- 1,讲一下java中的集合?
- 3、讲一下ArrayList 与 LinkedList、HashSet 与 TreeSet、HashMap与HashTable与ConcurrentHashMap的区别?
- 4,如何决定使用HashMap还是TreeMap?
- 5,说一下HashMap的实现原理?
- 6,说一下HashSet的实现原理?
- 7,ArrayList和Vectot的区别是什么?
- 8,Array和Arraylist有何区别?
- 9,Queue中poll和remove有什么区别?
- 10,那些集合类是线程安全的?
- 11,迭代器Iterator是什么?
- 12,iteration怎么使用?有什么特点?
- 13,iteration和listiterator有什么区别?
- 14,怎么确保一个元素集合不能被修改?
- 15、TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
- 16,常见数据结构
- 17、常见算法
- 18.说一下查找二叉树的理解?AVL树(平衡树),红黑树的特点
- 19、说一下B树和B+树的区别
- 20、说一下数据结构的分类
- ">
- 21、说一下你理解的排序算法
- 22、说一下你理解的查找算法
- 23、.HASH算法的原理(Hahs表)
- 24. Hash冲突的解决方案
- 25、HashMap底层用到了那些数据结构,HashMap扩容机制?
- 26、为什么要用到链表结构?
- 27、为什么要用到红黑树?
- 28.链表和红黑树在什么情况下转换的?
- 29、HashMap在什么情况下扩容?HashMap如何扩容的?
- 30.HashMap是如何Put一个元素的?
- 31.HashMap是如何Get一个元素的?
- 32.什么是Hash冲突
- 33、HashMap是如何解决Hash冲突的?
- 34、手写一个冒泡排序(代码截图加上注释)
- 35、手写一个二分查找(代码截图加上注释)
- 36、ConcurrentHashMap原理?
- 37、说一下ES用到了什么数据结构?


1,讲一下java中的集合?
java中的集合分为value,key-value(ConllectionMap)两种。存储值分为List和Set
List:是有序的,可以重复的,线程不安全。
Set:是无序的,不可重复的线程不安全的。根据equals和hashcode判断,也就是如果,一个对象要存储在Set中,必须重写equals和hashcode方法 存储key-value的为map
2,collection和conllections有什么区别?
conllection是一个集合接口,它提供了集合对象进行基本操作的通用接口方法,所有集合都是她的子类,比如list,set等。
conllections是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法:
3、讲一下ArrayList 与 LinkedList、HashSet 与 TreeSet、HashMap与HashTable与ConcurrentHashMap的区别?
ArrayList与LinkedList
相同点: 都是List接口的实现类都可存放任意多个数据都是线程不安全,都是有序(添加信息)
不同点:Arraylist底层是基于数组实现的,由于底层是基于数组实现数据具有索引,因此可以根据索引直接定位到数据,因此查询和修改较快,而添加和删除较慢
LinkedList底层基于双向链表实现 因为底层基于链表实现,不用去判断是否需要扩容或者数据的拷贝,此时添加,删除的速度较快,当查询,修改的时候需要遍历整个链表,速度相对较慢
HsahSet与TreeSet区别?
相同点:都是Set接口实现类,都可以存放任意类型任意多个数据都是无序不可重复的,都是线程不安全的
不同点:HashSet LinkedHashSet能够存储任意类型人多个数据,数据报考null
HashSet底层基于HashMap实现 添加数据是主要通过hashCode和equals方法去重(是根据hashcode与qeuals方法共同决定的,先去用hashcode判断是否相等,然后在用equals方法进行比较是否相同,如果hashcode方法判断不相等时,就不会调用equals方法进行比较
Treeset底层基于TreeMap实现,添加数据时,主要通过自然排序或者制定排序去重
HashMap与HashTable与ConcurrentHashMap区别?
相同点:都是map接口的实现类,都是以键值对形式存储key不能重复value可重复
遍历方式两种 获取keyset 或者entryset
不同点:HashMap(jdk1.7及其以前底层基于数组+链表实现,jdk1.8以后,底层基于数组+链表+红黑树实现) 线程不安全,可以使用null作为建或者值 效率最高
hashtable 同步方法保证线程安全,不可以使用null作为键或者值 效率最低
concurrentHashMap:同步代码块保证线程安全,效率较高,不可以使用null作为键或者值
如果想线程安全又想效率高?
通过吧整个map分为N个segment(类似HashTable),可以提供相同的线程安全,但是效率提升n,默认提升16倍。
4,如何决定使用HashMap还是TreeMap?
对于在Map中插入,删除,定位一个元素这类操作,HashMap是最好的选择,因为相对而言Hashmap的插入会更快,但如果你要对一个key集合进行有序的遍历,那TreeMap是更好的选择
5,说一下HashMap的实现原理?
HashMap基于hash算法实现的,我们通过put(k,y)存储。当传入key时,HashMap会根据key 计算hsahz值,根据hash值将value保存在bucket里。当计算出相同的hash值相同是,我们成为hash冲突,通过链表和红黑树储存hsah值,hash冲突的个数比较少时,使用链表
6,说一下HashSet的实现原理?
HashSet是基于hashMap实现的,HashSet底层使用HashMap来保存所有元素,因此hashSet的实现比较简单,相关hashset的操作,基本上都是直接调用底层hashmap的相关方法来完成,hashset不允许重复的值。
7,ArrayList和Vectot的区别是什么?
线程安全:vector使用了Synchronized来实现线程同步,是线程安全的,而ArrayList是非线程安全的。
性能:arrayList在性能方面要优于vector
扩容:ArrayList和vector都会根据实际的需要动态的调整容量,只不过在vector扩容每次会增加1倍,而ArrayList只会增加50%;
8,Array和Arraylist有何区别?
Array可以存储基本数据类型和对象,ArrayList只能存储对象。
Array是指定固定大小的,而ArrayList大小是自动扩展的。
Array内置方法没有ArrayList多,比如 addAll等等。
9,Queue中poll和remove有什么区别?
相同点:都是放回第一个元素,并在队列中删除返回的对象。
不同点:如果没有元素poll会返回null,而remove会直接抛出NoSuchElementException异常
10,那些集合类是线程安全的?
Vector,Hashtable,Stack都是线程安全的,而像hashMap则是非线程安全的,不过在jdk1.5之后,随着java util cincurrent并发包的出现,它们也有了自己对应的线程安全类,比如hashMap对应的线程安全类就是ConcurrentHashMap
11,迭代器Iterator是什么?
Iterator接口提供遍历任何collection的接口。我们可以从一个collection中使用迭代器方法来获取迭代器实例。迭代器取代了java集合框架中的enumerate,迭代器允许调用者在迭代器过程中移出元素。
12,iteration怎么使用?有什么特点?
iteration的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出ConcurrentModificationException异常。
13,iteration和listiterator有什么区别?
lterator可以遍历set和list集合,而listiterator只能遍历list.
iterator只能单向比遍历,而Listiterator可以双向遍历
listiterator从lterator接口继承,然后添加了一些额外的功能,比容添加一个元素,替换一个元素,获取前面或后面元素的索引位置。
14,怎么确保一个元素集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常
15、TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
TreeSet要求存放的对象所属的类必须实现Comparable接口,该接口提供了比较元素的compareTo()方法,当插入元素时会回调该方法比较元素的大小。
TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。
Collections工具类的sort方法有两种重载的形式,
第一种要求传入的待排序容器中存放的对象比较实现Comparable接口以实现元素的比较;
第二种不强制性的要求容器中的元素必须可比较,但是要求传入第二个参数,参数是Comparator接口的子类型(需要重写compare方法实现元素的比较),相当于一个临时定义的排序规则,其实就是通过接口注入比较元素大小的算法,也是对回调模式的应用(Java中对函数式编程的支持)
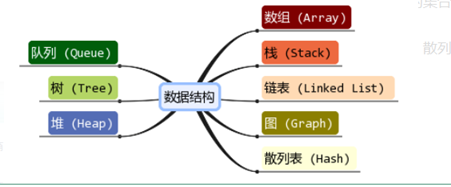
16,常见数据结构
2.1 什么是数据结构
存数据及数据之间关系集合。
2.2 逻辑结构
1)集合
2)线性结构
3)树状结构
4)图形结构
2.3 物理结构
1)顺序存储 - java用数组
2)链式存储
3)索引存储
4)hash存储
2.4 常用数据结构
1)集合 HashSet
2)线性结构
数组
线性表-顺序表(ArrayList)链表(LinkedList)
栈:FILO 顺序栈 链栈
队列:FIFO 顺序队列 链式队列
串:定长String 堆StringBuilder StringBuffer
3)树状结构
二叉树:二叉排序树。。。红黑树。。。
多叉树:B树 B-树 b+树(innodb)。。。。
17、常见算法
3.1 什么是算法 解决问题步骤有限集合。 在java中就是方法
3.2 评价算法是否高效
时间复杂度:时间频度,从理论上看它执行多少语句 o(1) o(n) o(2n) o(N平方)
空间复杂度:是否有额外空间
空间换取时间
3.3 常见算法
hash(散列)算法
递归
递归:自己调用自己,有出口
递归优化-数据库查询
排序:
java Arrays.sort Collections.sort Compartor(小于返回负数,大于返回正数)
还要很多排序算法 冒泡。。。
查找
二分查找:排序数据
18.说一下查找二叉树的理解?AVL树(平衡树),红黑树的特点
理解:每个节点只有两个分叉,左边分叉的数据比节点数据小,右边的数据更大。
AVL树(平衡树):左右两边的高度差不能相差一,查询效率高()
红黑树:也是一个平衡树,增删改快,父节点为黑色,下面每层就是黑色红色交替,最底下节点为红色 会自动在拼接两个黑色的节点为null
19、说一下B树和B+树的区别
B树的节点存储数据,B+树存储数据的地址(一般只有两层)
B+树相对于B树的优势
n 每个节点存储更多的KEY,树的高度更低,时间复杂度越小,查询越快
n 数据在叶子节点,每次查询都要查询到叶子节点,查询速度比较稳定
n 叶子节点构成构成了链表结构,方便区间查询和排序
Mysql为什么使用B+树:
以最小的IO找到更多的记录数,如果是B树,由于每个节点要存储Key和Value(数据) ,那么每个节点能存储的Key是很少的 ,而B+树每个节点只存储Key,它可以存储更多的Key, 每个节点存储的Key越多,路数越多,节点就越少,需要耗时的IO就越少,查找性能就越高 , 且B+树的叶子节点是有序的,形成链表,方便区间查询和排序
20、说一下数据结构的分类
21、说一下你理解的排序算法

22、说一下你理解的查找算法
l 顺序查找 无序数据查找,从前往后查找
l 二分查找 有序数据中进行查找
l 插值查找
l 斐波那契查找
l 树表查找
l 分块查找
l 哈希查找
23、.HASH算法的原理(Hahs表)
24. Hash冲突的解决方案
n 拉链法/链地址法 :把Hash碰撞的元素指向一个链表
n 开放寻址法:当 p=h(key)出现冲突,就以p为基础产生另一个Hash,如:p1=h(p),直到不冲突了把元素放在该位置
n 再散列法:准备若干个hash函数,如果使用第一个hash函数发生了冲突,就使用第二个hash函数,第二个也冲突,使用第三个
n 建立公共溢出区:把Hash表分为基本表和溢出表,把和基本表冲突的元素移到溢出表
25、HashMap底层用到了那些数据结构,HashMap扩容机制?
1.用到了数组,链表,红黑树结构 。
HashMap扩容机制
1.数组长度是16,每个元素都是key-value结构,元素存储到%75(0.75负载因子)进行 2倍扩容。
2.存储元素的算法是 hash(key) % 16 根据key进行hash计算得到的值来对数组长度16 取模,余数作为元素在数组中的存储索引位置。
3链表为了解决Hash冲突 , 不同的key进行 hash计算可能hash值一样,那么技术出来的存储索引位置也一样,这叫hash冲突,HashMap使用链表的方式来解决Hash冲突,就是在当前索引位置的元素上向下拖一个链表。
4.红黑树是为了提高查询速度了,因为链表过长,查询速度会很慢,红黑树能提高查询速度 ,当链表长度达到 8 编程 红黑树,当链表长度小于 6 编程链表。
26、为什么要用到链表结构?
链表为了解决Hash冲突 , 不同的key进行 hash计算可能hash值一样,那么技术出来的存储索引位置也一样,这叫hash冲突,HashMap使用链表的方式来解决Hash冲突,就是在当前索引位置的元素上向下拖一个链表。
27、为什么要用到红黑树?
红黑树是为了提高查询速度了,因为链表过长,查询速度会很慢,红黑树能提高查询速度 ,当链表长度达到 8 编程 红黑树,当链表长度小于 6 编程链表。
28.链表和红黑树在什么情况下转换的?
当链表长度达到 8 编程 转化为红黑树,当链表长度 小于 6 转化为编程链表。
29、HashMap在什么情况下扩容?HashMap如何扩容的?
元素存储到%75(0.75负载因子)进行 2倍扩容,位运算进行左移位。
30.HashMap是如何Put一个元素的?
HashMap 基于 Hash 算法实现的,我们通过put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据存储元素的算法是 hash值(key) % 16 根据key进行hash计算得到的值来对数组长度16 取模,余数作为元素在数组中的存储索引位置。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。
31.HashMap是如何Get一个元素的?
32.什么是Hash冲突
Hash冲突是存储两个不同的值而计算出了相同的Hash值,即两个数据在Hash表中计算出同一个下标,这种情况叫Hash冲突
33、HashMap是如何解决Hash冲突的?
34、手写一个冒泡排序(代码截图加上注释)
public static void main(String[] args) {
int x[]={7,345,456,2,36,36,798,3}; //定义一个要排序的数组
int test=0; //定义一个虚拟的数字
for (int i = 0; i < x.length-1; i++) {//每次都要比较完一个数直至到右边,所以-1
for (int j = 0; j < x.length-1-i; j++) {//每次都要比较完一轮数据,所以-i
if (x[j]>x[j+1]) { //如果在比较的时候这个数比后一个的数更大
test=x[j]; //定义的虚拟数给它赋值为x[j]
x[j]=x[j+1]; //给x数组的x[j]这个位置赋值为后一个更小的数
x[j+1]=test; // 给x数组的x[j+1]这个位置赋值为前一个更大的数
}
}
}
for (int i = 0; i < x.length; i++) {
System.out.print(x[i]+”,”); //打印出x[i]数组
}
}
35、手写一个二分查找(代码截图加上注释)
public class SearchElement {
public static void main(String[] args) {
//System.out.println(“hello”);
int[] array = {1,2,3,4,5,6,7,8};
int index = searchElement(array,0,7,100);
int index2 = searchElement2(array,6);
System.out.println(index2);
}
//二分查找 递归
public static int searchElement(int array[], int low, int high, int target) {
if (low > high) return -1;
int mid = (low + high) / 2;
if (array[mid] < target)
return searchElement(array, mid + 1, high, target);
if (array[mid]> target)
return searchElement(array,low,mid-1,target);
return mid;
}
//二分查找 不用递归
public static int searchElement2(int[] array,int target){
int low = 0;
int high = array.length-1;
while(low<=high){
int mid = (low+high)/2;
if(array[mid] > target){
high = mid-1;
}else if (array[mid]<target){
low = mid + 1;
}else{
return mid;
}
}
return -1;
}
}
36、ConcurrentHashMap原理?
HashMap 是线程不安全的,效率高;HashTable 是线程安全的,效率低。
ConcurrentHashMap 可以做到既是线程安全的,同时也可以有很高的效率,得益于使用了分段锁。
实现原理
JDK 1.7:
ConcurrentHashMap 是通过数组 + 链表实现,由 Segment 数组和 Segment 元素里对应多个 HashEntry 组成
value 和链表都是volatile 修饰,保证可见性
ConcurrentHashMap 采用了分段锁技术,分段指的就是 Segment 数组,其中 Segment 继承于 ReentrantLock
理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment
put 方法的逻辑较复杂:
尝试加锁,加锁失败 scanAndLockForPut 方法自旋,超过 MAX_SCAN_RETRIES 次数,改为阻塞锁获取
将当前 Segment 中的 table 通过 key 的 hashcode 定位到HashEntry
遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value
不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容
最后释放所获取当前 Segment 的锁
get 方法较简单:
将 key 通过 hash 之后定位到具体的 Segment,再通过一次 hash 定位到具体的元素上
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了其内存可见性
JDK 1.8:
抛弃了原有的 Segment 分段锁,采用了CAS + synchronized 来保证并发安全性
HashEntry 改为Node,作用相同
val next 都用了volatile 修饰
put 方法逻辑:
根据 key 计算出 hash 值
判断是否需要进行初始化
根据 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋
如果当前位置的 hashcode == MOVED == -1,则需要扩容
如果都不满足,则利用 synchronized 锁写入数据
如果数量大于 TREEIFY_THRESHOLD 则转换为红黑树
37、说一下ES用到了什么数据结构?


若有收获,就点个赞吧
0 人点赞
