- 1.组合两个表
- 2.第二高的薪水
- 3.第N高的薪水
- 4.分数排名
- 5.连续出现的数字
- 6.超过经理收入的员工
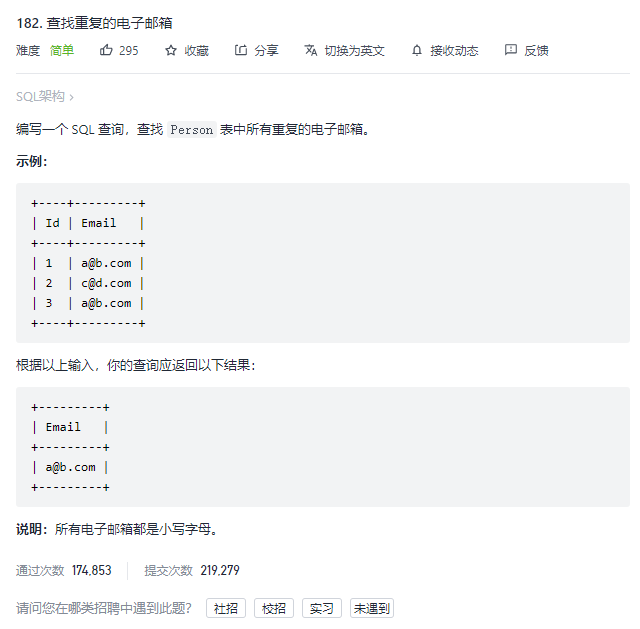
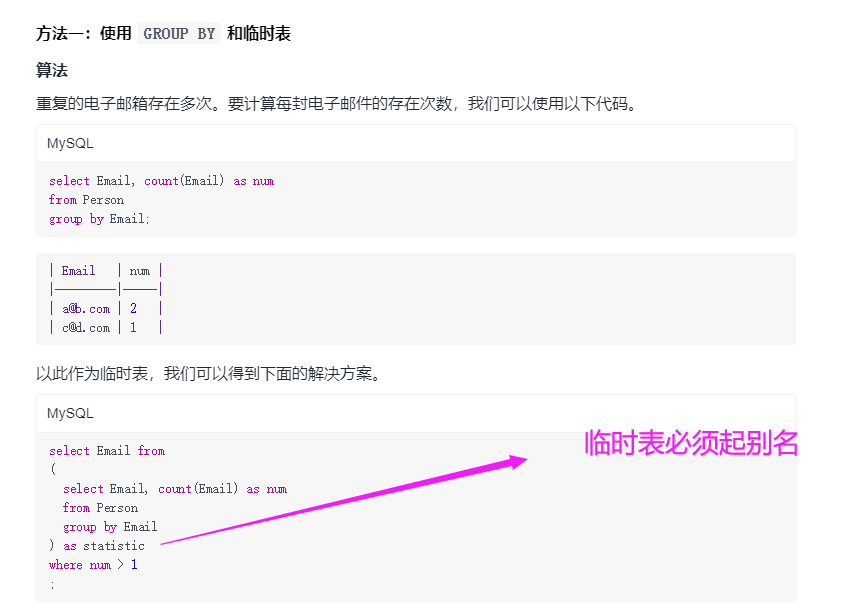
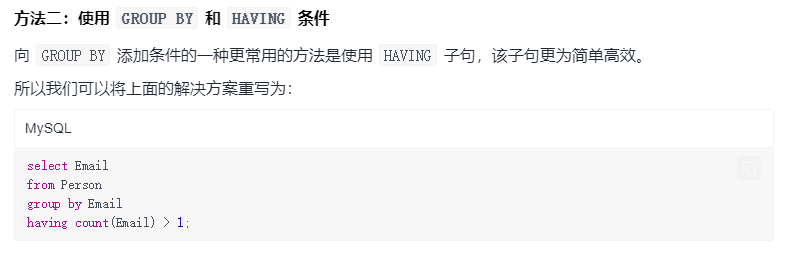
- 7.查找重复的电子邮箱
- 8.从不订购的客户
- 9.部门工资最高的员工
- 10.部分工资前三高的员工
- 使用group by如果没有聚合函数min,max之类的则只会在每个group中显示第一个
#按照DepartmentId之后求出前三个最大的salary显示出来怎么做?limit是配合group by的,不是配合order by,即limit限制的是group by的列
#group by是用来配合聚集函数的,如sum,avg,min,max,count,这些的结果都是单个值
# Select DepartmentId, salary from Employee group by DepartmentId order by salary desc limit 0,3 ;
select Department.Name asDepartment,e1.Name asEmployee,e1.salary from Employee as e1 , Department
where e1.DepartmentId=Department.Id
and 3>(select count(distinct e2.salary) from Employee as e2 where e2.salary>e1.salary and e1.DepartmentId=e2.DepartmentId) - 11.上升的温度
- Write your MySQL query statement below
#select w2.id as id from Weather w1,Weather w2 where w1.recordDate=w2.recordDate-1 and w1.Temperature - 12.行程与用户(困难)
- 13.换座位
1.组合两个表
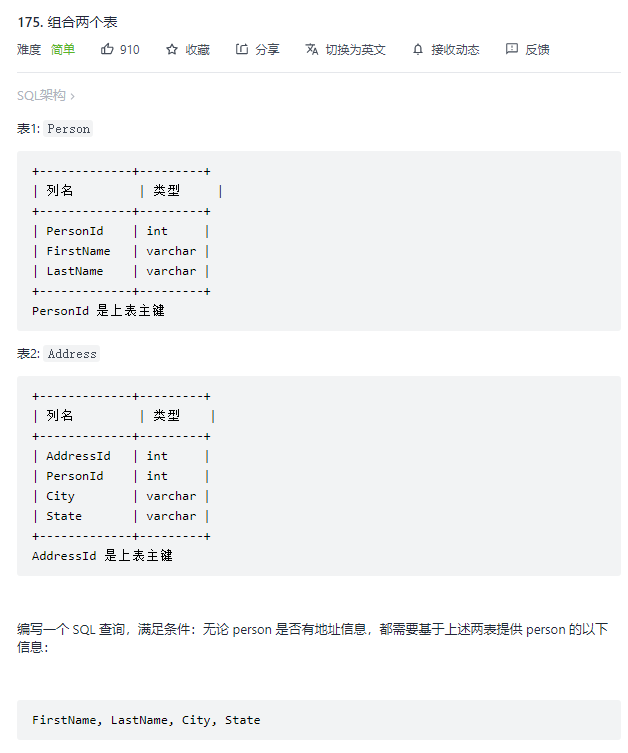
必然是要用联结查询,而且person没有地址也得显示,说明还得用外联结;
1.使用内联结的情况下
select FirstName,LastName,City,State from Person as p inner join Address as a on p.PersonId=a.PersonId;
输入:
{“headers”: {“Person”: [“PersonId”, “LastName”, “FirstName”], “Address”: [“AddressId”, “PersonId”, “City”, “State”]}, “rows”: {“Person”: [[1, “Wang”, “Allen”]], “Address”: [[1, 2, “New York City”, “New York”]]}}
输出:
{“headers”: [“FirstName”, “LastName”, “City”, “State”], “values”: []}
预期结果:
{“headers”: [“FirstName”, “LastName”, “City”, “State”], “values”: [[“Allen”, “Wang”, null, null]]}
2.使用外联结的情况下
select FirstName,LastName,City,State from Person as p left outer join Address as a on p.PersonId=a.PersonId;
输入:
{“headers”: {“Person”: [“PersonId”, “LastName”, “FirstName”], “Address”: [“AddressId”, “PersonId”, “City”, “State”]}, “rows”: {“Person”: [[1, “Wang”, “Allen”]], “Address”: [[1, 2, “New York City”, “New York”]]}}
输出:
{“headers”: [“FirstName”, “LastName”, “City”, “State”], “values”: [[“Allen”, “Wang”, null, null]]}
预期结果:
{“headers”: [“FirstName”, “LastName”, “City”, “State”], “values”: [[“Allen”, “Wang”, null, null]]}
解释:
在使用内联结时因为两张表中没有符合p.PersonId=a.PersonId的数据,因此没有数据[]
在使用左外联结时因为Person表中的用户数据并没有相应的地址,所以地址栏显示为null
2.第二高的薪水
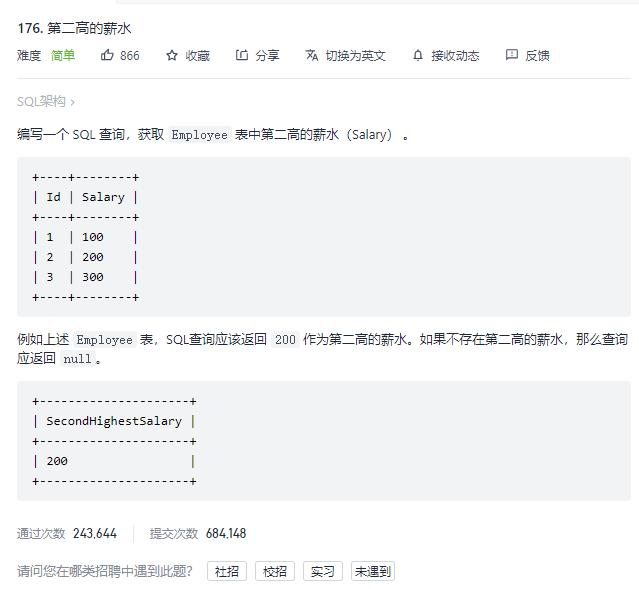
立马想到倒序排序后再用limit
select salary as SecondHighestSalary from Employee order by salary desc limit 1,1;
方法欠妥,因为如果有重复的话我们得去重,第二高的薪水要不同的薪水值;
因此加上distinct
select distinct salary as SecondHighestSalary from Employee order by salary desc limit 1,1;
然后还是有问题
当只有一条数据时我们无法找到第二高的薪水,因为返回的是[]
而题目要求此时应该返回null,这里使用子查询
select (select distinct salary from Employee order by salary desc limit 1,1) as SecondHighestSalary;
这里关于null的用法硬记吧
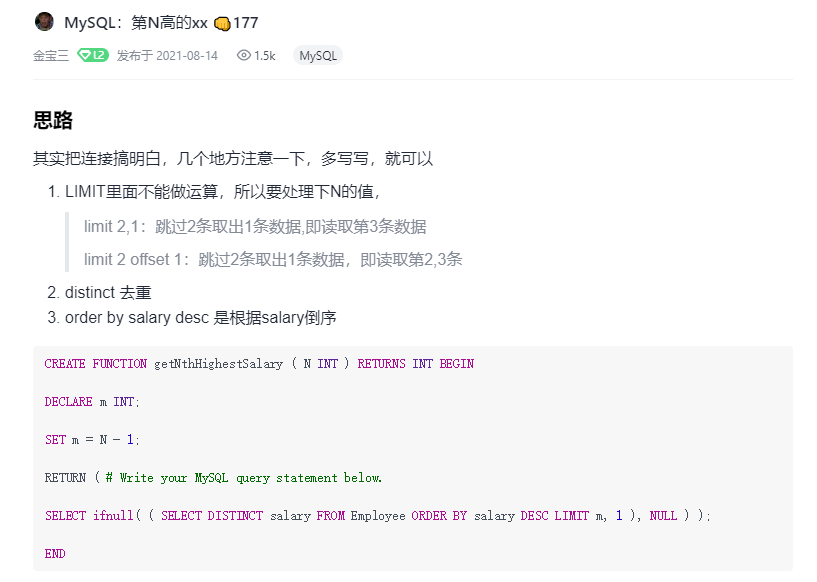
3.第N高的薪水
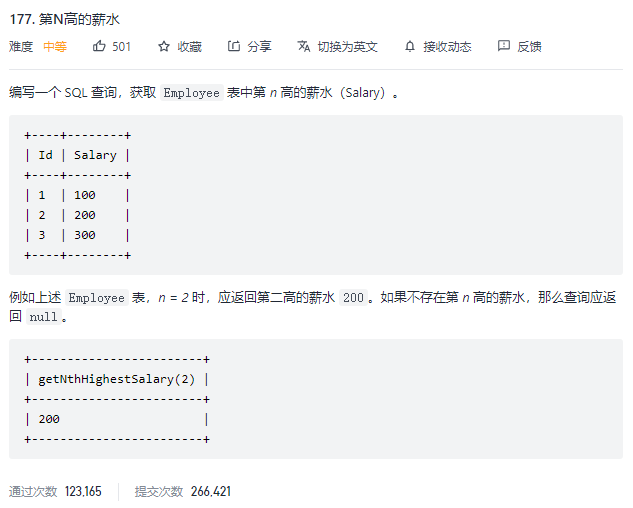
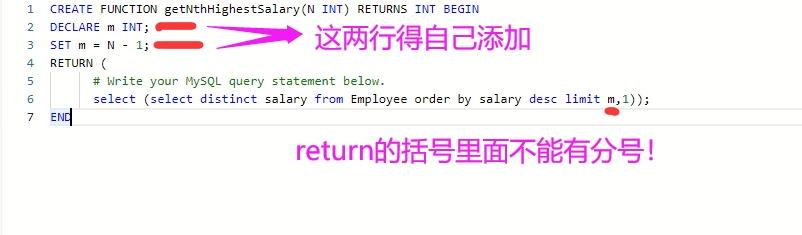
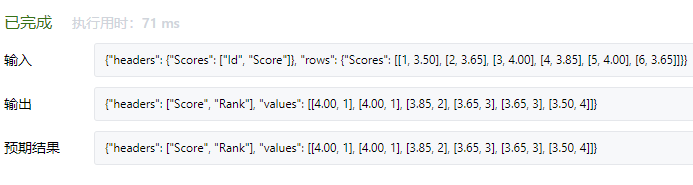
4.分数排名

select a.Score,(select count(distinct b.score) from Scores as b where b.score>=a.score) as Rank from Scores as a order by a.score desc;
上面的写法真的棒,子查询到处可以放置

5.连续出现的数字
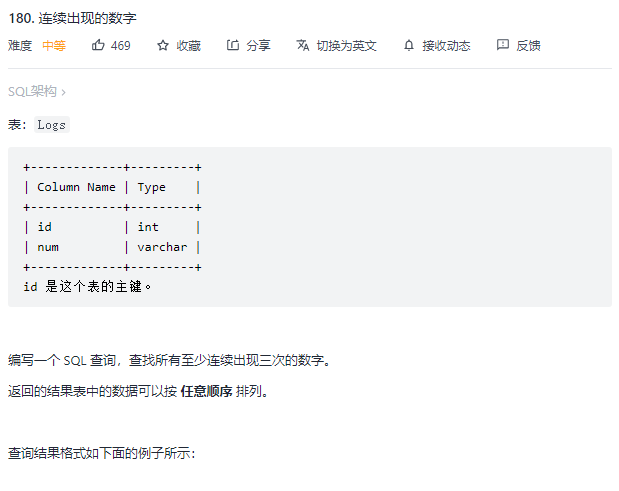
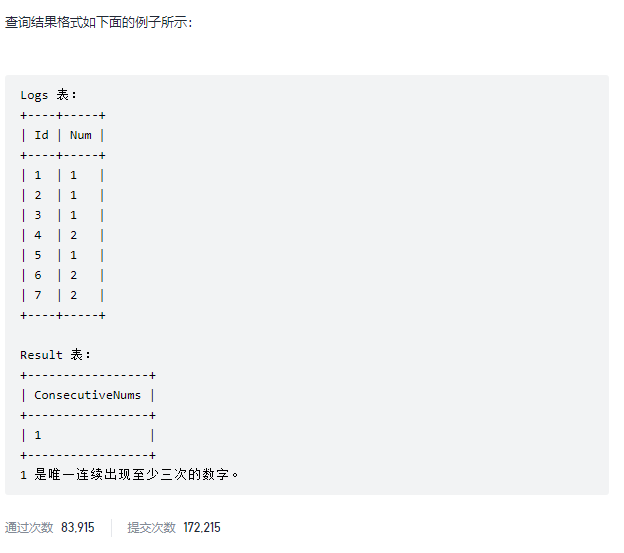
select distinct l1.Num as ConsecutiveNums from Logs as l1,logs as l2,logs as l3 where l1.id=l2.id+1 and l2.id=l3.id+1 and l1.Num=l2.Num and l2.Num=l3.Num;
本质上就是三表查询
那要是连续出现10次还得10表查询?
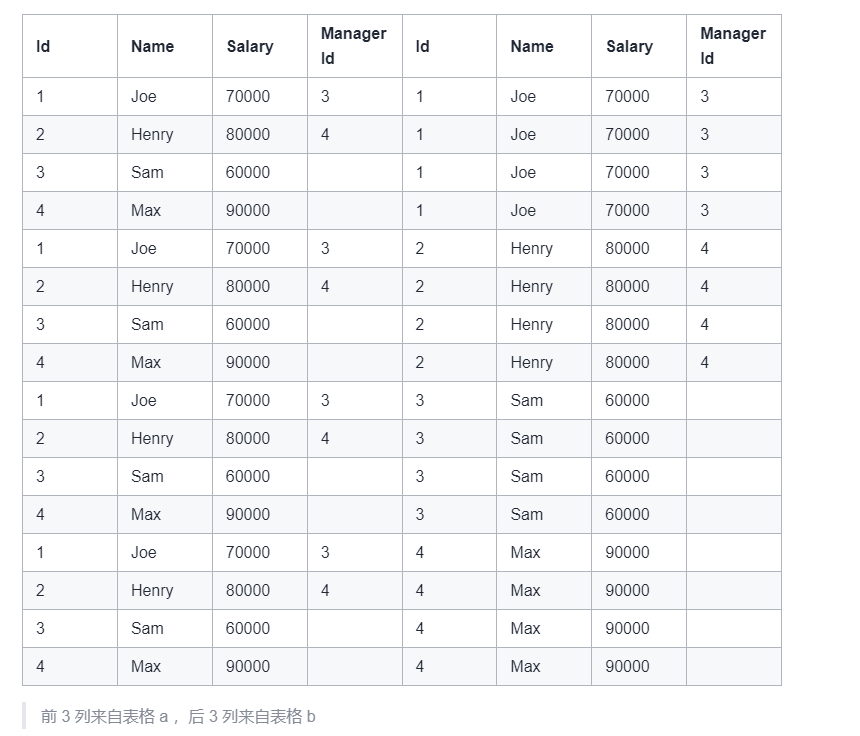
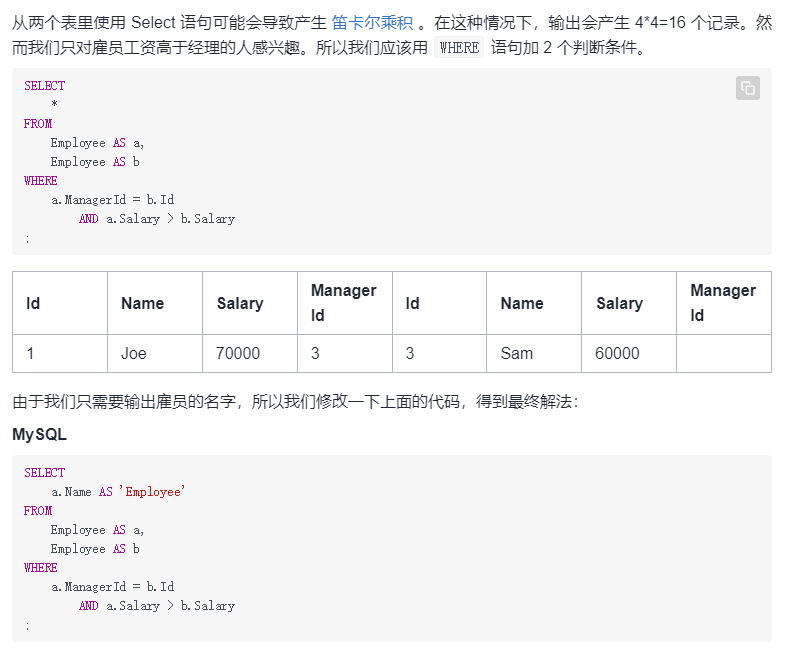
6.超过经理收入的员工

7.查找重复的电子邮箱
8.从不订购的客户

select Name as Customers from Customers where Id not in (select CustomerId from Orders);
这里的子查询没有用别名,我觉得where子句在子查询的前面就不需要,后面就需要;
评论区都在说not in效率不高
这也太专业了!
9.部门工资最高的员工


# select Department.Name,Employee.Name,max(salary) from Employee,Department where Employee.DepartmentId=Department.Id group by Department.Id;
上面的写法无法显示多个员工,这些员工的工资相同且为该部门最高
select Department.Name as Department,Employee.Name as Employee ,salary
from Employee,Department where Employee.DepartmentId=Department.Id
and (Department.Id,salary) IN
(select DepartmentId ,max(salary) from Employee group by DepartmentId);
先在部门表中找到每个部门的最高薪水
然后再将部门表和员工表联结起来
找到其中的符合最高薪水的数据
10.部分工资前三高的员工

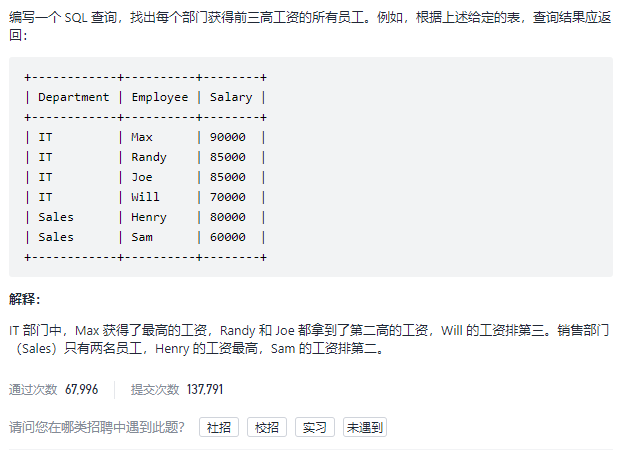
使用group by如果没有聚合函数min,max之类的则只会在每个group中显示第一个
#按照DepartmentId之后求出前三个最大的salary显示出来怎么做?limit是配合group by的,不是配合order by,即limit限制的是group by的列
#group by是用来配合聚集函数的,如sum,avg,min,max,count,这些的结果都是单个值
# Select DepartmentId, salary from Employee group by DepartmentId order by salary desc limit 0,3 ;
select Department.Name as Department,e1.Name as Employee,e1.salary from Employee as e1 , Department
where e1.DepartmentId=Department.Id
and 3>(select count(distinct e2.salary) from Employee as e2 where e2.salary>e1.salary and e1.DepartmentId=e2.DepartmentId)
当e2中的salary大于e1中的salary的数目为零时说明此时的e1.salary是第一名
当e2中的salary大于e1中的salary的数目为1时说明此时的e1.salary是第二名
当e2中的salary大于e1中的salary的数目为2时说明此时的e1.salary是第三名
11.上升的温度


Write your MySQL query statement below
#select w2.id as id from Weather w1,Weather w2 where w1.recordDate=w2.recordDate-1 and w1.Temperature select w2.id as id from Weather w1,Weather w2 where Datediff(w2.recordDate,w1.recordDate)=1 and w1.Temperature <w2.Temperature;
这道题考时间差函数DATEDIFF(时间1,时间2):当时间1比时间2更向未来时,函数值为正;
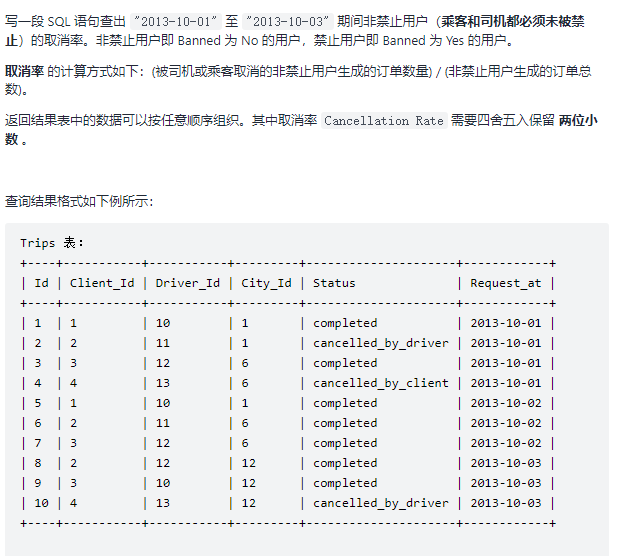
12.行程与用户(困难)

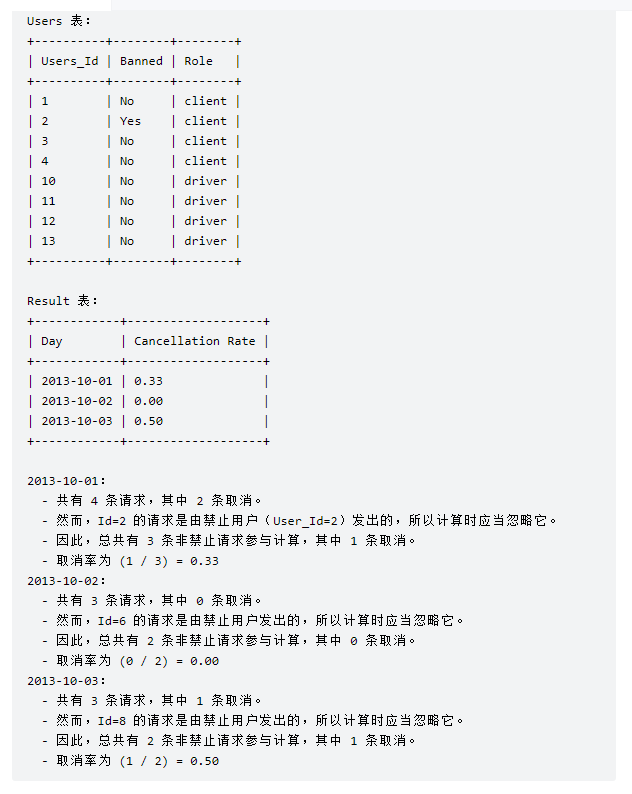
写法1:
select t.request_at Day,round((count(if(t.status<>’completed’,1,null))/count(*)),2) “Cancellation Rate”
from trips t
join users c on c.users_id=t.client_id and c.banned=’NO’
join users d on d.users_id=t.driver_id and d.banned=’NO’
where t.request_at between ‘2013-10-01’ and ‘2013-10-03’
group by t.request_at;
写法2:
select t.request_at Day,round((count(if(t.status<>’completed’,1,null))/count(*)),2) “Cancellation Rate”
from trips t,users c,users d where (c.users_id=t.client_id and c.banned=’NO’) and (d.users_id=t.driver_id and d.banned=’NO’) and
(t.request_at between ‘2013-10-01’ and ‘2013-10-03’)
group by t.request_at;
尝试查看这种三表联结得到的表的内容
select
from trips t,users c,users d where (c.users_id=t.client_id and c.banned=’NO’) and (d.users_id=t.driver_id and d.banned=’NO’)
#三张表的笛卡尔积的项数并不一定比一张表多,只要约束条件加得严格,项数可能更少。
“Id”, “Client_Id”, “Driver_Id”, “City_Id”, “Status”, “Request_at”, “Users_Id”, “Banned”, “Role”, “Users_Id”, “Banned”, “Role”
1, 1, 10, 1, “completed”, “2013-10-01”, 1, “No”, “client”, *10, “No”, “driver”
3, 3, 12, 6, “completed”, “2013-10-01”, 3, “No”, “client”, 12, “No”, “driver”
4, 4, 13, 6, “cancelled_by_client”, “2013-10-01”, 4, “No”, “client”, 13, “No”, “driver”
5, 1, 10, 1, “completed”, “2013-10-02”, 1, “No”, “client”, 10, “No”, “driver”
7, 3, 12, 6, “completed”, “2013-10-02”, 3, “No”, “client”, 12, “No”, “driver”
9, 3, 10, 12, “completed”, “2013-10-03”, 3, “No”, “client”, 10, “No”, “driver”
10, 4, 13, 12, “cancelled_by_driver”, “2013-10-03”, 4, “No”, “client”, 13, “No”, “driver”
可以看出三表联结之后的项数比Trips表的项数还要少!
这里的联结纯粹就是为了把Trips表中的某些记录剔除掉
这些记录中的client_id或者driver_id只要有一个是禁止用户的就要被删除
13.换座位


select id,student from seat where id = (select max(id) from seat) and id %2=1
union
select a.id,b.student from seat a,seat b
where a.id%2=1 and a.id=b.id-1
union
select a.id,b.student from seat a,seat b
where a.id%2=0 and a.id=b.id+1
order by id
用union考虑多种情况,然后拼在一起
这个思路确实不错
很多答案里面调用各种函数,没有这个直观

若有收获,就点个赞吧
0 人点赞
