1.上下文切换
多线程出现的意义,就是为了解决,IO和CPU之间速度差的冲突,比如,在一个程序中,需要从文件读取100个字节,然后进行处理,再将结果写入另一个文件中。那么在读写文件的过程中,cpu其实是在等待Io处理完成的。这时候就可以让CPU,去处理其他计算任务。
如果在一个单核系统上,有以上多个这样的线程,就可以在一个线程在等待IO的时候,CPU就去另一个线程进行计算处理。所以就可以在单核系统上并行处理多件事情。
同样基于以上原理,如果是每个线程一直就是在繁忙的计算,那么(单核系统)多个线程事实上也得不到任何好处,反而因为上下文的切换,要消耗比顺序执行更多的时间。
线程有创建和上下文切换的开销
减少上下文切换:
1.使用无锁并发编程:多线程竞争锁的时候,会引起上下文的切换,可以使用一些办法来避免使用锁。将数据ID按照Hash算法取模分段,不同线程处理不同段的数据。
2.CAS算法
3.尽量使用少的线程
4.使用协程
那么,什么是上下文切换呢?下面是一个上下文切换时需要履行的步骤:
- 将前一个 CPU 的上下文(也就是 CPU 寄存器和程序计数器里边的内容)保存起来;
- 然后加载新任务的上下文到寄存器和程序计数器;
- 最后跳转到程序计数器所指的新位置,运行新任务。
被保存起来的上下文会存储到系统内核中,等待任务重新调度执行时再次加载进来。
CPU 的上下文切换分三种:进程上下文切换、线程上下文切换、中断上下文切换。
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间:
内核空间:具有最高权限,可以访问所有资源;
用户空间:只能访问受限资源,不能直接访问内存等硬件设备,必须借助系统调用。
进程可以在用户空间运行(叫作:进程用户态),也可以在内核空间运行(叫作:进程内核态)。从用户态到内核态需要系统调用完成。
系统调用过程中也会发生 CPU 上下文切换。CPU 寄存器会先保存用户态的状态,然后加载内核态相关内容。系统调用结束之后,CPU 寄存器要恢复原来保存的用户态,继续运行进程。所以,一次系统调用,发生两次 CPU 上下文切换。
需要注意的是,系统调用过程中,不涉及虚拟内存等进程用户态的资源,也不会切换进程。与通常所说的进程上下文切换不同:
进程上下文切换是指,从一个进程切换到另一个进程;
系统调用过程中一直是同一个进程在运行。
2.死锁
避免死锁的几个常用方法
1.避免一个线程同时获得多个锁
2.避免一个线程在锁内占用多个资源。
3.尝试使用定时锁
4.对于数据库锁,加锁和解锁必须在一个数据库连接里。
3.并发机制的底层实现原理
java代码编译后变成java字节码,字节码被类加载器加载到jvm中,jvm执行字节码,最终转化为汇编指令在cpu上执行,java中所使用的并发机制依赖于jvm的实现和cpu的指令。
3.1 volatile
Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁要更加方便。如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的.
下面对volatile写和volatile读的内存语义做个总结。
·线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程
发出了(其对共享变量所做修改的)消息。
·线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile
变量之前对共享变量所做修改的)消息。
·线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过
主内存向线程B发送消息。
java中可以通过锁和循环CAS的方式来实现原子操作。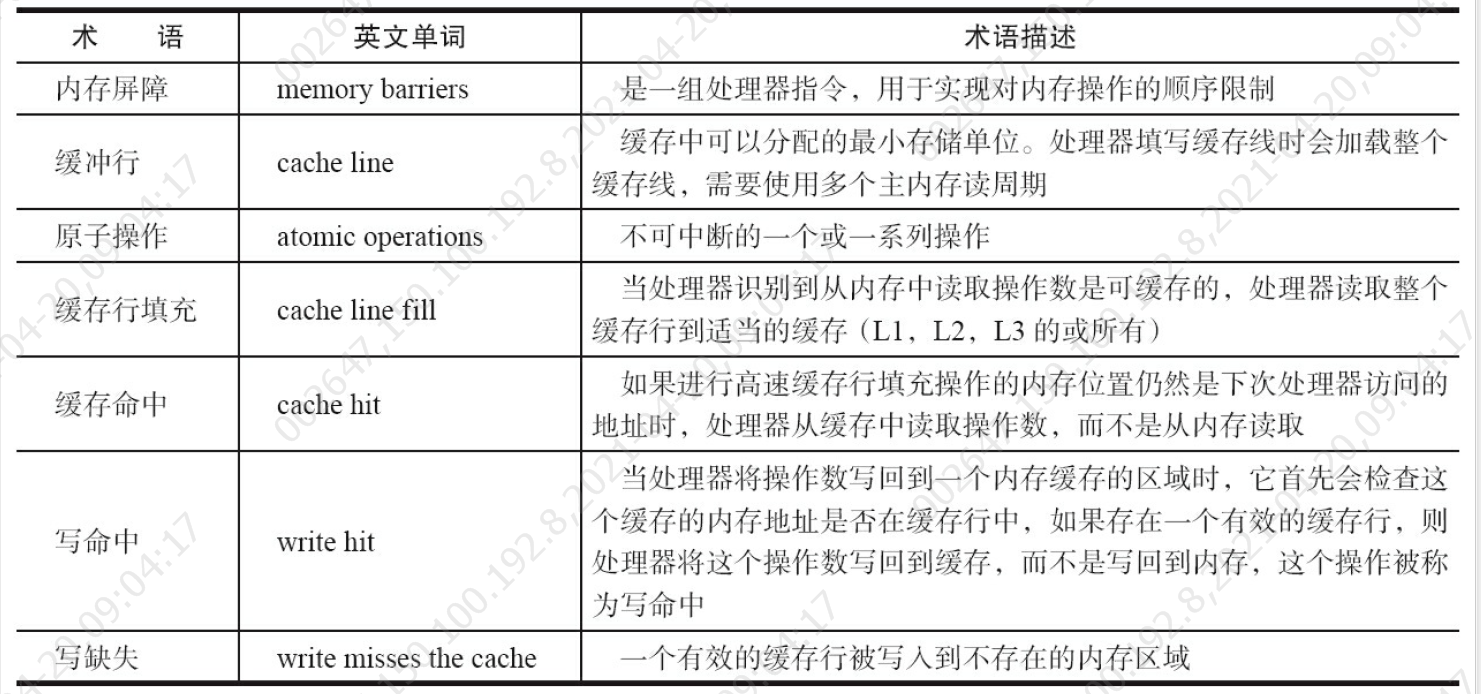
如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
下面来具体讲解volatile的两条实现原则。
4.原子操作
基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址
- 第一个机制是通过总线锁保证原子性
- 原因可能是多个处理器同时从各自的缓存中读取变量i,分别进行加1操作,然后分别写入系统内存中。那么,想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
- 第二个机制是通过缓存锁定来保证原子性
- 在同一时刻,我们只需保证对某个内存地址的操作是原子性即可,但总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,目前处理器在某些场合下使用缓存锁定代替总线锁定来进行优化
- 所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效,
- 缓存一致性:缓存一致性机制就整体来说,是当某块CPU对缓存中的数据进行操作了之后,就通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取,用MESI阐述原理如下:处理器上有一套完整的协议,来保证缓存的一致性,比较经典的应该就是MESI协议了,其实现方法是在CPU缓存中保存一个标记位,以此来标记四种状态。
- M:被修改的。处于这一状态的数据,只在本CPU核中有缓存数据,而其他核中没有。同时其状态相对于内存中的值来说,是已经被修改的,只是没有更新到内存中。
- E:独占的。处于这一状态的数据,只有在本CPU中有缓存,且其数据没有修改,即与内存中一致。
- S:共享的。处于这一状态的数据在多个CPU中都有缓存,且与内存一致。
- I:无效的。本CPU中的这份缓存已经无效。
在Java中可以通过锁和循环CAS的方式来实现原子操作。
原子类实现原理:**
这段代码我们需要注意一下几个方面:
(1)unsafe字段,AtomicInteger包含了一个Unsafe类的实例,unsafe就是用来实现CAS机制的,CAS机制我们在后面会讲到;
(2)value字段,表示当前对象代码的基本类型的值,AtomicInteger是int型的线程安全包装类,value就代码了AtomicInteger的值。注意,这个字段是volatile的。
(3)valueOfset,指是value在内存中的偏移量,也就是在内存中的地址,通过Unsafe.objectFieldOffset(Field f)获取。这个值在使用CAS机制的时候会用到。
我们来分析下incrementAndGet的逻辑:
1.先获取当前的value值
2.对value加一
3.第三步是关键步骤,调用compareAndSet方法来来进行原子更新操作,这个方法的语义是:
先检查当前value是否等于current,如果相等,则意味着value没被其他线程修改过,更新并返回true。如果不相等,compareAndSet则会返回false,然后循环继续尝试更新。
/*** Atomically increments by one the current value.** @return the updated value*/public final int incrementAndGet() {for (;;) {int current = get();int next = current + 1;if (compareAndSet(current, next))return next;}}
/*** Atomically sets the value to the given updated value* if the current value {@code ==} the expected value.** @param expect the expected value* @param update the new value* @return true if successful. False return indicates that* the actual value was not equal to the expected value.*/public final boolean compareAndSet(int expect, int update) {return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}
Unsafe的compareAndSwapInt是个native方法,也就是平台相关的。它是基于CPU的CAS指令来完成的。
5.内存屏障
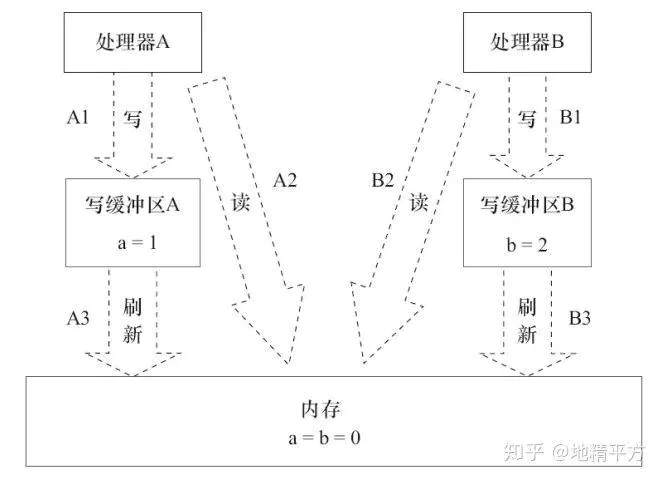
写缓存区没有及时刷新,使得处理器执行的读写操作与内存上顺序不一致。
处理器A读b=0,处理器B读a=0。A1写a=1先写到处理器A的写缓存区中,此时内存中a=0。如果这时处理器B从内存中读a,读到的将是0。
为了解决上述问题,处理器提供内存屏障指令(Memory Barrier):
- 写内存屏障(Store Memory Barrier):处理器将存储缓存值写回主存(阻塞方式)。
- 读内存屏障(Load Memory Barrier):处理器,处理失效队列,缓存失效,必须从主存里里面获取(阻塞方式)。
volatile读前插读屏障,写后加写屏障,避免CPU重排导致的问题,实现多线程之间数据的可见性。
对于处理器来说,内存屏障会导致cpu缓存的刷新,刷新时,会遵循缓存一致性协议。
- lock:解锁时,jvm会强制刷新cpu缓存,导致当前线程更改,对其他线程可见。
- volatile:标记volatile的字段,在写操作时,会强制刷新cpu缓存,标记volatile的字段,每次读取都是直接读内存。
- final:即时编译器在final写操作后,会插入内存屏障,来禁止重排序,保证可见性
5.总线风暴
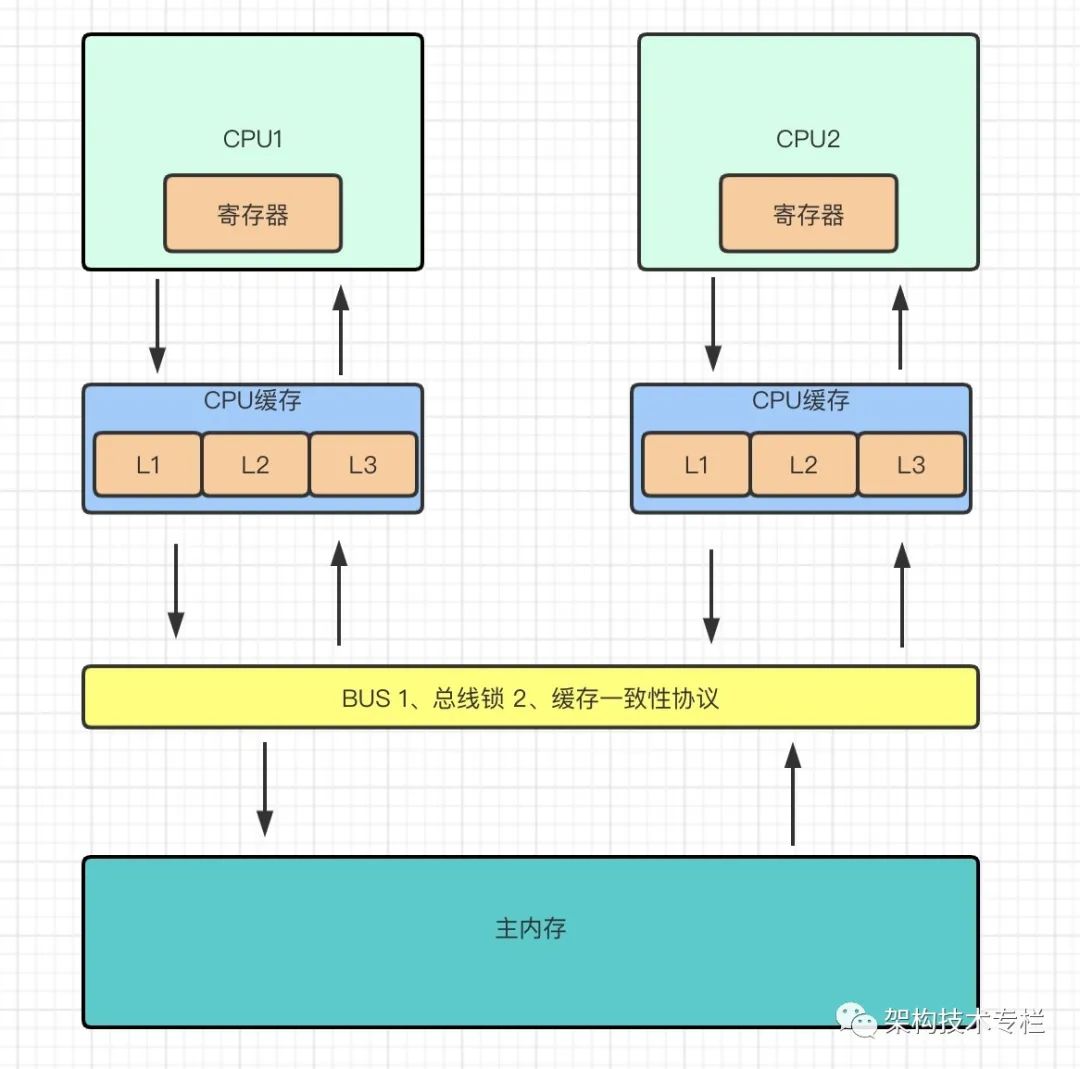
在java中使用unsafe实现cas,而其底层由cpp调用汇编指令实现的,如果是多核cpu是使用lock cmpxchg指令,单核cpu 使用compxch指令。如果在短时间内产生大量的cas操作在加上 volatile的嗅探机制则会不断地占用总线带宽,导致总线流量激增,就会产生总线风暴。 总之,就是因为volatile 和CAS 的操作导致BUS总线缓存一致性流量激增所造成的影响。
这里有些基础需要铺垫下,了解过volatile和cas 的朋友都知道由于一个变量在多个高速缓存中都存在,但由于高速缓存间的数据是不共享的,所以势必会有数据不一致的问题,为了解决这种问题处理器是通过总线锁定和缓存锁定这两个机制来保证复杂内存操作的原子性的。
1、总线锁
在早期处理器提供一个 LOCK# 信号,CPU1在操作共享变量的时候会预先对总线加锁,此时CPU2就不能通过总线来读取内存中的数据了,但这无疑会大大降低CPU的执行效率。
2、缓存一致性协议
由于总线锁的效率太低所以就出现了缓存一致性协议,Intel 的MESI协议就是其中一个佼佼者。MESI协议保证了每个缓存变量中使用的共享变量的副本都是一致的。
3、MESI 的核心思想
modified(修改)、exclusive(互斥)、share(共享)、invalid(无效)
如上图,CPU1使用共享数据时会先数据拷贝到CPU1缓存中,然后置为独占状态(E),这时CPU2也使用了共享数据,也会拷贝也到CPU2缓存中。通过总线嗅探机制,当该CPU1监听总线中其他CPU对内存进行操作,此时共享变量在CPU1和CPU2两个缓存中的状态会被标记为共享状态(S);
若CPU1将变量通过缓存回写到主存中,需要先锁住缓存行,此时状态切换为(M),向总线发消息告诉其他在嗅探的CPU该变量已经被CPU1改变并回写到主存中。接收到消息的其他CPU会将共享变量状态从(S)改成无效状态(I),缓存行失效。若其他CPU需要再次操作共享变量则需要重新从内存读取。
缓存一致性协议失效的情况:
- 共享变量大于缓存行大小,MESI无法进行缓存行加锁;
- CPU并不支持缓存一致性协议
4、嗅探机制
每个处理器会通过嗅探器来监控总线上的数据来检查自己缓存内的数据是否过期,如果发现自己缓存行对应的地址被修改了,就会将此缓存行置为无效。当处理器对此数据进行操作时,就会重新从主内存中读取数据到缓存行。5、缓存一致性流量
通过前面都知道了缓存一致性协议,比如MESI会触发嗅探器进行数据传播。当有大量的volatile 和cas 进行数据修改的时候就会产大量嗅探消息。6、总结
通过上面一顿巴拉,大家应该对开局图有一定的了解了,也大概知道了总线风暴的原因。这里再做一下概括性的总结(当前内部还有很有详细的机制,大家感兴趣可以撸一波)
在多核处理器架构上,所有的处理器是共用一条总线的,都是靠此总线来和主内存进行数据交互。当主内存的数据同时存在于多个处理的高速缓存中时,某一处理器更新了此共享数据后。会通过总线触发嗅探机制来通知其他处理器将自己高速缓存内的共享数据置为无效,在下次使用时重新从主内存加载最新数据。而这种通过总线来进行通信则称之为”缓存一致性流量“。
因为总线是固定的,所有相应可以接受的通信能力也就是固定的了,如果缓存一致性流量突然激增,必然会使总线的处理能力受到影响。而恰好CAS和volatile 会导致缓存一致性流量增大。如果很多线程都共享一个变量,当共享变量进行CAS等数据变更时,就有可能产生总线风暴。5.并发内存模型的基础
在并发编程中,需要处理两个关键问题:线程之间如何通信以及线程之间如何同步(这里的线程是指并发执行的活动实体)。
线程之间的通信包括共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信。
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。
实例、静态、数组元素都存储在堆内存中,堆内存在线程之间共享。局部变量,方法定义参数和异常处理器参数不会在线程之间共享。
线程之间的共享变量储存在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读写共享变量的副本。本地内存只是一个抽象的概念,并不是真实存在的。
如果两个线程之间要通信的话,需要经历两个步骤。
1.线程A把本地内存A中更新的书共享变量刷新到主内存中
2.线程B到主内存中读取线程A之前更新过的共享变量。
6.重排序
重排序是指编辑器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。编辑器和处理器在重排序的时候,会遵守数据依赖性,编辑器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。但是这里所说的数据依赖性仅仅针对单个处理器的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编辑器和处理器考虑。
在多线程程序中,对存在依赖控制的操作重排序,可能会改变程序的执行结果。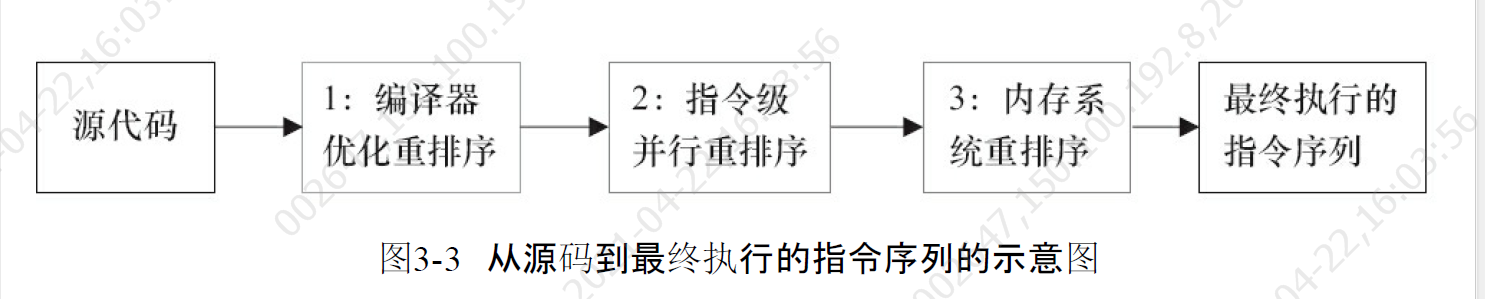
1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3)内存系统的重排序。由于处理器使 用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,减少对内存总线的占用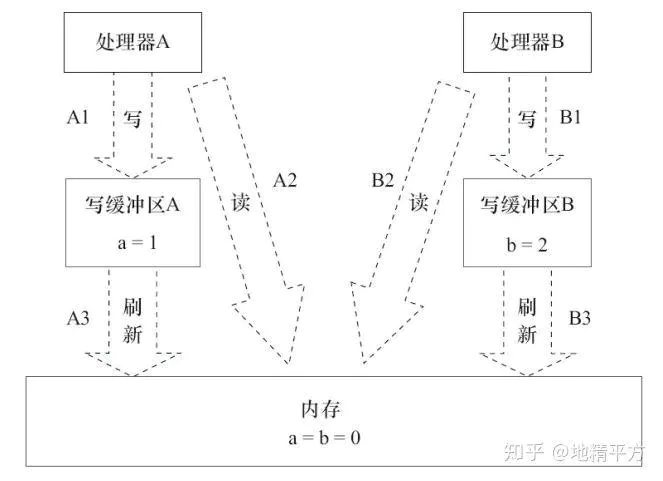
7.顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺讯一致性内存模型作为草考。
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供
了极强的内存可见性保证。顺序一致性内存模型有两大特性。
1)一个线程中的所有操作必须按照程序的顺序来执行。
2)(不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内
存模型中,每个操作都必须原子执行且立刻对所有线程可见。
8.锁的内存语义
·线程A释放了一个锁,实际上是线程A向接下来将要获取这个锁的某个线程发出了(线程A对共享变量所做修改的)消息
·线程B获取一个锁,实际上是线程B接受了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息
·线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发动消息。
公平锁是保证先到先得,非公平锁是所有锁都有可能获的到锁。非公平锁的效率优于公平锁。
公平锁在释放锁的最后写volatile变量state,
9.CAS算法
一个线程失败或挂起并不会导致其他线程也失败或者挂起,那么这种算法就别称为非阻塞算法。
CAS算法就是一种非阻塞算法的实现,也是一种乐观锁的技术,他能在不使用锁的情况下实现多线程安全所以CAS也是一种无锁算法。
CAS  比较并交换,是一种实现并发算法时常用到的技术,Java并发包中的很多类都使用了CAS技术。CAS具体包括三个参数:当前内存值V(主线程值)、旧的预期值A(当前线程的缓存值)、即将更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。CAS 有效地说明了“ 我认为位置 V 应该包含值 A,如果真的包含A值,则将 B 放到这个位置,否则,不要更改该位置,只告诉我这个位置现在的值(A)即可。 ”整个比较并交换的操作是原子操作。
比较并交换,是一种实现并发算法时常用到的技术,Java并发包中的很多类都使用了CAS技术。CAS具体包括三个参数:当前内存值V(主线程值)、旧的预期值A(当前线程的缓存值)、即将更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。CAS 有效地说明了“ 我认为位置 V 应该包含值 A,如果真的包含A值,则将 B 放到这个位置,否则,不要更改该位置,只告诉我这个位置现在的值(A)即可。 ”整个比较并交换的操作是原子操作。
10.处理器内存模型
由于常见的处理器内存模型要比JMM(java的内存模型)要弱,JAVA编辑器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。同时,由于各种处理器内存模型的强弱不一致,为了在不同的处理器平台向程序员展示一个一致的内存模型,jmm在不同的处理器中需要插入的内存屏障的数量和种类也不相同。
11.Daemon线程
Daemon线程是一种支持型线程,因为它主要被用作程序中后台调度以及支持性工作。这
意味着,当一个Java虚拟机中不存在非Daemon线程的时候,Java虚拟机将会退出。可以通过调
用Thread.setDaemon(true)将线程设置为Daemon线程。
Daemon属性需要在启动线程之前设置,不能在启动线程之后设置。
Daemon线程被用作完成支持性工作,但是在Java虚拟机退出时Daemon线程中的finally块
并不一定会执行,在构建Daemon线程时,不能依靠finally块中的内容来确保执行关闭或清理资源
的逻辑。Java虚拟机中已经没有非Daemon线程,虚拟机需要退出。Java虚拟机中的所有Daemon线程都需要立即终止。
12.wait、notify、notifyAll
wait:Object类的方法。作用是挂起当前线程,释放获取到的锁,直到别的线程调用了这个对象的notify或notifyAll方法。
notify:Object类的方法。作用是唤醒因调用wait挂起的线程,如果有过个线程,随机唤醒一个。
notifyAll:Object类的方法。作用是唤醒全部因调用wait挂起的线程。
使用wait/notify方法实现线程间的通信。这两个方法都是Object类的方法,也就是说Java所有的对象都提供这两个方法。
1、wait和notify必须配合synchronized关键(或同步锁)使用
2、wait方法释放锁(等待),notify方法不释放锁(通知)
3、wait和notify实现的线程通信存在非实时通知问题(因为notify只是通知并未释放锁)
使用场景
等待方遵循如下原则。
1)获取对象的锁。
2)如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件。
3)条件满足则执行对应的逻辑。
伪代码如下 :
synchronized(对象) {while(条件不满足) {对象.wait();}对应的处理逻辑}
通知方遵循如下原则。
1)获得对象的锁。
2)改变条件。
3)通知所有等待在对象上的线程。
对应伪代码如下:
synchronized(对象) {改变条件对象.notifyAll();}
13.重入锁
14.读写锁
读写锁在同一个时刻可以允许多个读线程访问,但是在写线程访问的时候,所有的读线程和其他的写线程均被阻塞。读写锁维护了一对锁,一个读锁和一个写锁,通过分离读锁和写锁,使得并发性相比一般的排它锁有了很大的提升。
写锁是一个支持重进入的排它锁。如果当前线程已经获取了写锁,则增加写状态。如果当前线程在获取写锁时,读锁已经被获取(读状态不为0)或者该线程不是已经获取写锁的线程,则当前线程进入等待状态。如果存在读锁,则写锁不能被获取,原因在于:读写锁要确保写锁的操作对读锁可见,如果允许读锁在已被获取的情况下对写锁的获取,那么正在运行的其他读线程就无法感知到当
前写线程的操作。
读锁是一个支持重进入的共享锁,它能够被多个线程同时获取,在没有其他写线程访问(或者写状态为0)时,读锁总会被成功地获取,而所做的也只是(线程安全的)增加读状态。如果当前线程已经获取了读锁,则增加读状态。如果当前线程在获取读锁时,写锁已被其他线程获取,则进入等待状态
15.多线程队列ConcurrentLinkedQueue(非阻塞)
在并发编程中,有时候需要使用线程安全的队列。如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现。非阻塞的实现方式则可以使用循环CAS的方式来实现。本节让我们一起来研究一下Doug Lea是如何使用非阻塞的方式来实现线程安全队列ConcurrentLinkedQueue的
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规
则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元
素时,它会返回队列头部的元素。
16.阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不
满。
2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
17.可重入锁和不可重入锁
可重入锁
可重入锁就是已线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他线程是不可以获取到的。
synchronized和ReentrantLock都是可重入锁,可重入锁的意义是为了防止死锁
实现原理:通过为每一个锁关联一个请求计数器和一个占有他的线程,当计数为0的时候,认为锁是为被占有的;线程请求一个未被占有的锁的时候,jvm将记录锁的占有者信息,计数器加1,每次同一线程再次请求这个锁的时候,计数器都会加1,每次占用线程退出同步块的时候,计数器递减,直到计数器为0;
Synchronized
jdk1.5版本之前,java是依靠Synchronized关键字实现锁功能的,但是Synchronized是java的关键字,是基于底层操作系统的Mutex Lock实现的,每次获取锁和释放锁都会带来用户态和内核态的切换,从而增加系统性能开销。因此被称之为重量级锁。
Lock同步锁是基于java实现的,java1.5版本之前性能要比Sychronized锁性能要好。但是1.6后,java对Synchronized坐了优化,甚至在某些场景下,它的性能已经超越了 Lock 同步锁。
1.6优化过后,引入了偏向锁,轻量级锁、重量级做的概念。
在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。Mark Word 记录了对象和锁有关的信息。锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位,Synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。下面我们就沿着这条优化路径去看下具体的内容。
偏向锁的作用就是:当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的 Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor 去竞争对象了。当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
因此,在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生 stop the word 后,开启偏向锁无疑会带来更大的性能开销,这时我们可以通过添加 JVM 参数关闭偏向锁来调优系统性能,示例代码如下:
-XX:-UseBiasedLocking //关闭偏向锁(默认打开)
或
-XX:+UseHeavyMonitors //设置重量级锁
轻量级锁:当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁,如果获取成功,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
自旋锁与重量级锁:轻量级锁 CAS 抢锁失败,线程将会被挂起进入阻塞状态。如果正在持有锁的线程在很短的时间内释放资源,那么进入阻塞状态的线程无疑又要申请锁资源。JVM 提供了一种自旋锁,可以通过自旋方式不断尝试获取锁,从而避免线程被挂起阻塞。这是基于大多数情况下,线程持有锁的时间都不会太长,毕竟线程被挂起阻塞可能会得不偿失。从 JDK1.7 开始,自旋锁默认启用,自旋次数由 JVM 设置决定,这里我不建议设置的重试次数过多,因为 CAS 重试操作意味着长时间地占用 CPU。自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为 10。在这个状态下,未抢到锁的线程都会进入 Monitor,之后会被阻塞在 _WaitSet 队列中。
在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于 CAS 重试状态,占用 CPU 资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。
在高负载、高并发的场景下,我们可以通过设置 JVM 参数来关闭自旋锁,优化系统性能,示例代码如下:
-XX:-UseSpinning //参数关闭自旋锁优化(默认打开)
-XX:PreBlockSpin //参数修改默认的自旋次数。JDK1.7后,去掉此参数,由jvm控制
读写锁ReentrantReadWriteLock
ReentrantLock 是一个独占锁,同一时间只允许一个线程访问,而 RRW 允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。读写锁内部维护了两个锁,一个是用于读操作的 ReadLock,一个是用于写操作的 WriteLock。
RRW 也是基于 AQS 实现的,它的自定义同步器(继承 AQS)需要在同步状态 state 上维护多个读线程和一个写线程的状态,该状态的设计成为实现读写锁的关键。RRW 很好地使用了高低位,来实现一个整型控制两种状态的功能,读写锁将变量切分成了两个部分,高 16 位表示读,低 16 位表示写。
一个线程尝试获取写锁时,会先判断同步状态 state 是否为 0。如果 state 等于 0,说明暂时没有其它线程获取锁;如果 state 不等于 0,则说明有其它线程获取了锁。
此时再判断同步状态 state 的低 16 位(w)是否为 0,如果 w 为 0,则说明其它线程获取了读锁,此时进入 CLH 队列进行阻塞等待;如果 w 不为 0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入 CLH 队列进行阻塞等待;若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态。
一个线程尝试获取读锁时,同样会先判断同步状态 state 是否为 0。如果 state 等于 0,说明暂时没有其它线程获取锁,此时判断是否需要阻塞,如果需要阻塞,则进入 CLH 队列进行阻塞等待;如果不需要阻塞,则 CAS 更新同步状态为读状态。
如果 state 不等于 0,会判断同步状态低 16 位,如果存在写锁,则获取读锁失败,进入 CLH 阻塞队列;反之,判断当前线程是否应该被阻塞,如果不应该阻塞则尝试 CAS 同步状态,获取成功更新同步锁为读状态。
读写锁再优化之 StampedLock
StampedLock是Java8引入的一种新的所机制,简单的理解,可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读锁会完全阻塞写锁,它使用的依然是悲观的锁策略.如果有大量的读线程,他也有可能引起写线程的饥饿
在 JDK1.8 中,Java 提供了 StampedLock 类解决了这个问题。StampedLock 不是基于 AQS 实现的,但实现的原理和 AQS 是一样的,都是基于队列和锁状态实现的。与 RRW 不一样的是,StampedLock 控制锁有三种模式: 写、悲观读以及乐观读,并且 StampedLock 在获取锁时会返回一个票据 stamp,获取的 stamp 除了在释放锁时需要校验,在乐观读模式下,stamp 还会作为读取共享资源后的二次校验,后面我会讲解 stamp 的工作原理。
StampedLock提供了三种模式的控制:
独占写模式。writeLock方法可能会在获取共享状态时阻塞,如果成功获取锁,返回一个stamp,它可以作为参数被用在unlockWrite方法中以释放写锁。tryWriteLock的超时与非超时版本都被提供使用。当写锁被获取,那么没有读锁能够被获取并且所有的乐观读锁验证都会失败。
悲观读模式。readLock方法可能会在获取共享状态时阻塞,如果成功获取锁,返回一个stamp,它可以作为参数被用在unlockRead方法中以释放读锁。tryReadLock的超时与非超时版本都被提供使用。
乐观读模式。tryOptimisticRead方法只有当写锁没有被获取时会返回一个非0的stamp。在获取这个stamp后直到调用validate方法这段时间,如果写锁没有被获取,那么validate方法将会返回true。这个模式可以被认为是读锁的一个弱化版本,因为它的状态可能随时被写锁破坏。这个乐观模式的主要是为一些很短的只读代码块的使用设计,它可以降低竞争并且提高吞吐量。但是,它的使用本质上是很脆弱的。乐观读的代码区域应当只读取共享数据并将它们储存在局部变量中以待后来使用,当然在使用前要先验证这些数据是否过期,这可以使用前面提到的validate方法。在乐观读模式下的数据读取可能是非常不一致的过程,因此只有当你对数据的表示很熟悉并且重复调用validate方法来检查数据的一致性时使用此模式。例如,当先读取一个对象或者数组引用,然后访问它的字段、元素或者方法之一时上面的步骤都是需要的。就是若读的操作很多,写的操作很少的情况下,你可以乐观地认为,写入与读取同时发生几率很少,因此不悲观地使用完全的读取锁定
悲观锁实现方式
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
- 在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locks)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 期间如果有其他对该记录做修改或加排他锁的操作,都会等待解锁或直接抛出异常。
乐观锁实现方式
- CAS 实现:Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
- 版本号控制:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会+1。当线程A要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,数据库中的版本号要小于刚才读取的version+1,同事版本号+1,否则重试更新操作,直到更新成功。乐观锁每次在执行数据修改操作时,都会带上一个版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败。因为每次操作的版本号都会随之增加,所以不会出现 ABA 问题,因为版本号只会增加不会减少。除了 version 以外,还可以使用时间戳,因为时间戳天然具有顺序递增性。
18.AQS
https://www.jianshu.com/p/b6388f2db2c0
什么是AQS?#
AQS即AbstractQueuedSynchronizer,是一个用于构建锁和同步器的框架。它能降低构建锁和同步器的工作量,还可以避免处理多个位置上发生的竞争问题。在基于AQS构建的同步器中,只可能在一个时刻发生阻塞,从而降低上下文切换的开销,并提高吞吐量。
AQS支持独占锁(exclusive)和共享锁(share)两种模式。
独占锁:只能被一个线程获取到(Reentrantlock),ReenTrantLock默认非公平锁
共享锁:可以被多个线程同时获取(CountDownLatch,ReadWriteLock).
它维护了一个volatile的state变量和一个FIFO(先进先出)的队列。 其中state变量代表的是竞争资源标识,而队列代表的是竞争资源失败的线程排队时存放的容器。**
AQS中提供了操作state的方法:
- getState();
- setState();
- compareSetState(); ```java
protected final int getState() { return state; } protected final void setState(int newState) { state = newState; } protected final boolean compareAndSetState(int expect, int update) { // See below for intrinsics setup to support this return unsafe.compareAndSwapInt(this, stateOffset, expect, update); }
无论是独占锁还是共享锁,本质上都是对AQS内部的一个变量state的获取。state是一个原子的int变量,用来表示锁状态、资源数等。<br />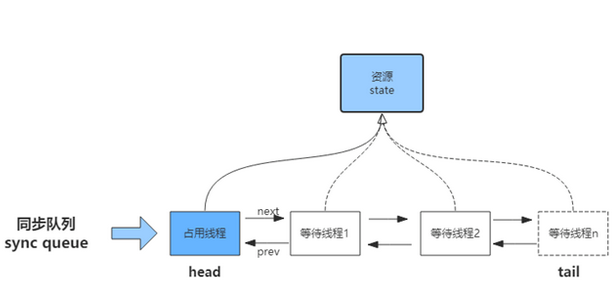AQS内部的数据结构与原理#<br />**AQS内部实现了两个队列,一个同步队列,一个条件队列。**<br />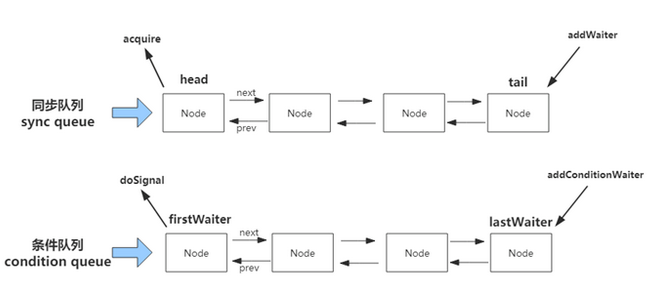<br />**同步队列的作用是**:当**线程获取资源失败**之后,就进入同步队列的**尾部保持自旋等待**,**不断判断自己是否是链表的头节点**,如果是头节点,就不断参试获取资源,获取成功后则退出同步队列。<br />**条件队列是为Lock实现的一个基础同步器,并且一个线程可能会有多个条件队列,只有在使用了Condition才会存在条件队列。**同步队列和条件队列都是由一个个Node组成的。AQS内部有一个静态内部类Node。```javastatic final class Node {static final Node EXCLUSIVE = null;//当前节点由于超时或中断被取消static final int CANCELLED = 1;//表示当前节点的前节点被阻塞static final int SIGNAL = -1;//当前节点在等待conditionstatic final int CONDITION = -2;//状态需要向后传播static final int PROPAGATE = -3;volatile int waitStatus;volatile Node prev;volatile Node next;volatile Thread thread;Node nextWaiter;final boolean isShared() {return nextWaiter == SHARED;}final Node predecessor() throws NullPointerException {Node p = prev;if (p == null)throw new NullPointerException();elsereturn p;}Node() { // Used to establish initial head or SHARED marker}Node(Thread thread, Node mode) { // Used by addWaiterthis.nextWaiter = mode;this.thread = thread;}Node(Thread thread, int waitStatus) { // Used by Conditionthis.waitStatus = waitStatus;this.thread = thread;}}
重要方法的源码解析#
//独占模式下获取资源public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
acquire(int arg)首先调用tryAcquire(arg)尝试直接获取资源,如果获取成功,因为与运算的短路性质,就不再执行后面的判断,直接返回。tryAcquire(int arg)的具体实现由子类负责。如果没有直接获取到资源,就将当前线程加入等待队列的尾部,并标记为独占模式,使线程在等待队列中自旋等待获取资源,直到获取资源成功才返回。如果线程在等待的过程中被中断过,就返回true,否则返回false。
如果acquireQueued(addWaiter(Node.EXCLUSIVE), arg)执行过程中被中断过,那么if语句的条件就全部成立,就会执行selfInterrupt();方法。因为在等待队列中自旋状态的线程是不会响应中断的,它会把中断记录下来,如果在自旋时发生过中断,就返回true。然后就会执行selfInterrupt()方法,而这个方法就是简单的中断当前线程Thread.currentThread().interrupt();其作用就是补上在自旋时没有响应的中断。
可以看出在整个方法中,最重要的就是acquireQueued(addWaiter(Node.EXCLUSIVE), arg)。
我们首先看Node addWaiter(Node mode)方法,顾名思义,这个方法的作用就是添加一个等待者,根据之前对AQS中数据结构的分析,可以知道,添加等待者就是将该节点加入等待队列.
private Node addWaiter(Node mode) {Node node = new Node(Thread.currentThread(), mode);// Try the fast path of enq; backup to full enq on failureNode pred = tail;//尝试快速入队if (pred != null) { //队列已经初始化node.prev = pred;if (compareAndSetTail(pred, node)) {pred.next = node;return node; //快速入队成功后,就直接返回了}}//快速入队失败,也就是说队列都还每初始化,就使用enqenq(node);return node;}//执行入队private Node enq(final Node node) {for (;;) {Node t = tail;if (t == null) { // Must initialize//如果队列为空,用一个空节点充当队列头if (compareAndSetHead(new Node()))tail = head;//尾部指针也指向队列头} else {//队列已经初始化,入队node.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;//打断循环}}}}
final boolean acquireQueued(final Node node, int arg) {boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();//拿到node的上一个节点//前置节点为head,说明可以尝试获取资源。排队成功后,尝试拿锁if (p == head && tryAcquire(arg)) {setHead(node);//获取成功,更新head节点p.next = null; // help GCfailed = false;return interrupted;}//尝试拿锁失败后,根据条件进行parkif (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}//获取资源失败后,检测并更新等待状态private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus;if (ws == Node.SIGNAL)/** This node has already set status asking a release* to signal it, so it can safely park.*/return true;if (ws > 0) {/** Predecessor was cancelled. Skip over predecessors and* indicate retry.*/do {//如果前节点取消了,那就往前找到一个等待状态的接待你,并排在它的后面node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {/** waitStatus must be 0 or PROPAGATE. Indicate that we* need a signal, but don't park yet. Caller will need to* retry to make sure it cannot acquire before parking.*/compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false;}//阻塞当前线程,返回中断状态private final boolean parkAndCheckInterrupt() {LockSupport.park(this);return Thread.interrupted();}
公平锁和非公平锁
公平锁
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
非公平锁
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
总结:公平锁和非公平锁只有两处不同:
- 非公平锁在调用 lock 后,首先就会调用 CAS 进行一次抢锁,如果这个时候恰巧锁没有被占用,那么直接就获取到锁返回了。
- 非公平锁在 CAS 失败后,和公平锁一样都会进入到 tryAcquire 方法,在 tryAcquire 方法中,如果发现锁这个时候被释放了(state == 0),非公平锁会直接 CAS 抢锁,但是公平锁会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面。
在AQS的实现中有一个出现了一个park的概念。park即LockSupport.park().它的作用是阻塞当前线程,并且可以调用LockSupport.unpark(Thread)去停止阻塞。它们的实质都是通过UnSafe类使用了CPU的原语。在AQS中使用park的主要作用是,让排队的线程阻塞掉(停止其自旋,自旋会消耗CPU资源),并在需要的时候,可以方便的唤醒阻塞掉的线程。
我们先简单介绍AQS的两种模式的实现类的代表ReentrantLock(独占模式)和CountDownLatch(共享模式),是如何来共享资源的一个过程,然后再详细通过AQS的源码来分析整个实现过程。
- ReentrantLock在初始化的时候state=0,表示资源未被锁定。当A线程执行lock()方法时,会调用tryAcquire()方法,将AQS中队列的模式设置为独占,并将独占线程设置为线程A,以及将state+1。 这样在线程A没有释放锁前,其他线程来竞争锁,调用tryAcquire()方法时都会失败,然后竞争锁失败的线程就会进入到队列中。当线程A调用执行unlock()方法将state=0后,其他线程才有机会获取锁(注意ReentrantLock是可重入的,同一线程多次获取锁时state值会进行垒加的,在释放锁时也要释放相应的次数才算完全释放了锁)。
- CountDownLatch会将任务分成N个子线程去执行,state的初始值也是N(state与子线程数量一致)。N个子线程是并行执行的,每个子线程执行完成后countDown()一次,state会通过CAS方式减1。直到所有子线程执行完成后(state=0),会通过unpark()方法唤醒主线程,然后主线程就会从await()方法返回,继续后续操作。
ReentrantLock并没有直接继承AQS类,而是通过内部类来继承AQS类的,这样自己的实现功能,自己用。 我们在用ReentrantLock加锁的时候都是调用的用lock()方法,那么我们来看看默认非公平锁下,lock()方法的源码:
/*** Sync object for non-fair locks*/static final class NonfairSync extends Sync {private static final long serialVersionUID = 7316153563782823691L;/*** Performs lock. Try immediate barge, backing up to normal* acquire on failure.*/final void lock() {if (compareAndSetState(0, 1))setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);}protected final boolean tryAcquire(int acquires) {return nonfairTryAcquire(acquires);}}
通过源码可以看到,lock()方法,首先是通过CAS的方式抢占锁,如果抢占成功则将state的值设置为1。然后将对象独占线程设置为当前线程。
protected final void setExclusiveOwnerThread(Thread thread) {exclusiveOwnerThread = thread;}
如果抢占锁失败,就会调用acquire()方法,这个acquire()方法的实现就是在AQS类中了,说明具体抢占锁失败后的逻辑,AQS已经规定好了模板。
public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
上面已经介绍了,独占模式是需要实现tryAcquire()方法的,这里首先就是通过tryAcquire()方法抢占锁,如果成功返回true,失败返回false。tryAcquire()方法的具体实现,是在ReentrantLock里面的,AQS类中默认是直接抛出异常的。
- 首先获取state值,如果state值为0,说明无锁,那么通过CAS尝试加锁,成功后,将独占线程设置为当前线程。
- 如果state值不为0,并且当前的独占线程和当前线程为同一线程,那么state重入次数加1。
- 如果state值不为0,并且当前线程不是独占线程,直接返回false。
```java
protected final boolean tryAcquire(int acquires) { return nonfairTryAcquire(acquires); } final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState();// 获取state值 if (c == 0) { // 如果state值为0,说明无锁,那么就通过cas方式,尝试加锁,成功后将独占线程设置为当前线程 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { // 如果是同一个线程再次来获取锁,那么就将state的值进行加1处理(可重入锁的,重入次数)。 int nextc = c + acquires; if (nextc < 0) // overflow throw new Error(“Maximum lock count exceeded”); setState(nextc); return true; } return false; }
**await存在的问题**- 执行countdown的某个子线程可能会因为某些原因无法执行countdown,这样就会导致await线程一直阻塞下去。在线程池中多次调用await方法,因为await方法会阻塞一段时间,有可能导致线程池可用线程被大量阻塞。<br />- await() 阻塞并等待计数为0再往下执行。- await(long timeout, TimeUnit unit) 阻塞并等待指定的时间,如果在指定的时间内计数未能到 0,则自动唤醒,向下执行。- countDown() 计数器中的计数减一- getCount() 获得当前计数的值<a name="OqQb2"></a>### Condition原理而Condition自己也维护了一个队列,该队列的作用是维护一个等待signal信号的队列,两个队列的作用是不同,事实上,每个线程也仅仅会同时存在以上两个队列中的一个,流程是这样的:1. 线程1调用`reentrantLock.lock`时,线程被加入到AQS的等待队列中。1. 线程1中`await`方法被调用时,该线程从AQS中移除,对应操作是锁的释放。1. 接着马上被加入到`Condition`的等待队列中,此时该线程需要`signal`信号。1. 线程2,因为线程1释放锁的关系,被唤醒,并判断可以获取锁,于是线程2获取锁,并被加入到AQS的等待队列中。1. 线程2调用`signal`方法,这个时候`Condition`的等待队列中只有线程1一个节点,于是它被取出来,并被加入到AQS的等待队列中。 注意,这个时候,线程1 并没有被唤醒。1. `signal`方法执行完毕,线程2调用`reentrantLock.unLock()`方法,释放锁。这个时候因为AQS中只有线程1,于是,AQS释放锁后按从头到尾的顺序唤醒线程时,线程1被唤醒,于是线程1回复执行。1. 直到释放所整个过程执行完毕。可以看到,整个协作过程是靠结点在AQS的等待队列和`Condition`的等待队列中来回移动实现的,`Condition`作为一个条件类,很好的自己维护了一个等待信号的队列,并在适时的时候将结点加入到AQS的等待队列中来实现的唤醒操作。<a name="LPDi5"></a># 19.信号量- “信号量”,也可以称其为“信号灯”,它的存在就如同生活中的红绿灯一般,用来控制车辆的通行。在程序员眼中,线程就好比行驶的车辆,程序员就可以通过信号量去指定线程是否可以执行,并且可以指定访问临界区的线程数量**;**- 信号量的模型很简单,有:一个计数器,一个等待队列,三个方法(init,down,up)。在该模型中,计数器与等待队列对外是透明的,只能去通过三个方法区。**三个方法详解:**- init():设置计数器的初始值(信号量是支持多个线程访问一个临界区的,所以可以通过设置计数器的初始值来控制线程访问临界资源的数量)- down():计数器减一操作;如果此时计数器的值小于0,则当前线程被阻塞,否则当前线程可以继续执行。- up():计数器加一操作;如果此时计数器的值小于或者等于 0,则唤醒等待队列中的一个线程,并将其从等待队列中移除。**注意:这里的三个方法均是原子操作。在Java SDK里,信号量是由java.util.concurrent.Semaphore实现的,Semaphore可以保证方其都是原子操作。并且在Java SDK并发包中,down()和up()对应的是acquire()和release()方法。**<br />**<br />**信号量具体如何实现互斥?**<br />比如现有两个线程 t1与t2,而我们规定在初始化计数器时将计数器设置为1,表明临界区只允许一个线程去访问。当两个线程同时访问addOne()方法时,两个线程同时执行acquire()方法,由于acquire()是一个原子操作,当t1将计数器值减为0,t2将计数器减为-1。对于t1而言,信号量的计数器值为0,满足大于等于0条件,所以t1会继续执行;对于t2而言,信号量里边的计数器为-1,小于0,按照down()操作的描述,t2会被阻塞。因此只有t1线程进入临界区执行count+=1操作。<br />当t1执行release()操作时,信号量里边的计数器会+1,此时为0,小于等于0,因此会将处于等待队列中的t2线程唤醒。于是t2在t1执行完临界代码之后进入到了临界区。从而保证了互斥性。**Semaphore有一个独特的功能,就是可以允许多个线程访问一个临界区。这里就通过“快速实现一个限流器”来说明;**<br />对象池:**指的是一次性创建出 N 个对象,之后所有的线程重复利用这 N 个对象**,当然对象在被释放前,也是不允许其他线程使用的。<br />这里的限流就是指不允许多余N个线程同时进入临界区<br />解决方法:在上一个例子中我们将计数器初始化为1,表示只允许一个线程进入临界区,现在我们将计数器设置为对象池中的对象个数N,表明在同一个时刻允许N个线程可以同时进入到临界区,就可以解决限流问题了;<br />思考:信号量在在执行release()方法后如果满足唤醒其他线程条件就会去唤醒一个线程继续执行,这里为什么不能去唤醒所有线程呢?<br />由于信号量没有Condition概念,当阻塞线程被唤醒会直接运行,不会去检查此时的临界条件是否满足,因此信号量只允许唤醒一个阻塞线程,否则就会出现缺少临界条件检查而带来的线程安全问题。<a name="6gaV3"></a># 20.协程协程运行在线程之上,**当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上**。**协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程**,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。一个线程可对应多个协程。<br />实际上协程并不是什么银弹,协程只有在等待IO的过程中才能重复利用线程,上面我们已经讲过了,线程在等待IO的过程中会陷入阻塞状态,意识到问题没有?<br />假设协程运行在线程之上,并且协程调用了一个阻塞IO操作,这时候会发生什么?实际上操作系统并不知道协程的存在,它只知道线程,**因此在协程调用阻塞IO操作的时候,操作系统会让线程进入阻塞状态,当前的协程和其它绑定在该线程之上的协程都会陷入阻塞而得不到调度,这往往是不能接受的。**<br />因此在协程中不能调用导致线程阻塞的操作。也就是说,协程只有和异步IO结合起来,才能发挥最大的威力。<br />那么如何处理在协程中调用阻塞IO的操作呢?一般有2种处理方式:1. **在调用阻塞IO操作的时候,重新启动一个线程去执行这个操作,等执行完成后,协程再去读取结果。这其实和多线程没有太大区别。**1. **对系统的IO进行封装,改成异步调用的方式,这需要大量的工作,最好寄希望于编程语言原生支持。**协程对计算密集型的任务也没有太大的好处,计算密集型的任务本身不需要大量的线程切换,因此协程的作用也十分有限,反而还增加了协程切换的开销。<br />以上就是协程的注意事项。这里顺带一提JavaScript的异步变同步的调用方式,如果协程能够实现该类型的语法,不仅可以把异步操作变为同步,同时在IO操作的时候还能够不占用CPU,写起来非常方便。<br />**异步变同步的调用方式只是一种编程方式,不管是用线程还是用协程都可以实现这种编程方式,好处是不用在处理非常多的回调。**
async function getProcessedData(url) { let v; try { v = await downloadData(url); } catch(e) { v = await downloadFallbackData(url); } try { return await processDataInWorker(v); } catch (e) { return null; } }
**总结**<br />在有大量IO操作业务的情况下,我们采用协程替换线程,可以到达很好的效果,一是降低了系统内存,二是减少了系统切换开销,因此系统的性能也会提升。<br />在协程中尽量不要调用阻塞IO的方法,比如打印,读取文件,Socket接口等,除非改为异步调用的方式,并且协程只有在IO密集型的任务中才会发挥作用。<br />**协程只有和异步IO结合起来才能发挥出最大的威力。**<a name="AqyJM"></a># 21.内核态和用户态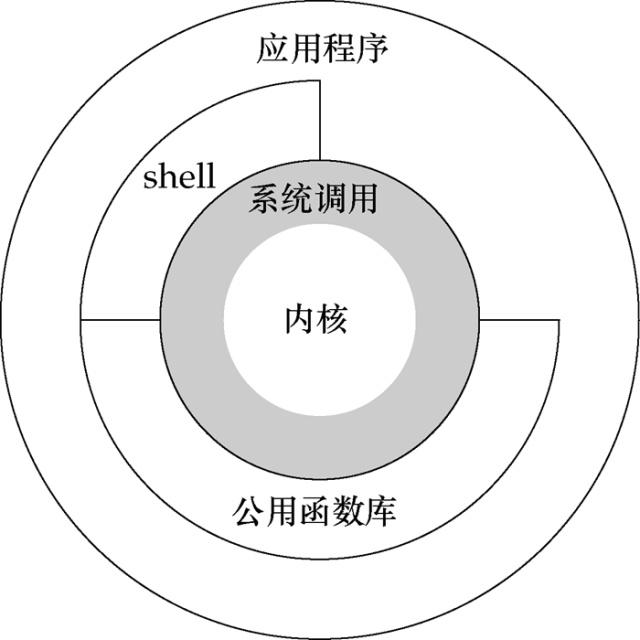<br />宏观上来说,上图很好的反应了Linux操作系统的架构图。首先,Linux系统包含一个内核,内核,实质是一个软件,特殊的地方在于,**内核具备直接操纵CPU资源,内存资源,I/O资源等的能力。**<br />内核之外是系统调用。**系统调用这层,相当于内核增加了一层封装**。将内核操作的复杂性封装起来,对外层提供透明的调用。系统调用可以理解为操作系统的最小功能单位,所有有应用程序,都是将通过将系统调用组合而成的。<br />系统调用之外,就是应用程序,各种各样的应用程序。特殊的有两个,一个是Shell,它是一个特殊的应用程序,俗称命令行。类似于windows的cmd,是一个命令解释器。有些应用程序是基于Shell做的,而不是基于系统调用。另一个特殊的是公用函数库。系统调用是操作系统的最小功能单位,一个Linux系统,根据版本不同,大约包含240~260个系统调用。为了使得操作更为简单,更加便于应用程序使用,Linux系统对系统调用的部分功能进行了再次封装,形成了公用函数库,以供应用程序调用。公用函数库中的一个方法,实质是若干个系统调用以特定的逻辑组合而成。Linux的架构中,很重要的一个能力就是操纵系统资源的能力。**但是,系统资源是有限的,如果不加限制的允许任何程序以任何方式去操纵系统资源,必然会造成资源的浪费,发生资源不足等情况。为了减少这种情况的发生,Linux制定了一个等级制定,即特权。Linux将特权分成两个层次,以0和3标识。0的特权级要高于3。**换句话说,0特权级在操纵系统资源上是没有任何限制的,可以执行任何操作,而3,则会受到极大的限制。**我们把特权级0称之为内核态,特权级3称之为用户态。**<br />一个应用程序,在执行的过程中,会在用户态和内核态之间根据需要不断切换的。因为,如果只有用户态,那么必然有某些操纵系统资源的操作很难完成或不能完成,而如果一直都在内核态,那事实上,导致特权的分层失去了意义。大家全是最高权限,和大家都没有限制,没有什么区别。<br />所以,**应用程序一般会运行于用户态,会在需要的时候,切换成内核态,完成相关任务后,会再切换加用户态。**需要注意的是,一种切换是有一定系统开销的。<br />**应用程序一般会在以下几种情况下用户态切换到内核态:**<br />**1. 系统调用。**<br />**2. 异常事件。**当发生某些预先不可知的异常时,就会切换到内核态,以执行相关的异常事件。<br />**3. 设备中断。**在使用外围设备时,如外围设备完成了用户请求,就会向CPU发送一个中断信号,此时,CPU就会暂停执行原本的下一条指令,转去处理中断事件。此时,如果原来在用户态,则自然就会切换到内核态。<a name="SzZWi"></a># 22.零拷贝**而且在很多技术中都使用到了,比如javaNIO、kafka、Netty、Linux等等**<br />所谓的零拷贝(Zero-Copy)是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手 。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换 。 对 Linux操作系统而言,零拷贝技术依赖于底层的 `sendfile()` 方法实现 。 对应于 Java 语言,`FileChannal.transferTo()` 方法的底层实现就是 `sendfile()` 方法。单纯从概念上理解 “零拷贝”比较抽象,这里简单地介绍一下它 。 考虑这样一种常用的情形 : 你需要将静态内容(类似图片、文件)展示给用户 。 这个情形就意味着需要先将静态内容从磁盘中复制出来放到一个内存 buf 中,然后将这个 buf 通过套接字(Socket)传输给用户,进而用户获得静态内容 。 这看起来再正常不过了,但实际上这是很低效的流程,我们把上面的这种情形抽象成下面的过程 :
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
``
首先调用read()将静态内容(这里假设为文件 A )读取到 tmp_buf, 然后调用write()` 将 tmp_buf 写入 Socket,如下图所示 。在这个过程中, 文件 A 经历了 4 次复制的过程:
- 调用
read()时,文件 A 中的内容被复制到了内核模式下的 Read Buffer 中。 - CPU 控制将内核模式数据复制到用户模式下 。
- 调用
write()时 ,将用户模式下的内容复制到内核模式下的 Socket Buffer 中 。 - 将内核模式下的 Socket Buffer 的数据复制到网卡(NIC: network interface card)设备中传迭 。
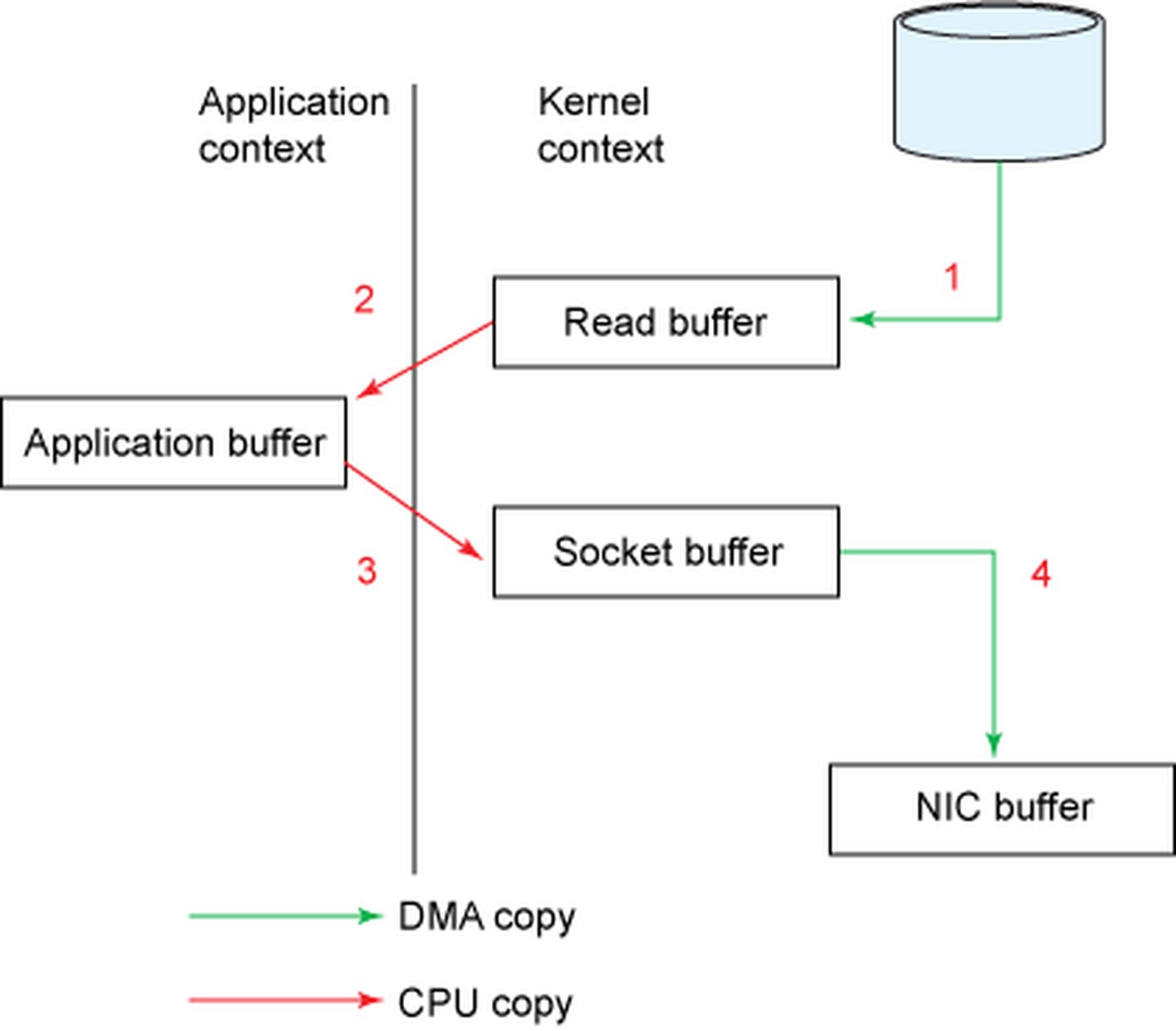
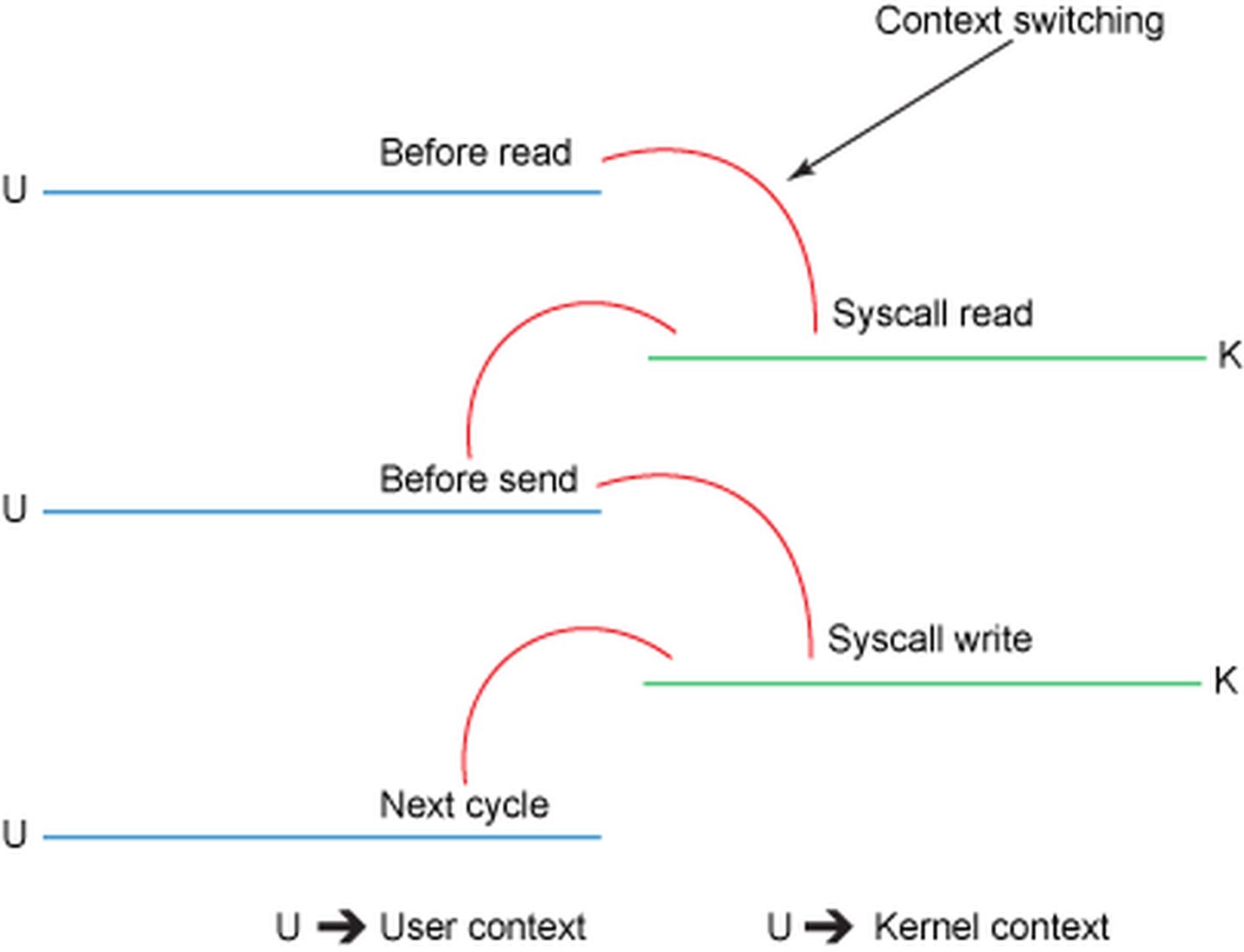
现在我们可以看到1->2->3->4的整个过程一共经历了四次拷贝的方式,但是真正消耗资源和浪费时间的是第二次和第三次,因为这两次都需要经过我们的CPU拷贝,而且还需要内核态和用户态之间的来回切换。想想看,我们的CPU资源是多么宝贵,要处理大量的任务。还要去拷贝大量的数据。如果能把CPU的这两次拷贝给去除掉,岂不快哉!!!既能节省CPU资源,还可以避免内核态和用户态之间的切换。
如果采用了零拷贝技术,那么应用程序可以直接请求内核把磁盘中的数据传输给 Socket, 如下图所示。
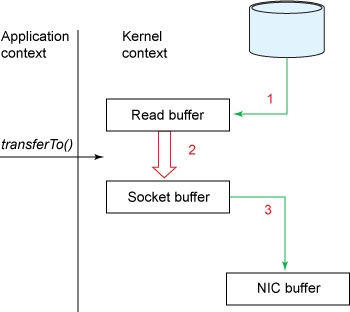
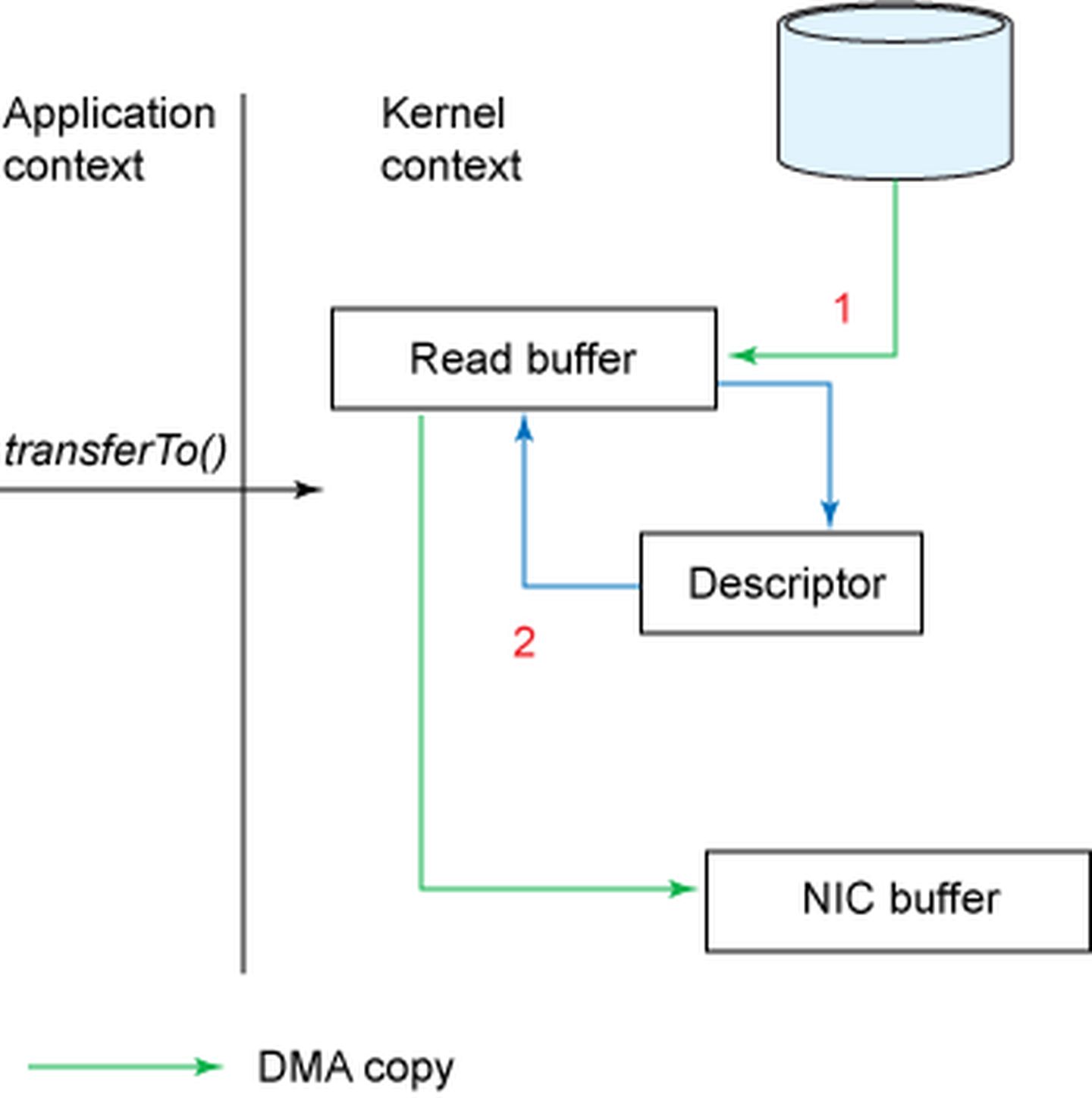
所示的 transferTo() 方法时的步骤有:
transferTo()方法引发 DMA 引擎将文件内容拷贝到一个读取缓冲区。然后由内核将数据拷贝到与输出套接字相关联的内核缓冲区。- 数据的第三次复制发生在 DMA 引擎将数据从内核套接字缓冲区传到协议引擎时。
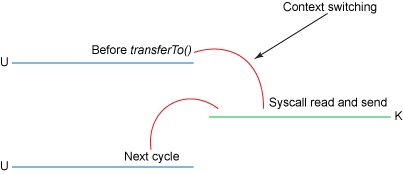
改进的地方:我们将上下文切换的次数从四次减少到了两次,将数据复制的次数从四次减少到了三次(其中只有一次涉及到了 CPU)。但是这个代码尚未达到我们的零拷贝要求。如果底层网络接口卡支持收集操作 的话,那么我们就可以进一步减少内核的数据复制。在 Linux 内核 2.4 及后期版本中,套接字缓冲区描述符就做了相应调整,以满足该需求。这种方法不仅可以减少多个上下文切换,还可以消除需要涉及 CPU 的重复的数据拷贝。对于用户方面,用法还是一样的,但是内部操作已经发生了改变:
transferTo()方法引发 DMA 引擎将文件内容拷贝到内核缓冲区。- 数据未被拷贝到套接字缓冲区。取而代之的是,只有包含关于数据的位置和长度的信息的描述符被追加到了套接字缓冲区。DMA 引擎直接把数据从内核缓冲区传输到协议引擎,从而消除了剩下的最后一次 CPU 拷贝。
展示了结合使用 transferTo() 方法和收集操作的数据拷贝:
性能比较
我们在一个运行 2.6 内核的 Linux 系统上执行了示例程序,并以毫秒为单位分别度量了使用传统方法和 transferTo() 方法传输不同大小的文件的运行时间。表 1 展示了度量的结果:
表 1. 性能对比:传统方法与零拷贝
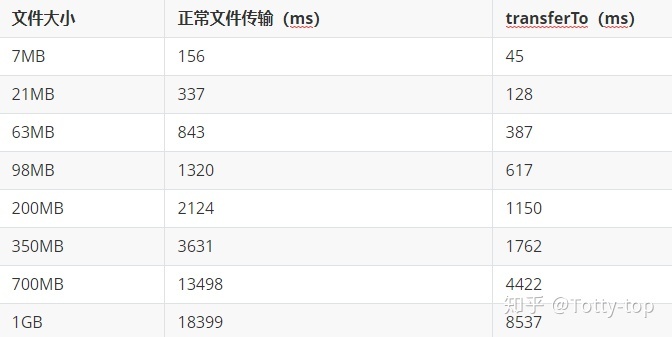
如您所见,与传统方法相比,transferTo() API 大约减少了 65% 的时间。这就极有可能提高了需要在 I/O 通道间大量拷贝数据的应用程序的性能,如 Web 服务器。

若有收获,就点个赞吧
0 人点赞
