https://kaiwu.lagou.com/course/courseInfo.htm?courseId=1414
- 内核态线程适用于计算密集型任务;
- 用户态线程(协程)更适用于 IO 密集型任务。
在各大厂的面试中:进程、线程、协程这三个概念经常被问到,我戏称其为“面试官操作系统三板斧”。
如果你是一个有经验的开发,我相信你对这“三板斧”并不陌生,但是很多人在真正面试时却答不上来。你可以回忆下你的面试过程,是不是也发现被这几个概念扫射到了?所以,如何更好地理清这些概念,成了大家在求职前亟待解决的问题之一。
简单地扔出一些概念来让人背总是很容易的,但是这对你来说收获有限。本文将尝试从演进的角度来说明这些概念的产生,由来,以及它们要解决的根本问题是什么。
通过本文,你将获得:
- 什么是进程、线程、协程?
- 我们为什么需要了解这三个概念,它们的产生的原因是什么?
- 它们的应用场景分别是什么?什么时候应该用内核态线程,什么时候应该使用协程?
关于进程
什么是进程?进程是怎么由来的?又有哪些应用和发展?接下来我们从故事的最开始讲起。
进程的由来
所有的这一切都得从计算机出现早期开始讲起。大家可能都知道,最早的计算机程序是使用纸带穿孔来执行的。


图1. (上)程序的执行;(下)纸带穿孔程序
这种机器的执行流程是——
- 第 1 步:由计算机管理员把打好控的纸袋安装到计算机上
- 第 2 步:按下开机键,计算机就运转起来,一条语句一条语句地开始执行纸带上的指令。
- 第 3 步:程序执行直到结束,并最终输出穿孔纸带上的结果。
当时计算机的用户(User)也就是科学家们开始排队提交自己的程序。在沟通过程中,人们发现纸带穿孔程序(paper tape punching procedure)读起来实在是有点绕口,于是一般把它简称为 Program。而运行着的 program,也就是进程,计算机管理员们约定使用 Job、Task、Process 这样更简单的、好识别的称呼。这就是为什么我们在读 Linux kernel 内核源码的时候,经常看到 job、task_struct、process 这样的单词,这些都是指进程。
话说回来,在那个时候,即使一个非简单的程序,跑个一两天都是常有的事儿。用户们提交了程序,不可能一直坐在那里等,往往是把 Program 往计算机管理员的桌子上一扔,就回去等通知拿结果。时间长了,这个“堆满纸带穿孔程序的计算机管理员的桌子”也开始有了一个简单的称呼:task_list、job_list。
那么,计算机管理员的日常工作就是这样:
for task in task_list {run(task); // <-- process: 进程}
而这个管理员和他的桌子,可能是世界上最早、最简单的操作系统了。这时候的进程真正独霸了整个计算机,不用考虑何时需要把计算机让给其他应用程序;进程的管理、CPU 资源的分配也都不用考虑。
不过,这样简单而又美好的时期并不能维持多久,因为他们很快就遇到了一个问题。
进程的切换

如果所有的 task 都是高速运算,那我们只需要把 task_list 里面的 task 扔到计算机里,让它执行就可以了。然而并不是。总是有那么一些程序,假设有一个 program A,执行了 10 天之后,需要 User 输入一些信息,才能继续后面的计算。那在通知 User 到机房去执行输入的这段时间里,process 就会处于一个等待状态。
这个等待状态给管理员带来了以下思考:

- 此时这个 process (program A)独霸了整个计算机,其他要执行的 program B 肯定也在等待。
- 如果我们将计算机停机,加载并执行后面的 program B,那当重新执行 program A 的时候,一切又要从头开始,执行了 10 天的程序还得要重新跑。
- 而且不能保证 program B 就不会出现需要 User 进行输入的情况。
当这个棘手的问题摆在了计算机管理员面前时,人们不得不尝试考虑,是否可以将 program A 执行到 10 天时整个机器的状态保存下来呢?中间先执行 program B,下次要继续执行 A 的时候,就将这个保存起来的机器的状态恢复,继续执行 10 天后续的纸带穿孔指令。
这其实就是最早的进程切换问题。我们现在遇到的情形,只不过是当时的问题和解决思路的延伸罢了。
那么当时的管理员是如何解决问题的呢?首先,计算机管理员根据机器的特点,确认哪些信息是需要保存的:
new_process = clone(SIGCHLD, 0);// clone的时候,要求子进程退出时向父进程发信号。// 其他资源子进程必须要自己重新生成。
那么,每当进程被卡住,需要停下来进行手动输入的时候,计算机管理员先按下“保存”按钮,把当前的状态信息打印到一个纸带上。保存完毕之后,他就可以选择一个其他进程来执行了。那么,对于这个保存下来的内容,我们当然应该起个名字,就叫作进程上下文(process context),而保存并且切换到下一个待执行的进程,这个动作就被称之为上下文切换。
再进一步想一下切换问题,保存好当前的进程状态之后,下一个被执行的进程应该如何挑选呢?要知道,管理员的桌子上有那么多穿孔纸带,如果我们随便指定一个进程来执行,就会遇到这样一个问题:万一我们又一次挑中的进程还是缺少相应的输入,那怎么办?
因此,为了方便选择进程,我们还需要记录每个进程的状态。
struct pcb {int status;};
这里的 pcb 表示 Process Control Block,主要的作用就是让我们选择是否执行这个进程。
当然,现代的操作系统还能对进程做更多的控制,所以 pcb 能做的事情就更多了。在 Linux 内核中,“pcb”、“上下文”是如下安排的。
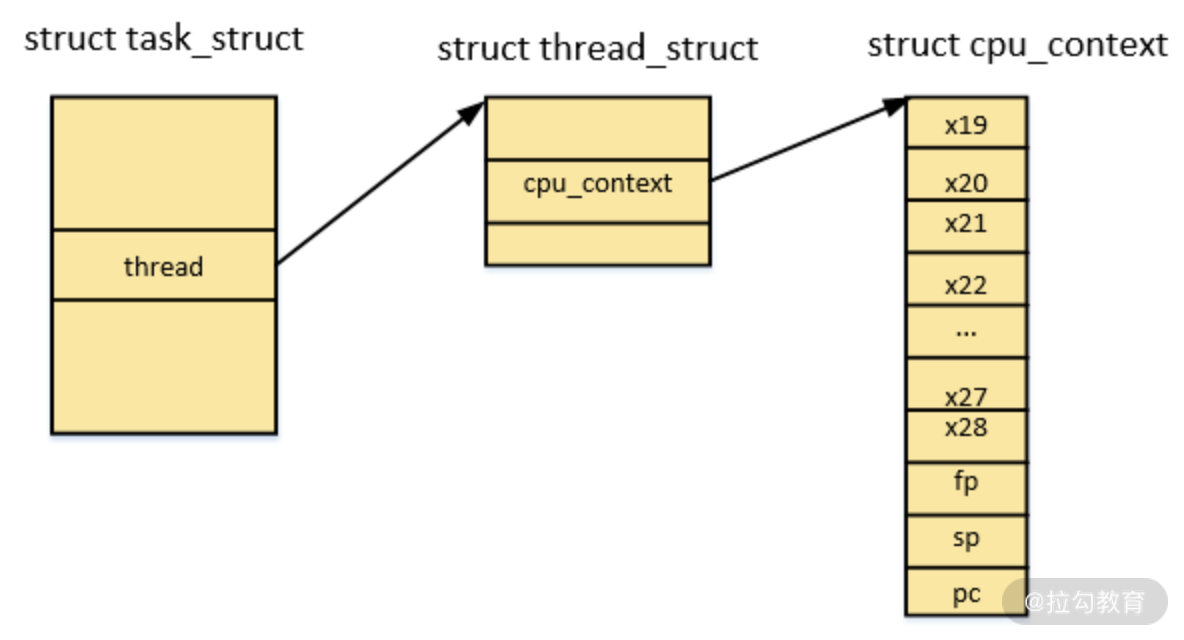
图2. Linux 内核的 task_struct 与 pcb,以及 context 的管理
备注:task_struct 更多记录进程与外界相关的信息,比如与其他进程的父子兄弟关系、信号处理、打开的文件等等。而 thread_struct 更多是记录进程自身的信息。
至此,我们这位计算机管理员已经能够很好地解决进程阻塞的问题了。
进程的 clone
在实际开发中,你的头脑里也许常常会冒出这样一个问题:为什么新生成一个进程的时候,Unix/Linux 系操作系统都喜欢用 clone?
为了方便理解,我们再回溯到纸带穿孔机的时代,那时候计算机的计算稳定性远远比不上现在。由于每次执行任务都需要开机,而开机当然需要执行一些自我检查的指令。糟糕的是,这部分指令由于写在用户的“穿孔”程序的开头,还给用户带来了一些困扰:

- 不同的机器,启动时的自检程序肯定是不一样的
- 用户只关心自己的核心计算程序,并不懂这部分自检查程序怎么写,也没有兴趣
所以对于用户来说,最省力的办法就是抄一份现成的程序,然后把核心代码换成自己的。就像现实生活中,当我们要填一个超复杂的表单的时候,最好是有一个 example 让我抄一下,我把这个表单里面核心的部分换成我自己的信息就完成了。这个抄的动作,生成新进程就叫做 clone。
就像抄表单一样,你可以抄不同的内容,在 clone 一个新进程的时候,你也可以选择抄不同的内容。比如 Linux 内核中:
new_process = clone(SIGCHLD, 0);// clone的时候,要求子进程退出时向父进程发信号。// 其他资源子进程必须要自己重新生成。
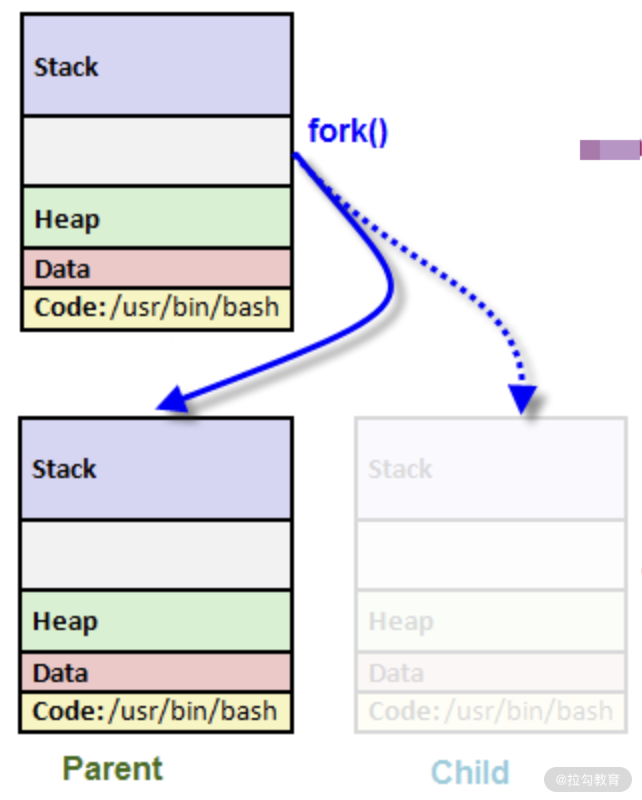
图3. 进程 clone 示意图
通过这种方式,就可以生成一个全新的进程。那么如何填上自己的核心代码呢?这个时候, Unix/Linux 系统会使用 exec 函数。
execv("/usr/bin/ls"); // <-- 执行查看程序
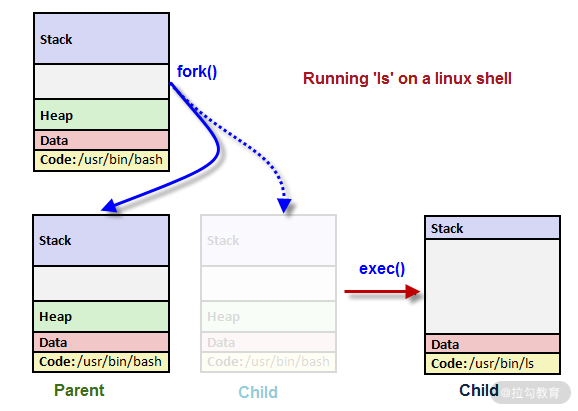
图4. clone 与 exec 的合作。
这样做,就解决了用户提交新程序的需求。
关于线程
直到有一天,有个用户提出了这样一个需求:
一条船上有两门炮:当一门炮在装填的时候,另外一门炮要开始瞄准和射击。
这个需求的难点在于:如果我们还是采用 clone+exec 的方法,就很容易出现两条船,每条船上只有一门炮。
如果解决呢?我这里有两种解决办法:
- 内核态线程
- 用户态线程
内核态线程
如果我们在 clone 生成新任务的时候,像下面这样,就在同一条船上生成了一门新的炮。
新的一门炮 = clone(共享船 | 共享桨 | 共享坐标, 0);
当然,计算机肯定是需要将“船,桨,坐标”等信息进行抽象的,比如抽象成内存、文件、信号,所以,真正的 clone 函数应该长这样:
new_process = clone(CLONE_VM | /*共享内存 */CLONE_FS | /*共享文件系统信息 */CLONE_FILES | /*共享打开的文件 */CLONE_SIGHAND, /*共享信号处理 */0);
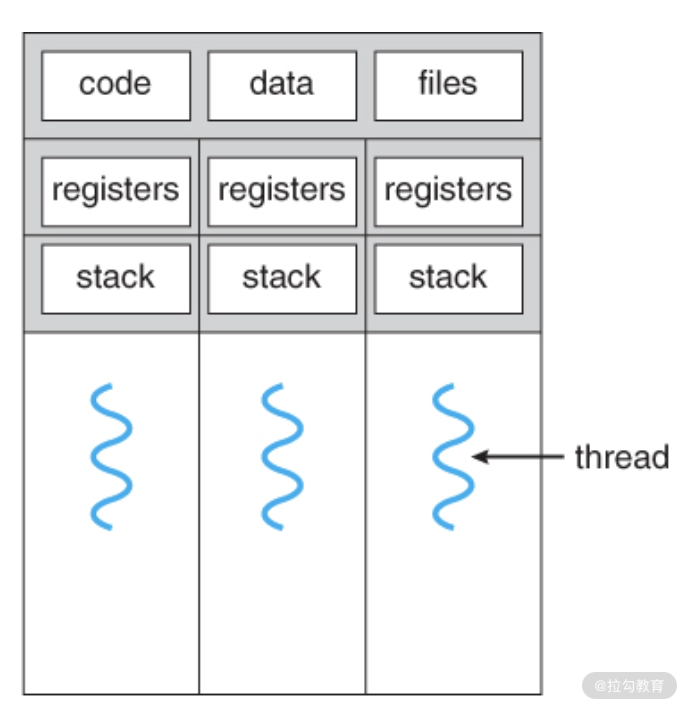
图5. clone 生成新的线程。
上图中 3 个线程共享了代码段、数据段、打开的文件,但是每个线程还是有一些独自己的资源,比如寄存器,栈。
我们发现,这个新生成的进程的资源分为两部分。
- 拥有的资源:操作系统会新分配 task_struct、thread_info、cpu_context、stack 给它。
- 共享的资源:内存、文件系统、打开的文件、信号处理。
像这样的进程,与前面的进程已经有所不同了,是时候该给它一个新名字了,于是我们称之为线程,或者叫内核线程。
不过,由于 Linux 在调度程序的时候,实际上采用的是如下策略:
for task_struct in task_list {if (task_struct can run)run(task_struct); // <-- process: 进程}
所以,从 Linux 内核的角度来看,进程与线程在调度运行的时候是没有区别的。
备注:其实大名鼎鼎的 fork() 函数就是简单地将 clone 包了一下。对 Unix/Linux 系统而言,pthread_create 创建线程,则是对 fork/clone 的进一步包装。

这里我们给线程/**内核态线程**一个定义——
操作系统的设计人员提出在进程内部添加可独立执行的单元,它们共享进程的地址空间,但又各自保存运行时所需的状态(寄存器、栈),这就是内核态线程。
注:这里我们要与 Linux 内核设计中的 kernel thread 这个概念进行区分。Linux 内核设计中的 kernel thread 指的是有一些进程永远都以内核态运行。这里不要混淆哦!
我们稍微总结一下内核态线程的优缺点:
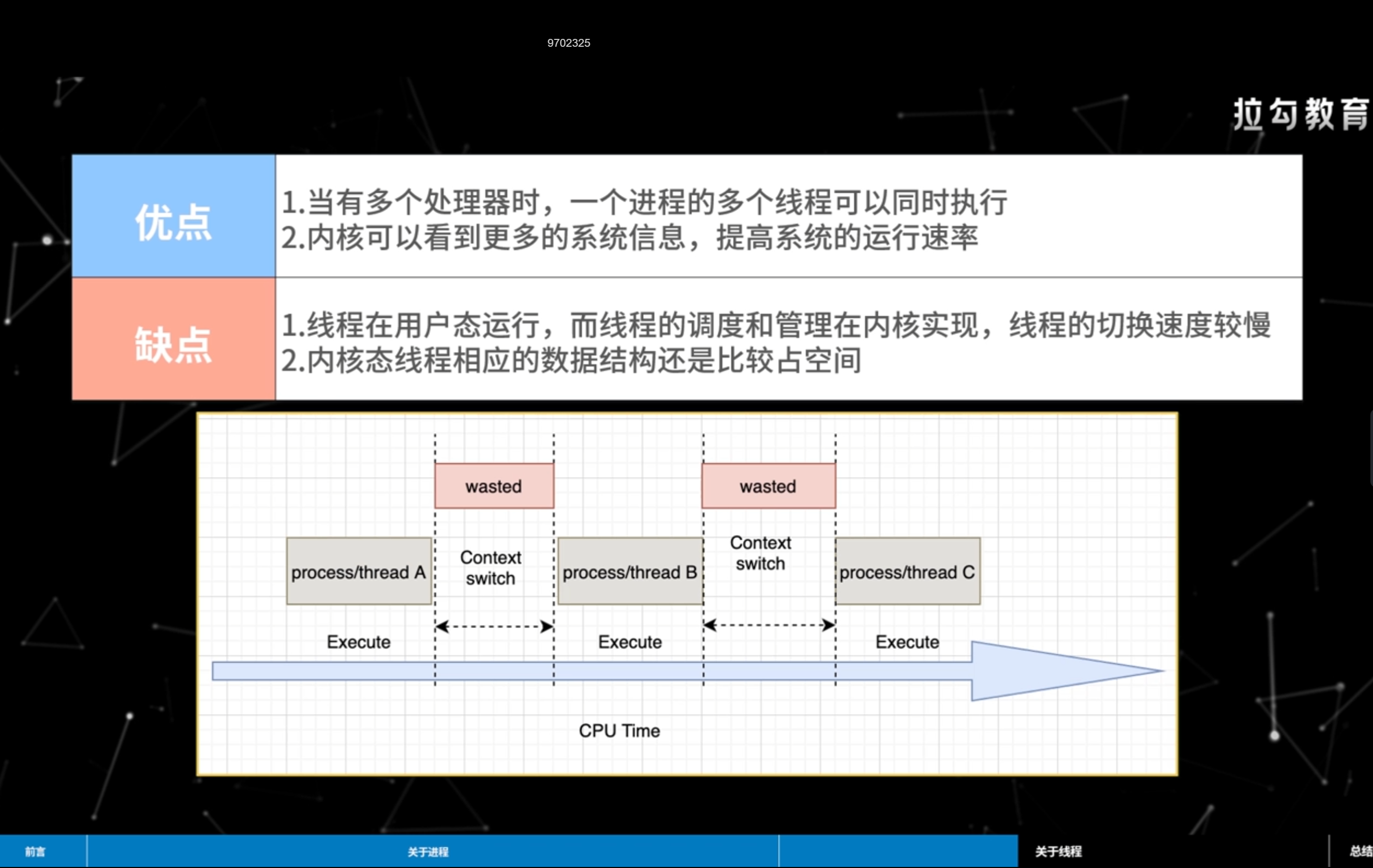
| 优点 | 1. 当有多个处理机时,一个进程的多个线程可以同时执行 1. 内核可以看到更多的系统信息,提高系统的运行速率 |
|---|---|
| 缺点 | 1. 线程在用户态运行,而线程的调度和管理在内核实现,线程的切换速度较慢 |
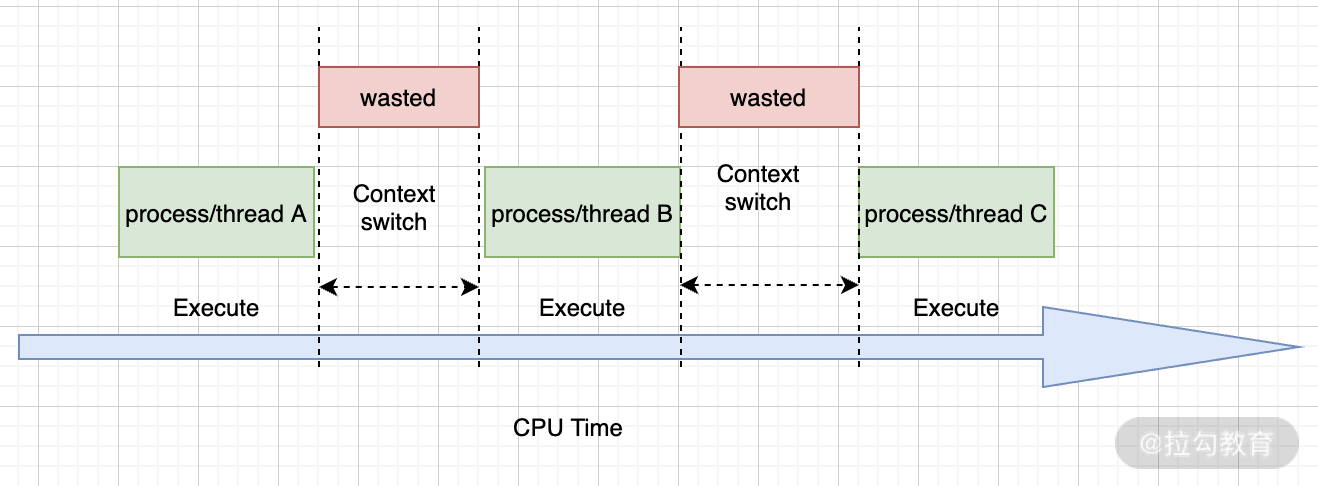
图6. 内核态较重的上下文切换导致开销较大
那么,有没有办法可以降低一些线程的开销呢?有!答案就是用户态线程!
用户态线程(协程)
首先我们理清一些概念:用户态线程与纤程(Fiber)、协程(co-routine, go-routine)这些概念大体是等价的,所以在下文中,我会交替使用这 3 个等价概念。
通过前文可知,内核态线程拥有一些自己的资源,比如 task_struct、thread_info、cpu_context、stack。
但是,如果这些本来属于操作系内核的资源,在用户态空间实现,并且调度也在用户态空间来执行,那么此时的线程就称为用户态线程,或纤程,或协程。
如果你问内核态线程与用户态线程的本质区别是什么?我的答案是——

- 内核态线程中,如果有 N 个线程,那么内核就会创建 N 个 task_struct;
- 用户态线程中,如果有 N 个线程,那么内核中还是只有 1 个 task_struct。
这里总结一下用户态线程的优缺点:
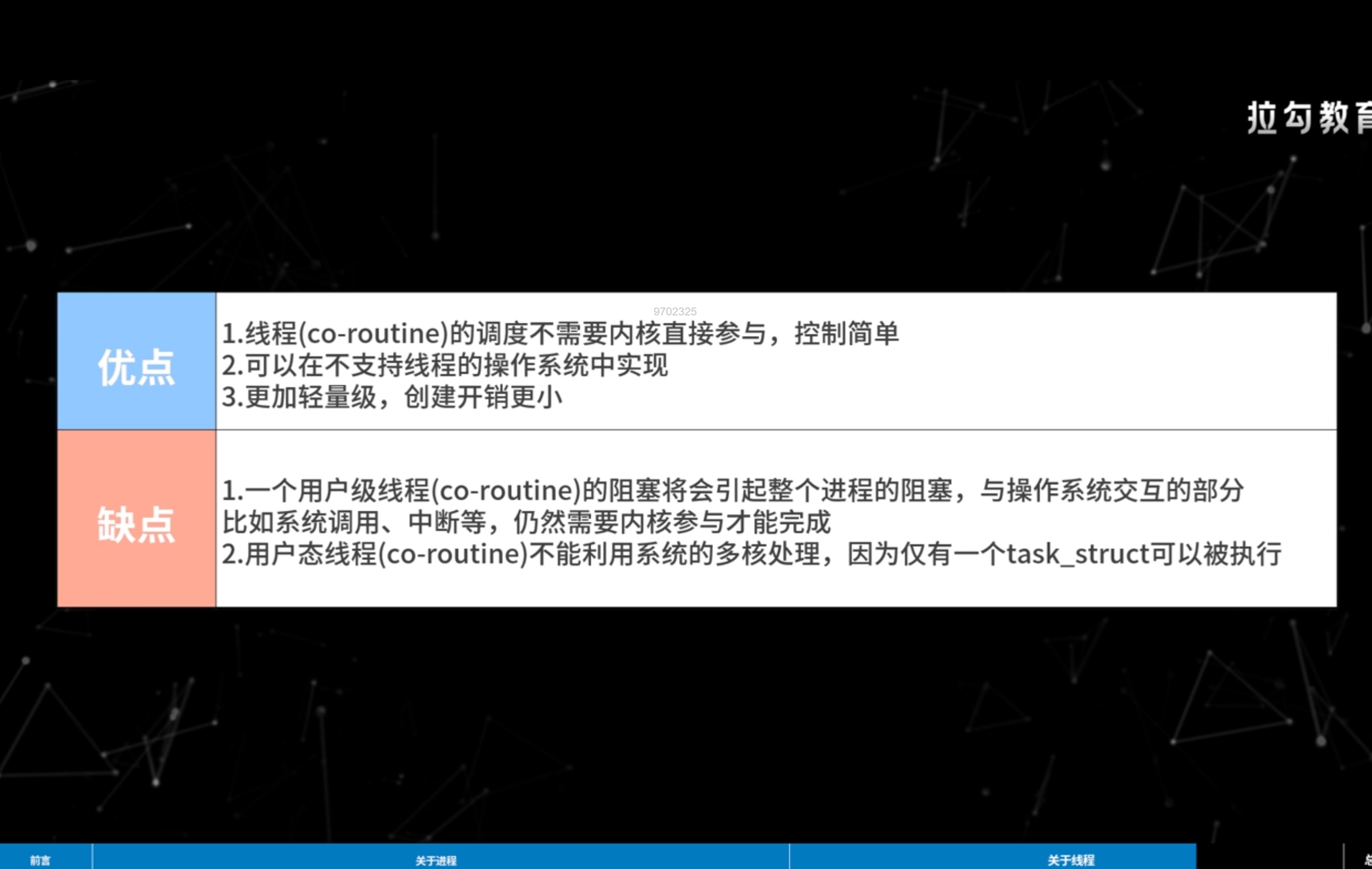
| 优点 | 1. 线程的调度不需要内核直接参与,控制简单 1. 可以在不支持线程的操作系统中实现 1. 更加轻量级,创建开销更小 |
|---|---|
| 缺点 | 1. 一个用户级线程的阻塞将会引起整个进程的阻塞,与操作系统交互的部分,比如系统调用、中断等,仍然需要内核参与才能完成 1. 用户级线程不能利用系统的多核处理,仅有一个用户级线程可以被执行 |
所以,我们能看到,用户态线程的功能还是受到限制。
如果只有一个内核线程,然后这个线程上创建了 N 个协程,当一个协程进行系统调用的时候,其他协程有可能会被阻塞,为了解决这个问题,又提出了新的线程模型:
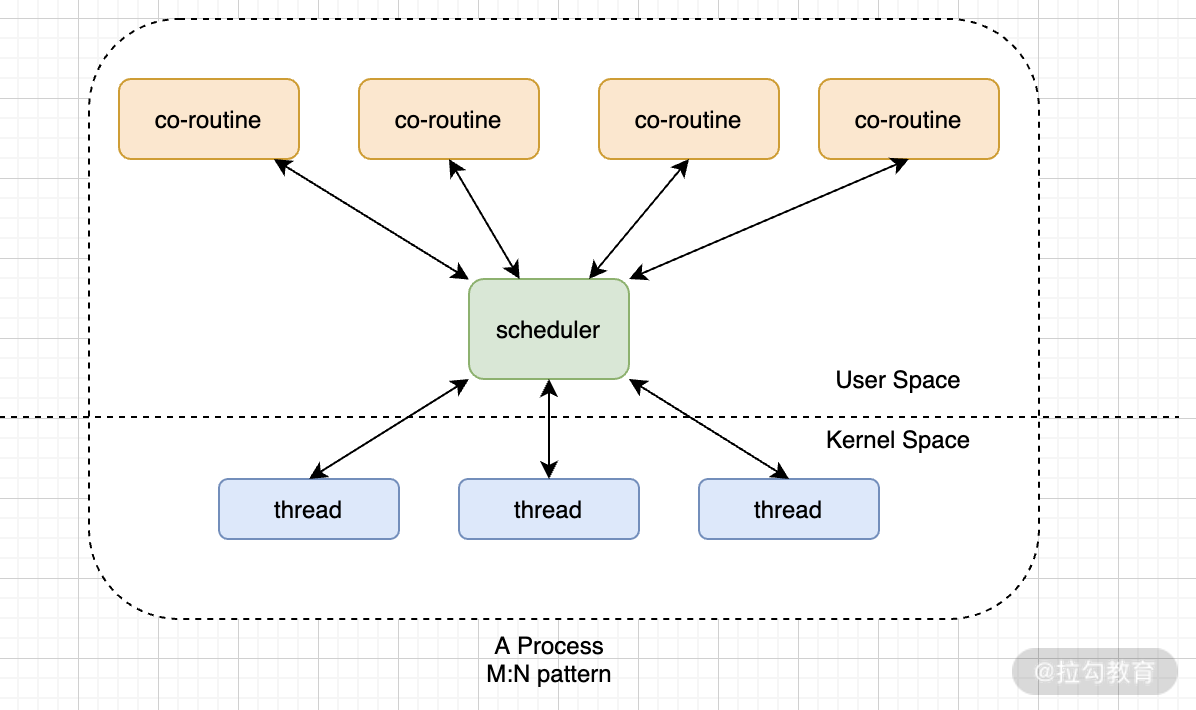
图7. 用户态线程与内核态线程的 M:N 模型。
这种思路的特点就是:在内核态创建 N 个线程,当某个内核线程被 co-routine 阻塞的时候,可以把能运行的 co-routine 调度到剩下的 N-1 个线程上继续运行,这样保证了程序不会完全被阻塞。当然,这样的复杂度也更高。
此外,从实现这个角度来进行分类,协程还可以分为两类——

- stackfull co-routine:即协程之间的切换需要使用栈来保存信息,速度稍慢,实现更容易
- stackless co-routine:切换协程的时候,不需要使用栈来保存信息,速度更快,实现更复杂
总结

在本期内容中,我们从计算机的远古时代开始聊起,一直谈到了现代化的、各种语言提供的用户态线程,以及相应的实现。希望你在加深理解这些概念的同时,能觉得轻松有趣。
最后还是提醒下,在使用进程、线程(内核态线程、用户态线程)的时候,你要特别注意下应用场景。根据经验,一般而言:
- 内核态线程适用于计算密集型任务;
- 用户态线程(协程)更适用于 IO 密集型任务。
那么,不知道你对进程,线程,协程等等概念还有什么疑问呢?请在评论区留言吧。

若有收获,就点个赞吧
0 人点赞
