技术图

分布式系统的指标
性能(Performance)
包括吞吐量(Throughput)、响应时间(Response Time)和完成时间 (Turnaround Time)。
吞吐量
QPS(Queries Per Second)、TPS(Transactions Per Second)和 BPS(Bits Per Second)。
QPS,即查询数每秒,用于衡量一个系统每秒处理的查询数。这个指标通常用于读操 作,越高说明对读操作的支持越好。所以,我们在设计一个分布式系统的时候,如果应用 主要是读操作,那么需要重点考虑如何提高 QPS,来支持高频的读操作。
TPS,即事务数每秒,用于衡量一个系统每秒处理的事务数。这个指标通常对应于写操 作,越高说明对写操作的支持越好。我们在设计一个分布式系统的时候,如果应用主要是 写操作,那么需要重点考虑如何提高 TPS,来支持高频写操作。
BPS,即比特数每秒,用于衡量一个系统每秒处理的数据量。对于一些网络系统、数据管 理系统,我们不能简单地按照请求数或事务数来衡量其性能。因为请求与请求、事务与事 务之间也存在着很大的差异,比方说,有的事务大需要写入更多的数据。那么在这种情况 下,BPS 更能客观地反应系统的吞吐量。
响应时间
系统响应一个请求或输入需要花费的时间。响应时间直接影响到用户体 验,对于时延敏感的业务非常重要。比如用户搜索导航,特别是用户边开车边搜索的时候, 如果响应时间很长,就会直接导致用户走错路。
完成时间
系统真正完成一个请求或处理需要花费的时间。任务并行(也叫作任务分 布式)模式出现的其中一个目的,就是缩短整个任务的完成时间。特别是需要计算海量数据 或处理大规模任务时,用户对完成时间的感受非常明显。
资源占用(Resource Usage)
资源占用指的是,一个系统提供正常能力需要占用的硬件资源,比如 CPU、内存、硬盘。
可用性(Availability)
系统的可用性可以用系统停止服务的时间与总的时间之比衡量。假设一个网站总的运行时间 是 24 小时,在 24 小时内,如果网站故障导致不可用的时间是 4 个小时,那么系统的可用 性就是 4/24=0.167,也就是 0.167 的比例不可用,或者说 0.833 的比例可用。
除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网 站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
可扩展性(Scalability)
可扩展性,指的是分布式系统通过扩展集群机器规模提高系统性能 (吞吐、响应时间、 完成时间)、存储容量、计算能力的特性,是分布式系统的特有性质。
分布式系统的设计初衷,就是利用集群多机的能力处理单机无法解决的问题。然而,完成某 一具体任务所需要的机器数目,即集群规模,取决于单个机器的性能和任务的要求。
当任务的需求随着具体业务不断提高时,除了升级系统的性能做垂直 / 纵向扩展外,另一 个做法就是通过增加机器的方式去水平 / 横向扩展系统规模。
这里垂直 / 纵向扩展指的是,增加单机的硬件能力,比如 CPU 增强、内存增大等;水平 / 横向扩展指的就是,增加计算机数量。好的分布式系统总在追求“线性扩展性”,也就是说 系统的某一指标可以随着集群中的机器数量呈线性增长。
一个系统的案例
一个系统会遇见的问题
相同的应用部署到不同的服务器上,当大量用户请求过来时,如何能比较均衡地转发到不 同的应用服务器上呢?解决这个问题的方法是设计一个负载均衡器,我会在”分布式高可 靠“模块与你讲述负载均衡的相关原理。
当请求量较大时,对数据库的频繁读写操作,使得数据库的 IO 访问成为瓶颈。解决这个 问题的方式是读写分离,读数据库只接收读请求,写数据库只接收写请求,当然读写数据 库之间要进行数据同步,以保证数据一致性。
当有些数据成为热点数据时,会导致数据库访问频繁,压力增大。解决这个问题的方法是 引入缓存机制,将热点数据加载到缓存中,一方面可以减轻数据库的压力,另一方面也可 以提升查询效率。
单机模式
单机模式是指,所有应用程序和数据均部署在一台电脑或服务器上,由一台计算机完成 所有的处理。
性能受限、存在单点失效问题。
数据并行或数据分布式
采用消息共享模式使用多台计算机并行运行或执行多项任务,核心原理是每 台计算机上执行相同的程序,将数据进行拆分放到不同的计算机上进行计算。
第一步,将应用与数据分离,分别部署到不同的服务器上: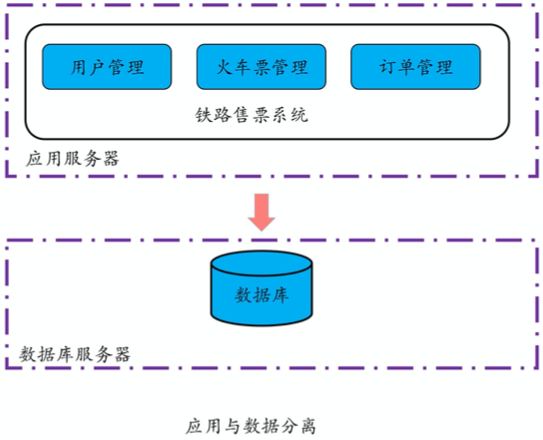
第二步,对数据进行拆分,比如把同一类型的数据拆分到两个甚至更多的数据库中
数据并行模式的主要问题是:对提升单个任务的执行性能及降低时延无效。
任务并行或任务分布式
任务并行指的是,将单个复杂的任务拆分为多个子任务,从而使得多个子任务可以在不同的 计算机上并行执行。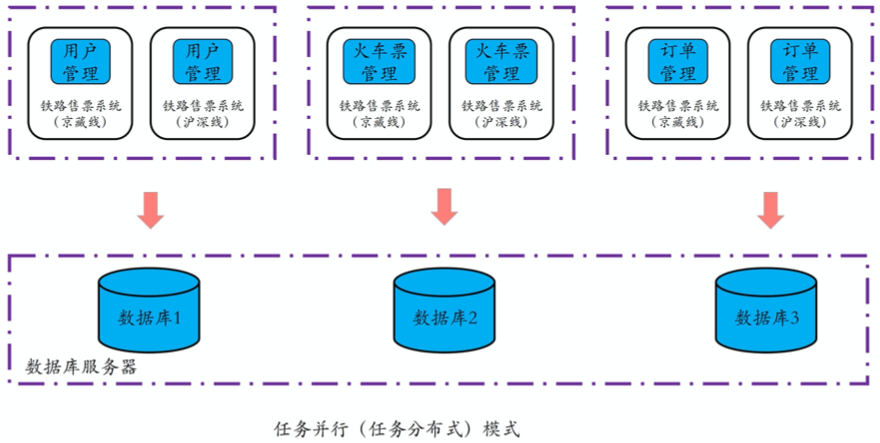
总结
单机模式指的是,所有业务和数据均部署到同一台机器上。这种模式的好处是功能、代码和 数据集中,便于维护、管理和执行,但计算效率是瓶颈。也就是说单机模式性能受限,也存 在单点失效的问题。
数据并行(也叫作数据分布式)模式指的是,对数据进行拆分,利用多台计算机并行执行多 个相同任务,通过在相同的时间内完成多个相同任务,从而缩短所有任务的总体执行时间, 但对提升单个任务的执行性能及降低时延无效。
任务并行(也叫作任务分布式)模式指的是,单任务拆分成多个子任务,多个子任务并行执 行,只要一个复杂任务中的任意子任务的执行时间变短了,那么这个业务的整体执行时间也 就变短了。该模式在提高性能、扩展性、可维护性等的同时,也带来了设计上的复杂性问 题,比如复杂任务的拆分。
到底是采用数据并行还 是任务并行呢?一个简单的原则就是:任务执行时间短,数据规模大、类型相同且无依赖, 则可采用数据并行;如果任务复杂、执行时间长,且任务可拆分为多个子任务,则考虑任务 并行。

若有收获,就点个赞吧
0 人点赞
