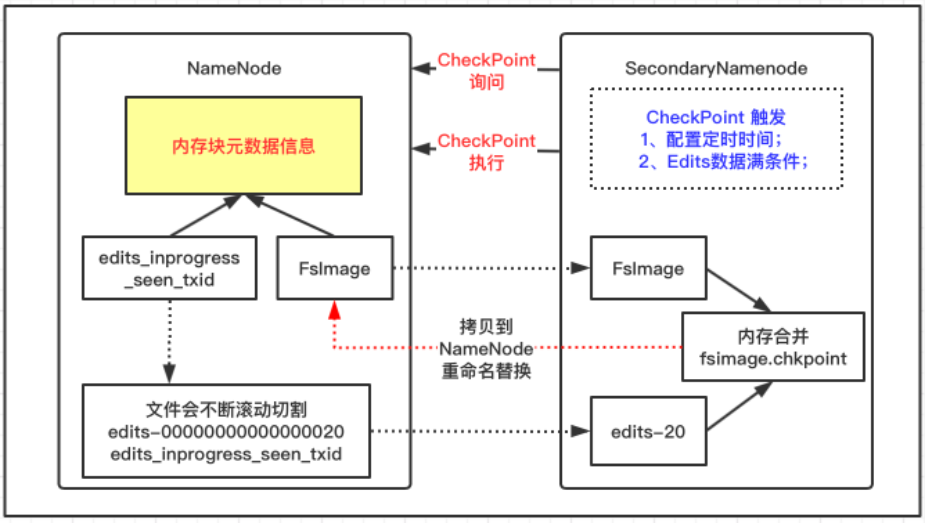
NameNode工作机制
NameNode机制
NameNode格式化启动之后,首次会创建Fsimage和Edits文件
- 非首次启动直接加载Fslmage镜像文件和Edits日志到内存中
- 客户端对元数据执行增删改操作会记录到Edits文件
-
SecondaryNameNode机制
询问NameNode是否需要CheckPoint,NameNode返回信息
- 如果需要SecondaryNameNode请求执行CheckPoint;
- NameNode切割现有日志文件,新纪录滚动写入新Edits文件
- 滚动前的编辑日志和镜像文件拷贝到SecondaryNameNode
- SecondaryNameNode加载Edits日志和Fslmage镜像文件到内存合并
- 生成新的镜像文件fsimage.chkpoint后拷贝到NameNode
- NameNode将fsimage.chkpoint重新命名成fsimage
Fsimage和Edits解析
NameNode被格式化之后,将在/opt/apps/hadoop-3.1.1/data/tmp/dfs/name/current目录中产生如下文件
- fsimage文件:HDFS文件系统元数据的一个永久性的检查点 其中包含HDFS文件系统的所有目录和文件inode的序列化信息
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
- seentxid文件保存的是一个数字 就是最后一个edits的数字
- 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的 同步的 可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并
DataNode工作机制

- DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度 校验 时间戳
- DataNode启动后向NameNode服务注册,并周期性的向NameNode上报所有的数据块元数据信息
- DataNode与NameNode之间存在心跳机制 每3秒一次 返回结果带有NameNode给该DataNode的执行命令,例如数据复制删除等,如果超过10分钟没有收到DataNode的心跳,则认为该节点不可用

若有收获,就点个赞吧
0 人点赞
