把KMP算法按得死死的~
CodeSheep;) 昨天
以下文章来源于Aime菌 ,作者Aimetoi
 Aime菌一个热爱技术的学生党,想把分享变成一种习惯!
Aime菌一个热爱技术的学生党,想把分享变成一种习惯!
「字符串匹配」是计算机基本任务之一,举个栗子,有一个字符串“「aaaaaaca」“,我想知道里面是否包含另一个字符串“「aaaac」”,该怎么办?
这里就会使用到「串的模式匹配算法」,最常见的分别是传统的「Brute-Force(暴力)算法」和「KMP算法」。
BF算法设计思想
1、主串和模式串逐个字符进行比较

2、当出现「字符串不相同」时,也就是「失配」时,主串的比较位置重置为起始位置的下一个字符位置,模式串的比较位置重置为起始位置

3、匹配成功后返回主串中匹配串的起始位置,否则就返回错误代码
BF算法的设计缺陷及解决方案
在BF算法中,每次失配都需要回溯指向上次比较起始字符的下一个字符。通过观察发现:在回溯的时候,已匹配似乎「有一部分」没必要继续比较了,这样可以降低算法的「时间复杂度」

「KMP」算法的出现有效地解决了BF算法的缺陷。KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位神人共同提出的。
但是这种算法相对于BF算法不太容易理解,网上也有很多解释,但配图有点少,总感觉差点意思,下面我通过画图的方式详细介绍KMP算法的设计思想和工作原理
KMP算法设计思想
在匹配过程中出现字符比较不相等时,「主串 S」已比较的位置不回溯,「模式串 T」比较的位置进行移动

在匹配过程中有一个难题需要解决:如何计算「模式串 T」失配时的移动位数?经过三位牛人的研究,设计出了「部分匹配函数」
部分匹配函数
部分匹配函数是KMP算法中最难以理解的部分。首先需要理解「前缀」、「后缀」、「最大共有长度」的概念。
· 前缀:指除了最后一个字符以外,一个字符串的全部头部组合
· 后缀:指除了第一个字符以外,一个字符串的全部尾部组合
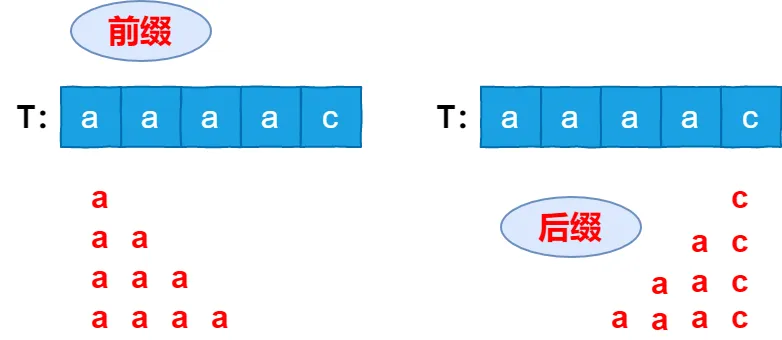
· 最大共有长度(部分匹配值):指前缀和后缀中的最大共有元素,没有则为0。例如“abab”的前缀为“a”、“ab”、“aba”,后缀为“b”、“ab”、“bab”,最大共有元素为“ab”,所以最大共有长度为 2
回顾一下KMP算法的匹配过程:
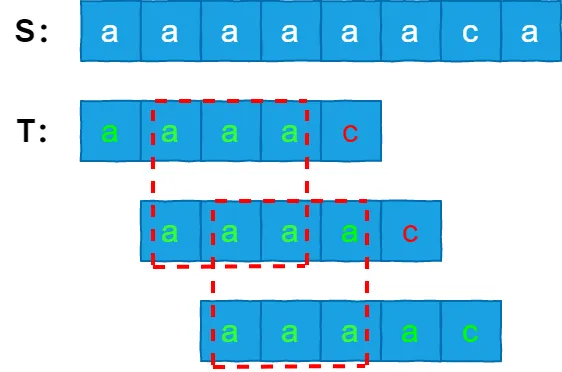
红线框出的部分恰好就是失配时已匹配部分,“aaaa” 的最大共有元素为 “aaa”,这一部分字符就是不需要再重复进行比较直接跳过的字符

在代码实现过程中,j 移动后的位置 = 模式串 T 的起始位置下标 + 部分匹配值。通常起始下标为 0,因此 j 移动后位置 = 部分匹配值,即 j = next[j],next[j] 就是「部分匹配函数」,j 为失配时的位置
因此接下来就成了对部分匹配函数的是实现。将 “aaaac” 以首字符起始的所有子串的最大共有长度枚举出来,构成「部分匹配表」,它描述了失配时的下标 j 与部分匹配值的关系

部分匹配表则是通过模式串 T 的自匹配实现:

示例代码(C语言哦):
/*KMP匹配算法*/int KMPCompare(HString parent, HString child, intpos) {int next[255];Get_Next(child, next);int i = pos - 1;int j = 0; //j用于子串child中的起始位置while (i < parent.length && j < child.length) {if (j == 0 || parent.ch[i] == child.ch[j]) {++i;++j;}else {j = next[j]; //i不变,j后退}}if (j == child.length) {return (i + 1) - j;}return 0;}/*部分匹配函数的实现*/void Get_Next(HString child, int * next) {int i = 0;int j = -1;next[0] = -1; //不会用到while (i < child.length) {if (j == -1 || child.ch[i] == child.ch[j]) {++i;++j;next[i] = j;}else {j = next[j];}}}void main() {/*使用KMP算法匹配串*/HString parent, child;StrAssign_HeapString(&parent, "BBC ABCDAB ABCDABCDABDE");StrAssign_HeapString(&child, "ABCDABD");printf("Index = %d\n", KMPCompare(parent, child, 1));}
往期资源回顾 需要可自取

若有收获,就点个赞吧
0 人点赞
