1.相比于无返回值的dfs函数,一般推荐创建带返回值的dfs函数,因为更灵活,但是难度也比较大;
1.二叉树的最大深度
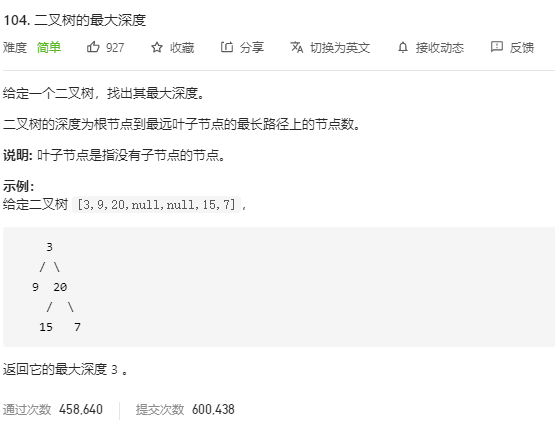
无返回值的dfs
public int maxDepth(TreeNode root) {dfs(root,1);return maxD;}public void dfs(TreeNode root,int depth){if(root==null){maxD=Math.max(maxD,depth-1);return;}dfs(root.left,depth++);dfs(root.right,depth++);}
注意点:
- root==null时depth已经加1,实际深度是depth-1
- 函数参数中不能使用自增或自减操作,切记
有返回值的dfs
class Solution {public int maxDepth(TreeNode root) {return dfs(root);}public int dfs(TreeNode root){if(root==null){return 0;}return Math.max(dfs(root.left),dfs(root.right))+1;}}
每个节点的深度等于左子树深度和右子树深度的最大值再加1
当节点为null时返回0,意味着叶子节点的深度为1,然后慢慢倒推
有返回值的dfs代码看起来更简洁
2.二叉树的最小深度
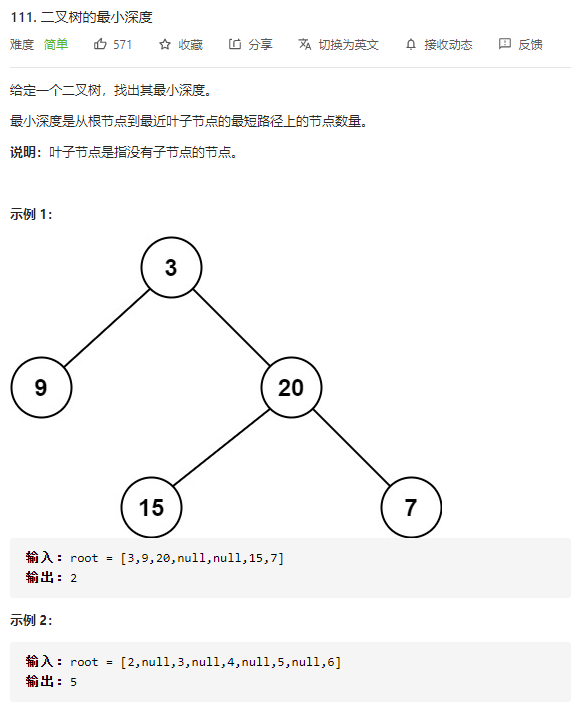
无返回值的dfs
class Solution {public int minD=100000;public int minDepth(TreeNode root) {if(root==null){return 0;}dfs(root,1);return minD;}public void dfs(TreeNode root,int depth){if(root==null){return ;}if(root.left==null && root.right==null){minD=Math.min(minD,depth);return;}dfs(root.left,depth+1);dfs(root.right,depth+1);}}
因为从根节点到叶子节点才算一个合格的路径,
所以要在递归的过程中要判断当前节点是否是叶子节点,如果是就可以更新minD
代码中还多了两处判断root是否为空的代码,整体结构比较零散
带返回值的dfs
class Solution {public int minDepth(TreeNode root) {if(root==null){return 0;}return dfs(root);}public int dfs(TreeNode root){if(root==null){return 1000000 ;}if(root.left==null && root.right==null){return 1;}return Math.min(dfs(root.left),dfs(root.right))+1;}}
同样多了两处判断root是否为空,整体结构比较零散
dfs中的root==null的return 1000000的目的是不考虑当前分支作为父节点的深度参考
我之前的思想:
class Solution {public int minDepth(TreeNode root) {return dfs(root);}public int dfs(TreeNode root){if(root==null){return 0;}int leftHeight=dfs(root.left);int rightHeight=dfs(root.right);if(root.left==null){return rightHeight+1;}else if(root.right==null){return leftHeight+1;}else{return Math.min(leftHeight,rightHeight)+1;}}}
上面的思想不是借助判断叶子节点;
而是左子树为空时就考虑右子树,同理,右子树为空时就考虑左子树;
3.路径总和
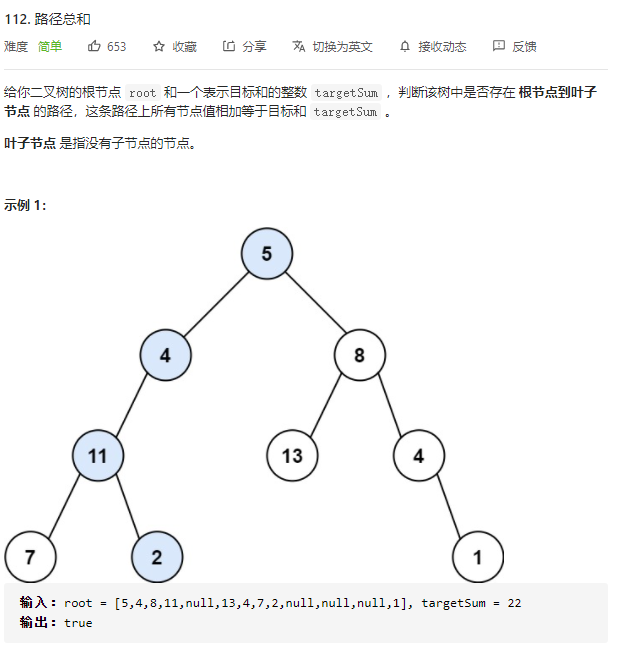
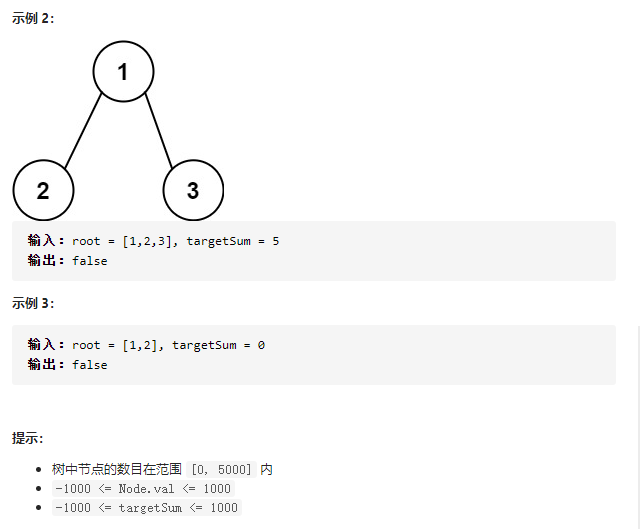
有返回值的dfs(这已经是复杂成了回溯了)
class Solution {ArrayList<Integer> list=new ArrayList();public boolean hasPathSum(TreeNode root, int targetSum) {if(root==null){return false;}list.add(root.val);return dfs(root,targetSum);}public boolean dfs(TreeNode root,int targetSum){// if(root==null){// return false;// }if(root.left==null && root.right==null){int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){return true;}else{return false;}}boolean b1=false;boolean b2=false;if(root.left!=null){list.add(root.left.val);b1=dfs(root.left,targetSum);list.remove(list.size()-1);}if(root.right!=null){list.add(root.right.val);b2=dfs(root.right,targetSum);list.remove(list.size()-1);}return b1 || b2;}}
思想:
使用回溯:
当前节点往下就两个选择,要么左子树,要么右子树;
如果左子树存在就将左节点放进列表中,递归后再取消;
如果右子树存在就将右节点放进列表中,递归后再取消;
注意每一次存和删的都是左子节点和右子节点,那当前节点呢?
这里需要知道二叉树中除了根节点,每个节点都是其他节点的左节点或者右节点;
所以这里只需要一开始就将根节点放进列表中就行,根节点全程只管进,不管出,符合题意;
dfs中不需要判断if(root==null),因为root=null进不了dfs
有返回值的dfs
class Solution {public boolean hasPathSum(TreeNode root, int targetSum) {return dfs(root,targetSum);}public boolean dfs(TreeNode root,int targetSum){if(root==null){return false;}if(root.left==null && root.right ==null){// if(targetSum==0){// return true;// }else{// return false;// }return (targetSum==root.val);}return dfs(root.left,targetSum-root.val) || dfs(root.right,targetSum-root.val);}}
这里用targetSum自动维护每一个节点的状态
注意当到达叶子节点的时候是判断targetSum与root.val的大小,而不是跟0的大小
另外注释的代码太垃圾了,一行的代码写成四行,面试官直接辞退
比较
什么时候非得用回溯?
回溯的话用于每条路径的中间的每个选择都需要获取,比如全排列问题,需要维护一个集合;
dfs的话只关注最终的值,只要最终值合适即可,不关注中间的选择,只需要维护一个变化的参数;
4.路径总和II
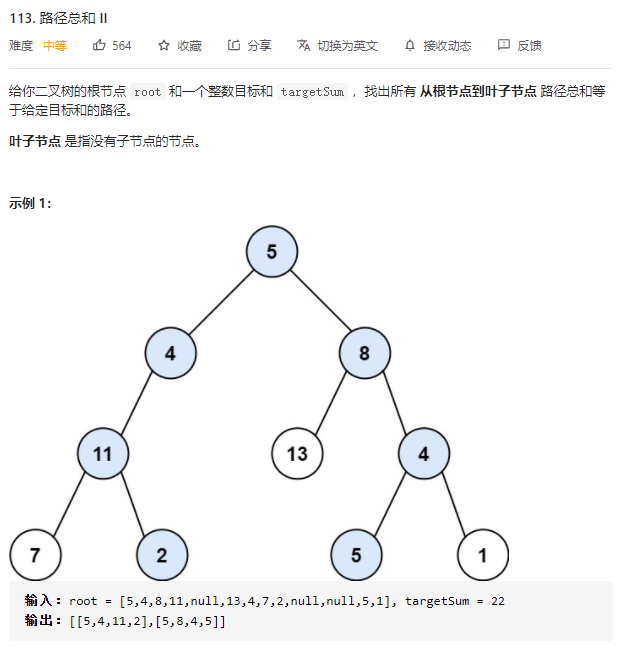
原来这才是我的回溯对应的题目
class Solution {List<List<Integer>> res=new ArrayList<List<Integer>>();ArrayList<Integer> list=new ArrayList();public List<List<Integer>> pathSum(TreeNode root, int targetSum) {if(root==null){return new ArrayList<List<Integer>>();//这里不能返回null}list.add(root.val);dfs(root,targetSum);return res;}public boolean dfs(TreeNode root,int targetSum){if(root.left==null && root.right==null){int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){res.add(new ArrayList<Integer>(list));//必须用new,因为list在回溯中仅一份return true;}else{return false;}}boolean b1=false;boolean b2=false;if(root.left!=null){list.add(root.left.val);b1=dfs(root.left,targetSum);list.remove(list.size()-1);}if(root.right!=null){list.add(root.right.val);b2=dfs(root.right,targetSum);list.remove(list.size()-1);}return b1 || b2;}}
官方题解:
class Solution {List<List<Integer>> ret = new LinkedList<List<Integer>>();Deque<Integer> path = new LinkedList<Integer>();public List<List<Integer>> pathSum(TreeNode root, int targetSum) {dfs(root, targetSum);return ret;}public void dfs(TreeNode root, int targetSum) {if (root == null) {return;}path.offerLast(root.val);targetSum -= root.val;if (root.left == null && root.right == null && targetSum == 0) {ret.add(new LinkedList<Integer>(path));}dfs(root.left, targetSum);dfs(root.right, targetSum);path.pollLast();}}
使用当前节点进行回溯,而不是用左子节点和右子节点
这个思想确实更好,代码更简洁
我尝试根据这个思想来写写
public boolean dfs(TreeNode root,int targetSum){if(root==null){return false;}if(root.left==null && root.right==null){int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){res.add(new ArrayList<Integer>(list));return true;}else{return false;}}list.add(root.val);boolean b1=dfs(root.left,targetSum);boolean b2=dfs(root.right,targetSum);list.remove(list.size()-1);return b1 || b2;}
上面代码有问题,输出的结果是空的
原因在于if中直接return会导致只有add没有remove
回溯有了add必然要有remove,而且要保证对应的两个都能执行,否则就回溯失败了
public void dfs(TreeNode root,int targetSum){if(root==null){return ;}list.add(root.val);//if判断中不能返回,因为返回的话,remove没法执行,这样只有add没有remove就不是回溯了if(root.left==null && root.right==null){int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){res.add(new ArrayList<Integer>(list));}}// list.add(root.val);dfs(root.left,targetSum);dfs(root.right,targetSum);list.remove(list.size()-1);}
public void dfs(TreeNode root,int targetSum){if(root==null){return ;}if(root.left==null && root.right==null){list.add(root.val);//多加判断1int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){res.add(new ArrayList<Integer>(list));}list.remove(list.size()-1);//多加判断2}list.add(root.val);//放在这里看着结构好看,上面的if判断就得多加两行dfs(root.left,targetSum);dfs(root.right,targetSum);list.remove(list.size()-1);}
public boolean dfs(TreeNode root,int targetSum){if(root==null){return false;}if(root.left==null && root.right==null){list.add(root.val);//添加当前节点,此时为叶子节点int sum=0;for(int i=0;i<list.size();i++){sum=sum+list.get(i);}if(sum==targetSum){res.add(new ArrayList<Integer>(list));list.remove(list.size()-1);//删除当前节点,此时为叶子节点return true;}else{list.remove(list.size()-1);//删除当前节点,此时为叶子节点return false;}}list.add(root.val);//添加当前节点,此时不是叶子节点boolean b1=dfs(root.left,targetSum);boolean b2=dfs(root.right,targetSum);list.remove(list.size()-1);return b1||b2;//带返回值的情况也可以!!!}
回溯方法的参数int targetSum这里是不变的
如果将其设定为可变的
那么就可以看在叶子结点处是否为0,而不需要遍历List集合来求和
这个可变的参数在很多dfs和回溯中用到(先给一个设定值,然后每次减去当前值)
比如括号生成等
5.路径总和III
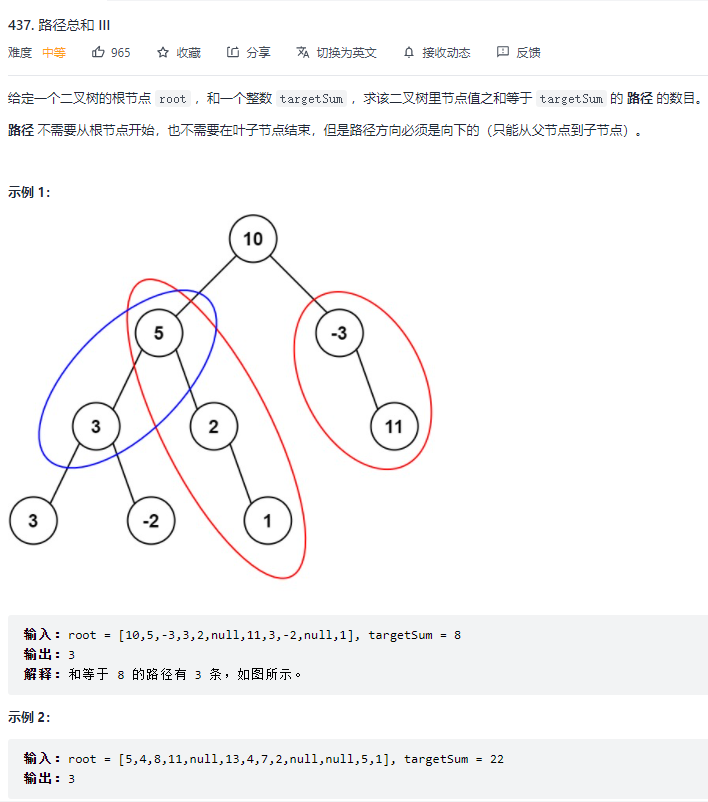
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/class Solution {public int pathSum(TreeNode root, int targetSum) {//key为前缀和,value为次数Map<Integer,Integer> map=new HashMap();//map.put(0,1)解释:比如根节点的val为n,targetSum也为n,此时根节点本身就是路径,但是按照下面的代码会将其设置为0,所以要加1;//不仅如此,当curSum第一次累加到target,本应该将key为0的value设置为1,但是按照res=res+map..的话,此时依旧为0map.put(0,1);return dfs(root,map,targetSum,0);}public int dfs(TreeNode root,Map<Integer,Integer> map,int target,int curSum){if(root==null){return 0;}int res=0;curSum=curSum+root.val;res=res+map.getOrDefault(curSum-target,0);map.put(curSum,map.getOrDefault(curSum,0)+1);// if(map.containsKey(curSum-target)){// res=res+map.get(curSum-target);// }res=res+dfs(root.left,map,target,curSum);res=res+dfs(root.right,map,target,curSum);map.put(curSum,map.get(curSum)-1);return res;}}

若有收获,就点个赞吧
0 人点赞
