1,谈谈你对ElasticSearch的理解?
是基于Lucene全文检索引擎的开源性搜索引擎,通过简单的RESTFUL api来隐藏Lucene的复杂性,从而让全文检索变得简单;
es即为了解决原生的lucene使用的不足,优化lucene的调用方式,并实现了高可用的分布式集群的搜索方案,
es是用javv开发的,但它却不是只支持java语言,因为它支持restful方式调用。那理论上他是支持所有开发语言的,除此之外,如果你不想使用restful方式电泳es服务器,那es还提供了各种语言的api供我们使用;
2,es的优点
分布式存储
方便集群
性能高:实时搜索;
存储数量打处理PB级别的数据
基于restful api使用简单
各种语言都支持
使用它简单上手容易(因为使用restful风格):屏蔽了lucene的复杂性
3,es相关概念
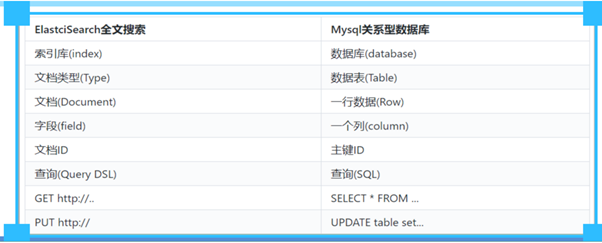
4,elasticSearch_CRUD
1,添加
put/索引库/类型/id {json数据}
2,获取
GET/索引库/类型/ID
3,删除
DELETE/索引库/类型/id
4,修改
全量
PUT/索引库/类型/id {json数据}
增量修改
post/索引库/类型/id/_update {doc:{json数据}}
5,es全文搜索的两个核心
6,es全文搜索创建索引大致原理
1,分词
2,词态转换,大小写装换
3,排序(自然顺序)
4,合并单词(id倒排)
5,形成倒排索引文档
6,工作原理流程
首先我们会为原始数据创建索引库,对原始数据进行分词,语义合并 排序 词语合并 形成倒排索引 查询的时候对索引的关键词进行分词 然后将分词后的关键词到索引库中查找就可以定位到原始数据
倒排索引是什么?
传统的数据库我们检索是通过文章,逐个遍历找到对应的关键词的位置
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。
倒排索引的底层是基于fst(数据结构)
lucene从4+版本后开始大量使用的数据结构是fst.fst有两个优点:
空间占用小:通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
查询速度快:0(len(str))的查询时间复杂度;
7,es全文搜索那些要建索引,要分词,不分词,那些要存储到数据区?
存储数据到elasticSearch时候需要创建索引库,有中文的时候就需要用插件分词器ik 进行分词;
8,es查询条件?
match:标准查询(分词)
match_all
term:单词查询(不分词,等值查询)
range:范围查询
prefix:前缀查询
bool:组合多个条件
wildcard:通配符查询
9,es使用的是query还是filter,两者之间有什么区别?
query查询过程:
1,比较查询条件:
这种查询方式适合全文检索类的查询。
filter查询过程
1,判断是否满足查询条件,如果不满足,会缓存查询过程(记录该文档不满足结果)
2,满足的话,就直接缓存结果。
这种方法会适合于精确匹配方式的查询
综上所述,filter快在两个方面:
1,对结果进行缓存;
2,避免计算文档相关性分值
当我们不关心搜索结果的评分或者不使用全文检索的时候,为了提高性能,注意使用filter
10,为什么不使用mysql查询,而要用ES呢?
在一个电商平台项目中,会有非常多的商品,如果使用以往的Mysql进行模糊查询,需要比较长的等待时间,对数据库压力比较大,es中使用倒排索引,查询效率非常高,可以减轻mysql压力,而且还能进行分词查询和高亮处理,mysql是做不到的。
不是所有的数据都会存在es中,像商品规格表这种不常修改,且不会去模糊查询的放到缓存中就好了。
11,lucene和es的区别
定义:
lucene是一个java信息检索程序库,一个jar包。您可以将其包含在项目中,并使用函数调用来参考其功能。
elasticsearch是基于json和lucene的分布式web服务。
关系:
es基于lucene构建,es利用lucene做实际的工作
es中的每一个分片都是一个分离的lucene实例
es在lucene基础上(即利用lucene的功能)提供了一个分布式的,基于json的restful api来更方便的使用lucene的功能
es提供其他支持功能,如线程池,队列,节点,集群监控api,数据监控api,集群管理等
12,Mysql数据如何同步到es中
mysql数据同步到es中,大致总结可以分为两种方案
方案一:监听mysql的binlog ,分析binlog将数据同步到es中。
优点:业务与es数据耦合度低,业务逻辑中不需要关系es数据的写入
缺点:binlog模式只能使用ROW模式,且引入了新的同步服务,增加了开发量以及维护成本,也增大了es同步的风险。
方案二:直接通过es的api将数据写入es集群中。
优点:简介明了,能够灵活的控制数据的写入;
缺点:与业务耦合严重,强依赖于业务系统的写入方式
考虑到订单系统 ES 服务的业务特殊性,对于订单数据的实时性较高,显然监听 Binlog 的方式相当于异步同步,有可能会产生较大的延时性。且方案 1 实质上跟方案 2 类似,但又引入了新的系统,维护成本也增高。所以订单中心 ES 采用了直接通过 ES API 写入订单数据的方式,该方式简洁灵活,能够很好的满足订单中心数据同步到 ES 的需求。
由于 ES 订单数据的同步采用的是在业务中写入的方式,当新建或更新文档发生异常时,如果重试势必会影响业务正常操作的响应时间。所以每次业务操作只更新一次 ES,如果发生错误或者异常,在数据库中插入一条补救任务,有定时工作任务队列会扫这些数据,以数据库订单数据为基准来再次更新 ES 数据。通过此种补偿机制,来保证 ES 数据与数据库订单数据的最终一致性。
13,在并发情况下,elasticsearch如何保证读写一致?
1,可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
2另外对写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才运行写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建;
3,对于读操作,可以设置replication为sync,这使得操作在主分片和副本分片都完成才会返回;如果设置replication为async时,也可以通过设置搜索请求参数preference为primary来查询主分片,确保文档是最新版本。
14,es的算法优化
这个问题问题的有点问题,使用elasticsearch不需要我们直接去优化算法,所有的优化都是通过配置完成。
1分片的数量不少越多越好,因为查询结果是所有分片数据组装起来的,分片越多,消耗的IO越大,最好的是分片数等于节点数乘以3,比如有3个节点,那么索引的分片就创建9个。
2默认情况下,一个分片对应着一个副本,副本可以起到负载均衡的效果,因为分片和副本都可以处理搜索的请求,所以适当的增加副本的数量,可以大大的提高系统的吞吐量,不过副本也会增加系统的压力,还会增加磁盘消耗,所以一般来说,设置2-3个副本就可以了。
3设置线程池大小
4尽量减少不需要的字段,这样可以节省一个文档所消耗的空间,在相同数据文档量的前提下,字段越少,搜索的速度越快
5锁定内存,不让JVM写入swapping,避免降低ES的性能,对应的配置为bootstrap.mlockall: true
6定时处理缓存,GET http://127.0.0.1:9200/*/_cache/clear
定时合并优化资源,GET http://127.0.0.1:9200/*/_optimize

若有收获,就点个赞吧
0 人点赞
