Java 集合类是用途广泛的工具类,可用于存储数量不等的对象,并可以实现常用的数据结构。Java 集合大致分为 Set、List、Map 和 Queue 四种体系
Set代表无序、不可重复的集合List代表有序、可重复的集合Map代表具有key-value键值映射关系的集合-
数组和集合的区别
Java提供了数组数据类型,可以充当集合,为何还需要其他集合类?因为数组存在很多使用限制: 数组初始化后大小不可变
- 数组无法保存具有映射关系的数据
- 数组只能按索引顺序存取
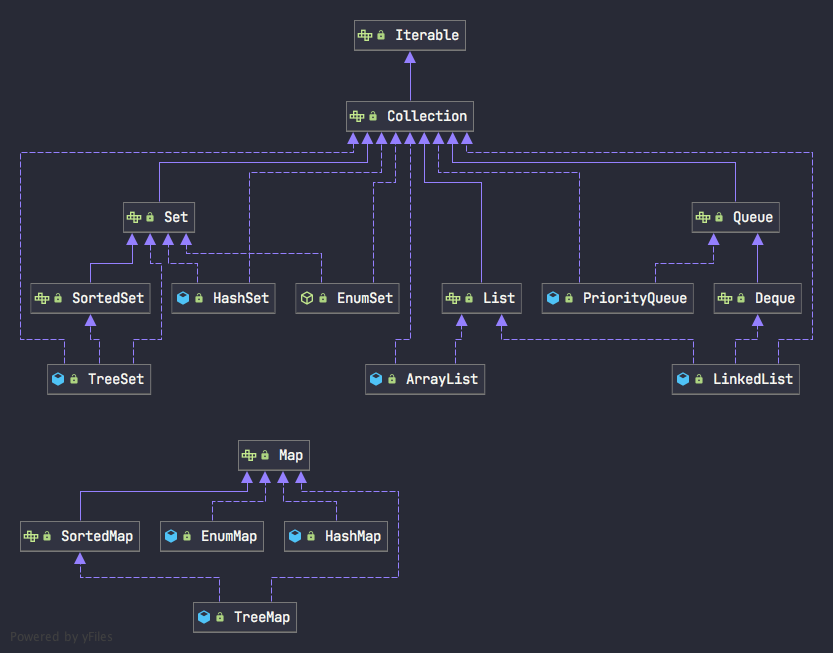
Java 集合 UML 继承树
List 集合
List是最基础的集合,List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合默认按元素的添加顺序设置元素的索引,索引从 0 开始,可以通过索引来访问指定位置的集合元素。ArrayList
ArrayList是最常用的有序列表。ArrayList是基于数组实现的List接口,它内部封装了一个动态的、允许再分配的Object[]数组,当向ArrayList中添加元素超出了该数组的长度时,其内部Object[]数组会先进行扩容,每次扩容增加原来的一半大小,扩容将原数组中的所有元素拷贝到新数组后再添加新元素。ArrayList 和 数组扩容区别
从一个已有的数组{'A', 'B', 'C', 'D', 'E'}中删除索引为 2 的元素:
这个“删除”操作实际上是把┌───┬───┬───┬───┬───┬───┐│ A │ B │ C │ D │ E │ │└───┴───┴───┴───┴───┴───┘│ │┌───┘ ││ ┌───┘│ │▼ ▼┌───┬───┬───┬───┬───┬───┐│ A │ B │ D │ E │ │ │└───┴───┴───┴───┴───┴───┘
'C'后面的元素依次往前挪一个位置,而“添加”操作实际上是把指定位置以后的元素都依次向后挪一个位置,腾出来的位置给新加的元素。删除和添加两种操作用数组实现非常麻烦。ArrayList把内部数组添加和删除的操作进行封装,操作List类似于操作数组,却不用关心内部元素如何移动,其原理简介如下:
一个ArrayList拥有 5 个元素,实际Object[]数组大小为 6 (即保留一个空位):
当添加一个元素并指定索引到size=5┌───┬───┬───┬───┬───┬───┐│ A │ B │ C │ D │ E │ │└───┴───┴───┴───┴───┴───┘
ArrayList时,ArrayList自动移动需要的元素:
然后,往内部指定索引的数组位置添加一个元素,然后把size=5┌───┬───┬───┬───┬───┬───┐│ A │ B │ │ C │ D │ E │└───┴───┴───┴───┴───┴───┘
size + 1:
继续向size=6┌───┬───┬───┬───┬───┬───┐│ A │ B │ F │ C │ D │ E │└───┴───┴───┴───┴───┴───┘
ArrayList中添加元素,但是数组已满,没有空闲位置的时候,ArrayList先创建一个更大的新数组,新数组大小为原数组length/2 + 1,然后把原数组的所有元素复制到新数组,再用新数组取代原数组,执行扩容后继续添加一个元素到数组末尾,同时size + 1:size=7┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐│ A │ B │ F │ C │ D │ E │ G │ │ │ │└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
LinkedList
LinkeList是通过“链表”实现List接口,在LinkedList中,它内部的每个元素都指向下一个元素:┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
LinkedList还实现了Deque接口,提供双向队列,栈的功能ArrayList 和 LinkedList 区别
是否保证线程安全?
ArrayList和LinkedList都是不同步的,也就是不保证线程安全;底层数据结构有何区别?
ArrayList底层使用的是Object[]数组;LinkedList底层使用的是双向链表数据结构插入和删除是否受元素位置的影响?
ArrayList采用数组存储,插入和删除元素的时间复杂度受元素位置的影响。例如:指向add(E e)方法时,ArrayList默认将指定元素追加到此列表的末尾,这种情况时间复杂度为O(1)。但如果要在指定位置i处插入和删除元素时add(int index,E e),因为在执行上述操作时集合中第i和 第i个元素之后的n-i个元素都要执行向后或向前位移一位的操作,时间复杂度为O(n-i)。LinkedList采用链表存储,对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响近似为O(1),如果是要在指定位置i插入和删除元素时add(int index,E e),因为需要先移动到指定个位置后在插入,时间复杂度近似为O(n)是否支持快速随机访问?
快速随机访问是指通过元素的序号快速获取元素对于get(int index)方法。LinkedList不支持高效的随机元素访问,而ArrayList支持。内存空间占用区别?
ArrayList的空间浪费主要体现在List列表的尾部会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArayList中元素更多的空间,每个元素都要存放直接后继(后一个)和直接前驱(前一个)以及数据
通常情况下,总是优先使用ArrayList
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除元素 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
List 和 Array 转换
第一种:调用 toArray() 方法直接返回一个 Object[] 数组
public class Main {public static void main(String[] args) {List<String> list = List.of("apple", "pear", "banana");Object[] array = list.toArray();for (Object s : array) {System.out.println(s);}}}
第二种:调用 toArray(T[]) 方法传入一个类型相同的 Array,List 内部自动把元素复制到传入的 Array 中
public class Main {public static void main(String[] args) {List<Integer> list = List.of(12, 34, 56);Integer[] array = list.toArray(new Integer[3]);for (Integer n : array) {System.out.println(n);}}}
第三种:通过 List 接口定义的 T[] toArray(IntFuntion<T[]> generator) 方法
Integer[] array = list.toArray(Integer[]::new);
Array 转 List 通过 List.of(T...) 方法
Integer[] array = { 1, 2, 3 };List<Integer> list = List.of(array);// 注意,返回的 List 不是 ArrayList 实现类,而是 Arrays 的内部类 ArrayList。并且返回的是只读的List<Integer> list = Arrays.asList(array);
equals() 方法
在 List 中查找元素时,List 接口的实现类通过元素的 equals() 方法比较两个元素是否相等,因此,放入的元素必须正确覆写 equals() 方法,Java 标准库提供的 String、Integer 等已经覆写了 equals() 方法
public class Main {public static void main(String[] args) {List<String> list = List.of("A", "B", "C");System.out.println(list.contains(new String("C"))); // trueSystem.out.println(list.indexOf(new String("C"))); // 2List<Person> list = List.of(new Person("Xiao Ming"),new Person("Xiao Hong"),new Person("Bob"));System.out.println(list.contains(new Person("Bob"))); // false}}class Person {String name;public Person(String name) {this.name = name;}}
Set 集合
Set 集合不允许包含相同的元素,如果视图把两个相同的元素加入同一个 Set 集合中,则添加操作失败,add() 方法返回 false,且新元素不会被加入。Set 集合多用于去除重复元素
public class Main {public static void main(String[] args) {Set<String> set = new HashSet<>();System.out.println(set.add("abc")); // trueSystem.out.println(set.add("xyz")); // trueSystem.out.println(set.add("xyz")); // false,添加失败,因为元素已存在System.out.println(set.contains("xyz")); // true,元素存在System.out.println(set.contains("XYZ")); // false,元素不存在System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在System.out.println(set.size()); // 2,一共两个元素}}
HashSet
HashSet 是 Set 接口的典型实现。当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据该 hashCode 值决定该对象在 HashSet 中的存储位置。
当把某个类的对象放入
HashSet集合中时,重写该对象对应类的equals()方法和hashCode()方法时,应该尽量保证两个对象通过equals()方法比较返回true时,它们的hashCode()方法返回值也相等。
观察 HashSet 源码可发现 HashSet 仅仅是对 HashMap 的一个简单封装,它的核心代码如下:
public class HashSet<E> implements Set<E> {// 持有一个HashMap:private transient HashMap<E, Object> map;// 放入HashMap的value:private static final Object PRESENT = new Object();public HashSet() {map = new HashMap<>();}public boolean add(E e) {return map.put(e, PRESENT) == null;}public boolean contains(Object o) {return map.containsKey(o);}public boolean remove(Object o) {return map.remove(o) == PRESENT;}}
TreeSet
Set 接口并不保证有序,而 SortedSet 接口则保证元素是有序的。TreeSet 集合实现了 SortedSet 接口,TreeSet 采用红黑树的数据结构来存储集合元素。TreeSet 支持两种排序方法:自然排序和定制排序。在默认情况下,TreeSet 采用自然排序
Comparable 比较接口
Java 提供了 Comparable 接口,它负责比较传入的两个元素 a 和 b,如果 a<b,则返回 -1,如果 a==b,则返回 0,如果 a>b,则返回 1。String、Integer 等常见类型已经实现了 Comparable 接口,JDK 也为常见类型提供了内置比较器
Set<Integer> demoBeans = new TreeSet<>(Comparator.comparingInt(q -> q));
HashSet 和 TreeSet 区别
HashSet 和 TreeSet 是 Set 的两个典型实现,而 HashSet 的性能总是比 TreeSet 好,尤其是最常用的添加、查询元素等操作。TreeSet 需要额外的红黑树算法来维护集合元素的次序。只有当需要一个保持排序的 Set 时,才应该使用 TreeSet,否则都应该使用 HashSet。
Map 集合
Map<K,V> 是一种键-值映射表,当调用 put(K key,V value) 方法时,就把 key 和 value 做了映射并放入 Map。当调用 V get(K key) 方法时,通过 key 获取到对应的 value。如果 key 不存在,则返回 null。
调用
put()方法插入Map时,若放入的key已经存在,put()方法会返回被删除的旧的value,否则返回null。Map中不存在重复的key,因为放入相同的key,只会把原油的key-value对应的value给替换掉
遍历 Map
- 仅遍历
Map中的key可使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合 - 同时遍历
key和value可使用for each循环遍历Map实例的entrySet()集合,它包含每一个key-value映射遍历
Map集合时,不可假设输出的key是有序的,Map不保证顺序
HashMap
HashMap 内部通过空间换时间的方法,用一个大数组存储所有 value,并根据 key 直接计算出 value 应用存储在哪个索引:
Map<String, Person> map = new HashMap<>();map.put("a", new Person("Xiao Ming"));map.put("b", new Person("Xiao Hong"));map.put("c", new Person("Xiao Jun"));map.get("a"); // Person("Xiao Ming")map.get("x"); // null
┌───┐0 │ │├───┤1 │ ●─┼───> Person("Xiao Ming")├───┤2 │ │├───┤3 │ │├───┤4 │ │├───┤5 │ ●─┼───> Person("Xiao Hong")├───┤6 │ ●─┼───> Person("Xiao Jun")├───┤7 │ │└───┘
equals() 和 hashCode()
在 HashMap 内部,对 key 做比较是通过 equals() 方法实现的,如果传入的 key 的内容相同但对象不同时,两个不同对象的 key 可能获取到的 value 是一样的
public class Main {public static void main(String[] args) {String key1 = "a";Map<String, Integer> map = new HashMap<>();map.put(key1, 123);String key2 = new String("a");map.get(key2); // 123System.out.println(key1 == key2); // falseSystem.out.println(key1.equals(key2)); // true}}
为避免上述情况发生,正确使用
Map必须保证:
- 要求作为
key的对象必须正确覆写equals()方法,相等的两个key实例的 equals()必须返回true。常用的String类型默认已经覆写了equals()方法。- 如果两个对象相等,则两个对象的 hashCode() 必须相等
- 如果两个对象不相等,则两个对象的 hashCode 尽量不要相等
Q:HashMap 内部使用了数组,并通过计算 key 的 hashCode() 直接定位 value 所在的索引,hashCode() 方法返回的 int 范围高达 ±21 亿,HashMap 内部使用的数组大小如何确定的?
A:观察 HashMap 源码,HaspMap 初始化时默认的数组大小只有 16 位。往 HashMap 中插入任何 key ,无论它的 hashCode() 结果多大,计算出的索引范围一定在 0~15
public class HashMap<K,V> {static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16}int index = key.hashCode() & 0xf; // 0xf = 15
Q:如果添加超过 16 个元素到 HashMap 中是,内部数组不够用时如何扩容?
A:HashMap 中添加超过一定数量的元素时,HashMap 会在内部自动扩容,每次扩容一倍,即长度为 16 的数组扩容为 32。大小扩容后会重新计算 hashCode() 方法生成新的索引位置。
int index = key.hashCode() & 0x1f; // 0x1f = 31
Q:如果两个不同的 key,如 "a" 和 "b",假设它们的 hashCode() 恰好是相同的,此时往 Map 中分别插入两个元素会造成覆盖吗?
A:结果是不会造成覆盖。使用 Map 时,只要 key 不相同,它们的 value 就互不干扰。在 HashMap 内部数组中使用 List 存储 value。假设两者计算得到索引为 5,List 中将包含两个 Entry,一个是 "a" 的映射,另一个是 "b" 的映射
┌───┐0 │ │├───┤1 │ │├───┤2 │ │├───┤3 │ │├───┤4 │ │├───┤5 │ ●─┼───> List<Entry<String, Person>>├───┤6 │ │├───┤7 │ │└───┘
EnumMap
如果作为 key 的对象是 enum 类型,最佳实践是使用 EnumMap,它在内部以一个非常紧凑的数组存储 value,并且根据 enum 类型的 key 直接定位到内部数组的索引,并不需要计算 hashCode(),不但效果高,而且没有额外的空间浪费
public class Main {public static void main(String[] args) {Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);map.put(DayOfWeek.MONDAY, "星期一");map.put(DayOfWeek.TUESDAY, "星期二");map.put(DayOfWeek.WEDNESDAY, "星期三");map.put(DayOfWeek.THURSDAY, "星期四");map.put(DayOfWeek.FRIDAY, "星期五");map.put(DayOfWeek.SATURDAY, "星期六");map.put(DayOfWeek.SUNDAY, "星期日");System.out.println(map);System.out.println(map.get(DayOfWeek.MONDAY));}}
TreeMap
TreeMap 实现了排序键值对接口 SortedMap 接口,保证遍历 Map 时按 key 的顺序进行排序。String 类型默认字母排序
public class Main {public static void main(String[] args) {Map<String, Integer> map = new TreeMap<>();map.put("orange", 1);map.put("apple", 2);map.put("pear", 3);for (String key : map.keySet()) {System.out.println(key);}// apple, orange, pear}}
SortedMap 要求作为 key 的对象必须实现 Comparable 接口或者传入 Comparator 实例,并且实现方案必须严格遵循 compare() 规范,否则将不能正常工作
public class Main {public static void main(String[] args) {Map<Student, Integer> map = new TreeMap<>(new Comparator<Student>() {public int compare(Student p1, Student p2) {return p1.score > p2.score ? -1 : 1;}});map.put(new Student("Tom", 77), 1);map.put(new Student("Bob", 66), 2);map.put(new Student("Lily", 99), 3);for (Student key : map.keySet()) {System.out.println(key);}System.out.println(map.get(new Student("Bob", 66))); // null。因为 compare 在两者相等时没有返回 0}}class Student {public String name;public int score;Student(String name, int score) {this.name = name;this.score = score;}public String toString() {return String.format("{%s: score=%d}", name, score);}}
Properties
读取配置文件类,是特殊的键值对集合,它内部继承了 Hashtable
典型的配置文件如下:
# setting.propertieslast_open_file=/data/hello.txtauto_save_interval=60
使用 Properties 读取配置文件:
String f = "setting.properties";Properties props = new Properties();// 1.从文件系统中读取props.load(new java.io.FileInputStream(f));// 2.从 classpath 中读取props.load(getClass().getResourceAsStream("/common/setting.properties"));// 3.使用 Reader 指定编码格式读取props.load(new FileReader("settings.properties", StandardCharsets.UTF_8));String filepath = props.getProperty("last_open_file");String interval = props.getProperty("auto_save_interval", "120");
使用 Properties 写入配置文件:
Properties props = new Properties();props.setProperty("url", "http://www.liaoxuefeng.com");props.setProperty("language", "Java");props.store(new FileOutputStream("C:\\conf\\setting.properties"), "这是写入的properties注释");
Queue
“先进先出”(FIFO:First In First Out)队列,Queue 与其他容器不同,它仅有两个操作:
- 把元素添加到队列末尾
- 从队列头部取出元素
超市的收银台就是一个典型的队列:
对于具体的实现类,有的Queue有最大队列长度限制,有的 Queue 没有。注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。我们用一个表格总结如下:
| throw Exception | 返回false或null | |
|---|---|---|
| 添加元素到队尾 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
从 Queue 中添加和取出元素示例代码:
public static void main(String[] args) {Queue<String> queue = new ArrayDeque<>();queue.offer("1");queue.offer("2");queue.offer("3");queue.offer("4");queue.offer("5");queue.offer("6");boolean hasNext = true;do {final String poll = queue.poll();log.debug(poll);hasNext = StrUtil.isNotEmpty(poll);} while (hasNext);}// 依次输出// 1 2 3 4 5 6
PriorityQueue
PriorityQueue 优先队列实现了 Queue 接口,Queue 队列只能按入列顺序逐个取出元素,而 PriorityQueue 队列的出队顺序与元素的优先级有关,调用 remove() 或 poll() 方法返回的总是优先级最高的元素PriorityQueue 默认按元素比较的顺序排序,也可以通过 Comparator 自定义排算法
public static void main(String[] args) {// 按照大小,较小的在前面final Queue<Integer> priorityQueue = new PriorityQueue<>(Comparator.comparingInt(s -> s));priorityQueue.offer(6);priorityQueue.offer(5);priorityQueue.offer(4);priorityQueue.offer(3);priorityQueue.offer(2);priorityQueue.offer(1);do {final Integer poll = priorityQueue.poll();if (poll == null) {break;}log.debug(poll.toString());} while (true);}// 依次输出// 1 2 3 4 5 6
Deque
Queue 队列只能一头进,另一头出。而 Deque 队列允许两头都进,两头都出,称之为双向对列
- 既可以添加到队尾,也可以添加到对首
- 既可以从对首获取,又可以从队尾获取
Deque 和 Queue 出对和入队的区别
| Queue | Deque | |
|---|---|---|
| 添加元素到队尾 | add(E e) / offer(E e) | addLast(E e) / offerLast(E e) |
| 取队首元素并删除 | E remove() / E poll() | E removeFirst() / E pollFirst() |
| 取队首元素但不删除 | E element() / E peek() | E getFirst() / E peekFirst() |
| 添加元素到队首 | 无 | addFirst(E e) / offerFirst(E e) |
| 取队尾元素并删除 | 无 | E removeLast() / E pollLast() |
| 取队尾元素但不删除 | 无 | E getLast() / E peekLast() |
Stack
Stack 栈是一种后进先出的数据结构,只能不断的往 Stack 中压入 push 元素,最后进去的元素必须最早弹出 pop。Java 集合类中没有单独的 Stack 接口,使用 Deque 接口来“模拟” Stack
public static void main(String[] args) {Deque<Integer> deque = new ArrayDeque<>();deque.push(1);deque.push(2);deque.push(3);do {final Integer poll = deque.poll();if (poll == null) {break;}log.debug(poll.toString());} while (true);// 依次输出// 3 2 1}
当把
Deque用作Stack使用时,注意只使用push()/pop()/peek()方法,不用调用addFirst()/removeFirst()/peekFirst()方法,这样使代码更清晰
Stack 用法
一、JVM 使用 Stack 维护方法调用的层次
static void main(String[] args) {foo(123);}static String foo(x) {return "F-" + bar(x + 1);}static int bar(int x) {return x << 2;}
JVM 会创建方法调用栈,每调用一个方法时,先将参数压入栈,然后指向对应的方法;当方法返回时,返回值压入栈,调用方法通过出栈操作获得方法返回值。
方法调用栈存在容量限制,嵌套调用过多会造成栈溢出,即引发 StackOverflowError
static int inc(int data){return inc(data)+1;}public static void main(String[] args) {inc(1);}
二、用 Stack 对整数进行进制转换
将 int 整数 12500 转换为十六进制表示的字符串:
准备一个空栈
│ ││ ││ ││ │└───┘
计算
12500÷16=781…4,余数是4,把余数4压栈:│ ││ ││ ││ 4 │└───┘
计算
781÷16=48…13,余数是13,13的十六进制用字母D表示,把余数D压栈:│ ││ ││ D ││ 4 │└───┘
计算
48÷16=3…0,余数是0,把余数0压栈:│ ││ 0 ││ D ││ 4 │└───┘
计算
3÷16=0…3,余数是3,把余数3压栈:│ 3 ││ 0 ││ D ││ 4 │└───┘
当商是
0的时候,结束计算。将栈中的所有元素依次弹出,组成字符串30D4,这就是十进制整数12500的十六进制表示的字符串 ```java static final String[] HEX_CHARS = new String[]{“0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”, “A”, “B”, “C”, “D”, “E”, “F”}; static String toHex(int data) { Dequestack = new ArrayDeque<>(); do { int result = data % HEX_CHARS.length;stack.push(HEX_CHARS[result]);data = data / HEX_CHARS.length;
} while (data != 0);
StringBuilder sb = new StringBuilder(stack.size()); do {
sb.append(stack.poll());
} while (stack.size() > 0);
return sb.toString(); }
public static void main(String[] args) { var hex = toHex(12500); log.debug(“{} toHex = {}”, 12500, hex); // 30D4 // JDK 写法 final String hexString = Integer.toHexString(12500).toUpperCase(); log.debug(“{} toHexString = {}”, 12500, hexString); // 30D4 } ```

若有收获,就点个赞吧
0 人点赞
