索引节点和目录项
Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。主要用来记录文件的元信息和目录结构。
索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
目录也是一个文件,这个特殊文件保存了该目录的所有文件名与inode的对应关系。
目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
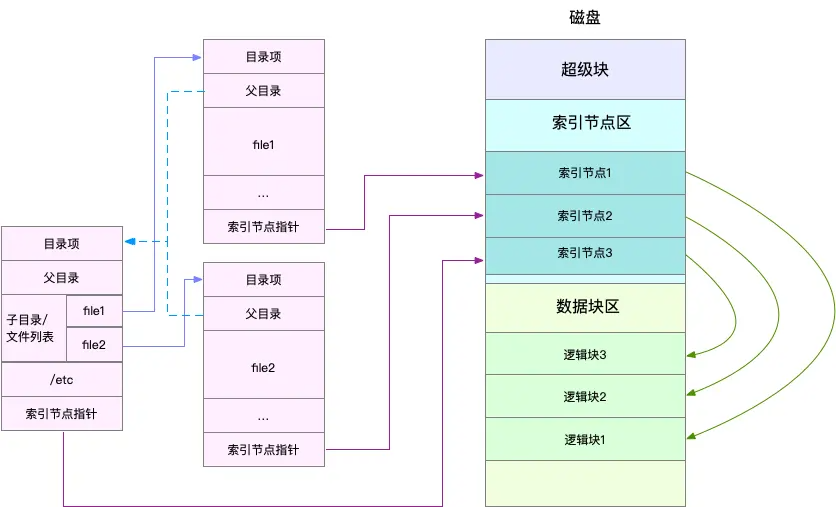
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
- 超级块,存储整个文件系统的状态。
- 索引节点区,用来存储索引节点。
-
虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过,为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。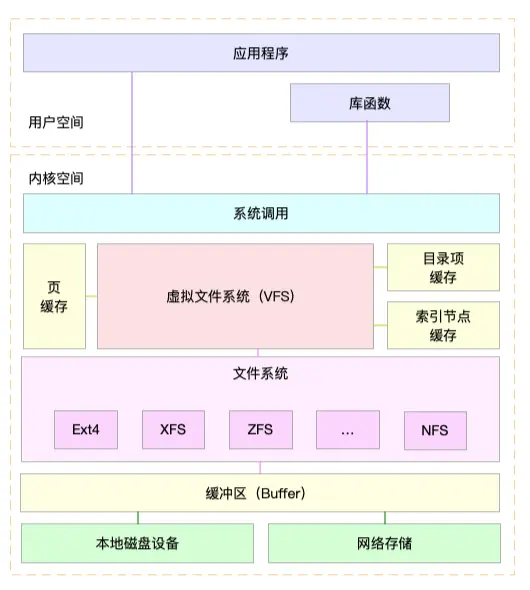
文件系统I/O
第一种,根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。
缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
- 非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
注意,这里所说的“缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
第二,根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。
如果没有设置过,默认的是非直接 I/O。不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
第三,根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
第四,根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。

若有收获,就点个赞吧
0 人点赞
