- 集合的概念
- Collection接口
- List接口与实现类
- 泛型和工具类
- Set接口与实现类
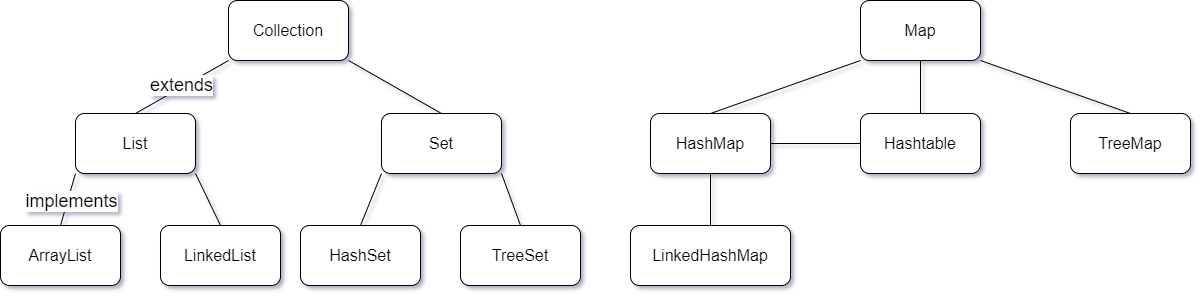
- Map接口与实现类
一、集合引入
数组与集合都是对多个数据进行内存层面存储操作的,简称为容器。 PS:持久化存储:.txt,avi,jpg,数据库
数组缺点:
- 一旦被确定了长度就不可以更改了。
- 声明了数组类型,数组中只能存放这个类型的数据
- 删除,增加元素效率低
- 数组中实际元素的数量是没有办法获取的,没有提供对应的方法或者属性来获取
集合应用场景:需要将相同结构的个体整合到一起的时候,需要集合。
二、Collection接口
Collection体系
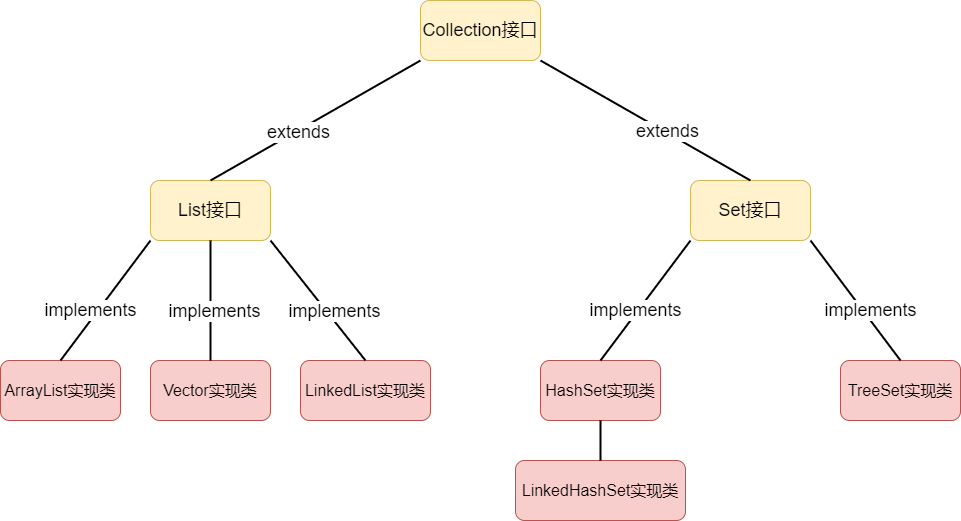
Collection接口
遍历方式:增强for循环、迭代器
LIst接口
不唯一、有序
遍历方式:普通for循环(因为有索引下标)、增强for循环、迭代器(Iterator、ListIterator)
ArrayList实现类
在JDK1.7中:在调用构造器的时候,数组初始化长度为10,扩容的时候扩展为原数组的1.5倍
在JDK1.8中:在调用空构造器的时候,数组初始化为{},在调用add()方法后,底层数组才重新赋值为新数组,新数组长度为10
JDK1.8相对于JDK1.7节省了内存,因为只有调用add方法后,才给集合赋予长度。避免了内存浪费
Vector实现类(淘汰)
ArrayList底层扩容长度为原数组的1.5倍。线程不安全、效率高
Vector底层扩容长度为原数组的2倍。线程安全、效率低
LinkedList实现类
JDK1.8:底层链表结构(双向链表结构)
Set接口
唯一、无序(无序是相对于List接口而言的,无序不是随机放置而是根据一定的”计算规则”)
遍历方式:增强for循环、迭代器
HashSet实现类
底层原理:数组+链表=哈希表
TreeSet实现类
唯一、无序(没有按照输入顺序进行输出)、升序(按照升序进行遍历)
底层的二叉树遍历是按照升序的,升序是靠二叉树中序遍历得到的。在TreeSet中放入数据的时候,自定义的类必须实现比较器
LinkedList实现类
唯一、有序(按照输入顺序进行输出)
其实就是在HashSet的基础上,多了一个总的链表,这个总链表将放入的元素串在一起,方便有序的遍历
底层原理:哈希表+链表
ArrayList源码

底层两个重要属性
- 在JDK1.7中:在调用构造器的时候给底层数组elementData初始化,数组初始化长度为10

- 在JDK1.8中:在调用空构造器的时候,底层数组elementData初始化为{}

数组扩容问题:
- 在JDK1.7中:在调用构造器的时候,数组初始化长度为10,扩容的时候扩展为原数组的1.5倍
- 在JDK1.8中:在调用空构造器的时候,数组初始化为{},在调用add()方法后,底层数组才重新赋值为新数组,新数组长度为10
JDK1.8相对于JDK1.7节省了内存,因为只有调用add方法后,才给集合赋予长度。避免了内存浪费
ArrayList与Vector
联系:
- 底层都是数组的扩容
区别:
- ArrayList底层扩容长度为原数组的1.5倍,线程不安全
- Vector底层扩容长度为原数组的2倍,线程安全

若有收获,就点个赞吧
0 人点赞
