参考链接:https://blog.csdn.net/qq_39390545/article/details/119112228
事务
什么是Mysql事务
- 事务就是将一组SQL语句放在同一批次内去执行
- 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行
-
事务的ACID原则
原子性(Atomic)
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(ROLLBACK)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consist)
- 一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。也就是说:如果事务是并发多个,系统也必须如同串行事务一样操作。其主要特征是保护性和不变性(Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是100元,那么五个账户总额是500元,如果在这个5个账户之间同时发生多个转账,无论并发多少个,比如在A与B账户之间转账5元,在C与D账户之间转账10元,在B与E之间转账15元,五个账户总额也应该还是500元,这就是保护性和不变性。
隔离性(Isolated)
- 隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
持久性(Durable)
- 在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
基本语法
```java — 使用set语句来改变自动提交模式 SET autocommit = 0; /关闭/ SET autocommit = 1; /开启/
— 注意: —- 1.MySQL中默认是自动提交
—- 2.使用事务时应先关闭自动提交
— 开始一个事务,标记事务的起始点 START TRANSACTION
执行CRUD
— 提交一个事务给数据库 COMMIT
— 将事务回滚,数据回到本次事务的初始状态 ROLLBACK
— 还原MySQL数据库的自动提交
SET autocommit =1;
— 保存点 SAVEPOINT 保存点名称 — 设置一个事务保存点 ROLLBACK TO SAVEPOINT 保存点名称 — 回滚到保存点 RELEASE SAVEPOINT 保存点名称 — 删除保存点
<a name="Pn2Ws"></a># 索引<a name="YYY79"></a>## 索引的作用- 提高查询速度- 确保数据的唯一性- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间- 全文检索字段进行搜索优化.<a name="umBTR"></a>## 索引的分类<a name="OWgIV"></a>### 1.主键索引 (Primary Key)主键 : 某一个属性组能唯一标识一条记录<br />特点 :- 最常见的索引类型- 确保数据记录的唯一性- 确定特定数据记录在数据库中的位置<a name="FCEnp"></a>### 2.唯一索引 (Unique)作用 : 避免同一个表中某数据列中的值重复<br />与主键索引的区别- 主键索引只能有一个- 唯一索引可能有多个```javaCREATE TABLE `Grade`(`GradeID` INT(11) AUTO_INCREMENT PRIMARYKEY,`GradeName` VARCHAR(32) NOT NULL UNIQUE-- 或 UNIQUE KEY `GradeID` (`GradeID`))
3.普通索引 (Index)
作用 : 快速定位特定数据
注意 :
- index 和 key 关键字都可以设置常规索引
- 应加在查询找条件的字段
- 不宜添加太多常规索引, 影响数据的插入, 删除和修改操作
``java -- 创建表时添加 CREATE TABLEresult( -- 省略一些代码 INDEX/KEYind(studentNo,subjectNo`) )
— 创建后添加
ALTER TABLE result ADD INDEX ind(studentNo,subjectNo);
<a name="mcEAY"></a>### 4.联合索引 ( index )一次性的为表中的多个列创建索引 (建议一个联合索引不超过5个字段)(最左前缀法则:如何命中联合索引中的索引列),开发常用!```java-- 格式create index 索引名称 on 表名(列名1,列名2, ...);-- 示例create index idx_name_age_password on user(name,age,password);
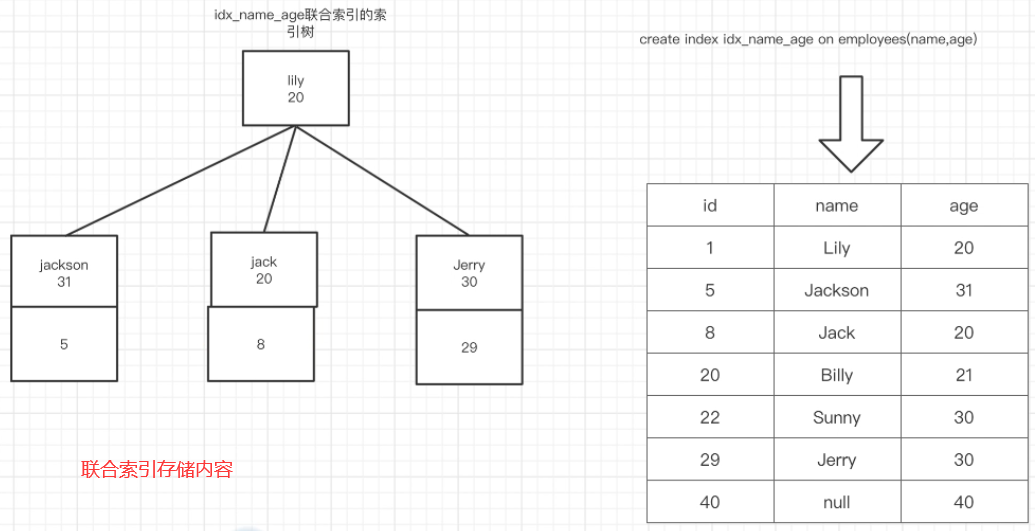
5.全文索引 (FullText)
作用 : 快速定位特定数据
注意 :
- 只能用于MyISAM类型的数据表
- 只能用于CHAR , VARCHAR , TEXT数据列类型
- 适合大型数据集
- 进行查询时,数据源可能来自不同的字段或者表MyISAM存储引擎支持全文索引,在实际开发中并不会去使用而是使用搜索引擎中间件
汇总
```java 【强制】主键索引名为 pk字段名;唯一索引名为 uk字段名;普通索引名则为 idx字段名。 说明:pk 即 primary key;uk 即 unique key;idx 即 index 的简称。
方法一:创建表时
CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) );
方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名ON 表名 (字段名[(长度)] [ASC |DESC]) ;
方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
删除索引:DROP INDEX 索引名 ON 表名字;
删除主键索引: ALTER TABLE 表名 DROP PRIMARY KEY;
显示索引信息: SHOW INDEX FROM student;
/增加全文索引/
ALTER TABLE school.student ADD FULLTEXT INDEX studentname (StudentName);
/EXPLAIN : 分析SQL语句执行性能/ EXPLAIN SELECT * FROM student WHERE studentno=’1000’;
/使用全文索引/ — 全文搜索通过 MATCH() 函数完成。 — 搜索字符串作为 against() 的参数被给定。搜索以忽略字母大小写的方式执行。对于表中的每个记录行, MATCH() 返回一个相关性值。即,在搜索字符串与记录行在 MATCH() 列表中指定的列的文本之间的相似性尺度。 EXPLAIN SELECT * FROM student WHERE MATCH(studentname) AGAINST(‘love’);
/* 开始之前,先说一下全文索引的版本、存储引擎、数据类型的支持情况
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引; MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引; 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。 测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。 */
<a name="rTNnM"></a>
## 索引的数据结构
- **二叉树** (链表情况)
- **红黑树** (层次太多)
- **Hash表**
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+树索引更高效
- 查询单条快,范围查询慢
- 仅能满足“=”,“IN”,不支持范围查询
- hash冲突问题
- **B Tree**
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
- B/B+树,层数越多,数据量指数级增长
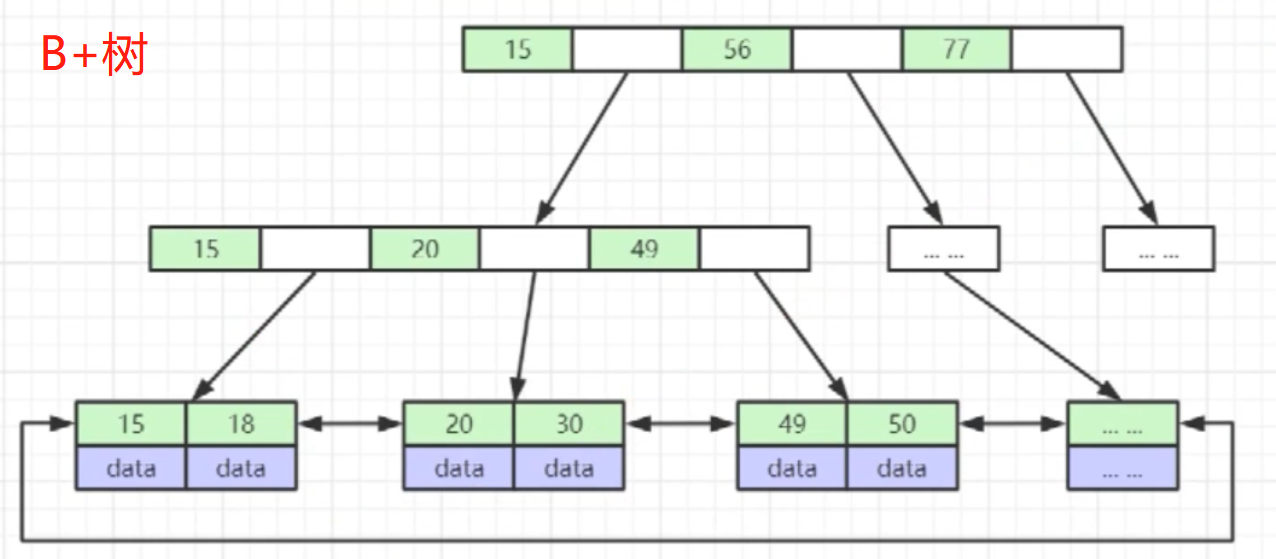
- **B+Tree **(底层)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
- B/B+树,层数越多,数据量指数级增长
- innodb默认支持它
<a name="LcUZ7"></a>
## 聚簇索引与非聚簇索引
说索引像一个汉语字典,聚集索引是根据拼音查询,而非聚集索引是根据偏旁部首查询,你想想哪个查的快?
<a name="cEn03"></a>
### 1.聚集索引
聚集索引是我们常用的一种索引,聚集索引的数据跟索引存储在一起。该索引中键值的逻辑顺序决定了表中相应行的物理顺序,我们叶子结点直接对应的实际数据,当索引值唯一(unique)时,使用聚集索引查找特定的行效率很高。例如,使用唯一店员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。可见,自增主键就是一个标准的聚集索引。
**当某列满足两个条件时,我们可以创建聚集索引**:
1. 数据存储有序(如自增)
1. key值应当唯一
聚簇索引像字典按字母顺序排列数据,有序。在聚集索引中,索引包含指向数据存储的块而不是数据存储地址的指针,和非聚集索引(Normal)相反。<br />
<a name="W7BWx"></a>
### 2.非聚集索引
非聚集索引的数据存储在一个位置,索引存储在另一位置。由于数据和非聚集索引是分开存储的,因此在一个表中可以有多个非聚集索引。非聚集索引就是索引类型为Normal的普通索引啦,我们在[《聊聊MySQL索引“B+Tree”的前世今生》](https://chensj.blog.csdn.net/article/details/117402214)这篇文章中提到,B+Tree(这里是索引类型是Normal)所有关键字存储在叶子节点,但不存储真正的data,叶子结点存的是一个指向磁盘data的指针,需要到磁盘数据页中取。
<a name="JzsuQ"></a>
### 聚集索引 和 非聚集索引的区别
1. 单表中只能有一个聚集索引,而非聚集索引单表可以存在多个。
1. 聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
1. 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
1. 聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;
<a name="zSIPK"></a>
#### 追问1:
**为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢?**<br />乍一看,这还真是和聚集索引的约束相背,但实际情况真可以创建聚集索引。<br /> 其原因是:如果未使用 UNIQUE 属性创建聚集索引,数据库引擎将向表自动添加一个四字节 uniqueifier列。必要时,数据库引擎 将向行自动添加一个 uniqueifier 值,使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
<a name="xBuLf"></a>
#### 追问2:
**聚集索引一定比非聚集索引性能优么?**<br />如果想查询学分在60-90之间的学生的学分以及姓名,在学分上创建聚集索引是否是最优的呢?<br /> 并不是。既然只输出两列,我们可以在学分以及学生姓名上创建联合非聚集索引,此时的索引就形成了 [覆盖索引](https://blog.csdn.net/qq_15037231/article/details/87891683) ,即索引所存储的内容就是最终输出的数据,这种索引当然比以学分为聚集索引做查询性能好,算是相当于联合聚集索引~~灵活运用即可。
<a name="YtoZf"></a>
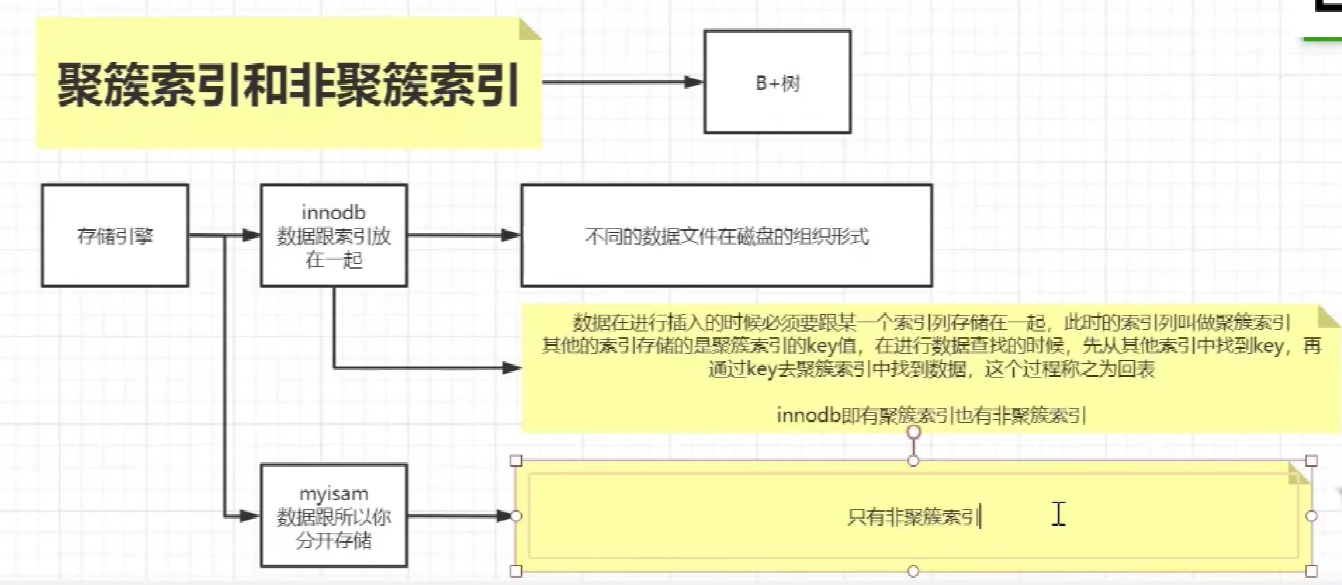
### Innodb和Myisam区别
```java
1、INNODB引擎----聚集索引
把索引和数据存放在一个文件中,通过找到索引后就能直接在索引树上的叶子结点中获得完整的数据。
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
2、MYISAM----非聚集索引
把索引和数据存放在两个文件中,查找到索引后还要去另一个文件中找数据,性能会慢一些
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
索引最左前缀原则
最左前缀原则是表示一条sql语句在联合索引中有没有走索引(命中索引/不会全表扫描)。
在建立联合索引的时候,无论是Oracle还是 MySQL 都会让我们选择索引的顺序,比如我们想在a,b,c三个字段上建立一个联合索引,我们可以选择自己想要的优先级,(a、b、c),或是 (b、a、c) 或者是(c、a、b) 等顺序。
在我们开发中经常会遇到这种问题,明明这个字段建了联合索引,但是SQL查询该字段时却不会使用这个索引。难道这索引是假的?
- 比如索引abc_index:(a,b,c)是a,b,c三个字段的联合索引,下列sql执行时都无法命中索引abc_index; ```java select * from table where c = ‘1’;
select * from table where b =’1’ and c =’2’;
- 以下三种情况却会走索引:
```java
select * from table where a = '1';
select * from table where a = '1' and b = '2';
select * from table where a = '1' and b = '2' and c='3';
- 其实当where条件只有(a,c)时也会走,但是只走a字段索引,不会走c字段。这至少把 a 的数据筛选出来了,总比直接全表扫描好多了。
咱们再来看一张索引存储数据的结构图,或许更明了一些。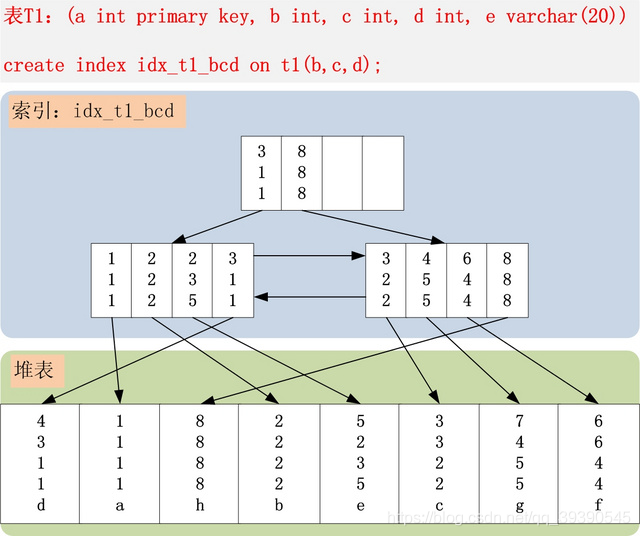
拓展1:如果建的索引顺序是 (a, b)。而查询的语句是 where b = 1 AND a = ‘陈哈哈’; 为什么还能利用到索引?
理论上索引对顺序是敏感的,但是由于 MySQL 的查询优化器会自动调整 where 子句的条件顺序以使用适合的索引,所以 MySQL 不存在 where 子句的顺序问题而造成索引失效。当然了,SQL书写的好习惯要保持。
拓展2:还有一个特殊情况说明下,下面这种类型的SQL, a 与 b 会走索引,c不会走。
select * from LOL where a = 2 and b > 1000 and c='JJJ疾风剑豪';
MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配(包括like ‘陈%’这种)。在a、b走完索引后,c已经是无序了,所以c就没法走索引,优化器会认为还不如全表扫描c字段来的快。所以只使用了(a,b)两个索引,影响了执行效率。这种场景可以通过修改索引顺序为 abc_index:(a,c,b),就可以使三个索引字段都用到索引。
索引创建原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表建议不要加索引
- 索引一般应加在查找条件的字段
- Tip: 一个索引的选择性越接近1,这个索引的效率就越高! ```java ==需要建索引的情况== 1、主键自动建立唯一索引 2、频繁作为查询条件的字段应该创建索引 3、查询中与其他表关联的字段,外键关系建立索引 4、单键/组合索引的选择问题 ?( 在高并发下倾向创建组合索引 ) 5、查询中排序的字段,排序字段通过索引去访问将大大提高排序速度 6、查询中统计或分组字段
==不需要建索引的情况== 1、频繁更新的字段不适合创建索引 2、经常增删改的表 3、where条件里用不到的字段不创建索引 4、表记录太少 5、如果某个数据列包含许多重复的内容,为他建立索引没有太大的效果
<a name="DWCAJ"></a>
## 测试索引
**建表app_user:**
```java
CREATE TABLE `app_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT '' COMMENT '用户昵称',
`email` varchar(50) NOT NULL COMMENT '用户邮箱',
`phone` varchar(20) DEFAULT '' COMMENT '手机号',
`gender` tinyint(4) unsigned DEFAULT '0' COMMENT '性别(0:男;1:女)',
`password` varchar(100) NOT NULL COMMENT '密码',
`age` tinyint(4) DEFAULT '0' COMMENT '年龄',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='app用户表';
批量插入数据:100w条
三种方法解决报错:This function has none of DETERMINISTIC, NO SQL...
1. mysql> set global log_bin_trust_function_creators = 1;
2. 系统启动时 --log-bin-trust-function-creators=1
3. 在my.ini(linux下为my.conf)文件中 [mysqld] 标记后加一行内容为 log-bin-trust-function-creators=1
-------------------------------------------------------------------
DROP FUNCTION IF EXISTS mock_data;
DELIMITER $$
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO app_user(`name`, `email`, `phone`, `gender`, `password`, `age`)
VALUES(CONCAT('用户', i), '24736743@qq.com', CONCAT('18', FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(), FLOOR(RAND()*100));
SET i = i + 1;
END WHILE;
RETURN i;
END;
SELECT mock_data();
索引效率测试
1.无索引
select * from app_user where name = '用户9999'; -- 查看耗时:大约在0.6s
select * from app_user where name = '用户99999';
select * from app_user where name = '用户999999';
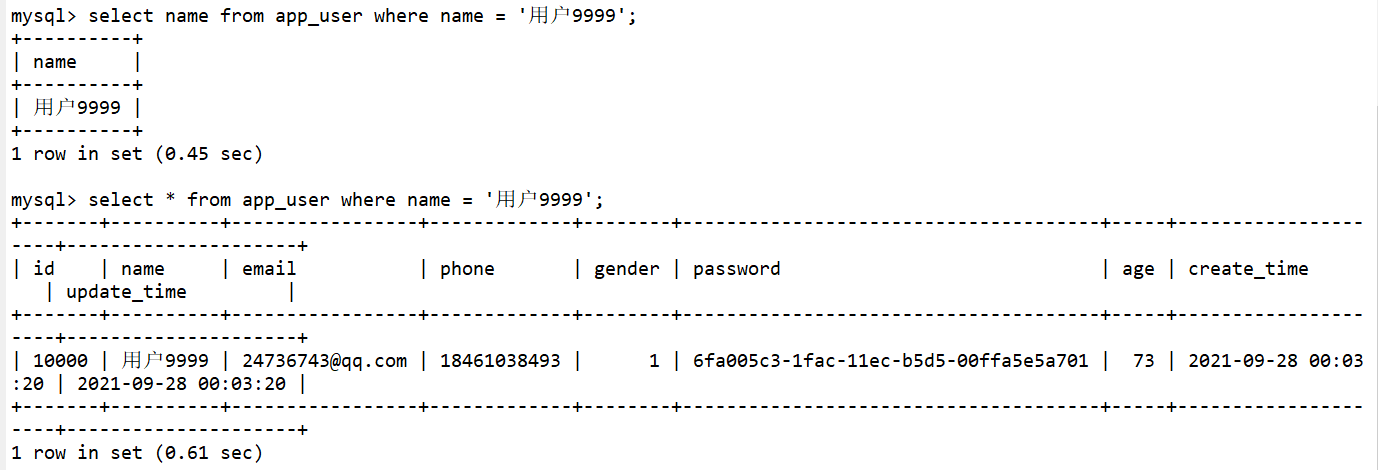
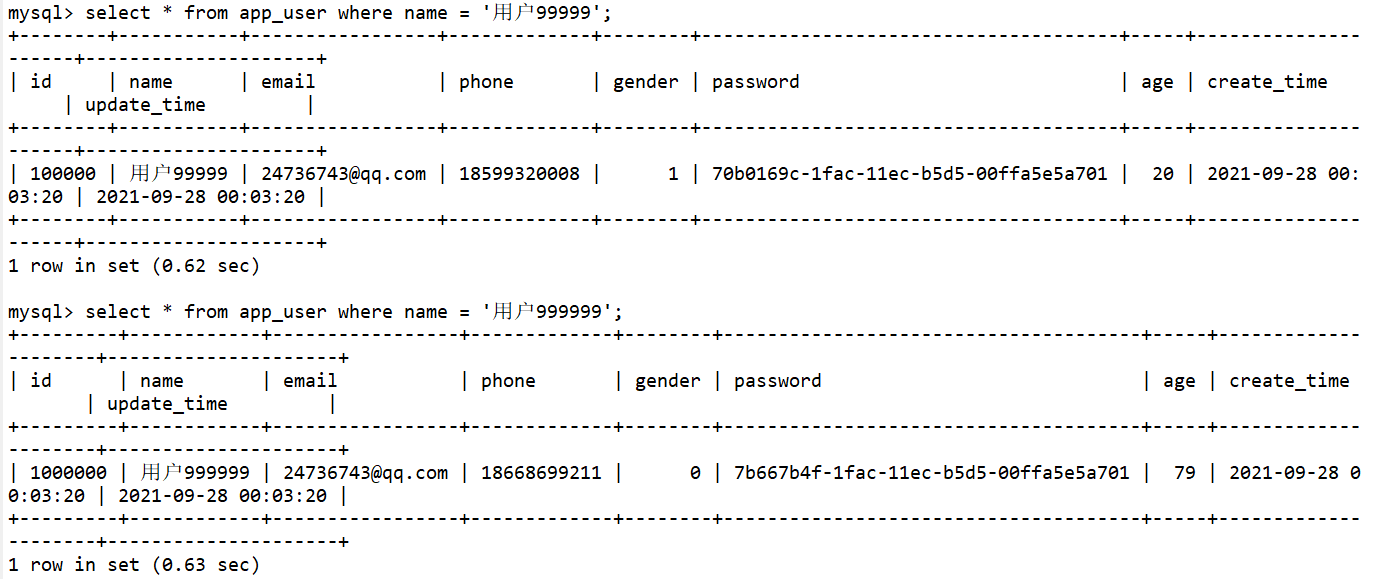
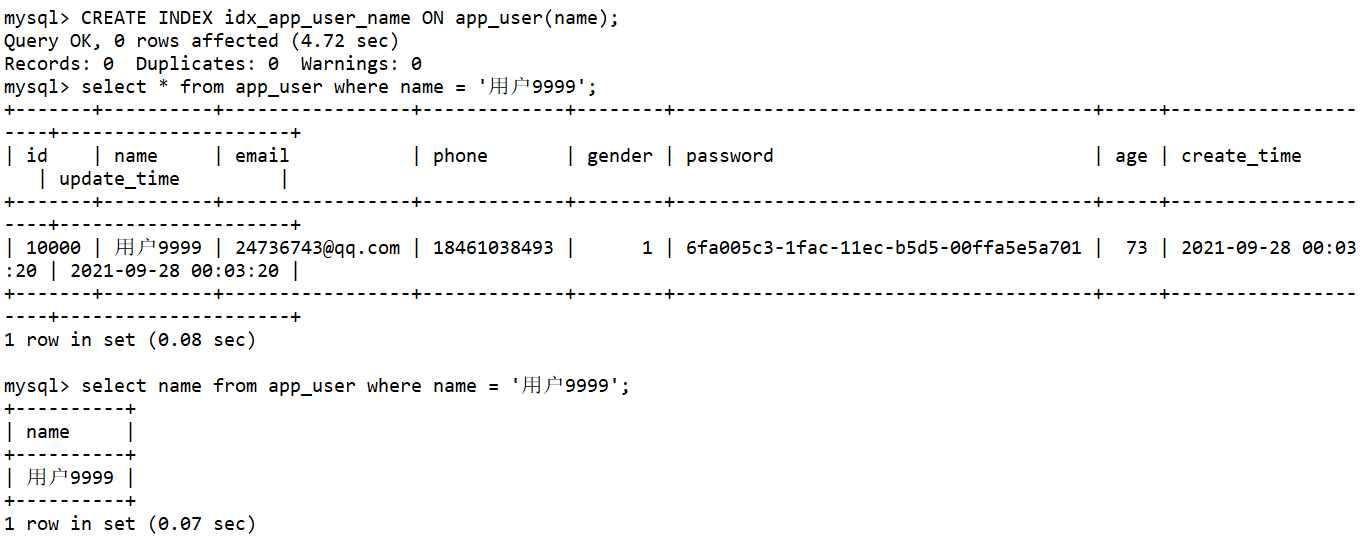
2.创常规建索引
--在name字段上创建index索引
CREATE INDEX idx_app_user_name ON app_user(name);
--测试
select * from app_user where name = '用户9999'; -- 查看耗时:大约在0.05~0.08s

若有收获,就点个赞吧
0 人点赞
