在看 HashMap 源码时,注意到一个问题,容量必须是 2 的整数幂,为了保证这一点,专门给出了一个巧妙而高效的方法 tableSizeFor。不妨想一下,如果是自己解决这个问题,该怎么解决?
给定一个 int 类型的整数 n,如何求出不小于它的最接近的 2 的整数幂 m,比如给定 10 得出 16,给定 25 得出 32?
普通人的简单粗暴方式
普通人的想法可能比较简单,直接对 n 求以 2 为底的对数,结果 m 是 double 类型,若小数部分为 0,则 m 就是我们要求的指数;小数部分不为 0,则对 m 向上取整,最后直接求 2 的 m 次幂。
首先遇到的问题是 jdk 没有提供对 2 求对数的数学公式,只有对自然对数 e 求对数的公式Math.log(double a)。
好在我们可以用对数的换底公式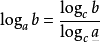
示例代码
public static int fun(int n) {double m = Math.log(n) / Math.log(2);int m2 = (int) Math.ceil(m);return (int) Math.pow(2, m2);}
不考虑是否有精度损失,上述代码很简洁,只有三步,求对数 + 取整 + 求指数。
问题
回顾 HashMap 中的需求我们知道,这个方法属于很基础的方法,将在初始化或者添加时被大量执行,这就要求方法本身一定要高效。
这里虽然代码简洁,但调用的方法细看的话代码还是很多的,而且涉及到的运算,比如对数,指数,除运算,取整,强制类型转换,都是比较高级的,必然依靠大量的底层简单操作实现。
一个程序运行的时间除了和环境比如时钟周期的长度和每条指令的平均时钟周期数有关外,还和指令数有关。感性的认识也能告诉我们,上述代码的实际执行的最终指令一定不会少。
我们之所有要用这个方法转换为 2 的幂,是为了减少哈希冲突,提高存取效率,结果这个方法本身严重影响了效率,岂不是拣了芝麻丢了西瓜?
大神的实现
我们不妨看看 HashMap 的作者是如何实现的。
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
第一行很简单,为什么要 - 1 放在最后说,最后一行是两个三目运算符,其中之一操作是 n+1,都很容易理解。关键是中间五步移位加上或运算。
移位的思想
说一下我理解的作者的思想:
2 的整数幂用二进制表示都是最高有效位为 1,其余全是 0,比如十进制 8 和 32,下图只用了一个字节示意。 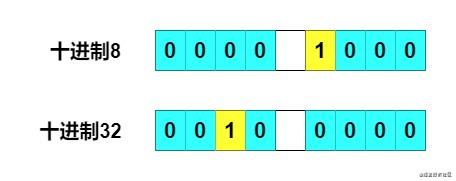
对任意十进制数转换为 2 的整数幂,结果是这个数本身的最高有效位的前一位变成 1,最高有效位以及其后的位都变为 0。
核心思想是,先将最高有效位以及其后的位都变为 1,最后再 + 1,就进位到前一位变成 1,其后所有的满 2 变 0。所以关键是如何将最高有效位后面都变为 1。
还是用图来示意。这里将十进制的 25 转换为 32。
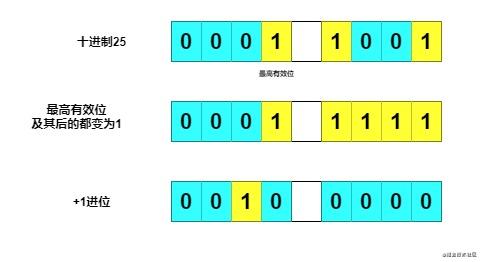
作者的做法是先移位,再或运算。
右移一位,再或运算,就有两位变为 1; 右移两位,再或运算,就有四位变为 1,,, 最后右移 16 位再或运算,保证 32 位的 int 类型整数最高有效位之后的位都能变为 1.
全过程示意图
自己觉得理解了,但是感觉文章写出来很绕,估计看到这里的你也有这种感觉。这里对整个过程画图示意。
初始值
选取任意 int 类型数字,下图 x 表示不确定 0 或者 1.
 我们目的是将所有的 x 变为 1,如下图
我们目的是将所有的 x 变为 1,如下图
 最后 + 1,就能进位得到 2 的整数幂。
最后 + 1,就能进位得到 2 的整数幂。

我们要做的就是不断通过右移 + 或运算来达到目的。
右移一位 + 或运算
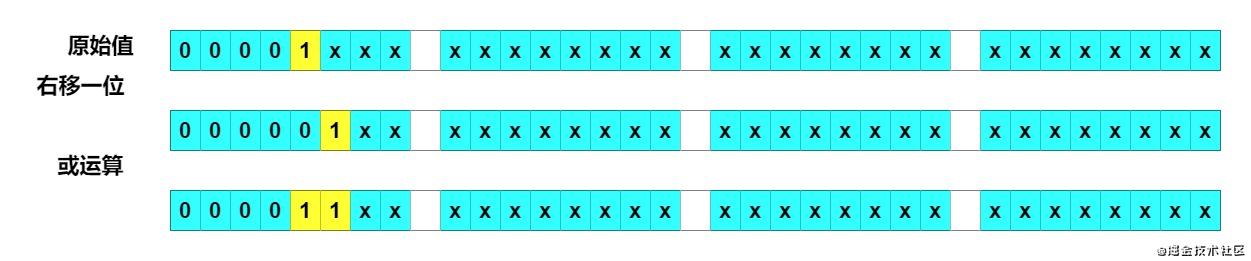
可以看出,右移一位再或运算,有两位变成了 1。
右移二位 + 或运算
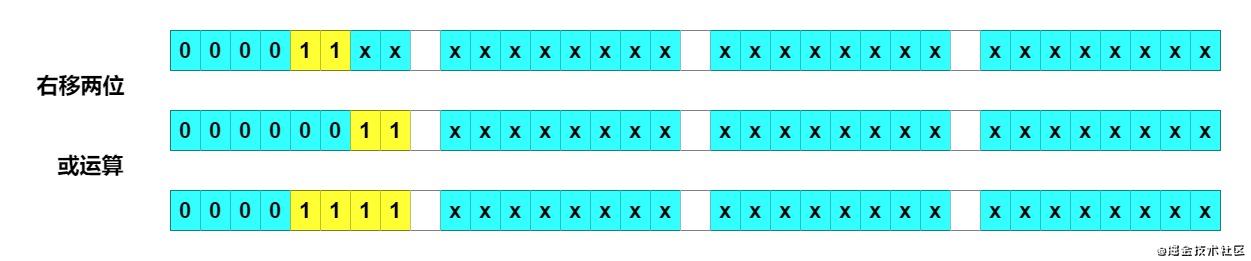
右移两位再或运算,有四位变成了 1。
右移四位 + 或运算
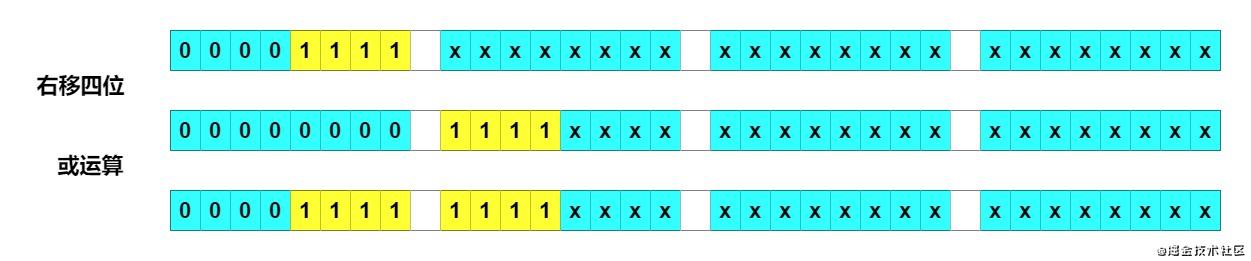
右移四位再或运算,有八位变成了 1。
右移八位 + 或运算
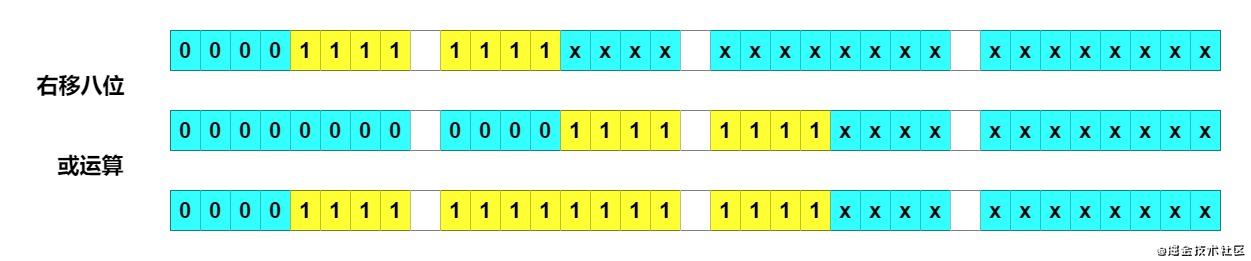
右移八位再或运算,有十六位变成了 1。
右移十六位 + 或运算
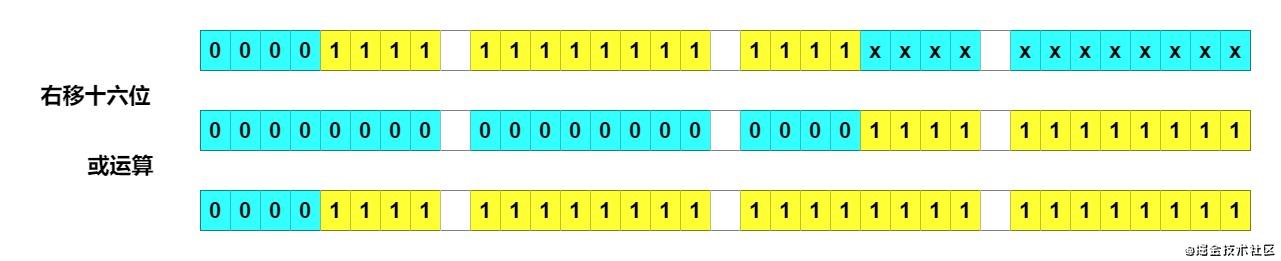
右移十六位再或运算,注意这里不是三十二位全变,而是最高位后面的全变 1。
结果 + 1

可以看出,不管 x 是多少,我们都能将其转换为 1。而且分别经过 1,2,4,8,16 次转换,不管这个 int 类型值多大,我们都会将其转换,只是值较小时,可能多做几次无意义操作。
初始容量 - 1
之所以在开始移位前先将容量 - 1,是为了避免给定容量已经是 8,16 这样 2 的幂时,不减一直接移位会导致得到的结果比预期大。比如预期 16 得到应该是 16,直接移位的话会得到 32。在上图中就是所有 x 本身已经是 0 的情况下,不减 1 得到的结果变大了。
总结
回到一开始的问题,这个方法之所以高效,是因为移位运算和或运算都属于比较底层的操作,代码的数量不会比最终的指令数多,也就是通过几个简单操作实现了我们的目的。
为啥要专门写一篇文章来解释这个方法,是因为在看这个方法的时候,意识到了一些原本不太在意的问题。通过这个方法,就理解了为啥学计算机要学一些基础的知识,比如二进制的操作,逻辑运算等等,以及为啥一些高级的算法看起来都在处理简单的问题。如果单纯学习可能觉得枯燥,但实际上它们都是有大用处的。平时可能看不出来,在一些关键的细节就看出普通人和大神的区别了。
要学的还有很多!
https://juejin.cn/post/6935828891546157093
转自掘金社区 https://juejin.cn/post/6935828891546157093

若有收获,就点个赞吧
0 人点赞
