分布式选举算法-ZAB 算法
概述:
ZAB(ZooKeeper Atomic Broadcast)选举算法是为 ZooKeeper 实现分布式协调功能而设计的。相较于 Raft 算法的投票机制,ZAB 算法增加了通过节点 ID 和数据 ID 作为参考进行选主,节点 ID 和数据 ID 越大,表示数据越新,优先成为主。相比较于Raft算法,ZAB算法尽可以保证数据的最新性。所以,ZAB 算法可以说是对 Raft 算法的改进。
三个角色:
- Leader,主节点;
- Follower,跟随者节点;
-
四种状态:
Looking 状态,即选举状态。当节点处于该状态时,它会认为当前集群中没有 Leader, 因此自己进入选举状态。
- Leading 状态,即领导者状态,表示已经选出主,且当前节点为 Leader。
- Following 状态,即跟随者状态,集群中已经选出主后,其他非主节点状态更新为,Following,表示对Leader 的追随。
- Observing 状态,即观察者状态,表示当前节点为 Observer,持观望态度,没有投票权和选举权。
选举流程概述
投票过程中,每个节点都有一个唯一的三元组 (server_id, server_zxID, epoch),其中 server_id 表示本节点的唯一 ID;server_zxID 表示本节点存放的数据 ID,数据 ID 越大表 示数据越新,选举权重越大;epoch 表示当前选取轮数,一般用逻辑时钟表示。
ZAB 选举算法的核心是“少数服从多数,**server_zxID** 大的节点优先成为主”,因此选举过程中通过
选票信息(epoch,vote_id, vote_zxID) 来表明投票给哪个节点,其中 vote_id 表示被投票节点的 ID, vote_zxID 表示被投票节点的服务器 zxID。
ZAB 算法选主的原则是:server_zxID 最大者 成为 Leader;若 server_zxID 相同,则 server_id 最大者成为 Leader。选举算法举例
第一步:当系统刚启动时,3 个服务器当前投票均为第一轮投票,即 epoch=1,且 zxID 均为 0。此时每个服务器都推选自己,并将选票信息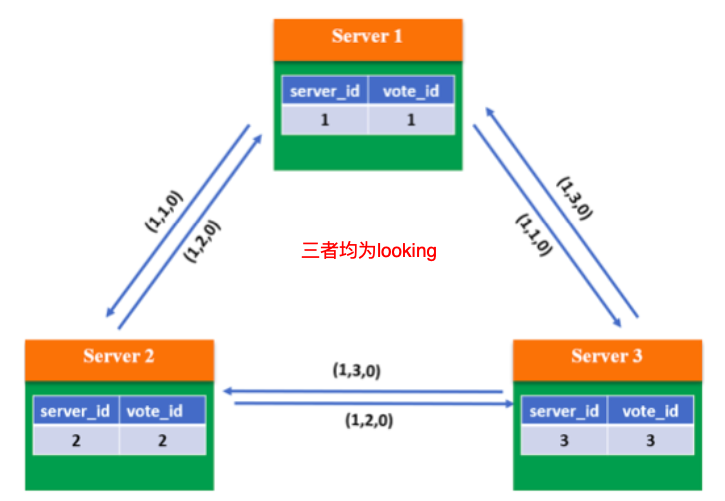
第二步:根据判断规则,由于 3 个 Server 的 epoch、zxID 都相同,因此比较 server_id, 较大者即为推选对象,因此 Server 1 和 Server 2 将 vote_id 改为 3,更新自己的投票箱并 重新广播自己的投票。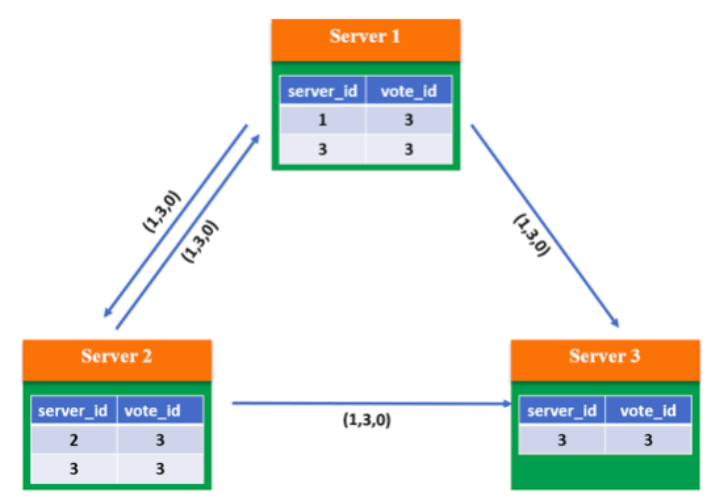
第三步:此时系统内所有服务器都推选了 Server 3,因此 Server 3 当选 Leader,处于 Leading 状态,向其他服务器发送心跳包并维护连接;Server1 和 Server2 处于 Following 状态。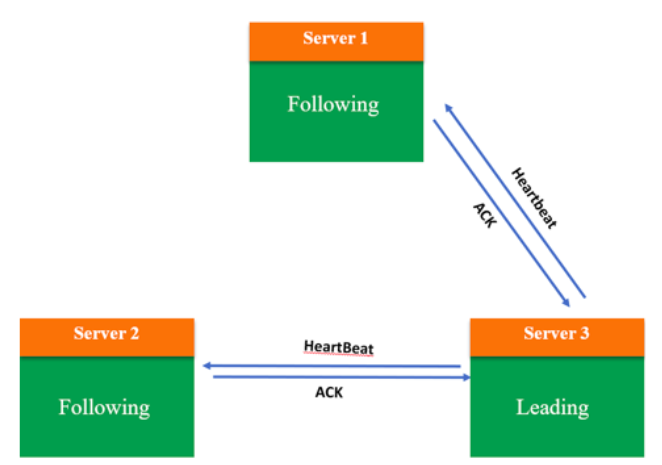

若有收获,就点个赞吧
0 人点赞
