 ">
">
添加数据(INSERT)
**INSERT INTO 表名[(字段1,字段2,字段3,...)] VALUES('值1','值2','值3')**
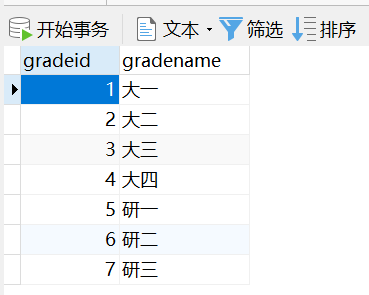
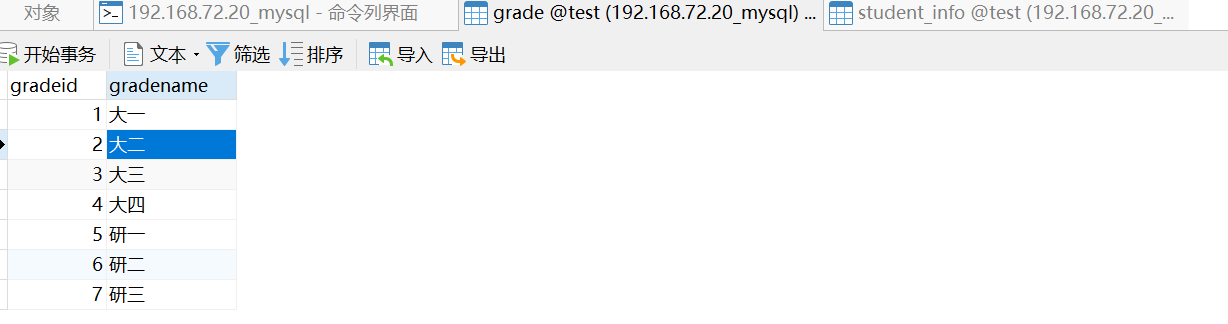
-- 使用语句如何增加语句?-- 语法 : INSERT INTO 表名[(字段1,字段2,字段3,...)] VALUES('值1','值2','值3')INSERT INTO grade(gradeid,gradename) VALUES (1,'大一');-- 主键自增,那能否省略呢? 可以INSERT INTO grade VALUES ('大二');-- 查询:INSERT INTO grade VALUE ('大二')错误代码:1136 Column count doesn`t match value count at row 1正确语句:INSERT INTO grade(gradename) VALUES ('大二');-- 结论:'字段1,字段2...'该部分可省略 , 但添加的值务必与表结构,数据列,顺序相对应,且数量一致.-- 一次插入多条数据INSERT INTO grade(gradename) VALUES ('大三'),('大四'),('研一'),('研二'),('研三');
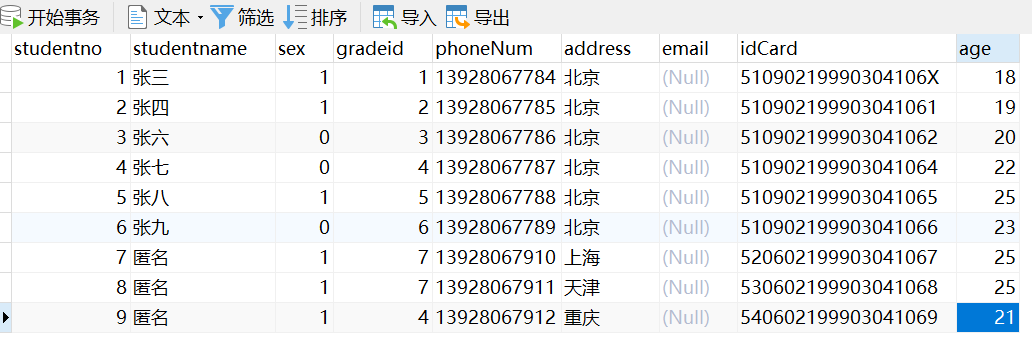
--为student_info插入数据#注:studentno自增,phoneNum非空insert into student_info(studentno,studentname,sex,gradeid,phoneNum,idCard)values(1,'张三',1,1,'13928067784','51090219990304106X'),insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张四',1,2,'13928067785','510902199903041061');insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张五',0,3,'13928067786','510902199903041062');insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张六',0,4,'13928067777','510902199903041063');insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张七',0,5,'13928067787','510902199903041064');insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张八',1,6,'13928067788','510902199903041065');insert into student_info(studentname,sex,gradeid,phoneNum,idCard)values('张九',0,7,'13928067789','510902199903041066');
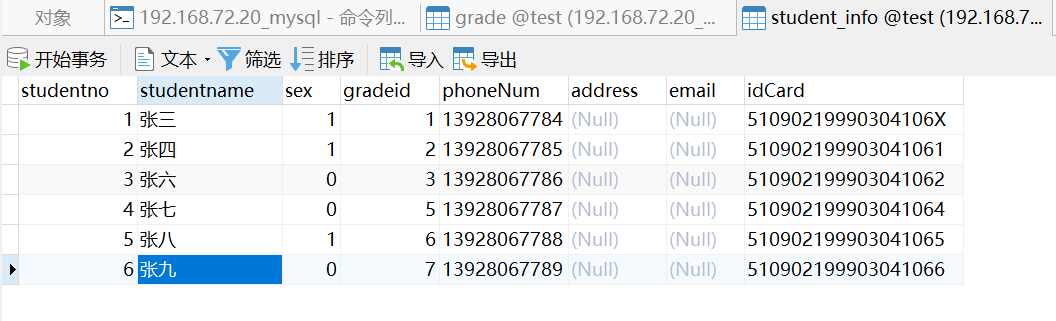
修改数据(UPDATE)
UPDATE 表名 SET column_name=value [,column_name2=value2,...] [WHERE condition];
参数说明 :
- column_name 为要更改的数据列
- value 为修改后的数据 , 可以为变量 , 具体指 , 表达式或者嵌套的SELECT结果
- condition 为筛选条件 , 如不指定则修改该表的所有列数据
where条件子句
可以简单的理解为 : 有条件地从表中筛选数据
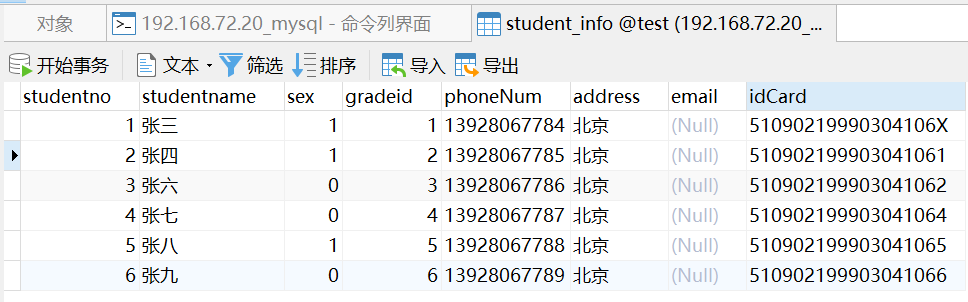
-- 修改年级信息UPDATE grade SET gradename = '高中' WHERE gradeid = 1; #修改某行UPDATE grade SET gradename = '高中'; #修改全部行
删除数据(DELETE)
DELETE FROM 表名 [WHERE condition];
注意:condition为筛选条件 , 如不指定则删除该表的所有列数据
-- 删除一个数据DELETE FROM grade WHERE gradeid = 5-- 删除全表数据DELETE FROM grade;-- 同样使用DELETE清空不同引擎的数据库表数据.重启数据库服务后-- InnoDB : 自增列从初始值重新开始 (因为是存储在内存中,断电即失)-- MyISAM : 自增列依然从上一个自增数据基础上开始 (存在文件中,不会丢失)
TRUNCATE命令
作用:用于完全清空表数据 , 但表结构 , 索引 , 约束等不变 ;
TRUNCATE [TABLE] table_name;-- 清空年级表TRUNCATE grade;TRUNCATE TABLE grade;-- 结论:truncate删除数据,自增当前值会恢复到初始值重新开始;不会记录日志.
注意:TRUNCATE 区别于DELETE命令
- 相同 : 都能删除数据 , 不删除表结构 , 但TRUNCATE速度更快
不同 :
- 使用TRUNCATE TABLE 重新设置AUTO_INCREMENT计数器
- 使用TRUNCATE TABLE不会对事务有影响 (事务后面会说)
查询数据(SELECT)
select语法汇总
```java SELECT [ALL | DISTINCT] — 全部数据|过滤重复数据 { | table. | [table.field1[as alias1][,table.field2[as alias2]][,…]]} — *所有|指定对应属性字段 FROM table_name [as table_alias] —as 起别名 [left | right | inner join table_name2] — 联合查询 [WHERE …] — 指定结果需满足的条件 [GROUP BY …] — 指定结果按照哪几个字段来分组 [HAVING] — 过滤分组的记录必须满足的次要条件 [ORDER BY …] — 指定查询记录按一个或多个条件排序 [LIMIT {[offset,]row_count | row_countOFFSET offset}]; — 指定查询的记录从哪条至哪条
参数说明:
[ ] 括号代表可选的 , { }括号代表必选的,|代表选其中一种
**查询语句的书写顺序和执行顺序 select ===> from ===> where ===> group by ===> having ===> order by ===> limit 查询语句的执行顺序 from ===> where ===> group by ===> having ===> select ===> order by ===> limit
<a name="XgMH6"></a>## 1.简单查询即不含where的select语句。<a name="WAnxg"></a>### 查询所有字段```javaselect * from student;(方法不唯一只是举例)
查询指定字段(sid、sname)
select sid,sname from student;
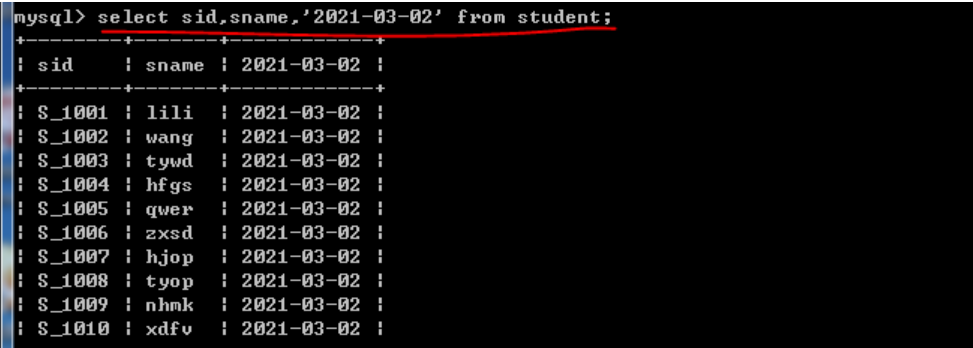
常数的查询
select sid,sname,'2021-03-02' from student;
过滤重复数据
SELECT * FROM student_info; -- 查看学生地址select address from student_info; -- 查看学生地址select distinct address from student_info; -- 了解:DISTINCT 去除重复项 , (默认是ALL)



算术运算符
在SELECT查询语句中还可以使用加减乘除运算符select sname,age+10 from student;SELECT 100*3-1 AS 计算结果; -- 表达式

2.函数
聚合函数
只有SELECT子句和HAVING子句、ORDER BY子句中能够使用聚合函数。例如,在WHERE子句中使用聚合函数是错误的。
1.count()
统计表中数据的行数或者统计指定列其值不为NULL的数据个数
select count(*) from student_info;select count(1) from student_info; 【推荐】select count(字段) from student_info; 【推荐】1)在表没有主键时,count(1)比count(*)快2)有主键时,主键作为计算条件,count(主键)效率最高;3)若表格只有一个字段,则count(*)效率较高。count(1)和count(*)都会对全表进行扫描,统计所有记录的条数,包括那些为null的记录,因此,它们的效率可以说是相差无几。而count(字段)则与前两者不同,它统计该字段不为null的记录条数。

2.max()|| min()
计算指定列的最大值 || 最小值(如果指定列是字符串类型则使用字符串排序运算)
select max(gradeid) from student_info;select min(gradeid) from student_info;
3.sum()
求和
select sum(age) from student;
4.avg()
求平均
select avg(age) from student;
其他常用函数
1.时间函数
SELECT NOW();SELECT DAY (NOW());SELECT DATE (NOW());SELECT TIME (NOW());SELECT YEAR (NOW());SELECT MONTH (NOW());SELECT CURRENT_DATE();SELECT CURRENT_TIME();SELECT CURRENT_TIMESTAMP();SELECT ADDTIME('14:23:12','01:02:01');SELECT DATE_ADD(NOW(),INTERVAL 1 DAY);SELECT DATE_ADD(NOW(),INTERVAL 1 MONTH);SELECT DATE_SUB(NOW(),INTERVAL 1 DAY);SELECT DATE_SUB(NOW(),INTERVAL 1 MONTH);SELECT DATEDIFF('2019-07-22','2019-05-05');SELECT VERSION(); /*版本*/SELECT USER(); /*用户*/
2.字符串函数
SELECT CHAR_LENGTH('狂神说坚持就能成功'); /*返回字符串包含的字符个数*/ #9SELECT CONCAT('我','爱','程序'); /*合并字符串,参数可以有多个*/ #我爱程序SELECT INSERT('我爱编程helloworld',1,2,'超级热爱'); /*替换字符串,开始位置:1,替换长度:2*/ #超级热爱编程helloworldSELECT LOWER('KuangShen'); /*小写*/ #kuangshenSELECT UPPER('KuangShen'); /*大写*/ #KUANGSHENSELECT LEFT('hello,world',5); /*从左边截取*/ #helloSELECT RIGHT('hello,world',5); /*从右边截取*/ #worldSELECT REPLACE('狂神说坚持就能成功','坚持','努力'); /*替换字符串*/ #狂神说努力就能成功SELECT SUBSTR('狂神说坚持就能成功',4,6); /*截取字符串,开始index:4,长度:6*/ #坚持就能成功SELECT REVERSE('狂神说坚持就能成功'); /*反转 #功成能就持坚说神狂SELECT REPLACE(studentname,'周','邹') AS 新名字 FROM student_info WHERE studentname LIKE '周%';-- 字符串函数length(string) -- string长度,字节char_length(string) -- string的字符个数substring(str, position [,length]) -- 从str的position开始,取length个字符replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_strinstr(string ,substring) -- 返回substring首次在string中出现的位置concat(string [,...]) -- 连接字串charset(str) -- 返回字串字符集lcase(string) -- 转换成小写left(string, length) -- 从string2中的左边起取length个字符load_file(file_name) -- 从文件读取内容locate(substring, string [,start_position]) -- 同instr,但可指定开始位置lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为lengthltrim(string) -- 去除前端空格repeat(string, count) -- 重复count次rpad(string, length, pad) --在str后用pad补充,直到长度为lengthrtrim(string) -- 去除后端空格strcmp(string1 ,string2) -- 逐字符比较两字串大小
3.数学函数
SELECT ABS(-136); -- 绝对值SELECT FLOOR(3.14); -- 向下取整SELECT CEILING(3.14); 或 select ceil(3.14); -- 向上取整SELECT RAND(); --随机数,返回一个0-1之间的随机数SELECT SIGN(0); --符号函数: 负数返回-1,正数返回1,0返回0SELECT MOD(m, n); --m%n m mod n 求余。 10%3=1select pi(); --圆周率select pow(m,n); --m^nselect sqrt(x); --x的算术平方根select truncate(x, d); -- 截取d位小数
3.条件查询(WHERE)
逻辑操作符

-- 满足条件的查询(where)SELECT Studentno,StudentResult FROM result;-- 查询考试成绩在95-100之间的 -- AND也可以写成 &&SELECT Studentno,StudentResultFROM resultWHERE StudentResult>=95 AND StudentResult<=100;-- 模糊查询(对应的词:精确查询) --between是取闭区间, 如:[95,100]SELECT Studentno,StudentResultFROM resultWHERE StudentResult BETWEEN 95 AND 100;-- 除了1000号同学,要其他同学的成绩SELECT studentno,studentresultFROM resultWHERE studentno!=1000;-- 使用NOTSELECT studentno,studentresultFROM resultWHERE NOT studentno=1000;
模糊查询 :比较操作符
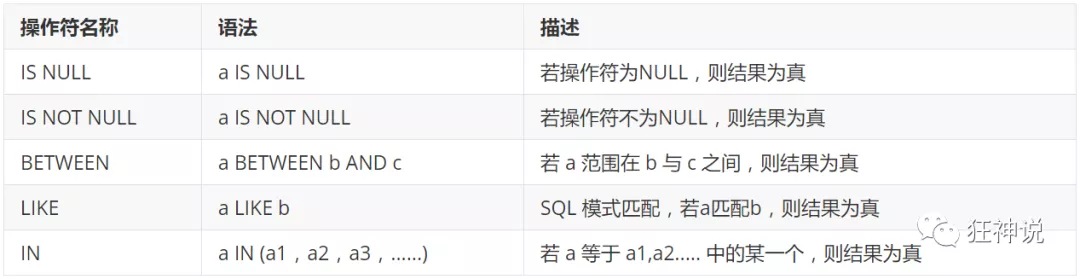
- 数值数据类型的记录之间才能进行算术运算 ;
- 相同数据类型的数据之间才能进行比较 ; ```java ====模糊查询 between and \ like \ in \ null
====使用IN关键字查询(判断某个字段的值是否在指定集合中) —注意:in不是范围,而是一个集合list select * from student_info where age in (20,22,23);
====使用LIKE关键字查询 — 查询姓刘的同学的学号及姓名 — like结合使用的通配符 : % (代表0到任意个字符) _ (一个字符) SELECT studentno,studentname FROM student WHERE studentname LIKE ‘刘%’;
— 查询姓刘的同学,后面只有一个字的 SELECT studentno,studentname FROM student WHERE studentname LIKE ‘刘_’;
— 查询姓刘的同学,后面只有两个字的 SELECT studentno,studentname FROM student WHERE studentname LIKE ‘刘__’;
— 查询姓名中含有 ‘嘉’ 字的 SELECT studentno,studentname FROM student WHERE studentname LIKE ‘%嘉%’;
— 查询姓名中含有特殊字符的需要使用转义符号 ‘\’ — 自定义转义符关键字: ESCAPE ‘:’
====使用NULL关键字查询 — 查询出生日期没有填写的同学 — 不能直接写=NULL , 这是代表错误的 , 用 is null SELECT studentname FROM student WHERE BornDate IS NULL;
— 查询出生日期填写了的同学 SELECT studentname FROM student WHERE BornDate IS NOT NULL;
— 查询没有写家庭住址的同学(空字符串不等于null) SELECT studentname FROM student WHERE Address=’’ OR Address IS NULL;
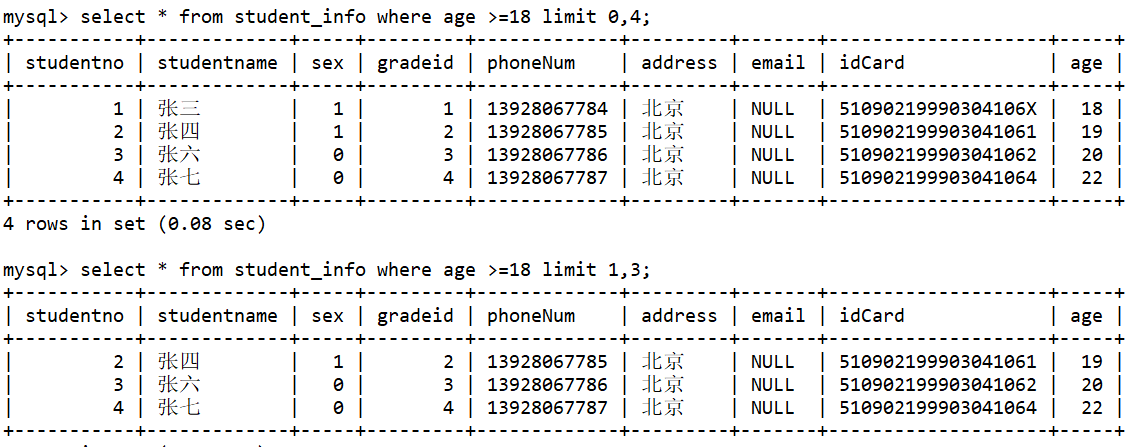
<a name="XsI9a"></a>### 分页(LIMIT)好处 : (用户体验,网络传输,查询压力)```javaSELECT * FROM table LIMIT currentIndex, pagSize;推导:第一页 : limit 0,5第二页 : limit 5,5第三页 : limit 10,5......第N页 : limit (pageNo-1)*pageSzie,pageSzie[pageNo:页码,pageSize:单页面显示条数]---- 每页显示3条数据select * from student_info where age >=18 limit 0,4; --从表中第1条数据起查,每页显示4条数据select * from student_info where age >=18 limit 1,3; --从表中第2条数据起查,每页显示3条数据
排序(ORDER BY)
ORDER BY 语句用于根据指定的列对结果集进行排序。ORDER BY 语句默认按照ASC升序对记录进行排序。如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。select * from student_info order by age desc;
分组(GROUP BY)
==GROUP BY和聚合函数一起使用select count(*), sex from student_info group by sex; --count(*)可以替换为任意想要计数的字段==GROUP BY和聚合函数以及HAVING一起使用select sum(age),sex from student_info group by sex having sum(age)>18 order by sum(age) desc;WHERE 搜索条件在进行分组操作之前应用;而 HAVING 搜索条件在进行分组操作之后应用。HAVING 语法与 WHERE 语法类似,但 HAVING 可以包含聚合函数。

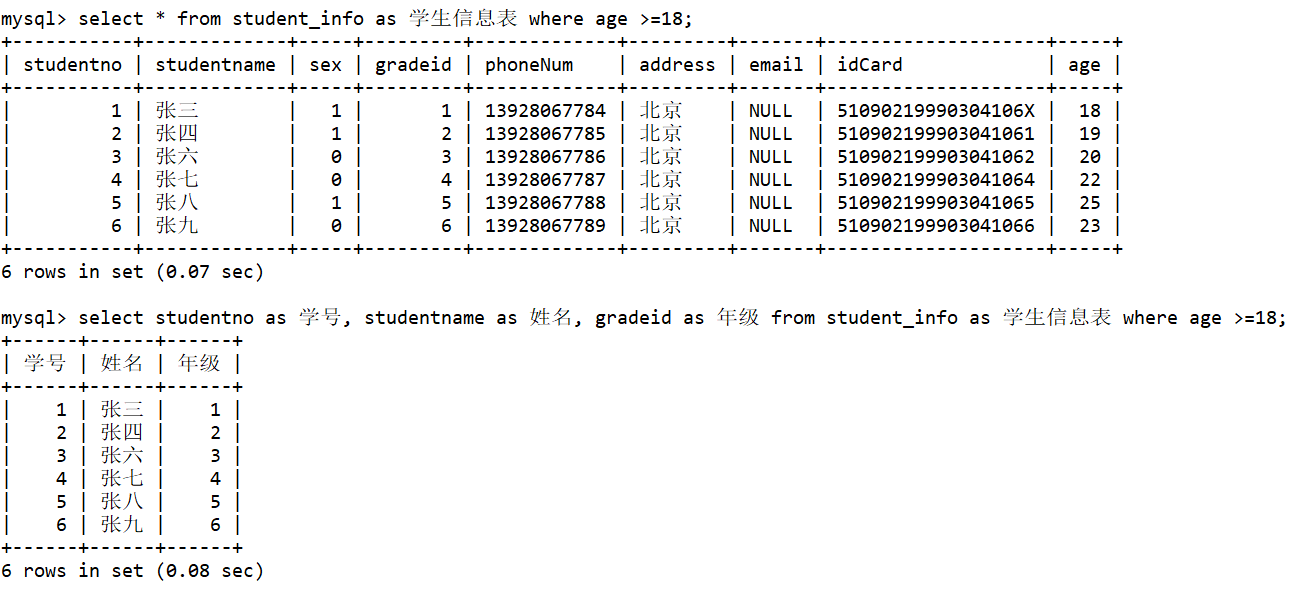
别名(AS)
1.为表取别名SELECT * FROM 表名 [AS] 表的别名 WHERE .... ;2.为字段取别名SELECT 字段名1 [AS] 别名1 , 字段名2 [AS] 别名2 , ... FROM 表名 WHERE ... ;select * from student_info as 学生信息表 where age >=18;select studentno as 学号, studentname as 姓名, gradeid as 年级 from student_info as 学生信息表 where age >=18;
多表查询
1.连接查询(JOIN)
如需要多张数据表的数据进行查询,则可通过连接运算符实现多个查询

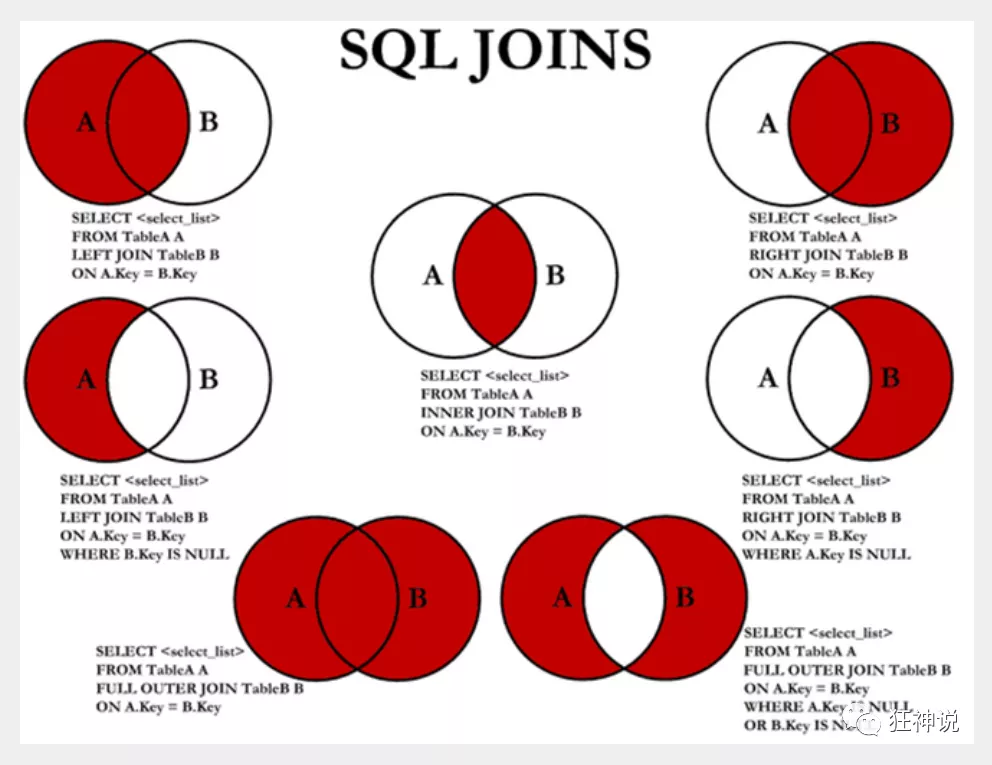
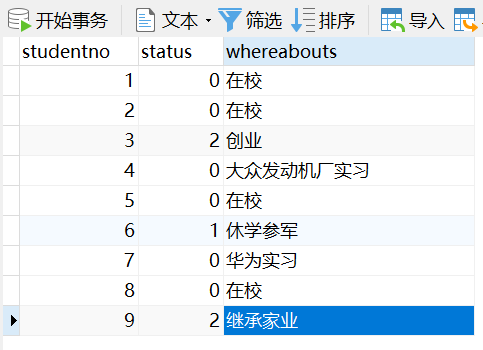
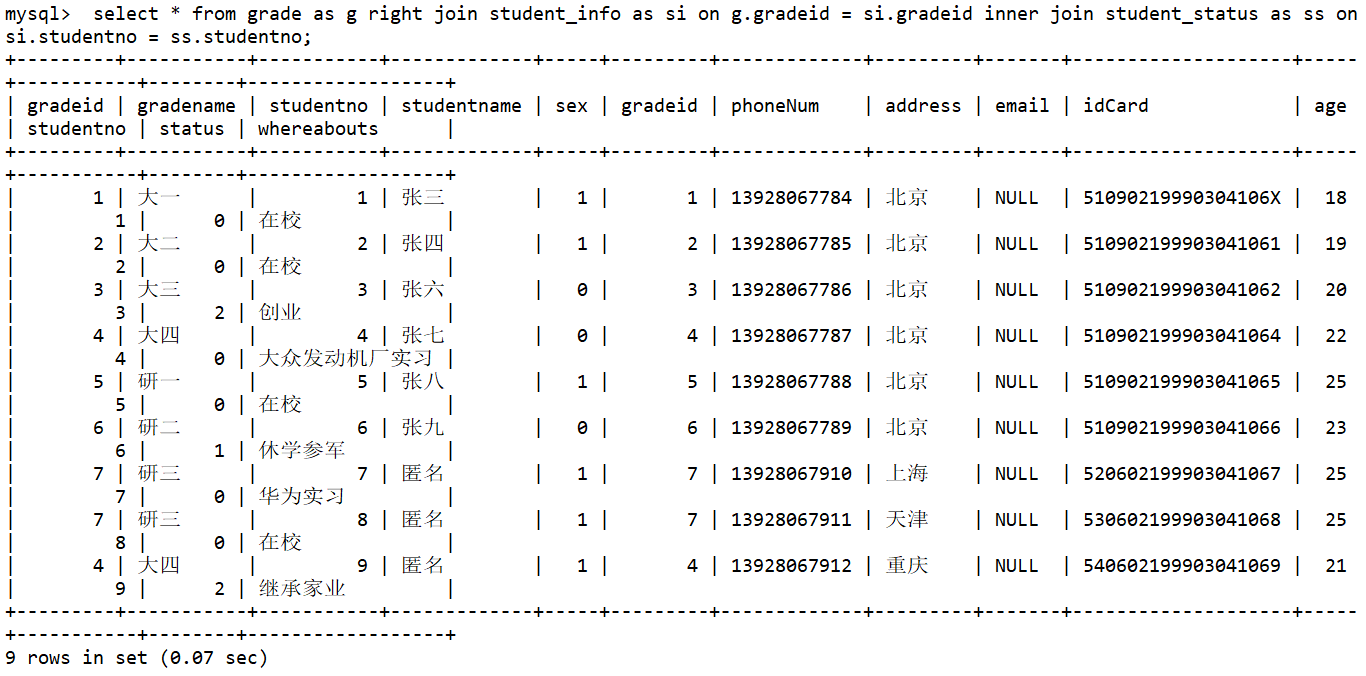
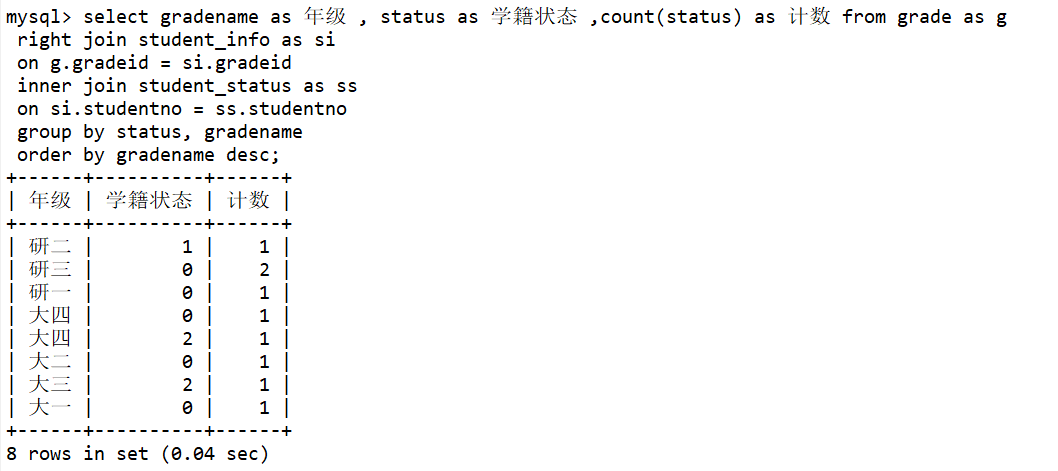
内连接 inner join查询两个表中的结果集中的交集外连接 outer join左外连接 left join(以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充)右外连接 right join(以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充)---------------------------------------------------------------------------------------------------------------------------目标: 查询各年级在校、休学、辍学的学生数量/*思路:(1):分析需求,确定查询的列来源于3个类,grade|student_info|student_status,连接查询(2):确定使用哪种连接查询?(内连接)*/---------------------------------------------------------------------------------------------------------------------------先用grade|student_info表通过gradeid (right join) -->得到表,再通过 studentno (inner join)select * from grade as gright join student_info as sion g.gradeid = si.gradeidinner join student_status as sson si.studentno = ss.studentno;------------------------------------优化:select gradename as 年级 , status as 学籍状态 , count(status) as 计数 from grade as gright join student_info as sion g.gradeid = si.gradeidinner join student_status as sson si.studentno = ss.studentnogroup by status, gradenameorder by gradename desc;
2.子查询
通常我们在查询的SQL中嵌套查询,称为子查询。子查询通常会使复杂的查询变得简单,但是相关的子查询要对基础表的每一条数据都进行子查询的动作,所以当表单中数据过大时,一定要慎重选择!
在查询语句中的条件子句中,又嵌套了另一个查询语句嵌套查询可由多个子查询组成,求解的方式是由里及外;子查询返回的结果一般都是集合,故而建议使用IN关键字;----------------------------------------------------------------------------------------------------------------------------带EXISTS关键字的子查询当内层返回值为TRUE时外层查询才会 执行select * from grade where exists (select * from student_info where 1=1);-----------------------------------------------------------------------------------------------------------------------------带ANY关键字的子查询ANY关键字表示满足内层其中任意一个条件就返回一个结果作为外层查询条件select * from student_info where age > any (select age from student_info where age <20);-----------------------------------------------------------------------------------------------------------------------------带ALL关键字的子查询ALL关键字与ANY有点类似,只不过带ALL关键字的子査询返回的结果需同时满足所有内层査询条件select * from student_info where age >= all (select age from student_info where age <19);----------------------------------------------------------------------------------------------------------------------------带IN关键字的子查询--现在我们用子查询的方式实现上面连接查询的目标(查询各年级在校、休学、辍学的学生数量)select gradename as 年级 , status as 学籍状态 , count(status) as 计数 from gradewhere gradeid in (select gradeid from student_infowhere studentno in (select studentno from student_status))group by gradename, statusorder by gradename desc;-- 发现无法实现,报错:Unknown column 'status' in 'field list'。意思就是status这些字段不在grade表中!-- 所以子查询在某些方面还是有缺陷的-------------------------------------------------------------------------------------------------现在我们实现: 查询'研究生'中各年级存在'学籍状态不为0'的数量select gradename as 年级, count(gradename) as 计数 from gradewhere gradeid in (select gradeid from student_info where gradeid between 5 and 7and studentno in (select studentno from student_status where status!=0))group by gradenameorder by gradename desc;
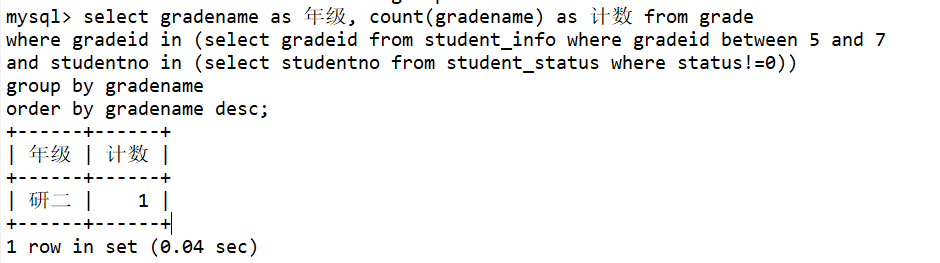
说明:研究生中,只有研二有1个学生的学籍状态不为 !0 (不在校),其他均在校
3.联合查询(UNION)
合查询结果是将多个select语句的查询结果合并到一块,因为在某种情况下需要将几个select语句查询的结果合并起来显示。
比如现在需要查询两个公司的所有员工的信息,这就需要从甲公司查询所有员工信息,再从乙公司查询所有的员工信息,然后将两次的查询结果进行合并。
联合查询的意义:
- 查询同一张表,但是需求不同 如查询学生信息, 男生身高升序, 女生身高降序
- 多表查询: 多张表的结构是完全一样的,保存的数据(结构)也是一样的。 ```java 语法: select 语句1 union [all|distinct] select 语句2 union|[all|distinct] select 语句n
注意:各条select 语句返回的result的字段(colums)必须要一致!
不然会报错:The used SELECT statements have a different number of columns
在联合查询中: order by不能直接使用(不能出现两次),需要对查询语句使用括号才行; order by不能直接多次出现在union的子句中,但是可以出现在子句的子句中。
select from
(select from student
where sex=”woman”
order by score)student
union
select from
(select from student
where sex=”man”
order by score)student;
```


若有收获,就点个赞吧
0 人点赞
