一、**解码器-ReplayingDecoder **
- public abstract class ReplayingDecoder extends ByteToMessageDecoder
- ReplayingDecoder扩展了ByteToMessageDecoder类,使用这个类,我们不必调用readableBytes()方法。参数S指定了用户状态管理的类型,其中Void代表不需要状态管理
- 应用实例:使用ReplayingDecoder 编写解码器,对前面的案例进行简化 [案例演示]
- ReplayingDecoder使用方便,但它也有一些局限性:
- 并不是所有的 ByteBuf 操作都被支持,如果调用了一个不被支持的方法,将会抛出一个 UnsupportedOperationException。
- ReplayingDecoder 在某些情况下可能稍慢于 ByteToMessageDecoder,例如网络缓慢并且消息格式复杂时,消息会被拆成了多个碎片,速度变慢

运行结果没有问题:
- 其它编解码器
二、Log4j 整合到Netty
- Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局)。这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出。综合使用这三个组件可以轻松地记录信息的类型和级别,并可以在运行时控制日志输出的样式和位置
- Loggers
Loggers组件在此系统中被分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,分别用来指定这条日志信息的重要程度,明白这一点很重要,Log4j有一个规则:只输出级别不低于设定级别的日志信息,假设Loggers级别设定为INFO,则INFO、WARN、ERROR和FATAL级别的日志信息都会输出,而级别比INFO低的DEBUG则不会输出。
log4j.rootLogger = [ level ] , appenderName1, appenderName2, …(默认输出目的地,当前端传入类名)
log4j.additivity.org.apache=false:表示Logger不会在父Logger的appender里输出,默认为true。
level :设定日志记录的最低级别,可设的值有OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL或者自定义的级别,Log4j建议只使用中间四个级别。通过在这里设定级别,您可以控制应用程序中相应级别的日志信息的开关,比如在这里设定了INFO级别,则应用程序中所有DEBUG级别的日志信息将不会被打印出来。
appenderName:就是指定日志信息要输出到哪里。可以同时指定多个输出目的地,用逗号隔开。
例如:log4j.rootLogger=INFO,A1,B2,C3
- Appenders
禁用和使用日志请求只是Log4j的基本功能,Log4j日志系统还提供许多强大的功能,比如允许把日志输出到不同的地方,如控制台(Console)、文件(Files)等,可以根据天数或者文件大小产生新的文件,可以以流的形式发送到其它地方等等。
- 常使用的类如下:
org.apache.log4j.ConsoleAppender(控制台)
org.apache.log4j.FileAppender(文件)
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
- 配置模式:
log4j.appender.appenderName = className
log4j.appender.appenderName.Option1 = value1
…
log4j.appender.appenderName.OptionN = valueN
- 配置日志信息输出目的地(appender):
log4j.appender.appenderName = className
appenderName:自定义appderName,在log4j.rootLogger设置中使用;
className:可设值如下:
- org.apache.log4j.ConsoleAppender(控制台)- org.apache.log4j.FileAppender(文件)- org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)- org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)- org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
(1)ConsoleAppender选项:
Threshold=WARN:指定日志信息的最低输出级别,默认为DEBUG。
ImmediateFlush=true:表示所有消息都会被立即输出,设为false则不输出,默认值是true。
Target=System.err:默认值是System.out。
(2)FileAppender选项:
Threshold=WARN:指定日志信息的最低输出级别,默认为DEBUG。
ImmediateFlush=true:表示所有消息都会被立即输出,设为false则不输出,默认值是true。
Append=false:true表示消息增加到指定文件中,false则将消息覆盖指定的文件内容,默认值是true。
File=D:/logs/logging.log4j:指定消息输出到logging.log4j文件中。
(3)DailyRollingFileAppender选项:
Threshold=WARN:指定日志信息的最低输出级别,默认为DEBUG。
ImmediateFlush=true:表示所有消息都会被立即输出,设为false则不输出,默认值是true。
Append=false:true表示消息增加到指定文件中,false则将消息覆盖指定的文件内容,默认值是true。
File=D:/logs/logging.log4j:指定当前消息输出到logging.log4j文件中。
DatePattern=’.’yyyy-MM:每月滚动一次日志文件,即每月产生一个新的日志文件。当前月的日志文件名为logging.log4j,前一个月的日志文件名为logging.log4j.yyyy-MM。
另外,也可以指定按周、天、时、分等来滚动日志文件,对应的格式如下:
1)’.’yyyy-MM:每月
2)’.’yyyy-ww:每周
3)’.’yyyy-MM-dd:每天
4)’.’yyyy-MM-dd-a:每天两次
5)’.’yyyy-MM-dd-HH:每小时
6)’.’yyyy-MM-dd-HH-mm:每分钟
(4)RollingFileAppender选项:
Threshold=WARN:指定日志信息的最低输出级别,默认为DEBUG。
ImmediateFlush=true:表示所有消息都会被立即输出,设为false则不输出,默认值是true。
Append=false:true表示消息增加到指定文件中,false则将消息覆盖指定的文件内容,默认值是true。
File=D:/logs/logging.log4j:指定消息输出到logging.log4j文件中。
MaxFileSize=100KB:后缀可以是KB, MB 或者GB。在日志文件到达该大小时,将会自动滚动,即将原来的内容移到logging.log4j.1文件中。
MaxBackupIndex=2:指定可以产生的滚动文件的最大数,例如,设为2则可以产生logging.log4j.1,logging.log4j.2两个滚动文件和一个logging.log4j文件。
- Layout
有时用户希望根据自己的喜好格式化自己的日志输出,Log4j可以在Appenders的后面附加Layouts来完成这个功能。Layouts提供四种日志输出样式,如根据HTML样式、自由指定样式、包含日志级别与信息的样式和包含日志时间、线程、类别等信息的样式。
常使用的类如下:
org.apache.log4j.HTMLLayout(以HTML表格形式布局)
org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等信息)
配置模式:
log4j.appender.appenderName.layout =className
log4j.appender.appenderName.layout.Option1 = value1
…
log4j.appender.appenderName.layout.OptionN = valueN
log4j.appender.appenderName.layout=className
className:可设值如下:
- org.apache.log4j.HTMLLayout(以HTML表格形式布局)
- org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
- org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
- org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
(1)HTMLLayout选项:
LocationInfo=true:输出java文件名称和行号,默认值是false。
Title=My Logging: 默认值是Log4J Log Messages。
(2)PatternLayout选项:
ConversionPattern=%m%n:设定以怎样的格式显示消息。
格式化符号说明:
%p:输出日志信息的优先级,即DEBUG,INFO,WARN,ERROR,FATAL。
%d:输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,如:%d{yyyy/MM/dd HH:mm:ss,SSS}。
%r:输出自应用程序启动到输出该log信息耗费的毫秒数。
%t:输出产生该日志事件的线程名。
%l:输出日志事件的发生位置,相当于%c.%M(%F:%L)的组合,包括类全名、方法、文件名以及在代码中的行数。例如:test.TestLog4j.main(TestLog4j.java:10)。
%c:输出日志信息所属的类目,通常就是所在类的全名。
%M:输出产生日志信息的方法名。
%F:输出日志消息产生时所在的文件名称。
%L::输出代码中的行号。
%m::输出代码中指定的具体日志信息。
%n:输出一个回车换行符,Windows平台为”rn”,Unix平台为”n”。
%x:输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%:输出一个”%”字符。
另外,还可以在%与格式字符之间加上修饰符来控制其最小长度、最大长度、和文本的对齐方式。如:
1) c:指定输出category的名称,最小的长度是20,如果category的名称长度小于20的话,默认的情况下右对齐。
2)%-20c:”-“号表示左对齐。
3)%.30c:指定输出category的名称,最大的长度是30,如果category的名称长度大于30的话,就会将左边多出的字符截掉,但小于30的话也不会补空格。
- 参考博客:https://www.cnblogs.com/wangzhuxing/p/7753420.html
- 在Maven 中添加对Log4j的依赖
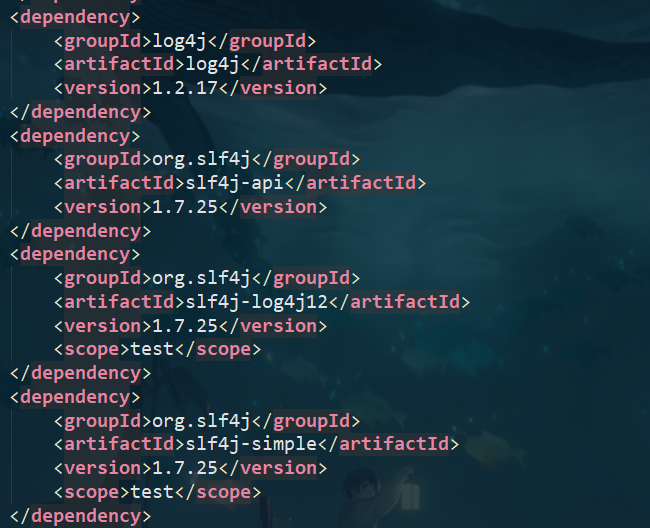
添加完以来后记得修改以下两个地方:
- 在 pom.xml 配置 Log4j , 在 resources/log4j.properties
三、TCP 粘包和拆包基本介绍
- TCP是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发给接收端的包,更有效的发给对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样做虽然提高了效率,但是接收端就难于分辨出完整的数据包了,因为面向流的通信是无消息保护边界的 。
- 由于TCP无消息保护边界, 需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题, 看一张图
- TCP粘包、拆包图解:

假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下四种情况:
- 服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包
- 服务端一次接受到了两个数据包,D1和D2粘合在一起,称之为TCP粘包
- 服务端分两次读取到了数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这称之为TCP拆包
- 服务端分两次读取到了数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余部分内容D1_2和完整的D2包。
- 在编写Netty 程序时,如果没有做处理,就会发生粘包和拆包的问题 ,如图:

- TCP 粘包和拆包解决方案
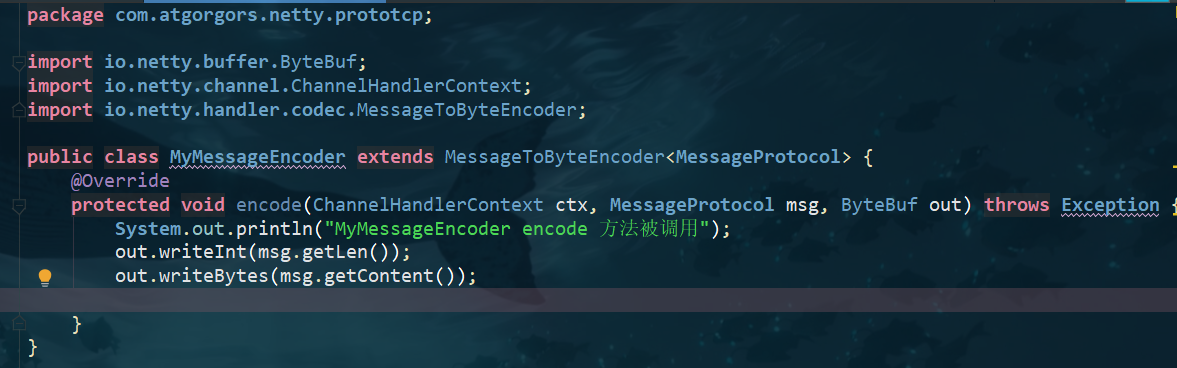
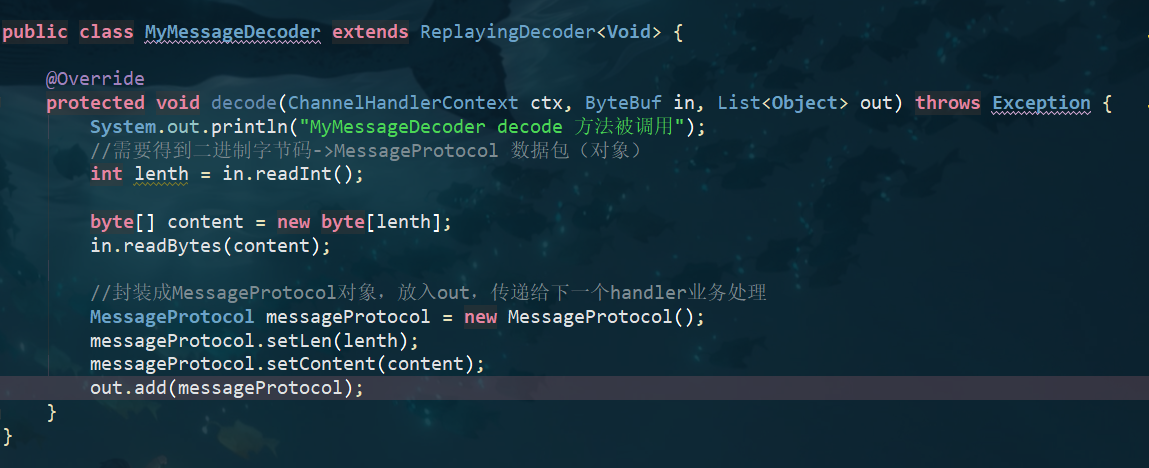
- 使用自定义协议 + 编解码器 来解决
- 关键就是要解决 服务器端每次读取数据长度的问题, 这个问题解决,就不会出现服务器多读或少读数据的问题,从而避免的TCP 粘包、拆包 。
- 看一个具体的实例:
- 要求客户端发送 5 个 Message 对象, 客户端每次发送一个 Message 对象
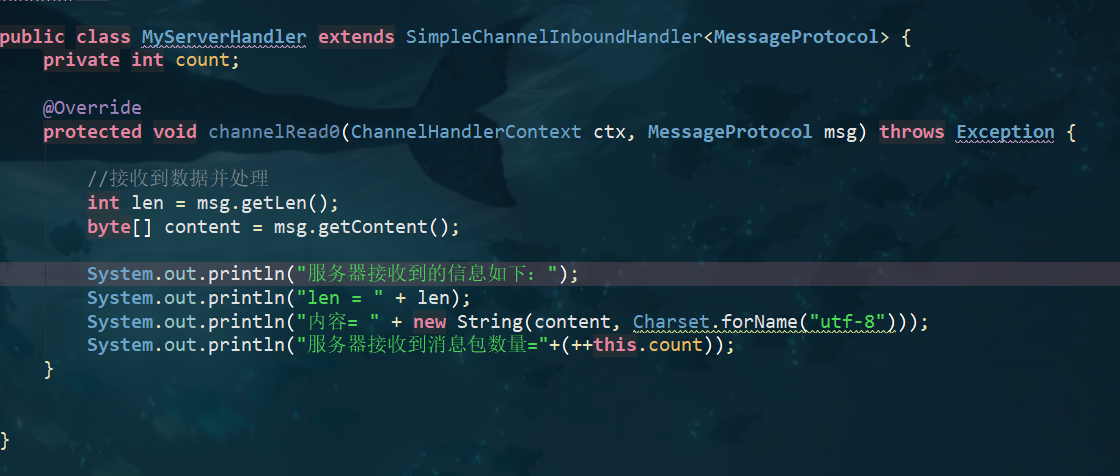
- 服务器端每次接收一个Message, 分5次进行解码, 每读取到 一个Message , 会回复一个Message 对象 给客户端。
- 客户端发送消息


运行结果:

b. 服务器回送消息
四、RPC远程调用
- RPC(Remote Procedure Call)— 远程过程调用,是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程
- 两个或多个应用程序都分布在不同的服务器上,它们之间的调用都像是本地方法调用一样(如图)

- 常见的 RPC 框架有: 比较知名的如阿里的Dubbo、google的gRPC、Go语言的rpcx、Apache的thrift, Spring 旗下的 Spring Cloud。

- RPC调用流程图 :
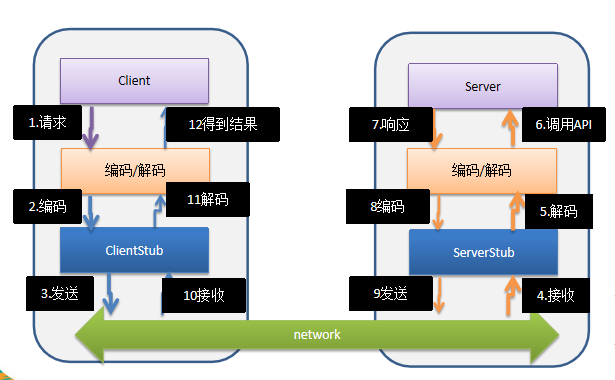
术语说明:在RPC 中, Client 叫服务消费者,Server 叫服务提供者
- PRC调用流程说明
- 服务消费方(client)以本地调用方式调用服务
- client stub 接收到调用后负责将方法、参数等封装成能够进行网络传输的消息体
- client stub 将消息进行编码并发送到服务端
- server stub 收到消息后进行解码
- server stub 根据解码结果调用本地的服务
- 本地服务执行并将结果返回给 server stub
- server stub 将返回导入结果进行编码并发送至消费方
- client stub 接收到消息并进行解码
- 服务消费方(client)得到结果 小结:RPC 的目标就是将 2-8 这些步骤都封装起来,用户无需关心这些细节,可以像调用本地方法一样即可完成远程服务调用。
- Dubbo
(读音[ˈdʌbəʊ])是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
- 自己实现 dubbo RPC(基于Netty)
- 需求说明:
dubbo 底层使用了 Netty 作为网络通讯框架,要求用 Netty 实现一个简单的 RPC 框架
模仿 dubbo,消费者和提供者约定接口和协议,消费者远程调用提供者的服务,提供者返回一个字符串,消费者打印提供者返回的数据。
底层网络通信使用 Netty 4.1.20
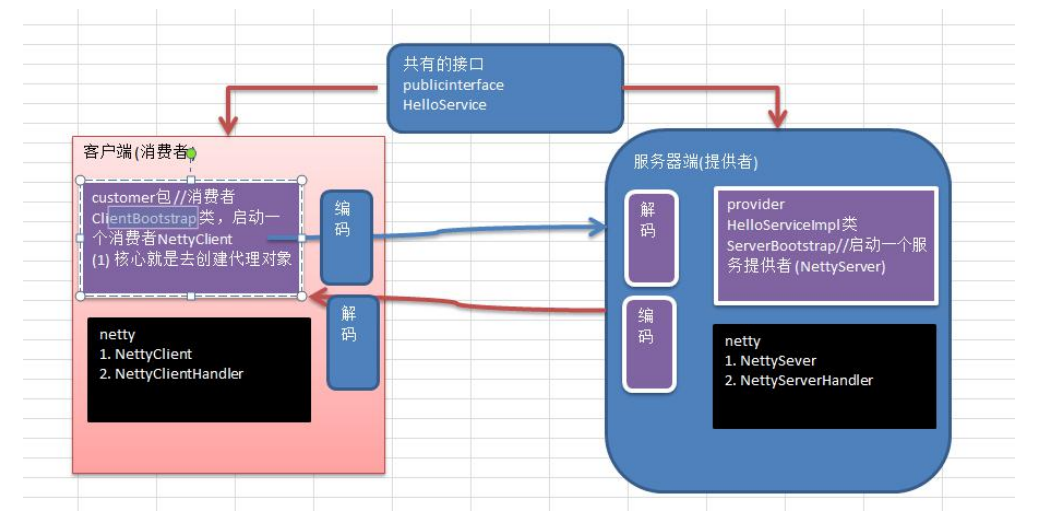
- 设计说明:
创建一个接口,定义抽象方法。用于消费者和提供者之间的约定。 创建一个提供者,该类需要监听消费者的请求,并按照约定返回数据。 创建一个消费者,该类需要透明的调用自己不存在的方法,内部需要使用 Netty 请求提供者返回数据
- 开发分析图:
- 代码实现
新建包dubborpc.publicinterface,新建一个接口HelloService:
package com.atgorgors.netty.dubborpc.publicinterface;public interface HelloService {String hello(String msg);}
新建包dubborpc.provider,新建类HelloServiceImpl、ServerBootStrap:
package com.atgorgors.netty.dubborpc.provider;import com.atgorgors.netty.dubborpc.publicinterface.HelloService;public class HelloServiceImpl implements HelloService {//当有消费方调用该方法时,就返回一个结果@Overridepublic String hello(String msg) {System.out.println("msg = " + msg);//根据msg返回不同的结果if (msg !=null){return "你好客户端,我已经收到你的消息 [" + msg +"]";}else {return "你好,我已经收到你的消息";}}}
package com.atgorgors.netty.dubborpc.provider;import com.atgorgors.netty.dubborpc.netty.NettyServer;//启动一个服务提供者,就是NettyServerpublic class ServerBootstrap {public static void main(String[] args) {NettyServer.startServer("127.0.0.1",7000);}}
新建包dubborpc.netty,新建类NettyServer、NettyServerHandler:
package com.atgorgors.netty.dubborpc.netty;import io.netty.bootstrap.ServerBootstrap;import io.netty.channel.ChannelFuture;import io.netty.channel.ChannelInitializer;import io.netty.channel.ChannelPipeline;import io.netty.channel.EventLoopGroup;import io.netty.channel.nio.NioEventLoopGroup;import io.netty.channel.socket.SocketChannel;import io.netty.channel.socket.nio.NioServerSocketChannel;import io.netty.handler.codec.string.StringDecoder;import io.netty.handler.codec.string.StringEncoder;public class NettyServer {public static void startServer(String hostname, int port){startServer0(hostname, port);}//编写写一个方法,完成NettyServer的初始化和启动private static void startServer0(String hostname, int port){EventLoopGroup bossgroup = new NioEventLoopGroup();EventLoopGroup workergroup = new NioEventLoopGroup();try {ServerBootstrap serverBootstrap = new ServerBootstrap();serverBootstrap.group(bossgroup,workergroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ChannelPipeline pipeline = ch.pipeline();pipeline.addLast(new StringEncoder());pipeline.addLast(new StringDecoder());pipeline.addLast(null);}});ChannelFuture channelFuture = serverBootstrap.bind(hostname, port);channelFuture.sync();System.out.println("服务提供方开始提供服务...");channelFuture.channel().closeFuture().sync();} catch (InterruptedException e) {e.printStackTrace();} finally {bossgroup.shutdownGracefully();workergroup.shutdownGracefully();}}}
package com.atgorgors.netty.dubborpc.netty;import com.atgorgors.netty.dubborpc.provider.HelloServiceImpl;import io.netty.channel.ChannelHandlerContext;import io.netty.channel.ChannelInboundHandlerAdapter;//服务器端的handler比较简单public class MyServerHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {//获取客户端发送的消息并调用我们的服务System.out.println("msg = " + msg);//客户端在调用服务器的api时,我们要定义一个协议//比如我们要求每次发消息时都必须以某个字符串开头 "HelloService#hello#"if (msg.toString().startsWith("HelloService#hello#")){String result = new HelloServiceImpl().hello(msg.toString().substring(msg.toString().lastIndexOf("#") + 1));ctx.writeAndFlush(result);}}@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {ctx.close();}}

若有收获,就点个赞吧
0 人点赞
