1.如何把对象放入spring容器
1.FactoryBean
@Componentpublic class AnimalFactoryBean implements FactoryBean {@Overridepublic Object getObject() throws Exception {return new Dog();}@Overridepublic Class<?> getObjectType() {return Dog.class;}}
FactoryBean是一个工厂Bean,可以生成某一个类型Bean实例,它最大的一个作用是:可以让我们自定义Bean的创建过程。
2.registerSingleton()方法
只适用于如果有两个对象A和B。A对象依赖于B对象。你需要把B对象装配进A。即在A中 @Autowired B
public class Test {public static void main(String[] args) {AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();EvanService evanService = new EvanService();ac.getBeanFactory().registerSingleton("evanService",evanService);//将扫描到的类注册到spring容器ac.register(AppConfig.class);//刷新容器,完成bean的实例化ac.refresh();ac.getBean(PersonService.class).showEvanServiceResult();}}
2.Springboot配置文件加解密
EncryptablePropertyResolver接口
https://blog.csdn.net/Dongguabai/article/details/81114569
在springboot容器中注入applicationContext.getBeanFactory().registerSingleton(“encryptablePropertyResolver”, encryptablePropertyResolver(desPlus));即可
3.应用容器Http处理线程数
Tomcat是一个Web应用服务器,同时也是一个Servlet/JSP容器。Tomcat作为Servlet容器,负责处理客户端请求,把请求传送给Servlet,并将Servlet的响应返回给客户端。
所以对于我们springboot应用来说能支持多少的并发量主要取决于对Tomcat的设置,可以在配置文件中对他修改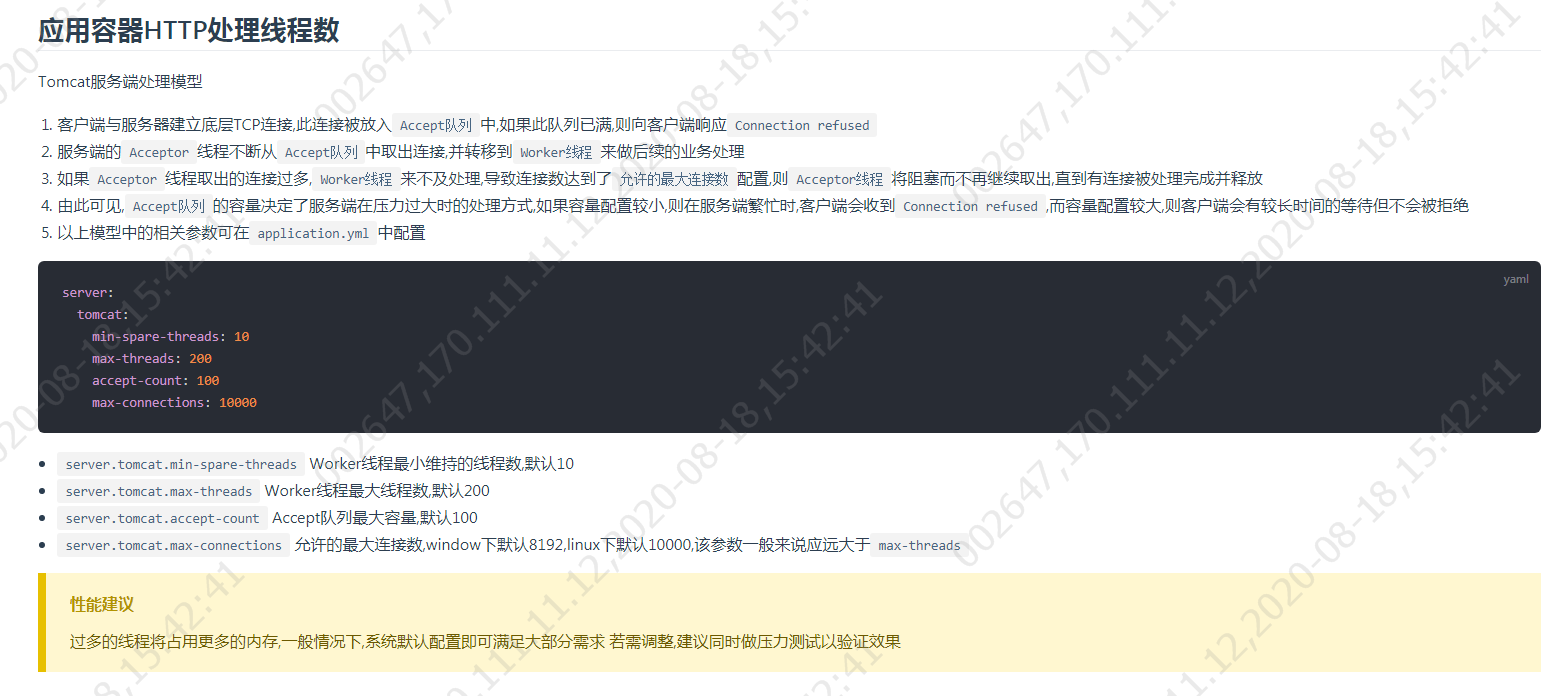
一般来说,并发量是指我们的连接数
Tomcat两个核心组件
1.Connector组件
一 个Connector组件将在某个指定的端口上侦听客户请求,接收浏览器发过来的tcp连接请求,创建一个Request和一个Response对象分别 用于和其你去端交换数据,然后会产生一个线程来处理这个请求并把产生的Request和Response对象传给Engine,从Engine中获得响应 并返回给客户端。 Tomcat有两个经典的Connector,一个直接侦听来自浏览器的HTTP请求,另外一个侦听来自其他的WebServer的请求。Cotote HTTP/1.1 Connector在端口8080处侦听来自客户浏览器的HTTP请求,Coyote JK2 Connector在端口8009处侦听其他WebServer的Servlet/JSP请求。 Connector 最重要的功能就是接收连接请求然后分配线程让 Container来处理这个请求,所以这必然是多线程的,多线程的处理是 Connector 设计的核心。
2.Container
Container是容器的父接口,该容器的设计用的是典型的 责任链的设计模式,它由四个自容器组件构成,分别是Engine、Host、Context、Wrapper。这四个组件是负责关系,存在包含关系。通常 一个Servlet class对应一个Wrapper,如果有多个Servlet则定义多个Wrapper,如果有多个Wrapper就要定义一个更高的 Container,如Context。 Context定义在父容器 Host 中,其中Host 不是必须的,但是要运行 war 程序,就必须要 Host,因为 war 中必有 web.xml 文件,这个文件的解析就需要 Host 了,如果要有多个 Host 就要定义一个 top 容器 Engine 了。而 Engine 没有父容器了,一个 Engine 代表一个完整的 Servlet 引擎。
Engine
Engine 容器比较简单,它只定义了一些基本的关联关系 Host 容器
Host
Host 是 Engine 的字容器,一个 Host 在 Engine 中代表一个虚拟主机,这个虚拟主机的作用就是运行多个应用,它负责安装和展开这些应用,并且标识这个应用以便能够区分它们。它的子容器通常是 Context,它除了关联子容器外,还有就是保存一个主机应该有的信息。
Context
Context 代表 Servlet 的 Context,它具备了 Servlet 运行的基本环境,理论上只要有 Context 就能运行 Servlet 了。简单的 Tomcat 可以没有 Engine 和 Host。Context 最重要的功能就是管理它里面的 Servlet 实例,Servlet 实例在 Context 中是以 Wrapper 出现的,还有一点就是 Context 如何才能找到正确的 Servlet 来执行它呢? Tomcat5 以前是通过一个 Mapper 类来管理的,Tomcat5 以后这个功能被移到了 request 中,在前面的时序图中就可以发现获取子容器都是通过 request 来分配的
Wrapper
Wrapper 代表一个 Servlet,它负责管理一个 Servlet,包括的 Servlet 的装载、初始化、执行以及资源回收。Wrapper 是最底层的容器,它没有子容器了,所以调用它的 addChild 将会报错。 Wrapper 的实现类是 StandardWrapper,StandardWrapper 还实现了拥有一个 Servlet 初始化信息的 ServletConfig,由此看出 StandardWrapper 将直接和 Servlet 的各种信息打交道。
原理:
1.用户在浏览器中输入网址localhost:8080/test/index.jsp,请求被发送到本机端口8080,被在那里监听的Coyote HTTP/1.1 Connector获得;
2.Connector把该请求交给它所在的Service的Engine(Container)来处理,并等待Engine的回应;
3.Engine获得请求localhost/test/index.jsp,匹配所有的虚拟主机Host;
4.Engine 匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机),名为 localhost的Host获得请求/test/index.jsp,匹配它所拥有的所有Context。Host匹配到路径为/test的 Context(如果匹配不到就把该请求交给路径名为“ ”的Context去处理);
5.path=“/test”的Context获得请求/index.jsp,在它的mapping table中寻找出对应的Servlet。Context匹配到URL Pattern为*.jsp的Servlet,对应于JspServlet类;
6.构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet()或doPost(),执行业务逻辑、数据存储等;
7.Context把执行完之后的HttpServletResponse对象返回给Host;
8.Host把HttpServletResponse对象返回给Engine;
9.Engine把HttpServletResponse对象返回Connector;
10.Connector把HttpServletResponse对象返回给客户Browser。
基本请求原理
socket ——->Connector接收socket连接封装成NioSocketWrapper对象——->ConnectionHandler取得HTTP协议内容,创建Requset,Reponse对象——->Container携带Requset,Reponse对象层级执行valve的invoke方法,到达最后一个StandardWrapperValve, 创建ApplicationFilterChain过滤器链, ——->ApplicationFilterChain过滤器链执行doFilter方法,执行完成后调用servlet.service()方法 ——->业务代码
Connector 启动以后会启动一组线程用于不同阶段的请求处理过程。
Acceptor 线程组。用于接受新连接,并将新连接封装一下,选择一个 Poller 将新连接添加到 Poller 的事件队列中。
Poller 线程组。用于监听 Socket 事件,当 Socket 可读或可写等等时,将 Socket 封装一下添加到 worker 线程池的任务队列中。
worker 线程组。用于对请求进行处理,包括分析请求报文并创建 Request 对象,调用容器的 pipeline 进行处理。
Acceptor、Poller、worker 所在的 ThreadPoolExecutor 都维护在 NioEndpoint 中。
4.BIO,NIO,AIO
BIO一个连接一个线程 同步阻塞
NIO一个请求一个线程 同步非阻塞
AIO一个有效请求一个线程 异步非阻塞
ava对BIO、NIO、AIO的支持:
- Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
- Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
- Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
同步阻塞IO:在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,用户进程才能运行。JAVA传统的IO模型属于此种方式!
同步非阻塞IO:在此种方式下,用户进程发起一个IO操作以后边可返回做其它事情,但是用户进程需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。其中目前JAVA的NIO就属于同步非阻塞IO。
异步阻塞IO:此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄,从而提高系统的并发性!
异步非阻塞IO:在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。目前Java中还没有支持此种IO模型。
TOMCAT通讯模式
| BIO | 阻塞式IO,即Tomcat使用传统的java.io进行操作。该模式下每个请求都会创建一个线程,对性能开销大,不适合高并发场景。优点是稳定,适合连接数目小且固定架构。 |
|---|---|
| NIO | 非阻塞式IO,jdk1.4 之后实现的新IO。该模式基于多路复用选择器监测连接状态在通知线程处理,从而达到非阻塞的目的。比传统BIO能更好的支持并发性能。Tomcat 8.0之后默认采用该模式 |
| APR | 全称是 Apache Portable Runtime/Apache可移植运行库),是Apache HTTP服务器的支持库。可以简单地理解为,Tomcat将以JNI的形式调用Apache HTTP服务器的核心动态链接库来处理文件读取或网络传输操作。使用需要编译安装APR 库 |
| AIO | 异步非阻塞式IO,jdk1.7后之支持 。与nio不同在于不需要多路复用选择器,而是请求处理线程执行完程进行回调调知,已继续执行后续操作。Tomcat 8之后支持。 |
5.Tomcat请求过程原理
https://juejin.im/post/6844903912604958733
6.InitializingBean
InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在初始化bean的时候都会执行该方法.

若有收获,就点个赞吧
0 人点赞
