基本思想
- 对于一个字符串中的每一个字符,首先将它的Unicode值转换为二进制数字串,然后对于二进制数字串按照UTF-8的编码规则进行转换,最终得到UTF-8编码。
UTF-8编码规则
编码规则表
- “xxxxx”从二进制数字串尾部依次取得,若高位不足则补”0”。 | Unicode数值范围(16进制) | UTF-8编码规则(二进制) | | :—-: | :—-: | | 0000 0000 - 0000 007F | 0xxxxxxx | | 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx | | 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx | | 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
推荐一个可以很方便地进行Unicode查询的网站:FileFormat
举个例子 🌰
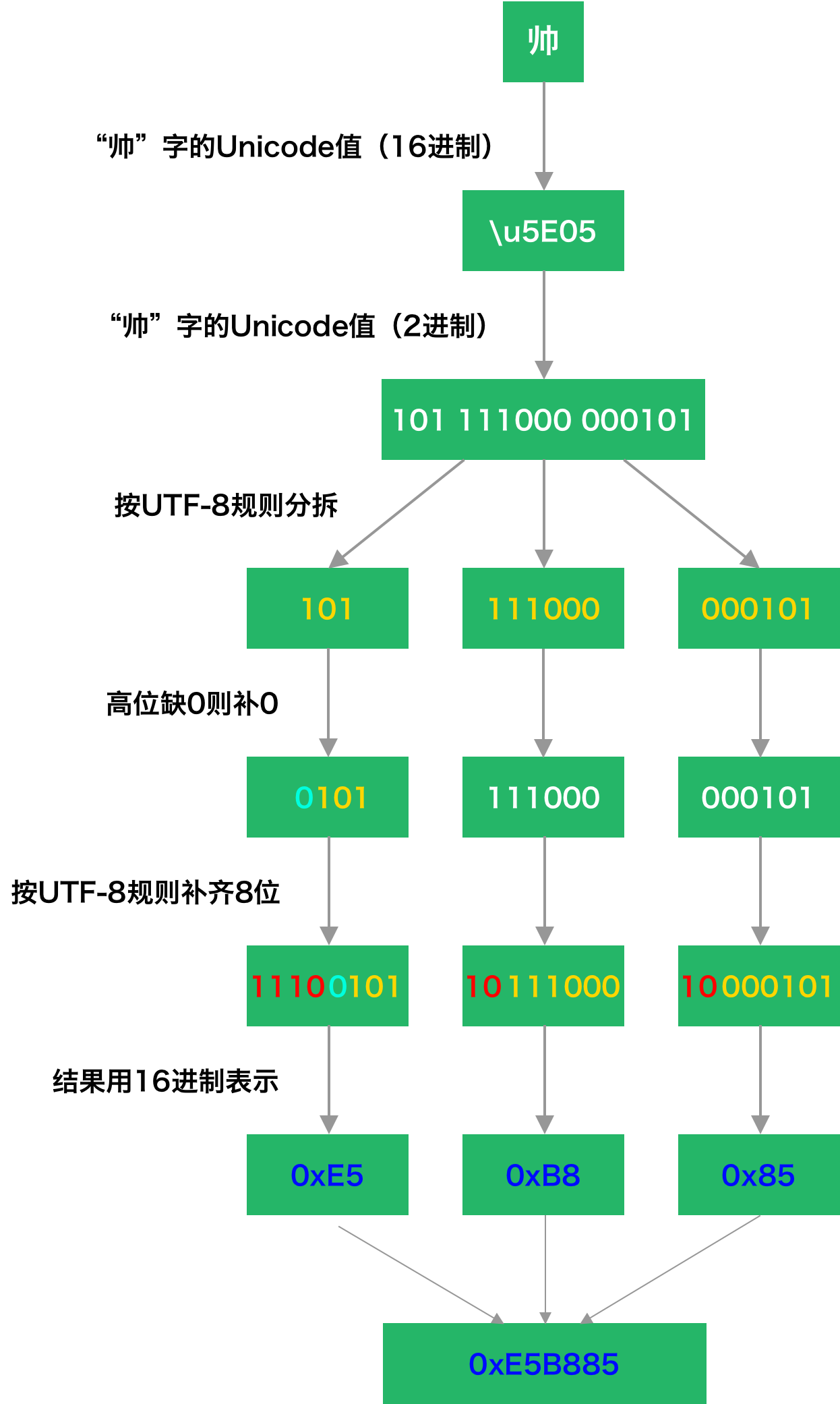
源代码(附注释)
/** 虽然使用了最笨的方法,但也是相对容易理解的方法*/// 接受一个字符串,返回UTF-8编码串function Unicode2UTF8(string) {// result 用于记录最后的结果let result = '';// 将string的每个字符都转为二进制再进行Encode操作for (let ch of string) {// 下面开始编码操作, 为了方便查看,结果用16进制显示// 取字符串中的每个字符,并获取到它的二进制数字串,传入getUTF-8函数进行转换// 返回的结果用16进制表示result += "0x" + parseInt(getUTF8(ch.charCodeAt().toString(2)), 2).toString(16);}console.log(result);return result;}// 接收一个字符串的Unicode值(二进制),转换成UTF8编码(二进制)并返回function getUTF8(string) {// 通过字符串的不同长度判断施加何种操作const length = string.lengthif (length <= 7) {// ASCII码return string;} else if (length <= 11) {// 字符串前面填6个0,再从后六位抽两次const tempString = '000000' + string;return '110' + tempString.slice(-11, -6) + '10' + tempString.slice(-6);} else if (length <= 16) {// 字符串前面填6个0,再从后六位抽三次const tempString = '000000' + string;return '1110' + tempString.slice(-16, -12) + '10' + tempString.slice(-12, -6) + '10' + tempString.slice(-6);} else {// 字符串前面填6个0,再从后六位抽四次const tempString = '000000' + stringreturn '11110' + tempString.slice(-21, -18) + '10' + tempString.slice(-18, -12) + '10' + tempString.slice(-12, -6) + '10' + tempString.slice(-6);}}// 测试(待完善)Unicode2UTF8('你好');
附录
- 附一个大神版代码(我等菜鸟还并未全部理解)
```javascript
function encodeCodePoint(code) {
if (code <= 0x7F) {
return [code]
} else if (code <= 0x7FF) {
return [
] } else if (code <= 0xFFFF) { return [0xC0 | ((code >> 6) & 0x1F),0x80 | ((code) & 0x3F),
] } else { return [0xE0 | ((code >> 12) & 0xF),0x80 | ((code >> 6) & 0x3F),0x80 | ((code) & 0x3F)
] } }0xF0 | ((code >> 18) & 0x7),0x80 | ((code >> 12) & 0x3F),0x80 | ((code >> 6) & 0x3F),0x80 | ((code) & 0x3F)
function UTF8_Encoding(string) { const codes = []; for (let ch of string) { const bytes = encodeCodePoint(ch.codePointAt(0)); codes.push(…bytes); } const array = new Uint8Array(codes); return array.buffer; }
module.exports = UTF8_Encoding; ```

若有收获,就点个赞吧
0 人点赞
