1. 简述
- 时间序列数据:从定义上来说,就是一串按时间维度索引的数据。
- 时序数据库(TSDB time-series database)特点:持续高并发写入、无更新;数据压缩存储;低查询延时。
- 常见 TSDB:influxdb、opentsdb、timeScaladb、Druid 等。
1.1 influxdb概念
- influxdb是一个开源分布式时序、时间和指标数据库,使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展,是 InfluxData 的核心产品。
- 应用:性能监控,应用程序指标,物联网传感器数据和实时分析等的后端存储。
- influxdb 完整的上下游产业还包括:Chronograf、Telegraf、Kapacitor,其具体作用及关系如下:
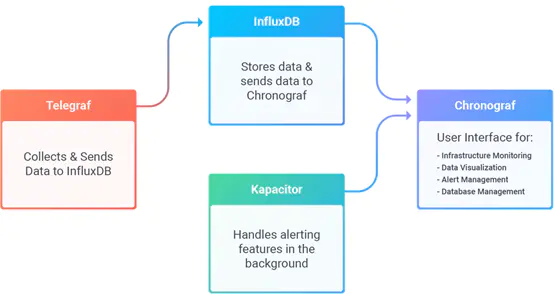
有些人也会选择 Telegraf (Heapster)+ influxdb + grafana组合。
1.2 与传统数据库相关区别
和传统数据库相比,influxdb在相关概念上有一定不同,具体如下: | influxdb 中的概念 | 传统数据库中的概念 | | :—-: | :—-: | | database | 数据库 | | measurement | 数据库中的表 | | point | 表中的一行数据 |
point的数据结构由时间戳(time)、标签(tags)、数据(fields)三部分组成,具体含义如下: | point 属性 | 含义 | | :—-: | :—-: | | time | 数据记录的时间,是主索引(自动生成) | | tags | 各种有索引的属性 | | fields | 各种value值(没有索引的属性) |
此外,influxdb还有个特有的概念:series(一般由:retention policy, measurement, tagset就共同组成),其含义如下:
所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。
- 需要注意的是,influxdb不需要像传统数据库一样创建各种表,其表的创建主要是通过第一次数据插入时自动创建,如下:
```sql — 自动创建表 insert mytest, server=serverA count=1,name=5
— mytest server 是 tags; count name 是 fields fields 中的 value 基本不用于索引
<a name="MaVUv"></a>#### 1.3 保留策略(retention policy)1. 每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,在集群中的副本个数为1,之后用户可以自己设置(查看、新建、修改、删除),例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。1. 每个数据库可以有多个过期策略:<br />```sqlshow retention policies on "db_name"
- Shard(分片、分区) 在 influxdb 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。 建议在数据库建立的时候设置存储策略,不建议设置过多且随意切换
create database testdb2 with duration 30d
1.4 存储引擎
1.4.1 存储引擎(Timestamp-Structure Merge Tree)
TSM是在LSM的基础上优化改善的,引入了serieskey的概念,对数据实现了很好的分类组织。TSM主要由四个部分组成: cache、wal、tsm file、compactor:
cache:插入数据时,先往 cache 中写入再写入wal中,可以认为 cache 是 wal 文件中的数据在内存中的缓存,cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB。
- wal:预写日志,对比MySQL的 binlog,其内容与内存中的 cache 相同,作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据,当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache。
- tsm file:每个 tsm 文件的大小上限是 2GB。当达到 cache-snapshot-memory-size,cache-max-memory-size 的限制时会触发将 cache 写入 tsm 文件。
compactor:主要进行两种操作,一种是 cache 数据达到阀值后,进行快照,生成一个新的 tsm 文件。另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,减少文件的数量,并且进行一些数据删除操作。 这些操作都在后台自动完成,一般每隔 1 秒会检查一次是否有需要压缩合并的数据。
1.4.2 存储目录
influxdb的数据存储有三个目录,分别是meta、wal、data:
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件;
- wal 目录存放预写日志文件,以 .wal 结尾;
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
1.5 相关特点
1) 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等);
2) 可度量性:你可以实时对大量数据进行计算;
3) 基于事件:它支持任意的事件数据;
4) 无结构(无模式):可以是任意数量的列;
5)支持min, max, sum, count, mean, median 等一系列函数;
6)内置http支持,使用http读写;
7)强大的类SQL语法;
8)自带管理界面,方便使用(新版本需要通过Chronograf)1.6 influxdb和其他时序数据库比较
从部署、集群、资源占用、存储模型、性能等方面比较influxdb和opentsdb,具体如下:
| 特性 | InfluxDB | OpentsDB |
|---|---|---|
| 单机部署 | 部署简单、无依赖 | 需要搭建 Hbase,创建 TSD 数据表,配置 JAVA 等 |
| 集群 | 开源版本没有集群功能 | 集群方案成熟 |
| 资源占用 | cpu 消耗更小,磁盘占用更小 | 资源消耗相比更多 |
| 存储模型 | TSM | 基于HBase存储时序数据(LSM) |
| 存储特点 | 同一数据源的tags不再冗余存储 ;列式存储,独立压缩 | 存在很多无用的字段;无法有效的压缩;聚合能力弱 |
| 性能 | 查询更快,数据汇聚分析较快 | 数据写入和存储较快,但查询和分析能力略有不足 |
| 开发 | 版本升级快,但架构简单,类SQL语言(InfluxQL)易开发 | API较为丰富,版本较为稳定 |
1.7 相关资料文档
- influxdb官网:https://www.influxdata.com/
相关API官网:https://docs.influxdata.com/influxdb/v1.7/
2. influxdb 访问
2.1 访问方式
influxdb访问本质上都是 HTTP 方式,具体有如下:
客户端命令行
- HTTP API 接口
- 各语言API 库(对 go 语言 API 封装)
-
2.2 连续查询
influxdb 的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT 等关键词。influxdb 会将查询结果放在指定的数据表中。
- 目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
CREATE CONTINUOUS QUERY wj_30m ON shhnwangjianBEGINSELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients)INTO redis_clients_30mFROM redis_clientsGROUP BY ip,port,time(30m)END-- 在shhnwangjian库中新建了一个名为 wj_30m 的连续查询,每三十分钟取一个connected_clients字段的平均值、中位值、最大值、最小值 redis_clients_30m 表中,使用的数据保留策略都是 default。
当数据超过保存策略里指定的时间之后就会被删除,但是这时候可能并不想数据被完全删掉,可以使用连续查询将数据聚合储存。
2.4 操作优化
- 控制 series 的数量;
- 使用批量写;
- 使用恰当的时间粒度;
- 存储的时候尽量对 Tag 进行排序;
- 根据数据情况,调整 shard 的 duration;
- 无关的数据写不同的database;
- 控制 Tag Key, 与 Tag Value 值的大小;
- 存储分离 ,将 wal 目录与 data 目录分别映射到不同的磁盘上,以减少读写操作的相互影响。
3. 安装
3.1 资源下载配置
InfluxDB、Telegraf、Chronograf、Kapacitor可到下方官网下载各平台版本
这里以Windows为例,说明一下环境搭建,使用Docker或者Linux下安装配置都基本一样
- 选择对应平台的influxdb:https://dl.influxdata.com/influxdb/releases/influxdb-1.7.6_windows_amd64.zip;
- 下载后解压,得到 influxd.exe、influx.exe、influxdb.conf 等文件,data、meta、wal 是自己建立的文件夹:
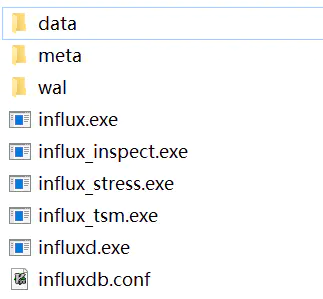
- influx.exe 表示客户端,influxd.exe 表示服务端,influx_inspect.exe 表示查看工具,influx_stress.exe 表示压力测试工具,influx_tsm 表示数据库转换工具(将数据库从 b1 或 bz1 格式转换为 tsm1 格式),influxdb.conf 是配置文件,我们需要修改该文件,主要是三个路径修改:
[meta]# Where the metadata/raft database is storeddir = "C:/Install/influxdb-1.7.6-1/meta"[data]# The directory where the TSM storage engine stores TSM files.#/var/lib/influxdb/datadir = "C:/Install/influxdb-1.7.6-1/data"# The directory where the TSM storage engine stores WAL files.#/var/lib/influxdb/walwal-dir = "C:/Install/influxdb-1.7.6-1/wal"
3.2 启动
- 启动服务端 influxd.exe;
打开客户端 influx.exe,可看到客户端也是 http 连接服务端,其端口在 conf 配置文件中
3.3 命令行操作
可通过SQL-like语言直接操作influxdb:
show databasesuse databaseshow measurements
需要注意的是,influxdb虽然很多时候都可以通过SQL语句操作,但数据更新例外。influxdb中数据更新只能重新Insert,且需要tags和时间戳相同,所以不建议大量更新数据。极少出现删除数据的情况,删除数据基本都是清理过期数据。
3.4 Web管理
Web管理需要下载Chronograf,解压后打开chronograf.exe,网页中输入:localhost:8888,即可打开网页;
- 网页中的数据显示需要配置才会有,这里简单示例一下,以读取系统内存和cpu使用情况为例:
下载Telegraf,启动命令行切换到对应目录,然后输入以下命令生成conf配置文件
telegraf -sample-config -input-filter cpu:mem -output-filter influxdb > telegraf1.conf
输入启动命令,打开 telegraf.exe,开始采集信息并输入到 influxdb
telegraf.ext --config telegraf1.conf
-
4.对常见关系型数据库(MySQL)的基础概念对比
| 概念 | MySQL | InfluxDB | | —- | —- | —- | | 数据库(同) | database | database | | 表(不同) | table | measurement | | 列(不同) | column | tag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
- tag set:不同的每组tag key和tag value的集合;
- field set:每组field key和field value的集合;
- retention policy:数据存储策略(默认策略为autogen)InfluxDB没有删除数据操作,规定数据的保留时间达到清除数据的目的;
- series:共同retention policy,measurement和tag set的集合;
- 示例数据如下: 其中 census 是 measurement,butterflies和honeybees是field key,location和scientist是tag key
name: census————————————time butterflies honeybees location scientist2015-08-18T00:00:00Z 12 23 1 langstroth2015-08-18T00:00:00Z 1 30 1 perpetua2015-08-18T00:06:00Z 11 28 1 langstroth2015-08-18T00:06:00Z 11 28 2 langstroth
4.1 注意点
- tag 只能为字符串类型
- field 类型无限制
- 不支持join
- 支持连续查询操作(汇总统计数据):CONTINUOUS QUERY
- 配合Telegraf服务(Telegraf可以监控系统CPU、内存、网络等数据)
- 配合Grafana服务(数据展现的图像界面,将influxdb中的数据可视化)
4.2 常用InfluxQL
```sql — 查看所有的数据库 show databases;
— 使用特定的数据库 use database_name;
— 查看所有的measurement show measurements;
— 查询10条数据 select * from measurement_name limit 10;
— 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式 precision rfc3339; — 之后再查询,时间就是rfc3339标准格式
— 或可以在连接数据库的时候,直接带该参数 influx -precision rfc3339
— 查看一个measurement中所有的tag key show tag keys
— 查看一个measurement中所有的field key show field keys
— 查看一个measurement中所有的保存策略(可以有多个,一个标识为default) show retention policies; ```

若有收获,就点个赞吧
0 人点赞
