关系型数据库的范式
第一范式
字段不可再分
- e.g.
- 我们要存储体检者的双眼视力
- 那么应该存为左眼视力和右眼视力两个字段
- 即user表应该有left_eye和right_eye
- 而不能把它们存在一个字段
- 缺点
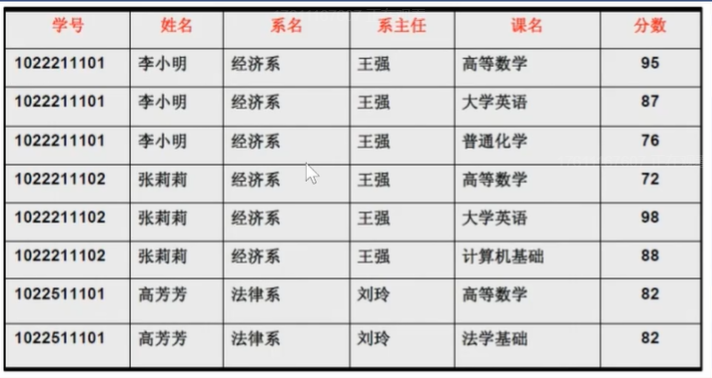
- 这是一个学生选课表,没有违反第一范式,但是存在一些问题
- 数据冗余、创建系时插入异常、删除学生会导致系消失、学生转系时改动多处
- 第一范式不够强
第二范式
在1NF的基础上,要有键(键可由多个字段组合)
所有字段分别完全依赖于键
如果键是多个字段组合,则不允许部分依赖于该键
- 依赖关系
- 给出键,就能唯一确定字段的值
- 如给出学号就能唯一确定姓名,反之则不行
- 则称姓名依赖于学号
- 不满足第二范式的地方
- 上表的键为(学号,课名)
- 但存在部分依赖:姓名依赖于学号
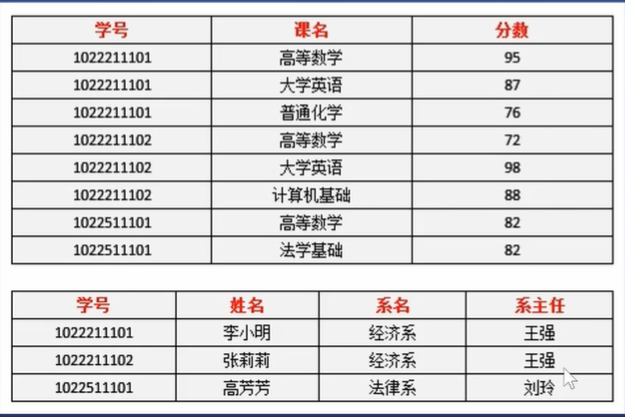
改进
解决
第一范式
- 属性不可分割
- 第二范式
- 字段完全依赖于键
- 第三范式
- 字段没有间接依赖于键
- BC范式
- 键中的属性也不存在间接依赖
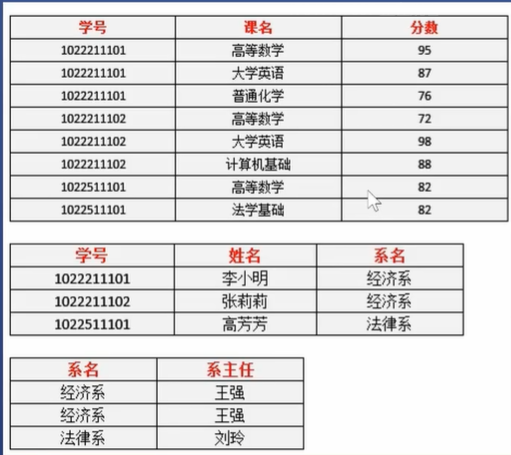
数据库设计
高内聚
- 把相关的字段放到一起,不相关的分开建表
-
低耦合
如果两个表之间有弱关系
- 一对一可放在一个表,也可以两个表加外键
- 一对多一般用外键
-
一对一
假设一个学生只能加入一个班级
可以把班级放在学生表里
- 学生 id:1001 姓名:小明 班级id:4002
- 班级 id:4002 名称:入门1班
也可以单独建立关联表
如果要把书放作者表里
- 某些DBMS支持数组,可以存两个id到一个字段
- 作者 id:1001 姓名:大牛 books:[2001,3002]
- 如果不支持数组,就不能这样做了
单独建立关系表(推介这么做)
可以把班级放在学生表
- 如果DBMS支持数组就可以放
- 不支持数据就不能
- 单独建立关系表(推荐)
- 学生 id:1001 姓名:小明
- 学生班级 id:2001 学生id:1001 班级id:4002 有效期
- 学生班级 id:2002 学生id:1001 班级id:4004 有效期
- 班级 id:4002 名称:入门1班
什么时候建关联表
当关联自身存在属性时
- 比如关联的有效期,有效期为一年
- 比如关联的级别,店铺会员分为vip1~6
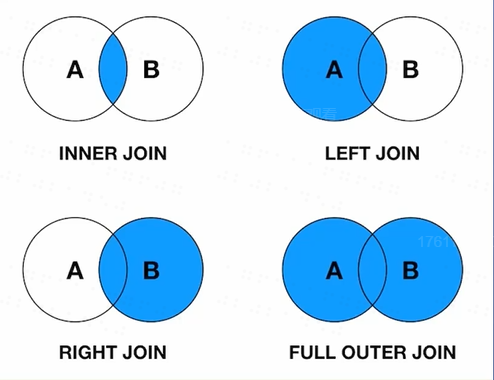
JOIN
连接表
- inner join
- left join
- 会保留右边的null,以保证左边都显示
- right join
- 会保留左边的null,以保证右边都显示
- full outer join
- 保留两边的null,以保证两边都显示
语法
把表名改为
T1 { [INNER] | {LEFT | RIGHT | FULL } [ OUTER ] } JOIN T2 ON bollean_expression
e.g.
SELECT A.PK AS A_PK,B.PK AS B_PK,A.Value AS A_Value,B.Value AS B_ValueFROM Table_A AINNER JOIN TABLE_B BON A.PK = B.PK;
试一试
启动 mysqldocker container start mysql1或者docker run --name mysql1 -e MYSQL_ROOT_PASSWORD=123456 -p 3306:3306 -d mysql:5.7.27进入 mysqldocker exec -it mysql1 bashmysql -u root -p输入密码 123456创建数据库CREATE DATABASE db1 CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;show databases;use db1;创建表create table users(id serial, name text);create table staffs(id serial, name text);create table orders(id serial, user_id bigint unsigned, staff_id bigint unsigned, amount int unsigned);创建记录insert into users (name) values ('XiaoMing');insert into staffs (name) values ('XiaoHong');insert into orders(user_id,staff_id, amount) values (1,1, 100);使用 inner joinselect users.name as uname, orders.amount as amount from users inner join orders on users.id =orders.user_id;得到 XiaoMing 100start transaction;语句1; 语句2; 语句3;commit;
缓存字段
假设一个博客blog包含多个评论commnets
如何获取博客的评论数
用户评论之后,要做两件事情
- 第一步在commnets表新增记录
- 第二步在blogs表将对应的commnet_count+1
- 如果第一步执行了,第二步没执行,数据就乱了
使用事务
start transaction;语句1; 语句2; 语句3;commit;
只要一句出错,则全部不生效
存储引擎InnoDB
命令$SHOW ENGINES;
常见的
- InnoDB 默认
- MyISAM 拥有较高的插入、查询速度、但不支持事物
- Memory 内存中,快速访问数据
- Archive 只支持insert和select
InnoDB
InnoDB是事务型数据库的首选,支持事物、遵循ACID、支持行锁和外键
索引
语法
CREATE UNIQUE INDEX index1 ON users(name(100))
show index in users;
菜鸟教程
用途
提高搜索效率
- where xxx>100那么可以创建xxx索引
- where xxx>100 and yyy>200 ,创建xxx,yyy的索引

若有收获,就点个赞吧
0 人点赞
