elf spec: https://refspecs.linuxfoundation.org/elf/elf.pdf
arm elf spec: https://refspecs.linuxfoundation.org/elf/ARMELF.pdf
ELF V1.2 spec文档写于1995年,今天使用的ELF格式就是V1.2中定义的格式。
ELF全称Executable and Linking Format,最初是Unix操作系统ABI(Application Binary Interface)的一部分。TIS(Tool Interface Standards)委员会选择持续进化的ELF作为工作在Intel 32-bit架构之上的标准的portable object file format。(但是ELF是一个被设计的易于扩展的格式,64位架构和其他处理器平台如今也都有基于ELF扩展而来的object file format。)
ELF标准旨在提高软件开发的效率,这是通过为不同操作系统制定一套统一的二进制接口规范,从而减少在进行软件移植时所需的重写代码和重新编译来实现的。
第一部分对ELF格式进行说明;
第二部分对处理器相关的ELF扩展信息进行说明,ELF spec里只覆盖了Intel,其他处理器一般单独提供说明文档;
第三部分对操作系统相关的ELF扩展信息进行说明,ELF spec里只覆盖了Unix System V Release 4。
在ELF spec中,虽然对Linker和Loader有提及,但该spec假设读者对linker和loader有一定的了解,并没有太多的解释关于程序链接和加载的细节。需要补充这部分知识的话,《Linker and Loader》或许是不错的资料。
ELF格式
Object Files
简介
这一章描述ELF这种目标文件格式,ELF格式的目标文件可以分为三类:
- Relocatable File,可重定位文件,用于和其他目标文件链接生成shared object file或者executable file;
- Executable File,可执行文件;
- Shared Object File,一般叫so文件,在两种链接场景下被使用:
- link editor会将so和其他可重定位文件一并处理,生成新的目标文件;
- dynamic linker将so和可执行文件组合来创process image。
由assembler和link editor创建的目标文件是待处理器执行的程序的二进制表示,能够直接被处理器执行。需要其他抽象层支持才能够运行的程序不属于目标文件。
File Format
目标文件参与program linking和program execution。为了效率和简洁,目标文件为这两种目的提供了两种抽象表示: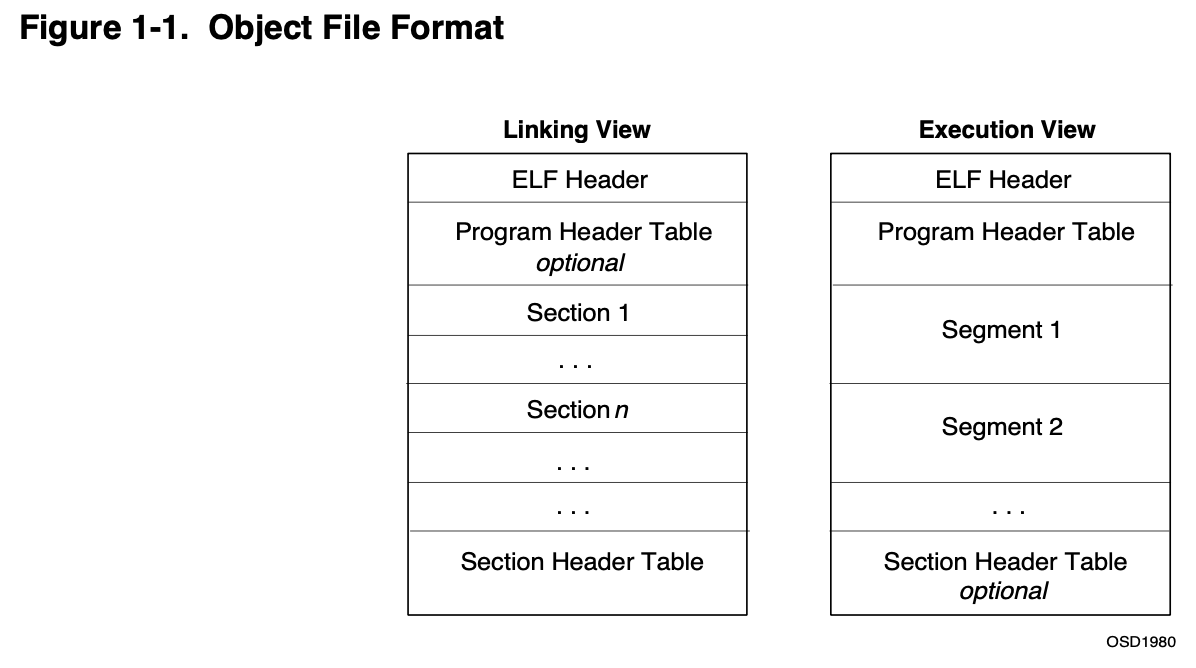
在ELF文件的开始是ELF Header,提供了ELF文件的总体布局。
Section header table包含了文件中的所有Section信息,文件中的每个section都对应着section header table中的一个entry,每个entry包含了section的描述信息,包括name、size等。Section对于linking阶段有意义,提供了instruction、data、symbol table、relocation information等对于链接而言必要的信息,因此每个参与链接的文件都必须包含section header table。
Program header table指导系统如何创建process image。用于创建process image的目标文件,也就是so文件和可执行文件,必须包含program header table,可重定位文件则不必。
Note: 上图中各个部分是紧密排布的,实际的目标文件中,除了ELF Header必须出现在文件开头外,其他部分的位置都是很自由的,只要在ELF Header中正确指定了各个部分的位置即可。
Data Representation
目标文件格式支持各种32位处理器。除此之外它还被设计成可以扩展到字宽更大(64位)或更小(16位)的架构。为了实现这个目标,ELF文件中的control data部分被设计为机器无关格式,让不同的机器都能够解析这部分内容。其他部分则是平台相关的,使用平台自身的编码方式(32位、64位、little endian、big endian等,这样做的好处应该是可以直接mmap进内存,并映射到POD数据结构进行处理)。
目标文件中的所有数据结构都遵循对应类型的size和alignment规则。必要时会填充0字符来满足alignment规则,确保所有alignment=4的数据都位于4的倍数的内存位置上。
出于可移植性的考虑,ELF不使用bit位。
ELF头
目标文件中的一些control structure可以长于定义的大小,因为ELF头里面包含了它们的大小信息。实际的目标文件中的control structure比预定义的大,处理目标文件的程序可以简单的忽略多出来的部分。至于比预定义小时,具体的行为没有统一定义,一般不会这么干。
- e_ident - identification
- elf文件最初的几个字节,提供了设备无关的描述信息,由以下部分组成:
- EI_MAG,固定的四字节: 0x7F, ‘E’, ‘L’, ‘F’
- EI_CLASS,一个字节,描述目标文件目标平台位数
- EI_DATADATA,一个字节,描述目标文件字节序
- EI_VERSIONVERSION,一个字节,目前固定为EV_CURRENT
- EI_PAD,剩余的9个字节,保留,全部以0填充,未来可能有用
- elf文件最初的几个字节,提供了设备无关的描述信息,由以下部分组成:
- e_type
- elf文件类型,描述elf文件是可重定位文件、可执行文件、so文件还是其他平台自定义文件类型
- e_machine
- 目标平台架构
- e_version
- ELF格式版本,目前ELF只发布了一版规范,因此这里要写成1
- e_entry
- 执行入口地址,是一个虚拟地址,表示当系统执行该目标文件时,应该将控制转移到该位置处执行
- e_phoff - program header offset
- e_shoff - section header offset
- e_flags
- 平台相关的flag
- e_ehsize - elf header size
- 当前elf头大小
- e_phentsize - program header entry size
- 每一个program header entry的大小
- e_phnum - program header number
- 在program header table中的entry数量
- e_shentsize - section header entry size
- e_shnum - section header number
- e_shstrndx - section header string index
- 这个字段的具体含义要参考Sections和String Table的说明。
Sections
目标文件的section header table用于定位文件中的所有section,section header table由一组struct Elf32_Shdr组成。
在目标文件中,其他数据有时会通过section在section header table中的索引来引用section,存在一些特殊的索引值表示特殊的含义:
- SHN_UNDEF = 0
- 表示undefined,如果一个symbol仅被声明但是没有被解析,该symbol关联的section索引值就是SHN_UNDEF
- SHN_ABS = 0xfff1
- 表示不受relocation影响
- SHN_COMMON = 0xfff2
- 表示未初始化的符号
- 0xff00 ~ 0xffff 之间的索引值是保留的,其中 0xff00 ~ 0xff1f 之间的值是为平台保留的
一个Section header项的数据结构定义如下: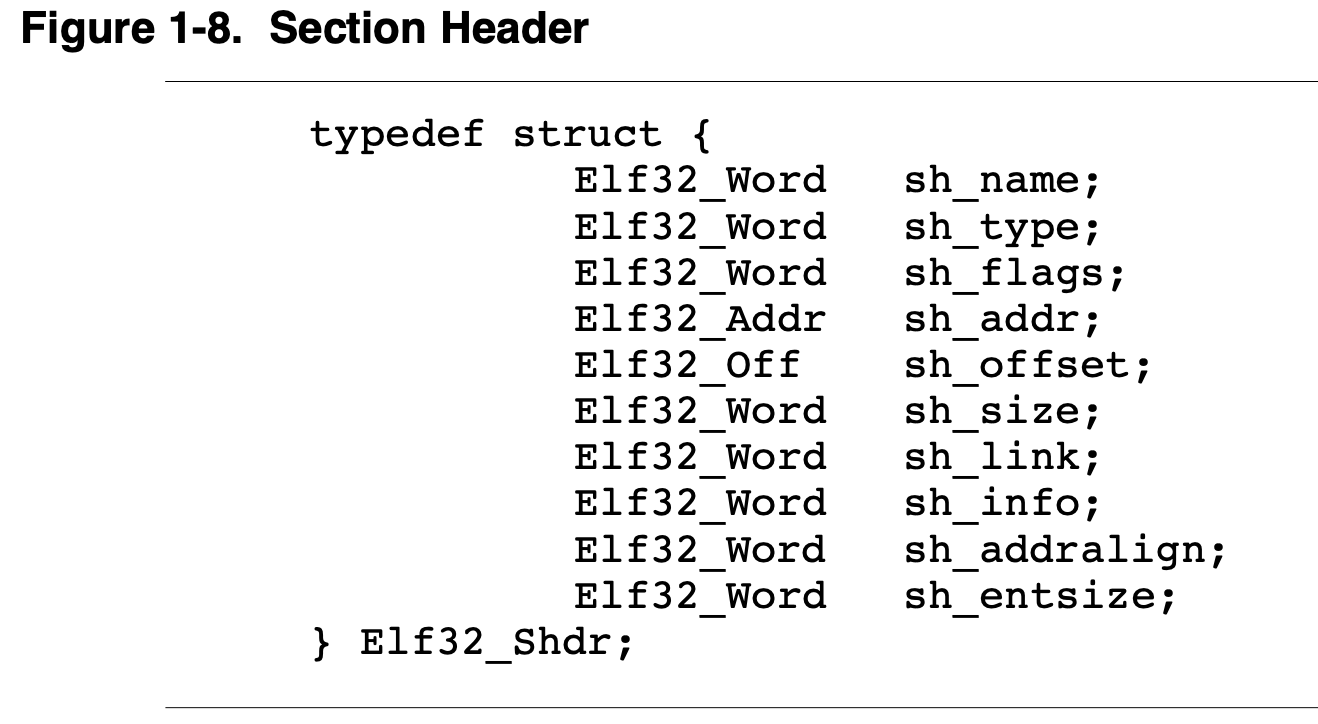
- sh_name
- section名称,是一个相对section header string table section起始位置的offset
- sh_type
- section类型,ELF spec中规定了一些标准的section类型,不同类型的section中存放不同目的的内容
- SHT_PROGBITS
- SHT_SYMTAB / SHT_DYNSYM
- SHT_STRTAB
- SHT_RELA / SHT_REL
- SHT_HASH
- SHT_DYNAMIC
- SHT_NOT
- SHT_NOBITS
- SHT_SHLIB
- 其他保留类型,从SHT_LOPROC一直到SHT_HIUSER,一部分是为平台保留的,一部分是为应用程序保留的
- sh_flags
- SHF_WRITE
- SHF_ALLOC
- SHF_EXECINSTR
- sh_addr
- 如果section会被加载进process image,该字段表示该section应该被加载到的内存地址,如果section不需要被加载到process image,该字段取0
- sh_offset
- section位置,是section相对目标文件起始位置的offset
- 对于SHT_NOBITS这种特殊type的section,由于这种section其实只存在header,但不存在section本身,因此该字段表示逻辑上的一个位置(就是没什么用呗。。。)
- sh_size
- section大小,大小用section所占字节数衡量
- 对于SHT_NOBITS这种特殊type的section,该字段表示的其实是这个section被加载进process image后在process image内存中占的大小,而不是section在目标文件中的大小,毕竟section本身在目标文件中是不存在的
- sh_link
- 具体含义取决于sh_type,默认取SHN_UNDEF
- sh_type = SHT_DYNAMIC - 指向关联的string table section在section header table中的索引
- sh_type = SHT_HASH - 指向关联的symbol table section在section header table中的索引
- sh_type = SHT_REL / SHT_RELA - 指向关联的symbol table section在section header table中的索引
- sh_type = SHT_SYMTAB / SHT_DYNSYM - 含义是平台相关的
- sh_info
- 具体含义取决于sh_type,默认取0
- sh_type = SHT_REL / SHT_RELA - 指向重定位要修改的section在section header table中的索引
- sh_type = SHT_SYMTAB / SHT_DYNSYM - 含义是平台相关的
- sh_addraligh
- section对齐要求,0和1表示不需要对齐
- sh_entsize
- 有的section内保存的是连续的大小固定的entry,该字段表示这样的section中每个entry的大小,如果section不是上面描述的那种section,该字段取0
Special Sections
存在不少预先定义好的section,这些section会由操作系统直接使用,不同的操作系统定义有不同的section。这些特殊section都是由一个英文句号开头的(这类section名都是系统保留的),包括:
- .bss
- .comment
- .data .data1
- .debug
- .dynamic
- .hash
- .line
- .note
- .rodata .rodata1
- .shstrtab
- .strtab
- .symtab
- .text
可执行文件是通过多个目标文件和库文件链接生成的。在链接阶段linker会从所有的依赖中解析出所有符号引用,确定它们每个符号引用的内容,调整指令和引用。
每个操作系统都支持一系列链接方式,但所有链接方式都可以最终被分为两类:
- Static,链接的最终结果是一个自包含的可执行文件,是由一系列的目标文件和静态库文件链接生成的,所有的符号已经全部解析完毕,并且都被包含在了该可执行文件内部,该文件不需要依赖其他动态库即可执行;
- Dynamic,链接过程中有动态库文件参与,在执行时必须要先加载动态库文件,然后程序才可以正常运行。
String Table
String Table是一种特殊的section,这个section内存放着一系列C风格字符串。当其他section用到字符串时,都是通过提供一个string table section的offset来引用某个字符串的。
string table section的起始处必须是一个空字符串,这样就可以令string table section offset = 0表示null或者空字符串。
Symbol Table
符号表中存储着对于定位和重定位程序的符号而言必要的信息。
一个symbol table entry的结构如下:
- st_name
- 指向目标文件string table的索引,表示符号名称
- st_value
- 该字段的具体含义取决于上下文:
- 在可重定位文件中,如果st_shndx为SHN_COMMON,则表示当前符号是一个仅声明未定义的符号,没有初始值,此时st_value字段表示该符号值的alignment要求;
- 在可重定位文件中,如果st_shndx为正常section索引,则表示当前符号是一个有初始值的符号,此时st_value字段表示距离section起始位置的offset;
- 在可执行文件和so文件中,st_value字段表示虚拟地址。
- 该字段的具体含义取决于上下文:
- st_size
- 很多symbol都是定义了大小的,这个字段描述符号占多少字节
- st_info
- symbol的type和binding都编码在这个字段中
- type被编码为最后4个bit,type描述symbol的类型:是object、function、section还是其他平台自定义类型
- binding为编码为前12个bit,binding描述symbol在链接阶段的可见性和优先级:是local(STB_LOCAL)、global(STB_GLOBAL)、weak(STB_WEAK)、还是平台自定义值
- st_other
- 保留,固定为0
- st_shndx
- 每个symbol都和某个section关联,这个字段是关联的section索引
- 该字段取预定义的特殊的section索引值时表示的含义是分别定义的:
- SHN_ABS,该符号的value不会因为重定位而改变
- SHN_COMMON,该符号没有初始值,因此st_value不表示符号address,而是表示符号的alignment要求,而st_size则表示符号值会占用的字节数;
- SHN_UNDEF,该符号是undefined,等待后续链接时去解析。
Relocation
Relocation是将符号引用和符号定义进行关联的过程。可重定位文件的目的是参与链接,必须提供信息以支持修改section内容,这样链接后得到的可执行文件和so文件才能够有正确的program image。
Relocation Entries提供了修改section所必须的信息:
- r_offset
- 指定重定位在哪里发生,对于可重定位文件而言是距离section起始位置的offset,对于so和可执行文件而言是虚拟地址,重定位作用于哪个section是由relocation section名称所指定的,例如.rel.text这个section就是用于对text section进行重定位的
- r_info
- 该字段提供了:这个重定位项对应的符号在symbol table中的索引,以及重定位的类型,两部分各占8bit
- 重定位类型的具体定义是平台相关的,具体定义要参考附录部分
- r_addend
- 定义一个常量加数,用于计算最终应该被存储到重定位字段中的值
- 有的平台可能会使用该字段,有的则不会使用,会直接将重定位字段原来的值当作addend,因此会存在两种relocation entry定义
一个relocation section引用了另外两个section:一个是symbol table,一个是要进行重定位的section。
Program Loading and Dynamic Linking
(spec的这部分描述不太完整,因为大量的细节都要结合操作系统和处理器平台讨论,这部分内容需要和后面的操作系统以及Intel部分结合起来看。)
这一章主要描述目标文件中,为了支持将程序加载到process image中而存在的那部分内容,以及系统在链接和加载阶段做了哪些动作。目标文件中的program header table是直接和程序的加载相关的,定义了程序中哪些section需要被加载到process image,并定义了加载过程中所需要的信息。
给定一个目标文件,系统必须首先将目标文件加载到内存中才能开始执行它。在此之后,系统还要解析目标文件的所有符号引用(符号引用的概念应该仅存在于dynamic executable file中,对于static executable file,所有符号引用已经在linking阶段被替换为绝对的虚拟内存地址了)。
Program Header
可执行文件或者so文件中定义了program header table,这是一个struct Elf32_Phdr组成的数组,每一项描述目标文件中的一个segment,注意和section区分,segment是一个或多个section的聚合。Program header仅对可执行文件或so文件有意义。
struct Elf32_Phdr定义如下:
- p_type
- segment类型
- PT_NULL
- unused segment,loader忽略这种类型的segment
- PT_LOAD
- loadable segment,loader将这类segment加载到process image
- 如果p_memsz比p_filesz更大,没有定义具体内容的内存会被0填充,p_filesz不可以比p_memsz大
- 这类segment必须以p_vaddr字段升序定义在program header table中
- PT_DYNAMIC
- dynamic linking,segment内容是一个dynamic section,dynamic section的内容是struct Elf32_Dyn数组,由于dynamic linking是和操作系统紧密相关的,具体细节在后面的操作系统Spec中介绍dynamic section时说明
- PT_INTERP
- program header entry用于指定加载器路径,后面在操作系统Spec中介绍loading过程时有进一步介绍
- PT_NOTE
- program header entry用于说明补充信息的位置和大小,segment内容是一个note section,参考下面的Note Section
- PT_SHLIB
- 保留type,System V禁止ELF文件中出现该type
- PT_PHDR
- segment的内容是program header table本身,这个segment header负责给出segment的位置和大小
- 存在的意义是支持将program header table加载到process image中,因为对于dynamic executable而言,在执行时需要检查program header table中的p_type=PT_INTERP的program header entry定义才能继续执行
- 这个类型的program header entry如果存在,必须定义在任何其他loadable segment header之前
- p_offset
- segment位置,位置是从目标文件开头算起的offset bytes
- p_vaddr
- segment被加载到process image后,应该位于的虚拟内存地址
- p_paddr
- segment的physical address,具体含义是平台相关的
- 在virtual address统一天下的今天,这个字段应该没意义了,其取值和含义一般都是unspecified
- p_filesz
- segment在目标文件中所占的大小
- p_memsz
- segment在process image中所占的大小
- p_flags
- PF_X - execute
- PF_W - write
- PF_R - read
- p_align
- segment的alignment要求,p_addr和p_offset都应该遵守该alignment要求
Note Section
vendor有时候希望在目标文件中嵌入一些特殊的信息,用于标记文件的兼容性等,类型SHT_NOTE的section或者类型为PT_NOTE的segment用于保存此类信息,此类的section或者segment内容是若干”note information”,这是一个由若干个4-byte word构成的数据结构,其格式描述如下:

- namesz & name
- namesz是一个数字,占4字节,用于规定下面的name部分的大小,name部分如果大小不是4的倍数,要用0填充padding;
- 如果没有name,namesz应该为0,此时name部分不存在;
- descsz & desc 同上
- type 应用自定义字段
操作系统spec(Unix System V Release 4)
这一部分描述System V操作系统上专门定义的elf spec。
Object Files
Sections
Symbol Table
当linker处理多个relocatable object file时,禁止同时出现多个STB_GLOBAL符号;当glbal和weak符号同时出现时,weak符号被忽略。此外,当同时出现SHN_COMMON符号和weak符号时,weak符号也会被忽略。
当linker处理archive library(静态库文件)时,只会从静态库文件中寻找未解析的global符号定义,这个符号可以是global的或者weak的;未解析的weak符号定义不会导致错误,也不会从archive library中查找。
Program Loading and Dynamic Linking
Program Header
Base Address
可执行文件中包含绝对地址,而so文件中一般包含的是相对地址。这意味着可执行文件中的program header定义的segment虚拟地址位置必须要能够和process image中的虚拟地址位置对应,系统会定义一个base address,可执行文件中的segment在计算虚拟地址位置时,会根据base address以及page大小进行计算。
Dynamic Linking
Program Interpreter和Dynamic Linker
使用了动态链接技术的可执行文件必须有一个program type=PT_INTERP的program header项。在程序开始执行时,系统从PT_INTERP解析出一个目标文件路径,这个目标文件就是interceptor,也就是dynamic linker,动态链接器,dynamic linker的路径信息是在可执行文件编译时,由linker写入的。当系统读取到dynamic linker路径后,会将dynamic linker的segment加载到process image中,然后将控制权交给dynamic linker,接下来dynamic linker要负责准备好程序的运行环境,然后再把控制权交给程序入口。
系统将控制权转交给dynamic linker有两种方式:将一个打开的可执行文件fd交给dynamic linker,或者将可执行文件读取到内存后再将控制权交给dynamic linker。dynamic linker文件本身可以是一个so或者可执行文件,dynamic linker本身禁止依赖另一个dynamic linker。
- 如果dynamic linker是一个so文件,系统会确保将so文件加载到不和原process image segment重叠的虚拟内存地址处;
- 如果dynamic linker是一个可执行文件,由于可执行文件必须被加载到事先写在目标文件里的虚拟内存地址处,因此dynamic linker可能和原process image segment重叠,dynamic linker必须要负责处理好这种冲突问题。
可执行文件和dynamic linker在程序启动时共同完成了如下工作:
- 将可执行文件的segment读取到process image中;
- 将so文件的segment读取到process image中;
- 处理可执行文件和so文件的relocation项;
- 关闭打开的可执行文件的fd;
- 将控制权转移给可执行文件,让可执行文件感觉程序启动时控制权是直接交给它的一样。
linker在构建可执行文件和so文件时构造了很多用来帮助dynamic linker的数据。和上面的Program Header部分介绍的一样,这些数据位于loadable segment中,从而在程序执行期间会被加载进process image中,是执行期间可见的。
- 一个section header type=SHT_DYNAMIC的名为.dynamic的section中存放着上述各种数据。section开头部分的数据结构里保存着其他dynamic linking数据的位置;
- 名为.hash的,type为SHT_HSAH的section中存放着符号的hash table,hash table内容参考后面的Hash Table章节;
- 名为.got和.plt的,type为SHT_PROGBITS的sections,分别保存着global offset table以及procedure linking table,这两张表都是为支持position-independent code而存在的,dynamic linker的工作用到了这两张表。
附录的Program Loading章节里描述了so文件可能会被加载到和目标文件program header中定义的虚拟地址不同的其他虚拟地址处。这导致so文件,和用到了so文件的其他目标文件,在引用内部符号时可以使用相对地址,但在引用外部符号时,还是必须使用绝对地址,并且这个绝对地址只有在so文件被加载到process image之后才能知道,因此确定绝对地址的责任就落到了dynamic linker头上,这项工作被叫做dynamic linker重定位。
默认情况下,dynamic linker会在程序执行期间尽可能晚的(也就是用到的时候)完成dynamic linker重定位工作。但是可以通过将LD_BIND_NOW环境变量设置为任意值来让dynamic linker在程序启动时完成重定位,这样有助于及早发现unresolved function reference,即使一个函数没有被调用到,也会在程序启动时报告错误。
Dynamic Section
用到了dynamic linking技术的目标文件的program header table中必须有一项PTDYNAMIC类型的element,这项element指向的segment内容是一个名为.dynamic的section。此外elf还规定要定义一个_DYNAMIC符号,指向由所有dynamic structure组成的数组:
在这个数据结构中,d_tag表示该项数据的作用,d_un则根据d_tag确定有意义的是d_val还是d_ptr,其中d_val表示普通数字值,而d_ptr表示虚拟内存地址。
d_tag可选的值都以DT开头,包括以下这些,具体的含义这里就先略过(因为实在是太多太杂了,后续补充下),这些都是为了指导dynamic linker完成运行时重定位而准备的:
Shared Object Dependencies
静态链接的目标文件执行期间不需要初该目标文件之外的任何其他信息,因为linker在编译期间已经将所有静态依赖的信息拷贝到目标文件里了,但是用到共享目标文件so时,dynamic linker必须将所有依赖的so,包括可执行文件本身依赖的so,已经so依赖的其他so,挨个加载到process image中。在用到了动态链接技术的可执行文件中,以及在so文件中,必须定义它们的依赖(由dynamic section中的DT_NEEDED tag提供)。
当需要解析一个符号引用时,dynamic linker会按照breadth-first(广度优先)规则搜索符号表,即首先在可执行文件内部查找该符号,然后再去当前目标文件的DT_NEEDED依赖中查找,如果还没找到,接着再从每个依赖文件的DT_NEEDED中查找。
so文件必须是可读的,除了可读之外没有其他权限要求。
同一个so文件,即使被多次依赖,它本身也只会被dynamic linker加载一次。
在linker链接多个so时,会将每个so的DT_SONAME复制到目标文件中,name可以是文件名或者路径。如果name是一个绝对路径,dynamic linker会直接使用该路径定位so文件,如果name是一个文件名,dynamic linker使用如下的机制寻找该目标文件:
- 首先,DT_RPATH可能提供了一组用冒号分隔的目录路径,例如
/home/dir/lib:/home/dir2/lib:,这种情况下dynamic linker会首先尝试从这些目录中寻找依赖的so文件; - 其次,环境变量中可能定义了LD_LIBRARY_PATH,其值为用分号或冒号分隔的目录路径,例如
LD_LIBRARY_PATH=/home/dir/lib;/home/dir2/lib:,这些路径会在DT_RPATH之后被搜索; - 最后,如果前面两步都没找到so文件,会去搜索/usr/lib目录。
需要注意,为了安全考虑,以set-user和set-group id执行的应用程序不会尝试从用户的环境变量里搜索so文件,也就是说这种情况下LD_LIBRARY_PATH会被忽略。
Global Offset Table
Procedure Linkage Table
以上两章在操作系统Spec部分都只做了简单的介绍,在附录中对应的章节有详细的讨论。
Hash Table
Hash Table这个section内存放的通常是如下的数据结构,这个数据结构具体的定义并不属于spec的一部分,这里提供一种示例来解释Hash Table section的工作原理: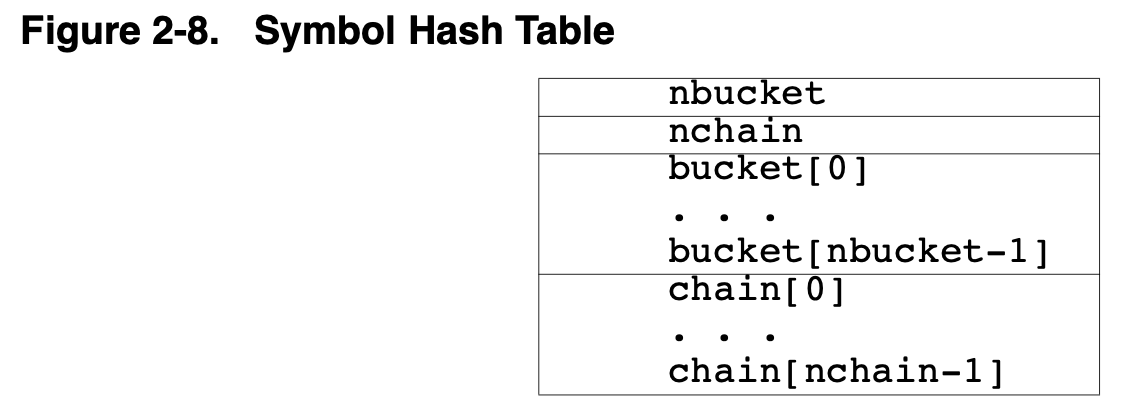
spec中这部分的描述较简略,这里有更详细的解释:https://flapenguin.me/elf-dt-hash
symbol hash table中的bucket数量就是hash桶的数量,桶的数量一般来说应该根据符号数量来确定,在空间利用率和查找时间之间寻求平衡,当需要寻找符号表中的某个符号时,会根据一个hash函数计算一个hash值,确定bucket索引,bucket内存储了一个symbol table以及chain的数组索引,如果symbol table中对应的符号和要寻找的符号不匹配,则继续去检查chain指定的下一个bucket,不断重复该过程来寻找符号表中的对应项。
为了让上述的查找过程能够工作,symbol hash table中的chain数组长度和对应的symbol table符号数量一致,linker根据符号表建立hash table的chain数组,在多个符号的hash冲突时,会将chain的值设置为下一个hash冲突的bucket索引,这样就可以通过追踪chain来最终确定符号了,如果最终到达了0号bucket索引,则表示符号没有定义,因此同一个hash的符号,其chain的最后一项内容为0,即表示符号未定义。
GNU开发了更优秀的symbol hash table,增加了bloom过滤器支持,但GNU的hash table没有文档,也不属于标准的一部分,只能从源码和源码中的注释了解其实现。
Initialization and Termination Functions
so文件在被dynamic loader加载完毕后,在控制权被转交给应用程序前,可以执行初始化工作。so文件依赖的其他so文件的初始化会先于该so文件执行,但当存在循环依赖时,具体的初始化顺序是undefined,因此如果不想写bug就别依赖多个so文件的初始化函数执行顺序。
so文件也可以定义销毁函数,在进程通过atexit过程结束时,dynamic loader确保所有销毁函数会按照和初始化函数调用顺序相反的顺序被执行,并且会在用户定义的atexit函数之后执行。需要注意的是,进程很可能不通过atexit终止,例如在收到某些特殊signal时,进程就会直接通过_exit终止,此时销毁函数不会执行。
dynamic section中的DT_INIT和DT_FINI用于指定so的初始化和销毁函数。
dynamic loader不会调用可执行文件中定义的初始化和销毁函数。
附录A Intel和System V spec
这一部分描述同时依赖Intel平台和System V操作系统的ELF Spec部分。
Relocation
Program Loading and Dynamic Linking
Program Loading
系统在初始化process image,或者在将一个so附到process image上时,会将目标文件的segment加载到虚拟内存中,当系统真的读取到这块内存时,物理内存页才会通过虚拟内存管理机制加载。为了能够和虚拟内存机制配合工作,目标文件的每个segment必须按照虚拟内存页的尺寸进行对齐。
在32位Intel处理器上,虚拟内存页通常大小是4KB,也就是0x1000个字节,因此所有segment的起始和结束内存地址都必须是能够整除0x1000的地址。运行在32位Intel处理器上的Unix操作系统通常会以0x8048000这个虚拟内存地址作为可执行文件加载的基地址,应用程序的loadable segment通常会被加载到该基地址上。
上图是一个典型的可执行文件被加载到process image的场景,可以看到虽然第一个loadable segment是text segment,但是为了满足page对齐需求,ELF Header和Program Header Table部分,包括中间的其他数据,都被作为首个page的一部分被加载到text segment page中了,因此同样的文件内容可能会以不同的权限flag被mmap多次。类似的情况可能发生在每个segment的起始和结束处。
可执行文件和so文件的加载存在差异。
可执行文件加载时,必须确保将每个segment加载到事先确定好的虚拟内存地址处,因为可执行文件的所有地址通常都是绝对地址,不可被加载到和segment的p_vaddr指定的位置不同的其他内存地址处;
另一方面,so文件的segment通常包含的都是位置无关代码,在引用同一个文件中的符号时都是使用的相对地址,因此可以被加载到任意基地址处,只要确保目标文件内的segment相对位置严格不变即可。
上面的讨论仅涉及目标文件内部符号,当使用了其他目标文件中定义的符号时,是一定需要dynamic linker的重定位协助的。
Global Offset Table
pic目标文件不可以包含绝对虚拟内存地址。got负责将绝对虚拟内存地址维护在单独的每个process image中,确保目标文件的位置无关代码本身是可共享的。got这个section和text section的相对位置是确定的,因此在代码中可以使用相对地址引用got,从而引用绝对地址。
最初got中保存着需要由重定位修改的信息,dynamic linker在加载好so之后会处理重定位,重定位项中的R_386_GLOB_DAT项就是负责维护got表的。在linker链接期间,动态链接进来的其他库的符号地址是未知的,因此linker只负责建立重定位项,每当需要使用符号的绝对地址时(也就是用到没有在本目标文件内定义的符号时),都会为该符号建立got项和重定位项;在dynamic linker加载好so之后,才能确定符号的绝对虚拟内存地址,此时dynamic linker负责计算重定位项要求确定地址的符号的地址,并将地址填到重定位项要求填入的位置,即got表内。
用到动态链接的每一个目标文件都有自己的got,dynamic linker必须要在转交控制权给可执行文件前,把所有got表都按照重定位表的要求填充好。这样在程序运行时,就能通过got表引用其他目标文件的符号了。
got表的第一项(0号索引)是DYNAMIC符号的地址,这允许dynamic linker能够直接找到dynamic section,方便让dynamic linker在当前目标文件还没有完成重定位的情况下获取动态链接库初始化所需的信息。在Intel架构下,后面的两项也是保留的,用于支持procedure linkage table。
elf spec规定必须定义一个名为_GLOBAL_OFFSET_TABLE的符号,指向GOT。
Function Addresses & Procedure Linkage Table
一个以pic模式编译的目标文件内部调用函数时,是使用函数的相对地址调用的,但是如果该目标文件被另一个可执行文件依赖,在可执行文件的代码中不可以使用相对地址。在编译时,linker会将函数符号解析到当前目标文件中plt表中的一项的地址处。
应用程序会以两种方式用到函数:取函数地址,或者调用函数。
对于取地址这种操作,如果要取的是一个其他动态库中定义的函数的地址,linker在编译期间是无法得知函数的绝对地址的,此时linker只好在符号表中将函数符号记录为SHN_UNDEF类型的,并将st_value指向函数在plt中的对应项。这意味着,在不同的目标文件中,尝试打印某个外部目标文件定义的某个函数时,即使它们都打印的是同一个函数的地址,实际打印出来的函数地址也是不同的,因为对于外部函数,其地址是plt表中对应项的地址。
对于函数调用这种操作,如果被调用的函数是定义在其他动态链接进来的目标文件中的,linker在链接时会令函数调用地址指向plt中的对应项,plt中存放着负责解析函数符号并调用的代码。这实际上是在前面描述的dynamic relocation之上的针对函数调用的性能优化,为了避免在so加载时解析所有函数符号的重定位项,将重定位推迟到了函数调用时。pic的动态链接库的函数调用过程比较复杂,可以分为如下几步:
- 将got表地址放到%ebx,然后将控制权交给plt中函数对应项;
- plt项的第一条指令将控制权转交给got中的函数符号对应项;
- got中的函数符号对应项存放的是指向跳过来的plt项下一个指令的地址,因此控制权又被重新还给plt项;
- plt项的接下来的指令负责将函数符号项在符号表中的offset压入栈,然后跳转到plt的第0项;
- plt第0项内的指令负责将4(%ebx),也就是got的第二项压入栈里,然后跳转到8(%ebx)处,继续执行got的第三项中的指令;
- got从栈里取出符号offset,从符号表找到符号,计算出符号的绝对地址,将绝对地址写入到got中符号的对应项,最后将控制权转交到函数绝对地址处;
- 下一次调用函数时,由于got项里保存的内容已经被修改为函数的绝对地址,因此能够直接根据该地址完成跳转。
和pic动态链接库中的函数跳转相关的重定位项类型是R_3862_JMP_SLOT。当LD_BIND_NOW环境变量被设置上时,在so加载时就会完成所有该类型的重定位解析,从而在加载时确定函数地址,将其地址填入got。这样,就不需要像上面描述的那样在plt和got之间来回跳转,完成函数地址解析了。尽管如此,调用其他动态链接进来的库的函数依然比本目标文件内的函数调用多了一次跳转,普通函数是直接跳转到函数,而调用其他库的函数则是先跳转到plt,再由plt加载got内的函数地址,跳转到函数。

若有收获,就点个赞吧
0 人点赞
