Python基础语法
window安装Python
下载安装包
下载地址:https://www.python.org/downloads/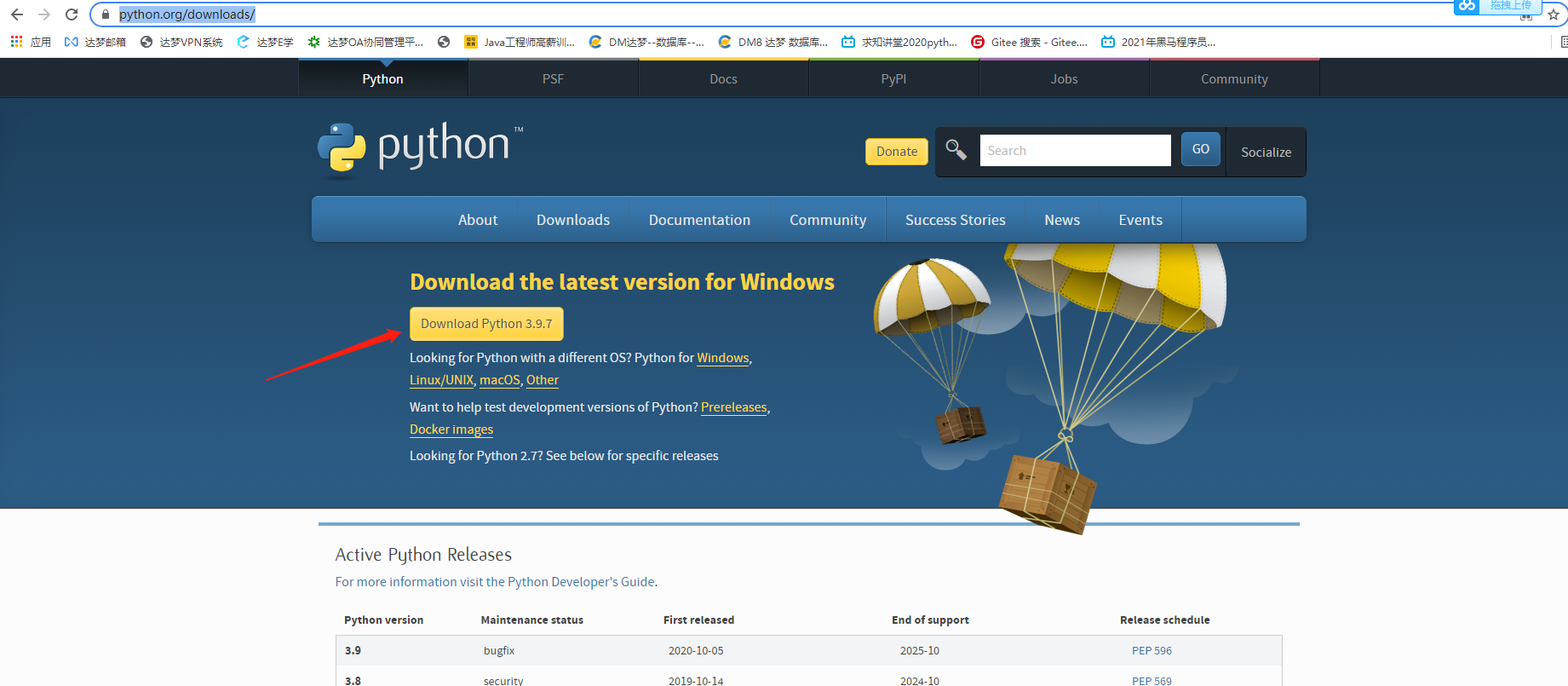
安装
- 点击下载的
.exe文件并且添加环境变量
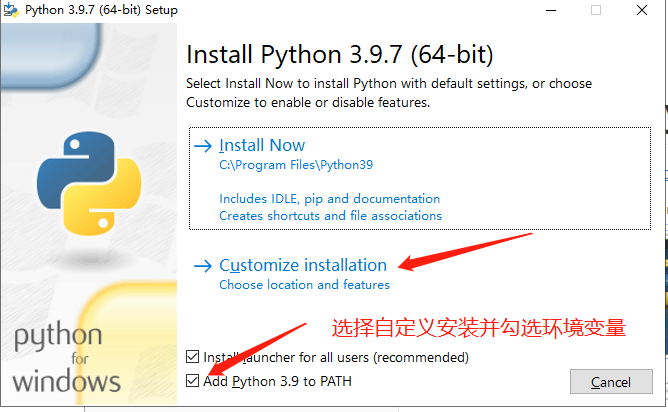
- 下一步全部勾选

第三步:nstall for all users :勾选 给所有用户
Associate files with python:关联python文件
create shortcuts for installed applications:给安装的软件,添加个快捷方式
add python to enviroment variables:将python添加到环境变量中
Precompile standard library:预编译[准备]python标准文件
Customize install location:本地安装位置
最后两个选项不需要勾选,其余的都勾选。
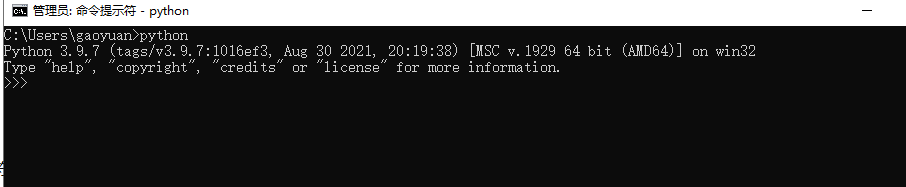
验证
python
pyCharm
PyCharm安装
下载地址:https://www.jetbrains.com/pycharm/download/other.html
注:注意勾选下图的两处
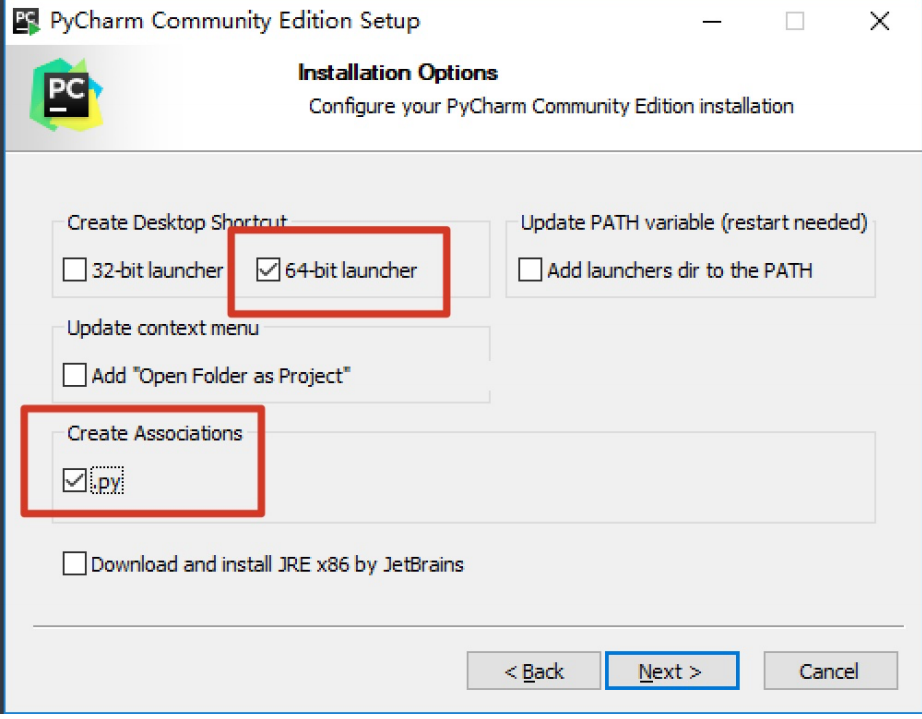
Pycharm新建项目

Pycharm配置
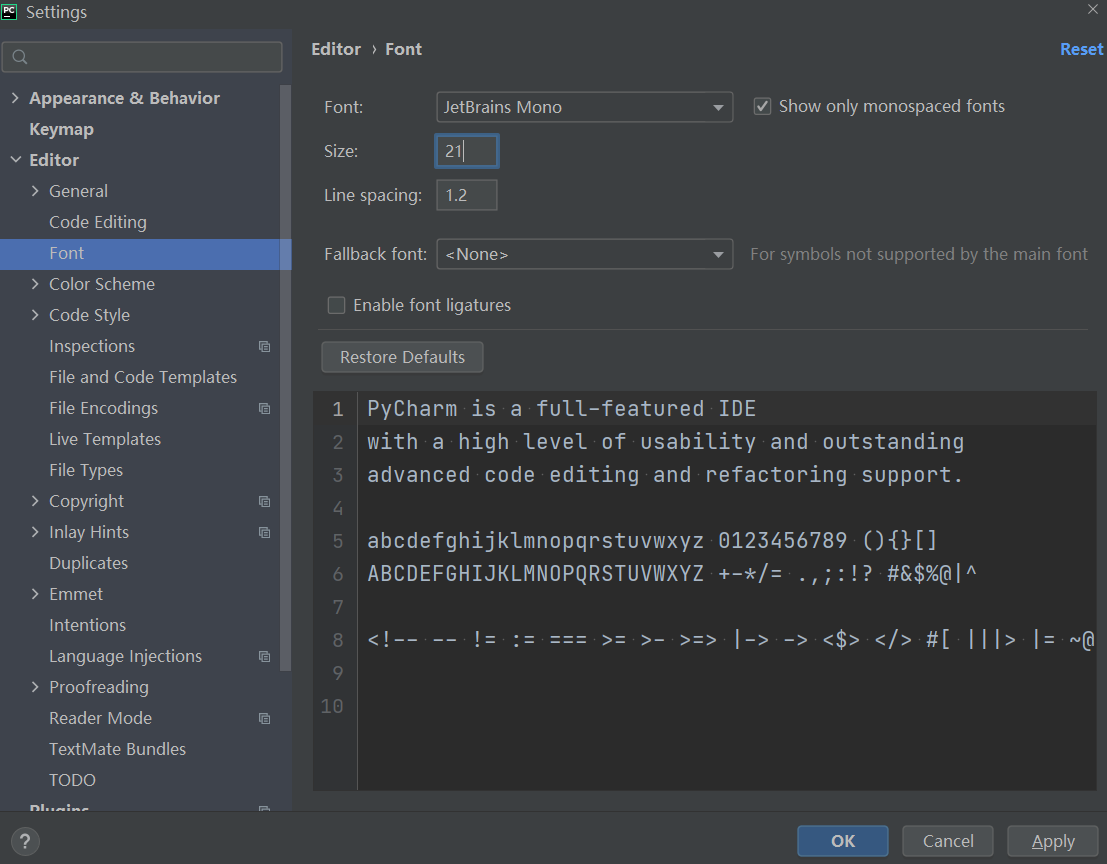
配置字体
[Editor] — [Font]
Font:修改字体
Size:修改字号
Line Spacing:修改⾏间距
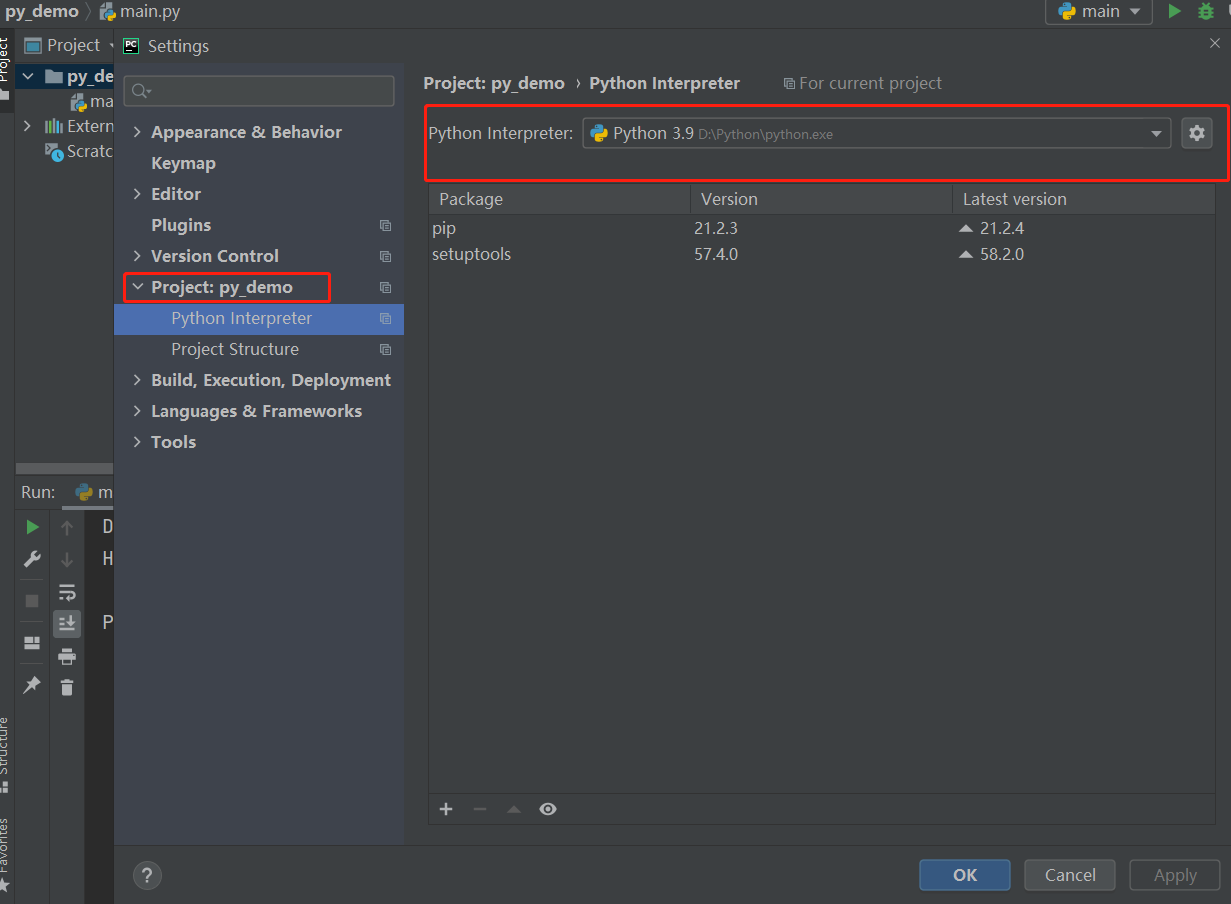
配置解析器
Python语法
变量
定义变量

a = 1print(type(a)) # <class 'int'> -- 整型b = 1.1print(type(b)) # <class 'float'> -- 浮点型c = Trueprint(type(c)) # <class 'bool'> -- 布尔型d = '12345'print(type(d)) # <class 'str'> -- 字符串e = [10, 20, 30]print(type(e)) # <class 'list'> -- 列表f = (10, 20, 30)print(type(f)) # <class 'tuple'> -- 元组h = {10, 20, 30}print(type(h)) # <class 'set'> -- 集合g = {'name': 'TOM', 'age': 20}print(type(g)) # <class 'dict'> -- 字典
输出变量
格式化符号
| 格式符号 | 转换 |
|---|---|
| %s | 字符串 |
| %d | 有符号的⼗进制整数 |
| %f | 浮点数 |
| %c | 字符 |
| %u | ⽆符号⼗进制整数 |
| %o | ⼋进制整数 |
| %x | ⼗六进制整数(⼩写ox) |
| %X | ⼗六进制整数(⼤写OX) |
| %e | 科学计数法(⼩写’e’) |
| 格式符号 | 转换 |
|---|---|
| %E | 科学计数法(⼤写’E’) |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
技巧
%06d,表示输出的整数显示位数,不⾜以0补全,超出当前位数则原样输出
%.2f,表示⼩数点后显示的⼩数位数。
输出变量
技巧
%06d,表示输出的整数显示位数,不⾜以0补全,超出当前位数则原样输出
%.2f,表示⼩数点后显示的⼩数位数。
f- 格式化字符串是Python3.6中新增的格式化⽅法,该⽅法更简单易读。
转义字符
- n :换⾏。
- t :制表符,⼀个tab键(4个空格)的距离。
结束符
在Python中,print(), 默认⾃带 end=”\n” 这个换⾏结束符,所以导致每两个 print 直接会换⾏展示,⽤户可以按需求更改结束符。
age = 18name = 'TOM'weight = 75.5student_id = 1# 我的名字是TOMprint('我的名字是%s' % name)# 我的学号是0001 补全位数 由1转换成0001print('我的学号是%4d' % student_id)# 我的体重是75.50公⽄print('我的体重是%.2f公⽄' % weight)# 我的名字是TOM,今年18岁了print('我的名字是%s,今年%d岁了' % (name, age))# 我的名字是TOM,明年19岁了print('我的名字是%s,明年%d岁了' % (name, age + 1))# 我的名字是TOM,明年19岁了# f-格式化字符串是Python3.6中新增的格式化⽅法,该⽅法更简单易读。print(f'我的名字是{name}, 明年{age + 1}岁了')##### 转移符号# 换行转义\nprint('我的名字是\nGG')# 结束符 \t ⼀个tab键(4个空格)的距离print('我的名字是\tGG')#### 结束符print('输出的内容1', end="\n")print('输出的内容2', end="\t")print('输出的内容3', end="\t")
input 输入函数
输入函数例子
password = input('请输⼊您的密码:')print(f'您输⼊的密码是{password}')# <class 'str'>print(type(password))
转换数据类型
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为⼀个整数 |
| flfloat(x) | 将x转换为⼀个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
| eval(str) | ⽤来计算在字符串中的有效Python表达式,并返回⼀个对象 |
| tuple(s) | 将序列 s 转换为⼀个元组 |
| list(s) | 将序列 s 转换为⼀个列表 |
# 1. 接收⽤户输⼊num = input('请输⼊您的幸运数字:')# 2. 打印结果print(f"您的幸运数字是{num}")# 3. 检测接收到的⽤户输⼊的数据类型 -- str类型print(type(num))# 4. 转换数据类型为整型 -- int类型print(type(int(num)))
运算符
- 算数运算的优先级
- 混合运算优先级顺序: () ⾼于 * ⾼于 / // % ⾼于 + -
- 赋值运算符
- =
- 复合赋值运算符
- +=
- -=
- 优先级
1. 先算复合赋值运算符右侧的表达式
* 2.再算复合赋值运算的算数运算* 3.最后算赋值运算
- ⽐较运算符
- 判断相等: ==
- ⼤于等于: >=
- ⼩于等于:<=
- 不等于: !=
- 逻辑运算符
- 与: and
- 或:or
- ⾮:not
条件语句(if+三目)
三⽬运算符也叫三元运算符或三元表达式
a = 1 b = 2 c = a if a > b else bprint(c)
# 导⼊random模块import random# 计算电脑出拳的随机数字computer = random.randint(0, 2)print(computer)player = int(input('请出拳:0-⽯头,1-剪⼑,2-布:'))# 玩家胜利 p0:c1 或 p1:c2 或 p2:c0if ((player == 0) and (computer == 1)) or ((player == 1) and (computer == 2)) or ((player == 2) and (computer == 0)):print('玩家获胜')# 平局:玩家 == 电脑elif player == computer:print('平局')else:print('电脑获胜')
while循环
j = 0while j < 3:i = 0while i < 3:print('媳妇⼉,我错了')i += 1print('刷晚饭的碗')print('⼀套惩罚结束----------------')j += 1
字符串
基础用法
name1 = 'Tom'name2 = "Rose"# 注意:三引号形式的字符串⽀持换⾏。name3 = ''' Tom '''name4 = """ Rose """a = ''' i am Tom,nice to meet you! '''b = """ i am Rose,nice to meet you! """
下标
name = "abcdef"print(name[1])print(name[0])print(name[2])
切⽚
## 切⽚是指对操作的对象截取其中⼀部分的操作。字符串、列表、元组都⽀持切⽚操作## 序列[开始位置下标:结束位置下标:步⻓]## 注意## 1. 不包含结束位置下标对应的数据, 正负整数均可;## 2. 步⻓是选取间隔,正负整数均可,默认步⻓为1。
print(name[2:5:1]) # cdeprint(name[2:5]) # cdeprint(name[:5]) # abcdeprint(name[1:]) # bcdefgprint(name[:]) # abcdefgprint(name[::2]) # acegprint(name[:-1]) # abcdef, 负1表示倒数第⼀个数据print(name[-4:-1]) # defprint(name[::-1]) # gfedcba
常⽤操作⽅法
- 字符串序列.find(⼦串, 开始位置下标, 结束位置下标)
- index():检测某个⼦串是否包含在这个字符串中,如果在返回这个⼦串开始的位置下标,否则则报异常。
- join():⽤⼀个字符或⼦串合并字符串,即是将多个字符串合并为⼀个新的字符串。
- isspace():如果字符串中只包含空⽩,则返回 True,否则返回 False。
## 查找## 字符串序列.find(⼦串, 开始位置下标, 结束位置下标)mystr = "hello world and itcast and itheima and Python"print(mystr.find('and')) # 12print(mystr.find('and', 15, 30)) # 23print(mystr.find('ands')) # -1## index():检测某个⼦串是否包含在这个字符串中,如果在返回这个⼦串开始的位置下标,否则则报异常。mystr = "hello world and itcast and itheima and Python"print(mystr.index('and')) # 12print(mystr.index('and', 15, 30)) # 23print(mystr.index('ands')) # 报错## rfind(): 和find()功能相同,但查找⽅向为右侧开始。## rindex():和index()功能相同,但查找⽅向为右侧开始。## count():返回某个⼦串在字符串中出现的次数mystr = "hello world and itcast and itheima and Python"print(mystr.count('and')) # 3print(mystr.count('ands')) # 0print(mystr.count('and', 0, 20)) # 1## join():⽤⼀个字符或⼦串合并字符串,即是将多个字符串合并为⼀个新的字符串。## 修改list1 = ['chuan', 'zhi', 'bo', 'ke']t1 = ('aa', 'b', 'cc', 'ddd')# 结果:chuan_zhi_bo_keprint('_'.join(list1))# 结果:aa...b...cc...dddprint('...'.join(t1))## 判断## startswith():检查字符串是否是以指定⼦串开头,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。mystr = "hello world and itcast and itheima and Python "# 结果:Trueprint(mystr.startswith('hello'))# 结果Falseprint(mystr.startswith('hello', 5, 20))## endswith()::检查字符串是否是以指定⼦串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查mystr = "hello world and itcast and itheima and Python"# 结果:Trueprint(mystr.endswith('Python'))# 结果:Falseprint(mystr.endswith('python'))# 结果:Falseprint(mystr.endswith('Python', 2, 20))## isalpha():如果字符串⾄少有⼀个字符并且所有字符都是字⺟则返回 True, 否则返回 False。mystr1 = 'hello'mystr2 = 'hello12345'# 结果:Trueprint(mystr1.isalpha())# 结果:Falseprint(mystr2.isalpha())## isdigit():如果字符串只包含数字则返回 True 否则返回 Falsemystr1 = 'aaa12345'mystr2 = '12345'# 结果: Falseprint(mystr1.isdigit())# 结果:Falseprint(mystr2.isdigit())## isalnum():如果字符串⾄少有⼀个字符并且所有字符都是字⺟或数字则返 回 True,否则返回False。mystr1 = 'aaa12345'mystr2 = '12345-'# 结果:Trueprint(mystr1.isalnum())# 结果:Falseprint(mystr2.isalnum())## isspace():如果字符串中只包含空⽩,则返回 True,否则返回 False。
列表
基础用法
name_list = [‘Tom’, ‘Lily’, ‘Rose’]
- index():返回指定数据所在位置的下标
- count():统计指定数据在当前列表中出现的次数
- len():访问列表⻓度,即列表中数据的个数
- in 判断是否存在
- not in:判断指定数据不在某个列表序列,如果不在返回True,否则返回False
- append():列表结尾追加数据
- pop():删除指定下标的数据(默认为最后⼀个),并返回该数据
- remove():移除列表中某个数据的第⼀个匹配项
- clear():清空列表
- reverse():逆置列表
- sort():排序
- copy():复制
name_list = ['Tom', 'Lily', 'Rose']print(name_list[0]) # Tomprint(name_list[1]) # Lilyprint(name_list[2]) # Rose# index():返回指定数据所在位置的下标name_list = ['Tom', 'Lily', 'Rose']print(name_list.index('Lily', 0, 2)) # 1# count():统计指定数据在当前列表中出现的次数name_list = ['Tom', 'Lily', 'Rose']print(name_list.count('Lily')) # 1# len():访问列表⻓度,即列表中数据的个数name_list = ['Tom', 'Lily', 'Rose']print(len(name_list)) # 3# in 判断是否存在name_list = ['Tom', 'Lily', 'Rose']# 结果:Trueprint('Lily' in name_list)# 结果:Falseprint('Lilys' in name_list)# not in:判断指定数据不在某个列表序列,如果不在返回True,否则返回Falsename_list = ['Tom', 'Lily', 'Rose']# 结果:Falseprint('Lily' not in name_list)# 结果:Trueprint('Lilys' not in name_list)# append():列表结尾追加数据。name_list = ['Tom', 'Lily', 'Rose']name_list.append('xiaoming')# 结果:['Tom', 'Lily', 'Rose', 'xiaoming']print(name_list)name_list.append(['xiaoming', 'xiaohong'])# 结果:['Tom', 'Lily', 'Rose', ['xiaoming', 'xiaohong']]print(name_list)name_list.insert(1, 'xiaoming')# 位置下标, 数据name_list = ['Tom', 'Lily', 'Rose']# 结果:报错提示:name 'name_list' is not defineddel name_listprint(name_list)del name_list[0]# 结果:['Lily', 'Rose']print(name_list)# pop():删除指定下标的数据(默认为最后⼀个),并返回该数据del_name = name_list.pop(1)# remove():移除列表中某个数据的第⼀个匹配项name_list = ['Tom', 'Lily', 'Rose']name_list.remove('Rose')# 结果:['Tom', 'Lily']print(name_list)# clear():清空列表name_list = ['Tom', 'Lily', 'Rose']name_list.clear()print(name_list) # 结果: []# 逆置:reverse()num_list = [1, 5, 2, 3, 6, 8]num_list.reverse()# 结果:[8, 6, 3, 2, 5, 1]print(num_list)# 排序:sort()num_list = [1, 5, 2, 3, 6, 8]num_list.sort()# 结果:[1, 2, 3, 5, 6, 8]print(num_list)# 复制:copy()name_list = ['Tom', 'Lily', 'Rose']name_li2 = name_list.copy()# 结果:['Tom', 'Lily', 'Rose']print(name_li2)#Forname_list = ['Tom', 'Lily', 'Rose']for i in name_list:print(i)# 列表嵌套name_list = [['⼩明', '⼩红', '⼩绿'], ['Tom', 'Lily', 'Rose'], ['张三', '李四', '王五']]# 第⼀步:按下标查找到李四所在的列表print(name_list[2])# 第⼆步:从李四所在的列表⾥⾯,再按下标找到数据李四print(name_list[2][1])
元组
列表可以⼀次性存储多个数据,但是列表中的数据允许更改。
⼀个元组可以存储多个数据,元组内的数据是不能修改的。
定义元组
## 元组特点:定义元组使⽤⼩括号,且逗号隔开各个数据,数据可以是不同的数据类型。# 多个数据元组t1 = (10, 20, 30)# 单个数据元组t2 = (10,)# 如果定义的元组只有⼀个数据,那么这个数据后⾯也好添加逗号,否则数据类型为唯⼀的这个数据的数据类型t2 = (10,)print(type(t2)) # tuplet3 = (20)print(type(t3)) # intt4 = ('hello')print(type(t4)) # str
常见操作
## 元组数据不⽀持修改,只⽀持查找tuple1 = ('aa', 'bb', 'cc', 'bb')print(tuple1[0]) # aa## 按下标查找数据tuple1 = ('aa', 'bb', 'cc', 'bb')print(tuple1[0]) # aa## index():查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index⽅法相同。tuple1 = ('aa', 'bb', 'cc', 'bb')print(tuple1.index('aa')) # 0## count():统计某个数据在当前元组出现的次数tuple1 = ('aa', 'bb', 'cc', 'bb')print(tuple1.count('bb')) # 2## len():统计元组中数据的个数。tuple1 = ('aa', 'bb', 'cc', 'bb')print(len(tuple1)) # 4## 如果元组⾥⾯有列表,修改列表⾥⾯的数据则是⽀持的,故⾃觉很重要tuple2 = (10, 20, ['aa', 'bb', 'cc'], 50, 30)print(tuple2[2]) # 访问到列表# 结果:(10, 20, ['aaaaa', 'bb', 'cc'], 50, 30)tuple2[2][0] = 'aaaaa'print(tuple2)
集合
特点:
- 集合可以去掉重复数据;
- 集合数据是⽆序的,故不⽀持下标
## 创建集合## {50, 20, 40, 10, 30}s1 = {10, 20, 30, 40, 50}print(s1)## {50, 20, 40, 10, 30}s2 = {10, 30, 20, 10, 30, 40, 30, 50}print(s2)## {'g', 'd', 'a', 'b', 'c', 'e', 'f'}s3 = set('abcdefg')print(s3)
常见操作
## 集合有去重功能,所以,当向集合内追加的数据是当前集合已有数据的话,则不进⾏任何操作。## add() 添加集合s1 = {10, 20}s1.add(100)s1.add(10)print(s1) # {100, 10, 20}## update(), 追加的数据是序列。s1 = {10, 20}# s1.update(100) # 报错s1.update([100, 200])s1.update('abc')print(s1)## 删除数据 remove(),删除集合中的指定数据,如果数据不存在则报错。s1 = {10, 20}s1.remove(10)print(s1)s1.remove(10) # 报错print(s1)## discard(),删除集合中的指定数据,如果数据不存在也不会报错。s1 = {10, 20}s1.discard(10)print(s1)s1.discard(10)print(s1)## pop(),随机删除集合中的某个数据,并返回这个数据。s1 = {10, 20, 30, 40, 50}del_num = s1.pop()print(del_num)print(s1)## in:判断数据在集合序列## not in:判断数据不在集合序列s1 = {10, 20, 30, 40, 50}print(10 in s1)print(10 not in s1)
字典
定义字典
字典特点:
- 符号为⼤括号
- 数据为键值对形式出现
- 各个键值对之间⽤逗号隔开
字典⾥⾯的数据是以键值对形式出现,字典数据和数据顺序没有关系,即字典不⽀持下标,后期⽆论数据如何变化,只需要按照对应的键的名字查找数据即可。
# 有数据字典dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}# 空字典dict2 = {}dict3 = dict()
常见操作
## 增加数据dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}dict1['name'] = 'Rose'# 结果:{'name': 'Rose', 'age': 20, 'gender': '男'}print(dict1)dict1['id'] = 110# {'name': 'Rose', 'age': 20, 'gender': '男', 'id': 110}print(dict1)## 删除数据## del() / del:删除字典或删除字典中指定键值对。dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}del dict1['gender']# 结果:{'name': 'Tom', 'age': 20}print(dict1)## clear():清空字典dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}dict1.clear()print(dict1) # {}## 修改数据## 如果key存在则修改这个key对应的值 ;如果key不存在则新增此键值对。# 有数据字典dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}dict1['name']='Jack'print(dict1)## 查找数据## 如果当前查找的key存在,则返回对应的值;否则则报错dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}print(dict1['name']) # Tomprint(dict1['id']) # 报错## get() 如果当前查找的key不存在则返回第⼆个参数(默认值),如果省略第⼆个参数,则返回None。dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}print(dict1.get('name')) # Tomprint(dict1.get('id', 110)) # 110print(dict1.get('id')) # None## keys() 返回所有的key值dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}print(dict1.keys()) # dict_keys(['name', 'age', 'gender'])## values() 返回所有的values值dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}print(dict1.values()) # dict_values(['Tom', 20, '男'])## items()dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}print(dict1.items()) # dict_items([('name', 'Tom'), ('age', 20), ('gender','男')])## 字典的循环遍历dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}for key in dict1.keys():print(key)## 遍历字典的valuedict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}for value in dict1.values():print(value)## 遍历字典的元素dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}for item in dict1.items():print(item)## 遍历字典的键值对dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}for key, value in dict1.items():print(f'{key} = {value}')
公共操作
常规函数
| 运算符 | 描述 | ⽀持的容器类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典 |
| 函数 | 描述 |
|---|---|
| len() | 计算容器中元素个数 |
| del 或 del() | 删除 |
| max() | 返回容器中元素最⼤值 |
| min() | 返回容器中元素最⼩值 |
| range(start,end, step) | ⽣成从start到end的数字,步⻓为 step,供for循环使⽤ |
| enumerate() | 函数⽤于将⼀个可遍历的数据对象(如列表、元组或字符串)组合为⼀个索引序 |
## len()# 1. 字符串str1 = 'abcdefg'print(len(str1)) # 7# 2. 列表list1 = [10, 20, 30, 40]print(len(list1)) # 4# 3. 元组t1 = (10, 20, 30, 40, 50)print(len(t1)) # 5# 4. 集合s1 = {10, 20, 30}print(len(s1)) # 3# 5. 字典dict1 = {'name': 'Rose', 'age': 18}print(len(dict1)) # 2## del()# 1. 字符串str1 = 'abcdefg'del str1print(str1)# 2. 列表list1 = [10, 20, 30, 40]del(list1[0])print(list1) # [20, 30, 40]## max()# 1. 字符串str1 = 'abcdefg'print(max(str1)) # g# 2. 列表list1 = [10, 20, 30, 40]print(max(list1)) # 40## min()# 1. 字符串str1 = 'abcdefg'print(min(str1)) # a# 2. 列表list1 = [10, 20, 30, 40]print(min(list1)) # 10## range()## range()⽣成的序列不包含end数字。# 1 2 3 4 5 6 7 8 9for i in range(1, 10, 1):print(i)# 1 3 5 7 9for i in range(1, 10, 2):print(i)# 0 1 2 3 4 5 6 7 8 9for i in range(10):print(i)## enumerate()## start参数⽤来设置遍历数据的下标的起始值,默认为0。list1 = ['a', 'b', 'c', 'd', 'e']for i in enumerate(list1):print(i)for index, char in enumerate(list1, start=1):print(f'下标是{index}, 对应的字符是{char}')
容器类型转换
## tuple() 将某个序列转换成元组list1 = [10, 20, 30, 40, 50, 20]s1 = {100, 200, 300, 400, 500}print(tuple(list1))print(tuple(s1))## list() 作⽤:将某个序列转换成列表t1 = ('a', 'b', 'c', 'd', 'e')s1 = {100, 200, 300, 400, 500}print(list(t1))print(list(s1))## set() 作⽤:将某个序列转换成集合list1 = [10, 20, 30, 40, 50, 20]t1 = ('a', 'b', 'c', 'd', 'e')print(set(list1))print(set(t1))#注意:#1. 集合可以快速完成列表去重#2. 集合不⽀持下标
推导式
作⽤:⽤⼀个表达式创建⼀个有规律的列表或控制⼀个有规律列表。
列表推导式⼜叫列表⽣成式。
列表推导式
# for循环list1 = []for i in range(10):list1.append(i)print(list1)## 列表推导式实现list1 = [i for i in range(10)]print(list1)
# ⽅法⼀:range()步⻓实现list1 = [i for i in range(0, 10, 2)]print(list1)# ⽅法⼆:if实现list1 = [i for i in range(10) if i % 2 == 0]print(list1)
字典推导式
# 如何快速合并为⼀个字典?list1 = ['name', 'age', 'gender']list2 = ['Tom', 20, 'man']## 创建⼀个字典:字典key是1-5数字,value是这个数字的2次⽅。dict1 = {i: i**2 for i in range(1, 5)}print(dict1) # {1: 1, 2: 4, 3: 9, 4: 16}## 将两个列表合并为⼀个字典list1 = ['name', 'age', 'gender']list2 = ['Tom', 20, 'man']dict1 = {list1[i]: list2[i] for i in range(len(list1))}print(dict1)## 提取字典中⽬标数据counts = {'MBP': 268, 'HP': 125, 'DELL': 201, 'Lenovo': 199, 'acer': 99}# 需求:提取上述电脑数量⼤于等于200的字典数据count1 = {key: value for key, value in counts.items() if value >= 200}print(count1) # {'MBP': 268, 'DELL': 201}
集合推导式
##需求:创建⼀个集合,数据为下⽅列表的2次⽅。list1 = [1, 1, 2]##代码如下:list1 = [1, 1, 2]set1 = {i ** 2 for i in list1}print(set1) # {1, 4}##注意:集合有数据去重功能。
总结
- 推导式的作⽤:简化代码
- 推导式写法
# 列表推导式[xx for xx in range()]# 字典推导式{xx1: xx2 for ... in ...}# 集合推导式{xx for xx in ...}
函数
定义函数
# 1. 定义函数def add_num1():result = 1 + 2print(result)# 调⽤函数add_num1()# 2. 定义函数接收形参def add_num2(a, b):result = a + bprint(result)# 调⽤函数add_num2(10, 20)## 3. 函数的返回值def buy():return '烟'# 调⽤函数goods = buy()print(goods)## 4.函数的说明⽂档def sum_num(a, b):""" 求和函数 """return a + bhelp(sum_num)
函数进阶
## 1. global 关键字声明a是全局变量a = 100def testA():print(a)def testB():# global 关键字声明a是全局变量global aa = 200testA() # 100testB() # 200print(f'全局变量a = {a}') # 全局变量a = 200## 2.函数的返回值## 2.1. return a, b 写法,返回多个数据的时候,默认是元组类型。## 2.2. return后⾯可以连接列表、元组或字典,以返回多个值。def return_num():return 1, 2result = return_num()print(result) # (1, 2)## 函数的参数### 1. 位置参数### 位置参数:调⽤函数时根据函数定义的参数位置来传递参数。def user_info(name, age, gender):print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')user_info('TOM', 20, '男')### 2. 关键字参数### 函数调⽤,通过“键=值”形式加以指定。可以让函数更加清晰、容易使⽤,同时也清除了参数的顺序需求。def user_info(name, age, gender):print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')user_info('Rose', age=20, gender='⼥')user_info('⼩明', gender='男', age=16)### 3. 缺省参数### 缺省参数也叫默认参数,⽤于定义函数,为参数提供默认值,调⽤函数时可不传该默认参数的值def user_info(name, age, gender='男'):print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')user_info('TOM', 20)user_info('Rose', 18, '⼥')### 4.不定⻓参数### 不定⻓参数也叫可变参数。⽤于不确定调⽤的时候会传递多少个参数(不传参也可以)的场景。### 注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为⼀个元组(tuple),args是元组类型,这就是包裹位置传递。def user_info(*args):print(args)# ('TOM',)user_info('TOM')# ('TOM', 18)user_info('TOM', 18)def user_info(**kwargs):print(kwargs)# {'name': 'TOM', 'age': 18, 'id': 110}user_info(name='TOM', age=18, id=110)# 交换变量值# 需求:有变量 a = 10 和 b = 20 ,交换两个变量的值。a, b = 1, 2a, b = b, aprint(a) # 2print(b) # 1
拆包
# 拆包和交换变量值## 1. 拆包:元组def return_num():return 100, 200num1, num2 = return_num()print(num1) # 100print(num2) # 200## 2.拆包:字典dict1 = {'name': 'TOM', 'age': 18} a, b = dict1# 对字典进⾏拆包,取出来的是字典的keyprint(a) # nameprint(b) # ageprint(dict1[a]) # TOMprint(dict1[b]) # 18
引⽤
在python中,值是靠引⽤来传递来的。
我们可以⽤ id() id() 来判断两个变量是否为同⼀个值的引⽤。 我们可以将id值理解为那块内存的地址标识。
## 我们可以⽤ id() id() 来判断两个变量是否为同⼀个值的引⽤。 我们可以将id值理解为那块内存的地址标识。# 1. int类型a = 1 b = aprint(b) # 1print(id(a)) # 140708464157520print(id(b)) # 140708464157520a = 2print(b) # 1,说明int类型为不可变类型## 引⽤当做实参def test1(a):print(a)print(id(a))a += aprint(a)print(id(a))# int:计算前后id值不同b = 100test1(b)# 列表:计算前后id值相同c = [11, 22]test1(c)
可变和不可变类型
所谓可变类型与不可变类型是指:数据能够直接进⾏修改,如果能直接修改那么就是可变,否则是不可变.
- 可变类型
- 列表
- 字典
- 集合
- 不可变类型
- 整型
- 浮点型
- 字符串
- 元组
总结
函数的作⽤:封装代码,⾼效的代码重⽤
函数使⽤步骤
- 定义函数
def 函数名():代码1代码2...
调⽤函数的方式
函数的参数:函数调⽤的时候可以传⼊真实数据,增⼤函数的使⽤的灵活性
- 形参:函数定义时书写的参数(⾮真实数据)
- 实参:函数调⽤时书写的参数(真实数据)
函数的返回值
- 作⽤:函数调⽤后,返回需要的计算结果
- 写法
return 表达式
函数的说明⽂档
作⽤:保存函数解释说明的信息
def 函数名():""" 函数说明⽂档 """
函数的参数
- 位置参数
- 形参和实参的个数和书写顺序必须⼀致
- 关键字参数
- 写法: key=value
- 特点:形参和实参的书写顺序可以不⼀致;关键字参数必须书写在位置参数的后⾯
- 缺省参数
- 缺省参数就是默认参数
- 写法: key=vlaue
- 不定⻓位置参数
- 收集所有位置参数,返回⼀个元组
- 不定⻓关键字参数
- 收集所有关键字参数,返回⼀个字典
引⽤:Python中,数据的传递都是通过引⽤
lambda表达式
应⽤场景
如果⼀个函数有⼀个返回值,并且只有⼀句代码,可以使⽤ lambda简化。
lambda语法
lambda 参数列表 : 表达式
- lambda表达式的参数可有可⽆,函数的参数在lambda表达式中完全适⽤。
- lambda函数能接收任何数量的参数但只能返回⼀个表达式的值
应用场景
# 函数def fn1():return 200print(fn1)print(fn1())# lambda表达式fn2 = lambda: 100print(fn2)print(fn2())
计算a + b
## 函数实现def add(a, b):return a + bresult = add(1, 2)print(result)## lambda实现print((lambda a, b: a + b)(1, 2))
## lambda的参数形式## ⽆参数print((lambda: 100)())## ⼀个参数print((lambda a: a)('hello world'))## 默认参数print((lambda a, b, c=100: a + b + c)(10, 20)) 1## 可变参数:**argsprint((lambda *args: args)(10, 20, 30))## 可变参数:**kwargsprint((lambda **kwargs: kwargs)(name='python', age=20))print((lambda **kwargs: kwargs)(name='python', age=20))
⾼阶函数
## 把函数作为参数传⼊,这样的函数称为⾼阶函数,⾼阶函数是函数式编程的体现。函数式编程就是指这种⾼度抽象的编程范式。
map()
map(func, lst),将传⼊的函数变量func作⽤到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3)返回。
## 需求:计算 list1 序列中各个数字的2次⽅。list1 = [1, 2, 3, 4, 5]def func(x):return x ** 2result = map(func, list1)print(result) # <map object at 0x0000013769653198>print(list(result)) # [1, 4, 9, 16, 25]
reduce()
reduce(func(x,y),lst),其中func必须有两个参数。每次func计算的结果继续和序列的下⼀个元素做累
积计算。
注意:reduce()传⼊的参数func必须接受2个参数。
## 需求:计算 list1 序列中各个数字的累加和。import functoolslist1 = [1, 2, 3, 4, 5]def func(a, b):return a + bresult = functools.reduce(func, list1)print(result) # 15
fifilter()
fifilter(func, lst)函数⽤于过滤序列, 过滤掉不符合条件的元素, 返回⼀个 fifilter 对象,。如果要转换为列表,可以使⽤ list() 来转换。
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]def func(x):return x % 2 == 0result = filter(func, list1)print(result) # <filter object at 0x0000017AF9DC3198>print(list(result)) # [2, 4, 6, 8, 10]
文件操作
⽂件操作的作⽤就是把⼀些内容(数据)存储存放起来,可以让程序下⼀次执⾏的时候直接使⽤,⽽不必重新制作⼀份,省时省⼒。
基础操作
## 在python,使⽤open函数,可以打开⼀个已经存在的⽂件open(name, mode)# w 和 a 模式:如果⽂件不存在则创建该⽂件;如果⽂件存在, w 模式先清空再写⼊, a 模式直接末尾追加。# 1. 打开⽂件f = open('test.txt', 'w')# 2.⽂件写⼊f.write('hello world')# 3. 关闭⽂件f.close()## 读## readlines()## readlines可以按照⾏的⽅式把整个⽂件中的内容进⾏⼀次性读取,并且返回的是⼀个列表,其中每⼀⾏的数据为⼀个元素。f = open('test.txt')content = f.readlines()# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']print(content)# 关闭⽂件f.close()## readline()## readline()⼀次读取⼀⾏内容。f = open('test.txt')content = f.readline()print(f'第⼀⾏:{content}')content = f.readline()print(f'第⼆⾏:{content}')# 关闭⽂件f.close()
⽂件和⽂件夹的操作
## 导⼊os模块import os## ⽂件重命名os.rename(⽬标⽂件名, 新⽂件名)## 删除⽂件os.remove(⽬标⽂件名)## 创建⽂件夹os.mkdir(⽂件夹名字)## 删除⽂件夹os.rmdir(⽂件夹名字)## 获取当前⽬录os.getcwd()## 改变默认⽬录os.chdir(⽬录)## 获取⽬录列表os.listdir(⽬录)
import os# 设置重命名标识:如果为1则添加指定字符,flag取值为2则删除指定字符flag = 1# 获取指定⽬录dir_name = './'# 获取指定⽬录的⽂件列表file_list = os.listdir(dir_name)# print(file_list)# 遍历⽂件列表内的⽂件for name in file_list:# 添加指定字符if flag == 1:new_name = 'Python-' + name# 删除指定字符elif flag == 2:num = len('Python-')new_name = name[num:]# 打印新⽂件名,测试程序正确性print(new_name)# 重命名os.rename(dir_name+name, dir_name+new_name)
总结
- ⽂件操作步骤
- 打开
⽂件对象 = open(⽬标⽂件, 访问模式)
- 操作
## 读⽂件对象.read()⽂件对象.readlines()⽂件对象.readline()## 写⽂件对象.write()##seek()
- 主访问模式
- w:写,⽂件不存在则新建该⽂件
- r:读,⽂件不存在则报错
- a:追加
- ⽂件和⽂件夹操作
- 重命名:os.rename()
- 获取当前⽬录:os.getcwd()
- 获取⽬录列表:os.listdir()

若有收获,就点个赞吧
0 人点赞
