1.概念
一种可以用于数据处理的编程模型。Hadoop可以运行各种语言版本的MapReduce程序。本质上是并行运行的,因此可以将大规模的数据分析任务分发给一个机器多的数据中心。优势在于处理大规模数据集。
2.map和reduce
MapReduce任务过程分为两个处理阶段:map阶段和reduce阶段。每阶段都以键值对作为输入和输出,类型可以自由选择。程序员需要写两个函数:map函数和reduce函数。
(1)map阶段:
选择输入格式(如文本);键是某一行起始位置对于文件起始位置的偏移量;筛掉缺失可疑错误的数据。
输入:
键:偏移量
值:文本
map输出:
键:年份
值:气温
主要功能:数据准备阶段,提取有用数据作为输出。输出经过MapReduce框架处理后发送到reduce函数。
处理过程基于键值对进行排序和分组。
处理后:
(2)reduce阶段:
主要功能:对map的输出遍历并找出最大的数。
输出:
流程图: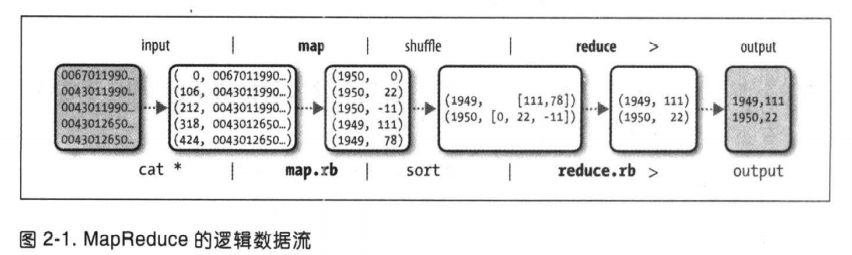
(3)代码实现:
(1)map:

(2)reduce:
(3)MapReduce:
负责运行该MapReduce作业

3.概念:
(1)job
客户端执行的工作单元,包括输入数据、MapReduce程序和配置信息。
hadoop将job分成几个task来执行,共两类task:map任务和reduce任务。任务运行在集群的节点上,通过YARN调度。
(2)分片
Hadoop将MapReduce的输入数据划分成等长的小数据块,称为输入分片。每个分片构建一个map任务。
分片越小负载平衡质量越高,但管理分片和构建map的时间占比大,合理的分片大小趋向HDFS的一个块的大小,默认128MB。
(3)数据本地化优化
hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务获得最佳性能,因为无需使用集群的带宽资源。
如果一个输入分片所在的HDFS数据块所在节点全在运行map任务,这时需要调度别的节点的map slot来运行map任务,所以最佳分片大小应该与块大小相同。
map任务将输出写入本地硬盘而非HDFS,因为map的输出是中间结果,job完成后可以删除。因此如果map任务节点结果传送失败将会在另一个节点上重新运行map任务。
reduce任务不具备该优势。因为map输出要通过网络传输到reduce任务节点,最后将reduce的输出存储在HDFS实现可靠存储。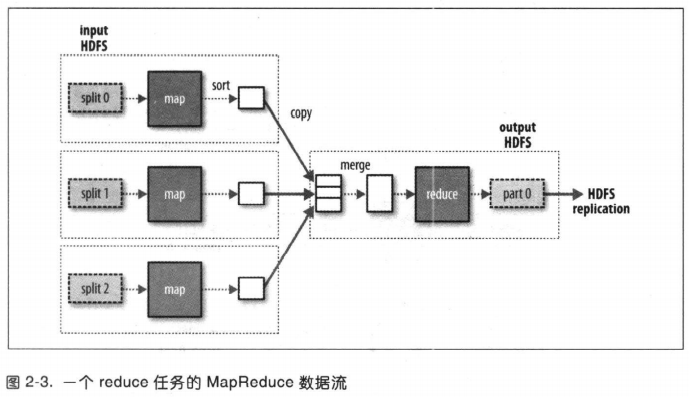
reduce任务数量与输入数据大小无关。
(4)混洗(shuffle)
map任务和reduce任务之间的数据流称为shuffle,因为每个reduce任务的输入都来自许多map任务。调整混洗参数对作业执行时间影响很大。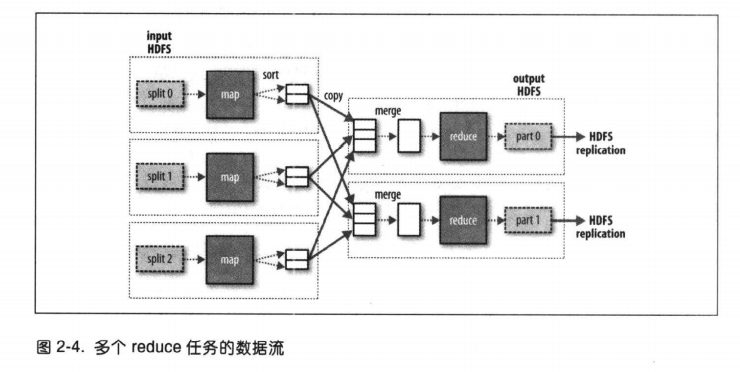
(5)combiner函数
用于减少map和reduce任务之间的数据传输(消耗带宽)的优化方案。该函数输入为map的输出,输出为reduce的输入。
例子:
map1输出:
map2输出:
reduce输入:
使用combiner函数时reduce输入: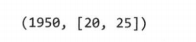
事先找出了每个map上的最大值。

若有收获,就点个赞吧
0 人点赞
