Redis
# 默认一共16个数据库# 切换数据库127.0.0.1:6379> select 1# 查看当前数据库大小127.0.0.1:6379[1]> dbsize# 查看所有key值127.0.0.1:6379> keys *# 清空当前数据库127.0.0.1:6379[1]> flushdb# 清空全部数据库127.0.0.1:6379[1]> flushall
redis是单线程的,基于内存的,CPU不是性能瓶颈,瓶颈是机器的内存和网络带宽。
误区:高性能的服务器一定是多线程的?多线程(CPU上下文切换,耗时)一定比单线程效率高?
为什么redis这么快,核心:redis将所有的数据都放在内存中,所以说使用单线程去操作就是效率最高的,多线程(CPU上下文切换耗时)单线程切换开销小,容易实现既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
简介
Redis是一种开放源代码(BSD许可)的内存中数据结构存储,用作数据库,缓存和消息代理。它支持数据结构,例如 字符串,哈希,列表,集合,带范围查询的排序集合,位图,超日志,带有半径查询和流的地理空间索引。Redis具有内置的复制,Lua脚本,LRU逐出,事务和不同级别的磁盘持久性,并通过以下方式提供高可用性:Redis Sentinel和Redis Cluster自动分区。
您可以 对这些类型运行原子操作,例如追加到字符串; 在哈希中增加值 ; 将元素推送到列表 ; 计算集的交, 并与差 ; 或获得排序集中排名最高的成员。
为了获得出色的性能,Redis使用 内存数据集。根据您的用例,您可以通过不时地 一次将数据集转储到磁盘上,或通过将每个命令附加到log来持久化它。如果只需要功能丰富的网络内存缓存,则可以选择禁用持久性。
Redis还支持琐碎的设置主从异步复制,具有非常快速的非阻塞式首次同步,以及在网络拆分时具有部分重新同步的自动重新连接。
其他功能包括:
您可以从大多数编程语言中使用Redis 。
Redis是用ANSI C编写的,并且可以在大多数POSIX系统中使用,例如Linux, BSD,OS X,而无需外部依赖。Linux和OS X是Redis开发和测试最多的两个操作系统,我们建议使用Linux进行部署。Redis可以在基于Solaris的系统中使用,例如SmartOS,但是尽力提供*了支持。Windows版本没有官方支持。
Redis(Remote Dictionary Server) 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key - value 数据库。
Redis 与 其他 key - value 缓存产品有以下三个特点:
- Redis 支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis 不仅仅支持简单的 key - value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
- Redis 支持数据的备份,即 master - slave 模式的数据备份。
BSD 协议
BSD开源协议是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。当你发布使用了BSD协议的代码,或者以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件:
- 如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。
- 如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。
- 不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
BSD代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销 售,因此是对商业集成很友好的协议。
很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者 二次开发。
优势
- 性能极高 – Redis 读速度是 110000 次 /s, 写的速度是 81000 次 /s 。
- 丰富的数据类型 - Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性 - Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 其他特性 - Redis 还支持 publish/subscribe 通知,key 过期等特性。
不同点
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
基本数据类型
Redis 支持 5 中数据类型:string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)
string
string 是 redis 最基本的数据类型。一个 key 对应一个 value。string 是二进制安全的。也就是说 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。string 类型是 redis 最基本的数据类型,string 类型的值最大能存储 512 MB。
理解:string 就像是 java 中的 map 一样,一个 key 对应一个 value
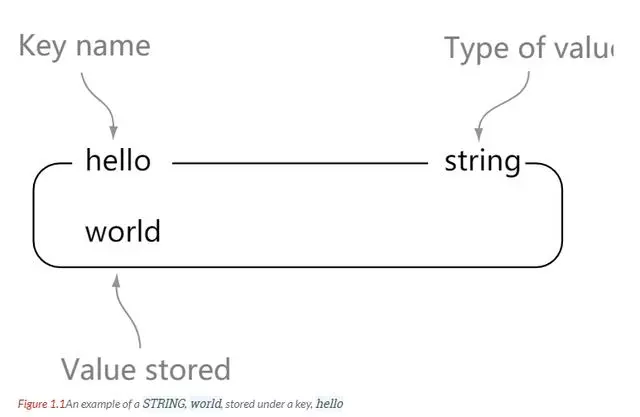
127.0.0.1:6379> set hello world # 设置值OK127.0.0.1:6379> get hello # 查看值"world"127.0.0.1:6379> keys * # 查看全部key1) "hello"127.0.0.1:6379> exists hello # 验证key是否存在(integer) 1127.0.0.1:6379> append hello s # 追加字符串,如果key不存在,相当于创建(integer) 6127.0.0.1:6379> strlen hello # 获取字符串长度(integer) 6127.0.0.1:6379> incr views # key的值加一127.0.0.1:6379> decr views # key的值减一127.0.0.1:6379> incrby views 10 # 设置增加步长127.0.0.1:6379> decrby views 5 # 设置减少步长127.0.0.1:6379> getrange hello 0 2 # 截取字符串"wor"127.0.0.1:6379> getrange hello 0 -1 # 截取到最后"worlds"127.0.0.1:6379> setrange hello 2 xx # 替换字符串(integer) 6127.0.0.1:6379> get hello"woxxds"127.0.0.1:6379> setex my 30 name # 设置过期时间OK127.0.0.1:6379> ttl my # 查询剩余时间(integer) 23127.0.0.1:6379> setnx db redis # 不存在则设置(分布式锁常用)(integer) 1127.0.0.1:6379> setnx db mongdb(integer) 0127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # 同时设置多个值OK127.0.0.1:6379> mget k1 k2 k3 # 同时获取多个值1) "v1"2) "v2"3) "v3"127.0.0.1:6379> msetnx k1 v1 k4 v4 # msetnx是一个原子性的操作(integer) 0# 对象127.0.0.1:6379> set user:1 {name:zhangsan,age:3}OK127.0.0.1:6379> get user:1"{name:zhangsan,age:3}"# 对象2127.0.0.1:6379> mset user:2:name zhangsan user:2:age 3OK127.0.0.1:6379> mget user:2:name user:2:age1) "zhangsan"2) "3"# 组合命令127.0.0.1:6379> getset k v(nil)127.0.0.1:6379> get k"v"127.0.0.1:6379> getset k vv"v"127.0.0.1:6379> get k"vv"
hash
Redis hash 是一个键值对(key - value)集合。Redis hash 是一个 string 类型的 key 和 value 的映射表,hash 特别适合用于存储对象。
理解:可以将 hash 看成一个 key - value 的集合。也可以将其想成一个 hash 对应着多个 string。更适合存放对象
与 string 区别:string 是 一个 key - value 键值对,而 hash 是多个 key - value 键值对。
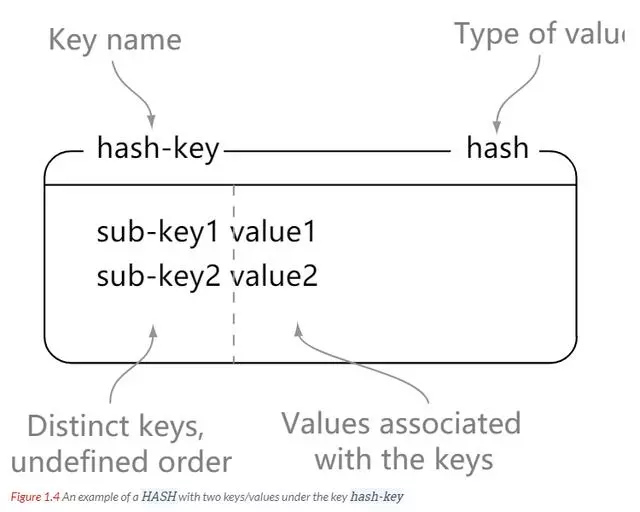
# hash-key 可以看成是一个键值对集合的名字,添加了 sub-key1 : value1 键值对127.0.0.1:6379> hset hash-key sub-key1 value1(integer) 1# 同时设置多个值127.0.0.1:6379> hmset key field value [field value ...]# 同时获取多个值127.0.0.1:6379> hmget key field [field ...]# 获取 hash-key 这个 hash 里面的所有键值对127.0.0.1:6379> hgetall key# 删除 hash-key 这个 hash 里面的 sub-key2 键值对127.0.0.1:6379> hdel hash-key sub-key2(integer) 1127.0.0.1:6379> hgetall hash-key1) "sub-key1"2) "value1"3) "sub-key3"4) "value3"# 获取hash的长度127.0.0.1:6379> hlen k(integer) 2# 是否存在127.0.0.1:6379> hexists key field# 查询所有的key127.0.0.1:6379> hkeys key# 查询所有的值127.0.0.1:6379> hvals key# hash也有 hsetnx
list
Redis 列表是简单的字符串列表,按照插入顺序排序。我们可以网列表的左边或者右边添加元素。
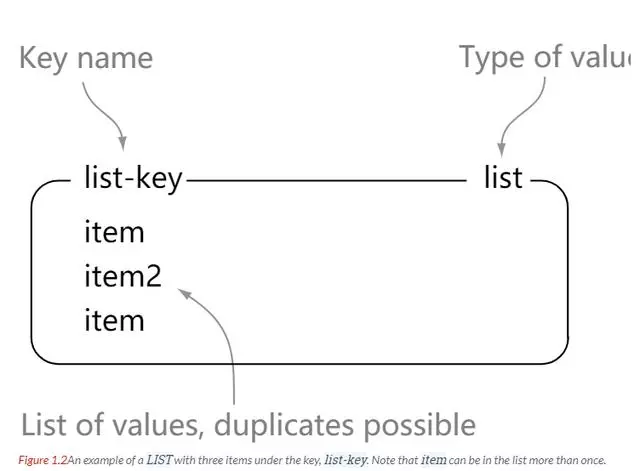
# 从左侧放入元素127.0.0.1:6379> lpush list 1127.0.0.1:6379> lpush list 2127.0.0.1:6379> lpush list 3127.0.0.1:6379> lrange list 0 -11) "3"2) "2"3) "1"# 从右侧放入元素127.0.0.1:6379> rpush list 1127.0.0.1:6379> rpush list 2127.0.0.1:6379> rpush list 3127.0.0.1:6379> lrange list 0 -11) "1"2) "2"3) "3"# 通过index获取127.0.0.1:6379> lindex list 2"3"# 从左侧取出元素127.0.0.1:6379> lpop list"1"127.0.0.1:6379> lrange list 0 -11) "2"2) "3"# 从右侧取出元素127.0.0.1:6379> rpop list"3"127.0.0.1:6379> lrange list 0 -11) "2"# 列表的长度127.0.0.1:6379> llen list(integer) 1# 移出指定key 指定个数 的值(精确匹配)127.0.0.1:6379> lrem key count value# 截取list值127.0.0.1:6379> ltrim key start stop# 替换指定下标的值(list对应的下标需要存在)127.0.0.1:6379> lset list 0 vv# 在某个list相应值的前或者后放入值# linsert key BEFORE|AFTER pivot value127.0.0.1:6379> lrange list 0 -11) "a"2) "c"3) "d"127.0.0.1:6379> linsert list before c b127.0.0.1:6379> lrange list 0 -11) "a"2) "b"3) "c"4) "d"# 组合命令# 移出source的最后一个元素放入destination里(destination不存在则创建)127.0.0.1:6379> rpoplpush source destination
我们可以看出 list 就是一个简单的字符串集合,和 Java 中的 list 相差不大,区别就是这里的 list 存放的是字符串。list 内的元素是可重复的。可以当作消息队列,或者栈。
set
redis 的 set 是字符串类型的无序集合。集合是通过哈希表实现的,因此添加、删除、查找的复杂度都是 O(1)
# 添加值127.0.0.1:6379> sadd k1 v1(integer) 1127.0.0.1:6379> sadd k1 v2(integer) 1127.0.0.1:6379> sadd k1 v3(integer) 1127.0.0.1:6379> sadd k1 v1(integer) 0# 查看元素127.0.0.1:6379> smembers k11) "v3"2) "v2"3) "v1"# 判断元素是否存在127.0.0.1:6379> sismember k1 k4(integer) 0127.0.0.1:6379> sismember k1 v1(integer) 1# 移除元素127.0.0.1:6379> srem k1 v2(integer) 1127.0.0.1:6379> srem k1 v2(integer) 0127.0.0.1:6379> smembers k11) "v3"2) "v1"# 随机取出元素127.0.0.1:6379> srandmember key [count]# 随机删除元素,输出删除的元素127.0.0.1:6379> spop key [count]# 将指定值移动到另一个set127.0.0.1:6379> smove source destination member# 集合操作127.0.0.1:6379> sdiff key [key ...] # 差集127.0.0.1:6379> sinter key [key ...] # 交集127.0.0.1:6379> sunion key [key ...] # 并集
redis 的 set 与 java 中的 set 还是有点区别的。
redis 的 set 是一个 key 对应着 多个字符串类型的 value,也是一个字符串类型的集合
但是和 redis 的 list 不同的是 set 中的字符串集合元素不能重复,但是 list 可以。
zset
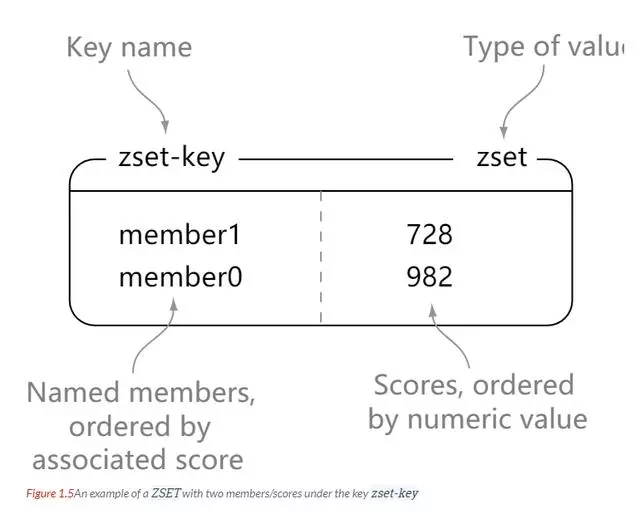
redis zset 和 set 一样都是 字符串类型元素的集合,并且集合内的元素不能重复。
不同的是,zset 每个元素都会关联一个 double 类型的分数。redis 通过分数来为集合中的成员进行从小到大的排序。
zset 的元素是唯一的,但是分数(score)却可以重复。
# 添加127.0.0.1:6379> zadd zset-key 728 member1(integer) 1127.0.0.1:6379> zadd zset-key 982 member0(integer) 1127.0.0.1:6379> zadd zset-key 982 member0(integer) 0# 查看127.0.0.1:6379> zrange zset-key 0 -1 withscores1) "member1"2) "728"3) "member0"4) "982"# 限制范围127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores1) "member1"2) "728"# 删除元素127.0.0.1:6379> zrem zset-key member1(integer) 1127.0.0.1:6379> zrem zset-key member1(integer) 0# 查看元素个数127.0.0.1:6379> zcard key(integer) 4# 降序查看127.0.0.1:6379> zrevrange key start stop [WITHSCORES]# 查看统计值127.0.0.1:6379> zcount key min max
zset 是按照分数的大小来排序的。
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合 | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
geospatial
概念
- redis的GEO特性在Redis3.2版本发布,这个功能可以将用户给定的地理位置信息储存起来,并对这些信息进行操作。
- GEO常用语LBS(Location Based Service),基于位置的服务。
相关命令
- 命令名称:geoadd
- 语法:geoadd key longitude latitude member [longitude latitude member……]
功能:
- 将给定的空间元素(维度、经度、名字)添加到指定的键里面。
- 有效的经度介于-180度至180度之间。
- 有效的维度介于-85.05112878度至85.05112878度之间。
返回值:
- 新添加到键里面的空间元素数量,不包括那些已经存在但是被更新的元素。
# 添加位置信息127.0.0.1:6379> geoadd key longitude latitude member [longitude latitude member ...]127.0.0.1:6379> geoadd china:city 116.28 39.54 beijing(integer) 1
- 命令名称:geopos
- 语法:geopos key member [member……]
功能:
- 从键里面返回所有给定位置元素的位置(经度和维度)
返回值:
- 返回一个数组,数组中的每个项都由两个元素组成:第一个元素为给定位置元素的经度,第二个元素为给定位置元素的纬度。
# 获取成员位置127.0.0.1:6379> geopos china:city beijing1) 1) "116.28000229597091675"2) "39.54000124957348561"
- 命令名称:geodist
- 语法:geodist key member1 member2 [unit]
功能:
- 返回两个给定位置之间的距离。
- 如果两个位置之间的其中一个不存在,那么返回空值。
- 指定单位的参数unit必须是一下单位的其中一个:(默认m,km,mi,ft)
返回值:
- 计算出的距离会以双精度浮点数的形式被返回。如果给定的位置元素不存在,那么命令返回空值。
# 获取成员间的距离127.0.0.1:6379> geodist china:city beijing zhengzhou"622485.0956"127.0.0.1:6379> geodist china:city beijing zhengzhou km"622.4851"
- 命令名称:georadius
- 语法:georadius key longitude latitude radius m|km|gt|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
- 功能:1)以给定的经纬度为中心,返回键包含的位置元素当中,与中心的距离不超过给定最大距离的而所有位置元素。
选项:
- WITHDIST:在返回位置元素的同时,将位置元素与中心之间的距离也一并返回。
- WITHCOORD:将位置元素的经度和纬度也一并返回。
- WITHHASH:以52位有符号整数的形式,返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试,实际中的作用并不大。
- ASC:根据中心的位置,按照从近到远的方式返回位置元素
- DESC:根据中心的位置,按照从远到近的方式返回位置元素
127.0.0.1:6379> georadius china:city 110.00 30.00 800 km withcoord withdist withhash1) 1) "zhengzhou"2) "588.4221"3) (integer) 40641968687016164) 1) "113.42000037431716919"2) "34.43000085762499651"
- 命令名称:georadiusbymember
- 语法:georadiusbymemeber key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
功能:
- 这个命令和georadius命令一样。
- 不同的是中心点是由给定的位置元素决定的。
返回值:
- 一个数组,数组中的每个项表示一个范围之内的位置元素。
127.0.0.1:6379> georadiusbymember china:city beijing 800 km1) "zhengzhou"2) "beijing"3) "tianjin"
- 命令名称:geohash
- 语法:geohash key member [member……]
功能:
- 返回一个或多个位置元素的geohash表示。
返回值:
- 一个数组,数组中的每个项都是一个geohash。命令返回的geohash的位置与用户给定的位置元素的位置一一对应。
127.0.0.1:6379> geohash china:city beijing1) "wx48yn090q0"
geo的底层是zset,可以使用相关的zset命令。
# 查询127.0.0.1:6379> zrange china:city 0 -1 withscores1) "haikou"2) "3975568994346731"3) "guangzhou"4) "4046510568184210"5) "zhengzhou"6) "4064196868701616"7) "beijing"8) "4069140601296155"9) "tianjin"10) "4069185531597821"# 移除127.0.0.1:6379> zrem china:city haikou(integer) 1127.0.0.1:6379> zrange china:city 0 -11) "guangzhou"2) "zhengzhou"3) "beijing"4) "tianjin"
hyperloglog
概念
1、redis在2.8.9版本添加了HyperLogLog结构。
2、redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且使很小的。
3、在redis里面,每个HyperLogLog键只需要花费12kb内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
4、但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
什么是基数
比如数据集{1,3,5,7,5,7,8},那么这个数据集的基数集为{1,3,5,7,8},基数(不重复元素)为5.基数估计就是在误差可接受的范围内,快速计算基数。
相关命令
- 命令名称:pfadd
- 语法:pfadd key element [element……]
功能:
- 将任意数量的元素添加到指定的HyperLogLog里面。
- 作为这个命令的副作用,HyperLogLog内部可能会被更新,以便反映一个不同的唯一元素估计数量(也即是集合的基数)。
返回值:
- 整数回复:如果HyperLogLog的内部储存被修改了,那么返回1,否则返回0.
127.0.0.1:6379> pfadd k2 e f 5 6(integer) 1127.0.0.1:6379> pfadd k2 e f 5 6(integer) 0
- 命令名称:pfcount
- 语法:pfcount key [key……]
功能:
- 当pfcount命令作用于当个键时,返回储存在给定键的HyperLogLog的近似基数,如果键不存在,那么返回0。
- 当pfcount命令作用于多个键时,返回所有给定HyperLogLog的并集的近似基数,这个近似基数是通过将所有给定HyperLogLog合并至一个临时HyperLogLog来计算得出的。
返回值:
- 整数回复:给定HyperLogLog包含的唯一元素的近似数量。
127.0.0.1:6379> pfadd k a b c d(integer) 1127.0.0.1:6379> pfadd k 1 2 3 4 a(integer) 1127.0.0.1:6379> pfcount k(integer) 8
- 命令名称:pfmerge
- 语法:pfmerge destkey sourcekey [sourcekey……]
功能:
- 将多个HyperLogLog合并(merge)为一个HyperLogLog,合并后的HyperLogLog的基数接近于所有输入HyperLogLog的可见集合(observed set)的并集。
返回值:
- 返回OK
127.0.0.1:6379> pfmerge k2 kOK127.0.0.1:6379> pfcount k k2(integer) 12127.0.0.1:6379> pfcount k(integer) 8127.0.0.1:6379> pfcount k2(integer) 12
Bitmaps
位地图,就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省储存空间。
Redis从2.2.0版本开始新增了setbit,getbit,bitcount等几个bitmap相关命令。虽然是新命令,但是并没有新增新的数据类型,因为setbit等命令只不过是在set上的扩展。
在一台2010MacBook Pro上,offset为230-1(分配128MB)需要~80ms,offset为226-1(分配8MB)需要8ms。<来自官方文档>
大概的空间占用计算公式是:($offset/8/1024/1024)MB
使用场景一:用户签到。
使用场景二:统计活跃用户
使用场景三:用户在线状态
- 命令名称:setbit
- 语法:setbit key offset value
功能:
- 1)对key所存储的字符串值,设置或清除指定偏移量上的位(bit),位的设置或清除取决于value参数,可以是0也可以是1。
- 2)字符串会进行伸展(grown)以确保它可以将value保存在指定的偏移量上。当字符串值进行伸展时,空白位置以0填充。offset参数必须大于或等于0,小于2^32(bit映射被限制在512MB之内)
返回值:
- 1)当key不存在时,自动生成一个新的字符串值。
- 2)指定偏移量原来存储的位。
127.0.0.1:6379> setbit bm 1 0(integer) 0127.0.0.1:6379> setbit bm 2 2(error) ERR bit is not an integer or out of range
- 命令名称:getbit
- 语法:getbit key offset
- 功能:1)对key所存储的字符串值,获取指定偏移量上的位(bit)
返回值:
- 1)当offset比字符串值的长度大,或者key不存在时,返回0。
- 2)字符串值偏移量上的位(bit)
127.0.0.1:6379> getbit bm 0(integer) 1
- 命令名称:bitcount
- 语法:bitcount key [start] [end]
- 注意:start和end是一个字节,一个字节为8位
功能:
- 1)计算给定字符串中,被设置为1的比特位的数量。
- 2)一般情况下,给定的整个字符串都会被进行计数,通过指定额外的start或end参数,可以让计数只在特定的位上进行。
- 返回值:1)不存在的key被当成是空字符串来处理,因此对一个不存在的key进行bitcount操作,结果为0/被设置为1的位的数量
127.0.0.1:6379> bitcount bm(integer) 2
命令名称:bitop
语法:bitop operation destkey key [key……]
功能:1)对一个或多个保存二进制位的字符串key进行位元操作,并将结果保存到destkey上。
OPERATION:
- 1)可以是and(与)、or(或)、not(非)、xor(异或)这四种操作中的任意一种。
- 2)除了not操作外,其他操作都可以接受一个或多个key作为输入
注意:1)当bitop处理不同长度的字符串时,较短的那个字符串所缺少的额部分会被看做0.空的key也被看做是包含0的字符串序列
返回值:1)保存到destkey的字符串的长度,和输入key中最长的字符串长度相等。
命令名称:bitpos
语法:bitpos key bit [start] [end]
注意:start和end是一个字节,一个字节为8位
功能:1)返回字符串里面第一个被设置为1或者0的bit位。
返回值:
- 1)命令返回字符串里面第一个被设置为1或者0的bit位。
- 2)如果我们在空字符串或者0字节的字符串里面查找bit为1的内容,那么结果将返回-1。
分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0, R1, R2, R3, 还有很多表示用户的键 user:1, user:2, … , 有不同的方式来选择一个指定的键存储在哪个实例中。
- 最简单的是范围分片,例如用户 id 从 0 ~ 1000 的存储到实例 R0 中,用户 id 从 1001 ~ 2000 的存储到实例 R1中,等等。但是这样需要维护一张映射范围表,维护操作代价高。
- 还有一种是哈希分片。使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道存储的实例。
根据执行分片的位置,可以分为三种分片方式:
- 客户端分片:客户端使用一致性哈希等算法决定应当分布到哪个节点。
- 代理分片:将客户端的请求发送到代理上,由代理转发到正确的节点上。
- 服务器分片:Redis Cluster。
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。没有隔离级别的概念。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余命令依然被执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
相关命令
命令名称:multi
语法:multi
功能:标记一个事务块的开始
返回值:总是返回OK命令名称:exec
语法:exec
功能:执行所有事务块内的命令。
返回值:- 事务块内所有命令的返回值,按命令执行的先后顺序排列。
- 当操作被打断时,返回空值nil。
- 命令名称:discard
语法:discard
功能:取消事务,放弃执行事务块内的所有命令。
返回值:总是返回OK
127.0.0.1:6379> multiOK127.0.0.1:6379> set k2 v2QUEUED127.0.0.1:6379> discardOK127.0.0.1:6379> get k2(nil)
命令名称:watch
语法:watch key [key……]
功能:监视一个(或多个)key,如果在事务执行之前这个(或这些)key被其他命令所改动,那么事务将被打断。
返回值:总是返回OK命令名称:unwatch
语法:unwatch
功能:- 取消watch命令对所有key的监视。
- 如果在执行watch命令之后,exec命令或discard命令先被执行了的话,那么久不需要再执行unwatch了
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
127.0.0.1:6379> multiOK127.0.0.1:6379> set k vQUEUED127.0.0.1:6379> get kQUEUED127.0.0.1:6379> sadd tag "c++"QUEUED127.0.0.1:6379> smembers tagQUEUED127.0.0.1:6379> exec1) OK2) "v"3) (integer) 14) 1) "c++"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It’s important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multiOKredis 127.0.0.1:7000> set a aaaQUEUEDredis 127.0.0.1:7000> set b bbbQUEUEDredis 127.0.0.1:7000> set c cccQUEUEDredis 127.0.0.1:7000> exec1) OK2) OK3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。如果是编译错误,整个事务将不会被执行。
监控
悲观锁:无论做什么都会加锁。
乐观锁:不会加锁,更新数据时要获取version并比较。
# 正常情况127.0.0.1:6379> set money 1000OK127.0.0.1:6379> set used 0OK127.0.0.1:6379> watch moneyOK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby money 200QUEUED127.0.0.1:6379> incrby used 200QUEUED127.0.0.1:6379> exec1) (integer) 8002) (integer) 200
# 事务失败127.0.0.1:6379> watch moneyOK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby money 100QUEUED127.0.0.1:6379> incrby used 100QUEUED# 执行事务前127.0.0.1:6379> set money 2000OK# 执行事务127.0.0.1:6379> exec(nil)
# 事务失败后处理 : 先unwatch解锁 > 再watch监控127.0.0.1:6379> unwatchOK127.0.0.1:6379> watch moneyOK127.0.0.1:6379> multiOK127.0.0.1:6379> decrby money 600QUEUED127.0.0.1:6379> incrby used 600QUEUED127.0.0.1:6379> exec1) (integer) 14002) (integer) 800
持久化
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。
一、持久化流程
既然redis的数据可以保存在磁盘上,那么这个流程是什么样的呢?
要有下面五个过程:
(1)客户端向服务端发送写操作(数据在客户端的内存中) > (2)数据库服务端接收到写请求的数据(数据在服务端的内存中) > (3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中) > (4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中) >(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
(1)Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
(2)操作系统发生故障,必须上面5步都完成才可以。
在这里只考虑了保存的过程可能发生的故障,其实保存的数据也有可能发生损坏,需要一定的恢复机制,不过在这里就不再延伸了。现在主要考虑的是redis如何来实现上面5个保存磁盘的步骤。它提供了两种策略机制,也就是RDB和AOF。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。如果系统发生故障,将会丢失最后一次创建快照之后的数据。如果数据量大,保存快照的时间会很长。
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化。我们分别来看一下
1.save触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
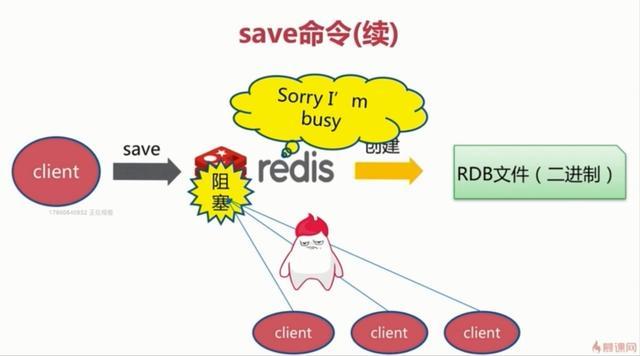
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
2.bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
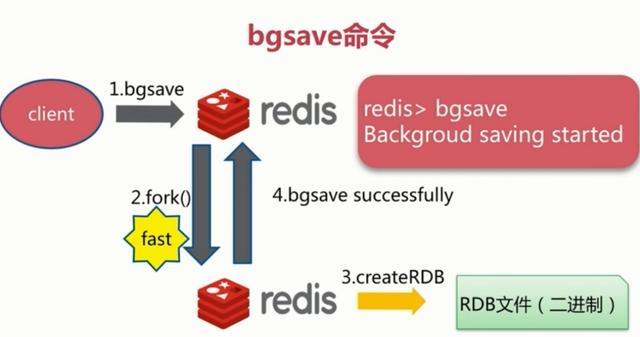
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
3.自动触发
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
①save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
默认如下配置:
表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1
表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10
表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
②stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
④rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤dbfilename :设置快照的文件名,默认是 dump.rdb
⑥dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
我们可以修改这些配置来实现我们想要的效果。因为第三种方式是配置的,所以我们对前两种进行一个对比:
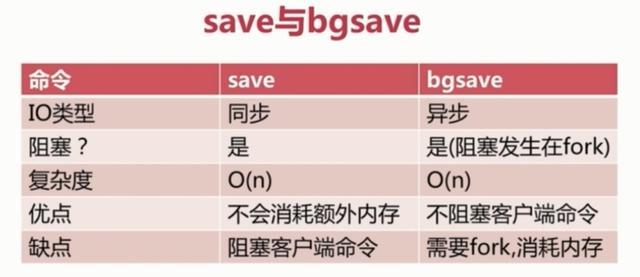
4、RDB 的优势和劣势
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步:
- always 选项会严重减低服务器的性能
- everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
- no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
全量备份总是耗时的,有时候我们提供一种更加高效的方式AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
appendonly.aof文件损坏后可以使用,redis-check-aof命令进行修复。
1、持久化原理
他的原理看下面这张图:
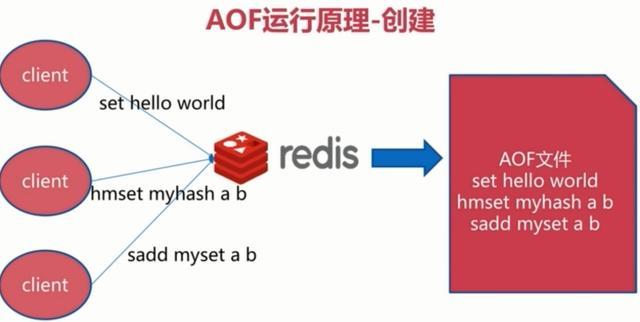
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
# 改为yes,重启即可开启appendonly yes# AOF文件名称 (默认: "appendonly.aof")# appendfilename appendonly.aof# appendfsync alwaysappendfsync everysec# appendfsync nono-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
2、文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
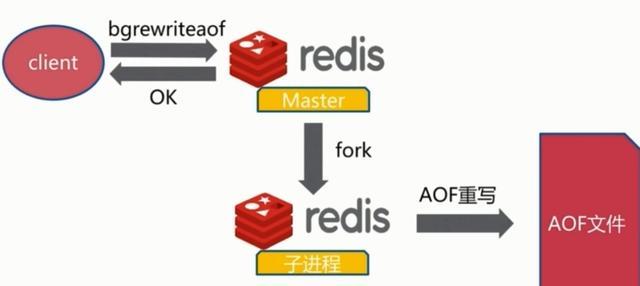
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
3、AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步

4、优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
5、缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
四、RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结:
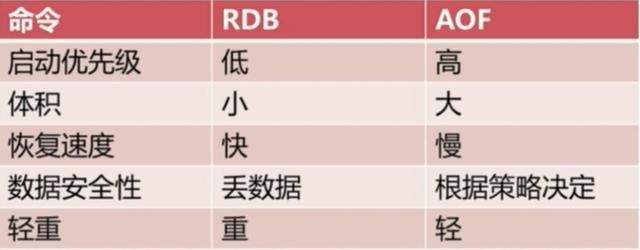
对比了这几个特性,剩下的就是看自己了。
发布订阅
一般不用 Redis 做消息发布订阅。
简介
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
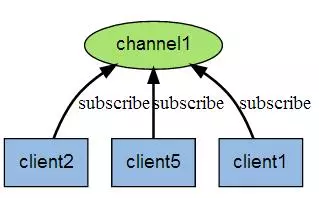
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
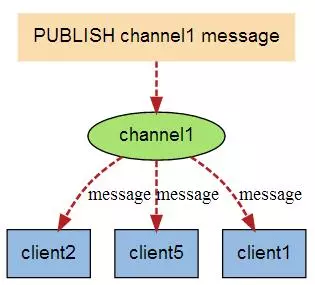
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
# 订阅127.0.0.1:6379> SUBSCRIBE redisChatReading messages... (press Ctrl-C to quit)1) "subscribe"2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
# 发送信息127.0.0.1:6379> PUBLISH redisChat "send message"(integer) 1127.0.0.1:6379> PUBLISH redisChat "hello world"(integer) 1
订阅者的客户端显示如下
# 接收信息127.0.0.1:6379> SUBSCRIBE redisChatReading messages... (press Ctrl-C to quit)1) "subscribe"2) "redisChat"1) "message"2) "redisChat"3) "send message"1) "message"2) "redisChat"3) "hello world"
发布订阅常用命令
自行查阅
复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。一个从服务器只能有一个主服务器,并且不支持主主复制。
连接过程
- 主服务器创建快照文件,即 RDB 文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始像从服务器发送存储在缓冲区的写命令。
- 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令。
- 主服务器每执行一次写命令,就向从服务器发送相同的写命令。
主从链
随着负载不断上升,主服务器无法很快的更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
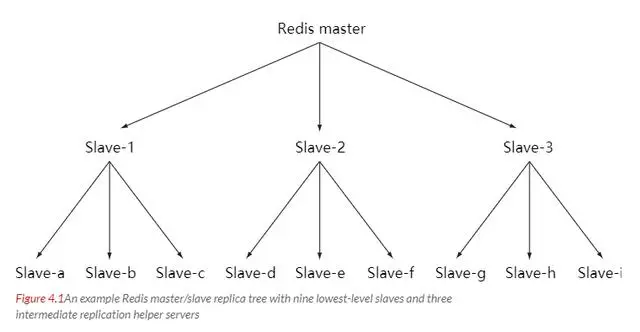
1、redis支持简单且易用的主从复制(master-slave replication)功能,该功能可以让从服务器(slave server)成为主服务器(master server)的精确复制品。
2、以下是关于redis复制功能的几个重要方面
1)redis使用异步复制。
2)一个主服务器可以有多个从服务器。
3)不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个网状结构
4)复制功能不会阻塞主服务器。
5)复制功能也不会阻塞从服务器。
6)复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability)。
7)可以通过复制功能来让主服务器免于执行持久化操作。
环境配置
port > pidfile > logfile > dbfilename
127.0.0.1:6379> info replication# Replicationrole:masterconnected_slaves:0 # 没有从机master_replid:a957876b45d8e79fc3ff244dd311a6ece7ba0485master_replid2:0000000000000000000000000000000000000000master_repl_offset:0second_repl_offset:-1repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0
一主二从
# 一主[root@centos redisconfig]# cp redis.conf redis6379.conf# 二从[root@centos redisconfig]# cp redis.conf redis6380.conf[root@centos redisconfig]# cp redis.conf redis6381.conf
主机配置
主机可以读写,从机只可读
1)如果主服务器通过requirepass选项设置了密码,那么为了让从服务器的同步操作可以顺利进行,也必须为从服务器进行相应的身份验证设置。
2)config set masterauth 或者masterauth
port 6379pidfile /var/run/redis_6379.pidlogfile "6379.log"dbfilename dump6379.rdb
从机配置
1)配置从服务器,在配置文件中增加:slaveof 主服务器IP 端口
2)另一种方法是调用slaveof命令,输入主服务器的IP和端口,然后同步就会开始:slaveof host port(此种方式重启后会变为主机)
slaveof no one (成为新的主机)
1)从redis2.8开始,为了保证数据的安全性,可以通过配置,让主服务器只在有至少N个当前已连接从服务器的情况下,才执行写命令。
2)用户可以通过配置,指定网络延迟的最大值min-slaves-max-lag,以及执行写操作所需的至少从服务器数量min-slaves-to-write。
slaveof 127.0.0.1 6379 # 主机配置port 6380pidfile /var/run/redis_6380.pidlogfile "6380.log"dbfilename dump6380.rdbslaveof 127.0.0.1 6379 # 主机配置port 6381pidfile /var/run/redis_6381.pidlogfile "6381.log"dbfilename dump6381.rdb
启动
[root@centos bin]# ./redis-server ./redisconfig/redis6381.conf[root@centos bin]# ps -ef|grep redisroot 3357 1 0 21:53 ? 00:00:00 ./redis-server 127.0.0.1:6379root 3381 1 0 21:54 ? 00:00:00 ./redis-server 127.0.0.1:6380root 3397 1 0 21:54 ? 00:00:00 ./redis-server 127.0.0.1:6381
验证
启动从服务器,进入客户端,通过info replication命令可以查看redis服务的信息
# 主机role:masterconnected_slaves:2slave0:ip=127.0.0.1,port=6380,state=online,offset=140,lag=0slave1:ip=127.0.0.1,port=6381,state=online,offset=140,lag=0master_replid:aef75013d20bcea85a15ddc9141764e3450491f5master_replid2:0000000000000000000000000000000000000000master_repl_offset:140second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:140# 从机1role:slavemaster_host:127.0.0.1master_port:6379master_link_status:upmaster_last_io_seconds_ago:6master_sync_in_progress:0slave_repl_offset:210slave_priority:100slave_read_only:1connected_slaves:0master_replid:aef75013d20bcea85a15ddc9141764e3450491f5master_replid2:0000000000000000000000000000000000000000master_repl_offset:210second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:210# 从机2role:slavemaster_host:127.0.0.1master_port:6379master_link_status:upmaster_last_io_seconds_ago:9master_sync_in_progress:0slave_repl_offset:336slave_priority:100slave_read_only:1connected_slaves:0master_replid:aef75013d20bcea85a15ddc9141764e3450491f5master_replid2:0000000000000000000000000000000000000000master_repl_offset:336second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:29repl_backlog_histlen:308
master_link_status值为down,出现这个问题的原因有很多。
- 首先检查主服务器6379端口有没有对外开放,如果没有需要打开。
- 还需要编辑一下主服务器的配置文件 protected-mode yes
- 默认情况下这个值为yes,是保护模式,如果从机没有密码来访问主机,保护模式会阻止从机访问。先临时改成no
- bind 127.0.0.1
- 默认是只能这个IP来访问,可以临时注释掉或者改为0.0.0.0对所有IP开放
重启主机redis服务。此时通过命令查看从服务器状态可以发现master_link_status值为up
哨兵
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。

这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
单哨兵
# 添加sentinel.conf文件,内容如下sentinel monitor my 127.0.0.1 6379 1# 启动sentinel[root@centos bin]# ./redis-sentinel ./redisconfig/sentinel.confRunning in sentinel modePort: 26379PID: 3296########################################## 哨兵选举新master的过程 #################################### +monitor master my 127.0.0.1 6379 quorum 1* +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ my 127.0.0.1 6379* +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ my 127.0.0.1 6379# +sdown master my 127.0.0.1 6379# +odown master my 127.0.0.1 6379 #quorum 1/1# +new-epoch 1# +try-failover master my 127.0.0.1 6379# +vote-for-leader b0273f5dcb4da13110f32e830c75efe606b63bdd 1# +elected-leader master my 127.0.0.1 6379# +failover-state-select-slave master my 127.0.0.1 6379# +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ my 127.0.0.1 6379* +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ my 127.0.0.1 6379* +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ my 127.0.0.1 6379# +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ my 127.0.0.1 6379# +failover-state-reconf-slaves master my 127.0.0.1 6379* +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ my 127.0.0.1 6379* +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ my 127.0.0.1 6379* +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ my 127.0.0.1 6379# +failover-end master my 127.0.0.1 6379# +switch-master my 127.0.0.1 6379 127.0.0.1 6380* +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ my 127.0.0.1 6380* +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ my 127.0.0.1 6380# +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ my 127.0.0.1 6380
选举后,实质上修改了redis.conf文件,添加了replicaof 127.0.0.1 6380。
多哨兵
配置3个哨兵和1主2从的Redis服务器来演示这个过程。
| 服务类型 | 主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 127.0.0.1 | 6379 |
| Redis | 否 | 127.0.0.1 | 6380 |
| Redis | 否 | 127.0.0.1 | 6381 |
| Sentinel | - | 127.0.0.1 | 26379 |
| Sentinel | - | 127.0.0.1 | 26380 |
| Sentinel | - | 127.0.0.1 | 26381 |

多哨兵监控Redis
首先配置Redis的主从服务器,修改redis.conf文件如下
# 使得Redis服务器可以跨网络访问bind 0.0.0.0# 设置密码requirepass "123456"# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置slaveof 127.0.0.1 6379# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置masterauth 123456
上述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式protected-mode no# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。sentinel monitor mymaster 192.168.11.128 6379 2# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码# sentinel auth-pass <master-name> <password>sentinel auth-pass mymaster 123456
上述关闭了保护模式,便于测试。
有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程./redis-server ../redis.conf# 启动哨兵进程./redis-sentinel ../sentinel.conf
注意启动的顺序。首先是主机(192.168.11.128)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。
配置项
| 配置项 | 参数类型 | 作用 |
|---|---|---|
| port | 整数 | 启动哨兵进程端口 |
| dir | 文件夹目录 | 哨兵进程服务临时文件夹,默认为/tmp,要保证有可写入的权限 |
| sentinel down-after-milliseconds | <服务名称><毫秒数(整数)> | 指定哨兵在监控Redis服务时,当Redis服务在一个默认毫秒数内都无法回答时,单个哨兵认为的主观下线时间,默认为30000(30秒) |
| sentinel parallel-syncs | <服务名称><服务器数(整数)> | 指定可以有多少个Redis服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求越高 |
| sentinel failover-timeout | <服务名称><毫秒数(整数)> | 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟 |
| sentinel notification-script | <服务名称><脚本路径> | 指定sentinel检测到该监控的redis实例指向的实例异常时,调用的报警脚本。该配置项可选,比较常用 |
sentinel down-after-milliseconds配置项只是一个哨兵在超过规定时间依旧没有得到响应后,会自己认为主机不可用。对于其他哨兵而言,并不是这样认为。哨兵会记录这个消息,当拥有认为主观下线的哨兵达到sentinel monitor所配置的数量时,就会发起一次投票,进行failover,此时哨兵会重写Redis的哨兵配置文件,以适应新场景的需要。链接:https://www.jianshu.com/p/06ab9daf921d
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,接着查询数据库也无法查询出结果,因此也不会写入到缓存中,这将会导致每个查询都会去请求数据库,造成缓存穿透;
解决方案
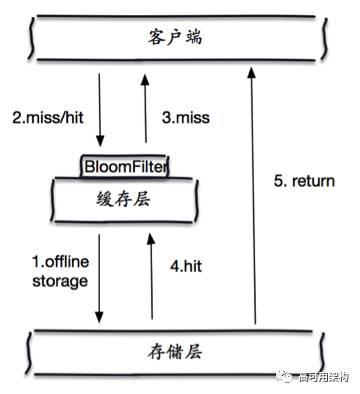
布隆过滤:对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
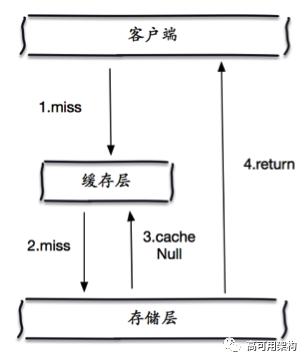
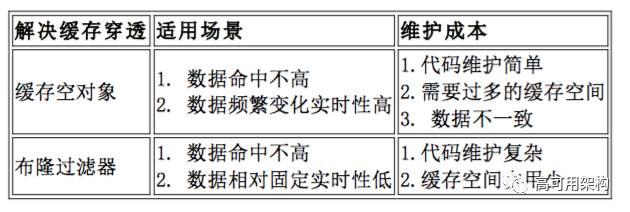
缓存空对象:当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在两个问题:
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存雪崩
缓存雪崩是指,由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
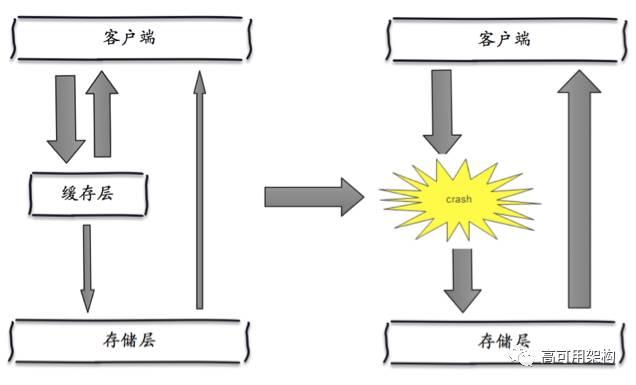
保证缓存层服务高可用性:即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,比如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
依赖隔离组件为后端限流并降级:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热:可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
缓存并发
缓存并发是指,高并发场景下同时大量查询过期的key值、最后查询数据库将缓存结果回写到缓存、造成数据库压力过大。
分布式锁:在缓存更新或者过期的情况下,先获取锁,在进行更新或者从数据库中获取数据后,再释放锁,需要一定的时间等待,就可以从缓存中继续获取数据。

若有收获,就点个赞吧
0 人点赞
