1. 关键字和保留字
- 关键字:被Java语言赋予了特殊含义,用做专门用途的字符串或单词。关键字中所有字母都是小写。
- 保留字:goto和const
2. 标识符
- 定义:方法、变量、类名、接口名、包名、属性名……凡是自己可以起名字的地方都叫标识符。
- 标识符命名规则:如果不遵循编译不通过
- 由26个英文字母大小写,0-9,_或$组成。
- 数字不可以开头。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- java中严格区分大小写,长度无限制。
- 标识符不能包含空格。
- 标识符命名规范:如果不遵循也可以编译通过,但是建议遵守,且命名尽量见名知意
- 包名:所有字母都小写,多单词组成所有单词都小写
- 类名:大驼峰,多单词组成,所有单词的首字母大写
- 变量名:小驼峰,多单词组成时,第一个单词首字母小写,第二单词开始每个单词首字母大写
- 方法名:小驼峰,多单词组成时,第一个单词首字母小写,第二单词开始每个单词首字母大写
- 常量名:单词之间下划线分割,所有字母都大写,多单词时,每个单词用下划线连接
3. 变量
- 定义变量:变量数据类型变量名 = 变量存储值;
- 注意:
- 变量必须先声明后使用。
- 变量有一定的作用域,在作用域内才能使用,出了作用域就失效了。
- 同一个作用域内,不能定义重名的变量。
- 变量的分类:成员变量与局部变量
- 成员变量:在方法体外,类体内声明的变量,即属性。包括不以static修饰的实例变量、以static修饰的类变量。
- 局部变量:形参(方法、构造器中定义的变量)、方法局部变量(在方法体内部声明的变量)、代码块局部变量(在代码块内定义)
- 成员变量(属性)和局部变量的区别:
- 声明的位置:成员变量直接声明在类中;局部变量声明在方法形参或内部、代码块内、构造器内等
- 成员变量可以用private、public、static、final等权限修饰符修饰;局部变量不能用权限修饰符修饰,可以用final修饰
- 初始化值:成员变量有默认初始化值,byte 0、short 0、int 0、long 0L、float 0.0F、double 0.0、char 0或写为: ‘\u0000’ (表现为空)、boolean false、引用类型 null;局部变量没有默认初始化值,除形参外,均需显式初始化赋值,方可使用
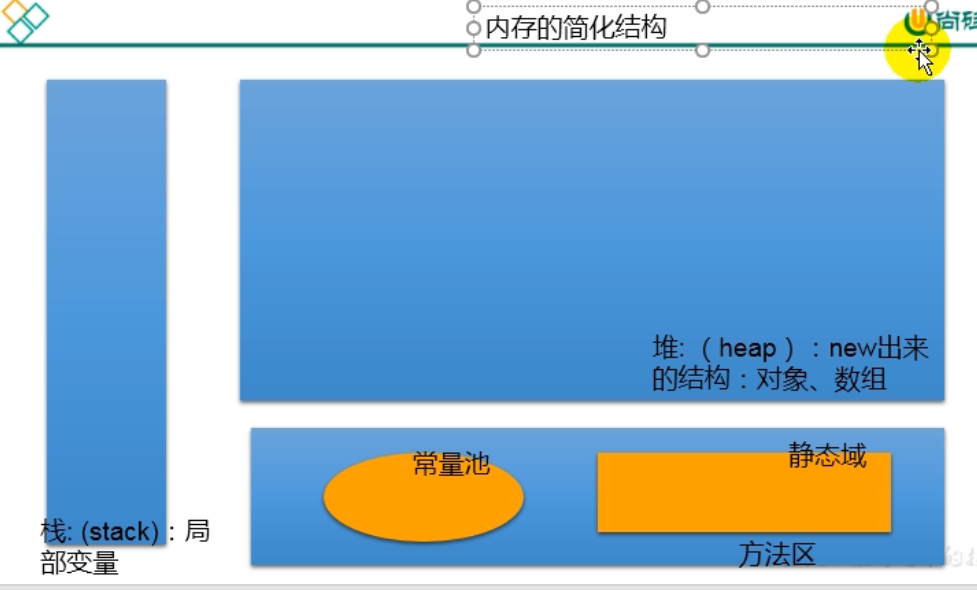
- 内存加载位置:成员变量在堆空间(非static的属性)或静态域内(static的属性);局部变量在栈空间
4. 数据类型
基本数据类型
- 整型:
- byte、short、int、long(声明要加字母L)
- 数值范围:byte(1字节):-128~+127 因为1byte=8bit=可以表示2的8次方个数,分成两半就是2的7次方;short:2字节;int:4字节 在java中整型的常量,默认类型是:int型;long:8字节
- 浮点型:
- float(4字节)、double(8字节)
- 范围:float:尾数可以精确到7位有效数字,double精度是float的两倍。
- 注意:定义float类型变量时,变量要以”f”或”F”结尾,因为Java 的浮点型常量默认为double型,声明float型常量,须后加f或F。不然会编译出错
- 字符型:
- char(一个字符=2字节),通常使用一对单引号来定义一个字符型变量。且引号内部只能写一个字符。里面可以放数字,中文,转义字符。表示方式:1、声明一个字符。2、转义字符3、直接使用Unicode值来表示字符型常量。
- boolean类型:只能取值:true、false
基本数据类型之间的运算规则
- 自动类型提升:当容量小的数据类型的变量与容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型。byte 、 short 、 char —> int —> long —> float —> double(说明:此时容量大小指的是,表示数的范围的大和小,跟占据的字节大小没有关系。比如:float容量要大于long的容量,但是float是4字节,而long是8字节)。特别地:当byte,char、short三种类型的变量做运算时,结果都是int类型,包括本身之间做运算
- 强制类型转换:自动类型提升运算的逆运算(容量大的转换成容量小的)。需要使用强转符()。强制类型转换,可能导致精度损失
引用数据类型
- 字符串类型String
- String属于引用型数据类型
- 声明String类型变量时,使用一对双引号””
- String可以和8种基本数据类型做运算,且运算只能是连接运算。
- 运算的结果仍然是String类型
- 字符串不能直接转换为基本类型,但通过基本类型对应的包装类则可以实现把字符串转换成基本类型
5. 运算符
- 算术运算符(+ - * / 前++ 后++ 前— 后— +)
- 取余运算(%):取模运算的结果的符号与被模数的符号相同。
- (前++):先自增1,然后再做运算。不会改变本身的数据类型。例如:short s1 = 10; s1++;//正确,且s1还是short类型。但是short s1 = 10;s1 = s1 + 1;//编译出错,因为s1+1之后是int类型了,需要做强制转换才可以。
- (后++):先运算,后自增1。不会改变本身的数据类型。
- (前—):同上
- (后—):同上
- -(连接运算符):前面讲过,只能用于String类型和String类型或String类型和其他数据类型之间。
- 赋值运算符(=、+=、-+、*=、/=、%=)
- 区别(==)
- 可以连续赋值,例如:int i2, j2; i2=j2=10;
- +=、-=、/=、%=运算的结果不会改变变量本身的数据类型。例如:short s1 = 10;s1 = s1 + 2;//编译失败,但是s1 += 2;//编译通过
- 比较运算符(关系运算符):==、!=、<、>、<=、>=、instanceof
- 比较运算符的结果都是boolean类型。
- 区分==和=
- instanceof:检查是否是类的对象
- ‘>’、<、>=、<= 只能使用在数值类型的数据之间
- !=、==不仅可以使用在数值爱类型数据之间,还可以使用在其他引用类型变量之间。
- 逻辑运算符:&(逻辑与)、&&(短路与)、|(逻辑或)、||(短路或)、!(逻辑非)、^(逻辑异或)
- 逻辑运算符操作的都是boolean类型的变量。而且结果也是boolean类型
- 区分&和&&:相同点1是当符号左边是true时,二者都会执行符号右边的运算。相同点2是它们的运算结果都是相同的。不同点是当符号左边是false时,&继续执行符号右边的运算,而&&不再执行符号右边的运算。开发中推荐使用短路与
- 区分|和||:相同点1:当符号左边是false时,二者都会执行符号右边的运算。相同点2是它们的运算结果是相同的。不同点是当符号左边是true时,|继续执行符号右边的运算,而||不再执行符号右边的运算。开发中推荐使用短路或
- 位运算符:<<(左移)、>>(右移)、>>>(无符号右移)、&(与运算)、|(或运算)、^(异或运算)、~(取反运算)
- 注意没有<<<
- 位运算操作的都是整型数据,是直接对整数的二进制进行的运算。
- <<(左移):在一定范围内每向左移一位,都乘2。
- ‘>>’(右移):在一定范围内每向右一位,都除以2。
- 面试题:最高效方式计算2*8?答:2<<3
- 典型题目1、交换两个变量的值
- 典型题目2、实现60的二进制到十六进制的转换。
- 三元运算符
- 结构:(条件表达式) ? 表达式1 : 表达式2
- 说明
- 条件表达式的结果为boolean类型。
- 根据条件表达式真或假,决定执行表达式1,还是表达式2。如果表达式为true,则执行表达式1.如果表达式为false,则执行表达式2。
- 三元运算符可以嵌套使用
- 凡是可以用三元运算符的地方,都可以改成if else,反之不成立。
- 如果程序既可以使用三元运算符,又可以使用if-else结构,那么优先选择三元运算符。原因:简洁,执行效率高。
- 运算符的优先级
6. 流程控制
顺序结构
分支结构
- if-else结构
- 针对于条件表达式:如果多个条件表达式之间是“互斥”关系(或没有交集的关系),哪个判断和执行语句声明在上面还是下面,无所谓。
- 如果多个表达式之间有交集的关系,需要根据实际情况,考虑清楚应该将哪个结构声明在上面。
- 如果多个表达式之间有包含的关系,通常情况下,需要将范围小的声明在范围大的上面,否则,范围小的就没机会执行。 ```java //第一种格式 if(条件表达式){ 执行代码块; }
//第二种格式:二选一 if(条件表达式){ 执行代码块1; }else{ 执行代码块2; }
//第三种格式:多选一 if(条件表达式1){ 执行代码块1; }else if(条件表达式2){ 执行代码块2; }else if(条件表达式3){ 执行代码块3; } … else{ 执行代码块n; }
- switch-case语句- 根据switch表达式的值,依次匹配各个case中的常量。一旦匹配成功,则进入相应case结构中,调用其执行语句。**当调用完执行语句以后,则仍然继续向下执行其他case结构中的执行语句。 直到遇到break关键字或此switch-case结构末尾结束为止**。- switch结构中的表达式,只能是如下的6种数据类型之一:byte、short、char、int、枚举类型(JDK5.0新增的)、String类型(JDK7.0新增的)。- case之后只能声明常量,不能声明范围。- break,可以使用在switch-case结构中,表示一旦执行到此关键字,就跳出switch-case结构。- break语句在switch-case结构中是可选的,不是必须的。- default:相当于if-else中的else。default结构也是可选的。而且位置可以随便放,但是建议放最后面。- 如果switch-case结构中的多个case的执行语句相同,则可以考虑进行合并。- 凡是可以使用switch-case的结构,都可以转换为if-else,反之,不成立。- 我们写分支结构时,当发现既可以使用switch-case,(同时,switch中表达式的取值情况不太多),又可以使用if-else时,我们优先选择使用switch-case。原因:switch-case执行效率稍高。```javaswitch(表达式){case 常量1:执行语句1;//break;case 常量2:执行语句2;//break;...default:执行语句n;//break;}
- 循环结构
- 循环语句的4个组成部分
(1)初始化部分
(2)循环条件部分:是boolean类型
(3)循环体部分
(4)迭代部分
- for循环
- 结构:
- while循环
- 结构:
- for循环和while循环是可以相互转换的。区别就是for循环和while循环的初始化条件部分的作用范围不同。
- do-while循环
- 结构:
- 说明:do-while循环至少会执行一次循环体。
- 不在循环条件部分限制次数的结构
- for(;;)或while(true)
- 结束循环有几种方式?
- 方式一:循环条件部分返回false
- 方式二:在循环体中,执行break
嵌套循环
- 练习输出九九乘法表
练习输入100以内的质数(2是最小的质数),质数(素数),只能被1和它本身整除的自然数。(面试题)
//获取开始时间的毫秒数long startTime1 = System.currentTimeMillis();int count1 = 0;//方式一for(int i=2; i <= 500000; i++) {boolean isFlag = true;//标识i是否被除尽,一旦被除尽,修改其值。for(int j=2; j < i; j++) {if(i % j == 0) {isFlag = false;}}if(isFlag == true) {count1++;System.out.println(i);}//重置isFlagisFlag = true;}//获取结束时间的毫秒数long endTime1 = System.currentTimeMillis();System.out.println("所花费时间为:"+(endTime1-startTime1));System.out.println("质数的个数是:"+count1);//获取开始时间的毫秒数long startTime2 = System.currentTimeMillis();int count2 = 0;//质数输出的优化方式一for(int i=2; i <= 500000; i++) {boolean isFlag = true;//标识i是否被除尽,一旦被除尽,修改其值。for(int j=2; j < i; j++) {if(i % j == 0) {isFlag = false;break;//优化一:只对本身非质数的自然数是有效的。}}if(isFlag == true) {count2++;System.out.println(i);}//重置isFlagisFlag = true;}//获取结束时间的毫秒数long endTime2 = System.currentTimeMillis();System.out.println("所花费时间为:"+(endTime2-startTime2));System.out.println("质数的个数是:"+count2);//质数输出的优化方式二//获取开始时间的毫秒数long startTime3 = System.currentTimeMillis();int count3 = 0;//用于记录质数的个数for(int i=2; i <= 500000; i++) {boolean isFlag = true;//标识i是否被除尽,一旦被除尽,修改其值。for(int j=2; j <= Math.sqrt(i); j++) { //优化方式二:针对本身质数和非质数的自然数都有效,等号不能少if(i % j == 0) {isFlag = false;break;//优化一:只对本身非质数的自然数是有效的。}}if(isFlag == true) {System.out.println(i);count3++;}//重置isFlagisFlag = true;}//获取结束时间的毫秒数long endTime3 = System.currentTimeMillis();System.out.println("所花费时间为:"+(endTime3-startTime3));System.out.println("质数的个数是:"+count3);//质数输出方式优化三int count4 = 0;//用于记录质数的个数label:for(int i=2; i <= 500000; i++) {for(int j=2; j <= Math.sqrt(i); j++) { //优化方式二:针对本身质数和非质数的自然数都有效if(i % j == 0) {continue label;}}count4++;}System.out.println("质数的个数是:"+count4);
- System类的currentTimeMills方法获取当前时间的Long型时间
- break关键字和continue关键字的使用
区别:1、使用范围不同:break可以使用在switch-case和循环结构中,而continue只能使用在循环结构中。2、break表示结束当前循环,continue表示结束当次循环。相同点:break和continue后面不能声明执行语句,不然会编译不通过。
- break默认跳出包裹此关键字最近的一层循环。
- 带标签的break和continue的使用。
- return:并非专门用于结束循环的,他的功能是结束一个方法,当一个方法执行到一个return语句时,这个方法将被结束。与break和continue不同的是,return直接结束整个方法,不管这个return处于多少层循环之内。
7. 数组
7.1 数组基础
数组概述:
- 数组属于引用数据类型的变量,数组中的元素的类型可以是基本数据类型,也可以使引用数据类型。
- 创建数组对象会在内存中开辟一整块连续的空间。
- 数组一旦初始化完成,其长度就确定了的,就不可修改。
数组的分类:
- 按照维数:一维、二维、….、多维
- 按照数组元素的类型:基本数据类型元素的数组、引用数据类型元素的数组。
数组使用中常见的异常
- 数组角标越界的异常:ArrayIndexOuttOfBoundsException
- 空指针异常:NullPointerException
7.2 数组使用
一维数组的使用:
- 如何调用数组的指定位置的元素:通过角标的方式调用,java中的角标从0开始。
- 如何获取数组的长度:属性 length
- 数组元素的默认初始值
- 数组元素是整型:0
- 数组元素是浮点型:0.0
- 数组元素是boolean类型:false
- 数组元素是char类型:是0不是’0’,是ASCII码为0。或者是’\u0000’
- 数组元素是引用数据类型时:null
int[] ids;//声明//静态初始化:数组的初始化和数组元素的赋值操作同时进行。ids = new int[]{1001,1002,1003,1004};//动态初始化:数组的初始化和数组元素的赋值操作分开进行。String[] names = new String[5];//也是正确的写法int[] arr4 = {1,2,3,4,5};//类型推断:注意第3行的情况不可以省,要放在同一行才可以。int a[] = new int[3];int b[] = new int[]{1,2,3};//错误写法:总结:就是前面的中括号不能有值,后面的中括号和大括号不能同时有值int[] arr1 = new int[];int[5] arr2 = new int[5];int[] arr3 = new int[2]{1,2,3};//遍历数组for(int i = 0; i < names.length; i++){System.out.println(names[i]);}
数组的内存解析
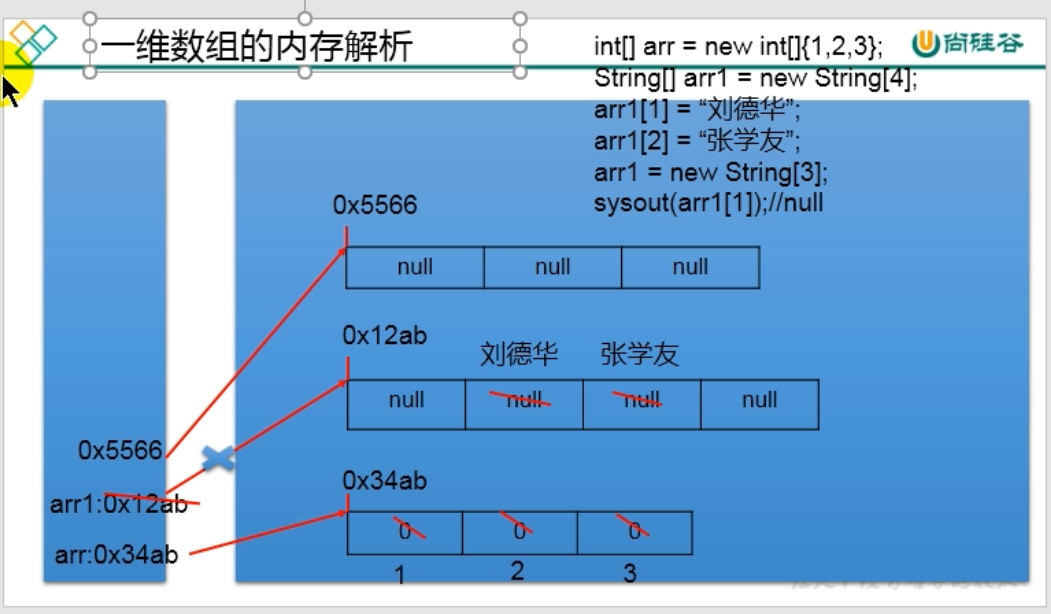
二维数组的使用:
- 概念:对于二维数组的理解,我们可以看成是一维数组array1又作为另一个一维数组array2的元素而存在。
- 数组属于引用数据类型,数组的元素也可以使引用数据类型,一个一维数组A的元素如果还是一个一维数组类型的,则,此数组A称为二维数组。
二维数组的声明和初始化
int[] arr = new int[]{1,2,3};//一维数组//静态初始化int[][] arr1 = new int[][]{{1,2,3},{4,5},{6,7,8}};//动态初始化1String[][] arr2 = new String[3][2];//动态初始化2String[][] arr3 = new String[3][];//也是正确的int[] arr4[] = new int[][]{{1,2,3},{4,5},{6,7,8}};int[] arr5[] = {{1,2,3},{4,5},{6,7,8}};int a[][] = new int[4][4];int b[][] = new int[][]{{1,2,3},{4,5,6},{7,8,9}};int c[][] = new int[4][];//错误情况String[][] arr4 = new String[][4];String[4][3] arr5 = new String[][];int[][] arr6 = new int[4][3]{{1,2,3},{4,5},{6,7,8}};
二维数组元素的调用
- 获取数组的长度
- 如何遍历二维数组:嵌套for循环
数组元素的默认初始化值
//二维数组的使用//规定:二维数组分为外层数组元素,内层数组的元素int[][] arr = new int[4][3];外层元素:arr[0],arr[1]等内层元素:arr[0][0],arr[1][2]等public class ArrayTest3 {public static void main(String[] args){int[][] arr = new int[4][3];System.out.println(arr[0])//[I@6d06d69c 16进制的地址值System.out.println(arr[0][0]);//0System.out.println(arr);//[[I@6d06d69c 16进制的地址值double[][] arr3 = new double[4][];System.out.println(arr3[1]);//nullSystem.out.println(arr3[1][0]);//空指针异常}}总结:针对于初始化方式一:比如如:int[][] arr = new int[4][3];外层元素的初始化值为:地址值内层元素的初始化值为:与一维数组初始化情况相同针对于初始化方式二:比如:int[][] arr = new int[4][];外层元素的初始化值为:null内层元素的初始化值为:不能调用,否则报错。
二维数组的内存结构
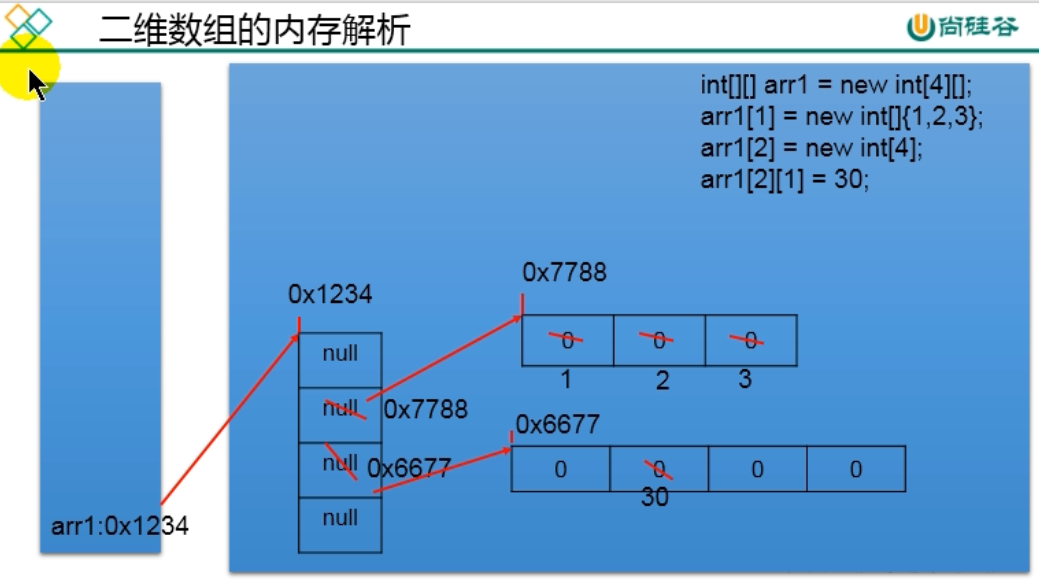
引用类型的变量,存储的值就两种情况,要么是地址值,要么是null;
7.3 数组中涉及到的常见算法
数组元素的赋值(杨辉三角、回形数等)
- 获取一个两位数的随机数
(int)(Math.random()*(99 - 10 + 1) + 10)
- 获取一个两位数的随机数
- 求数值型数组中元素的最大值、最小值、平均数、总和等
- 求最大值,最小值的注意点:数组第一个元素复制给maxValue,以防数组中有0的时候的情况。
- 数组的复制、反转、查找(线性查找、二分查找)
- 注意数组反转的循环条件i < arr.length/2,有两种方法
//数组的反转方式一for(int i = 0; i < a.length/2; i++) { //极其容易弄错成i < a.length;int temp = a[i];a[i] = a[a.length-i-1];a[a.length-i-1] = temp;}//数组反转方式二for(int i = 0, int j = a.length-1; i < j; i++, j--){int temp = a[i];a[i] = a[j];a[j] = temp;}
- 注意数组反转的循环条件i < arr.length/2,有两种方法
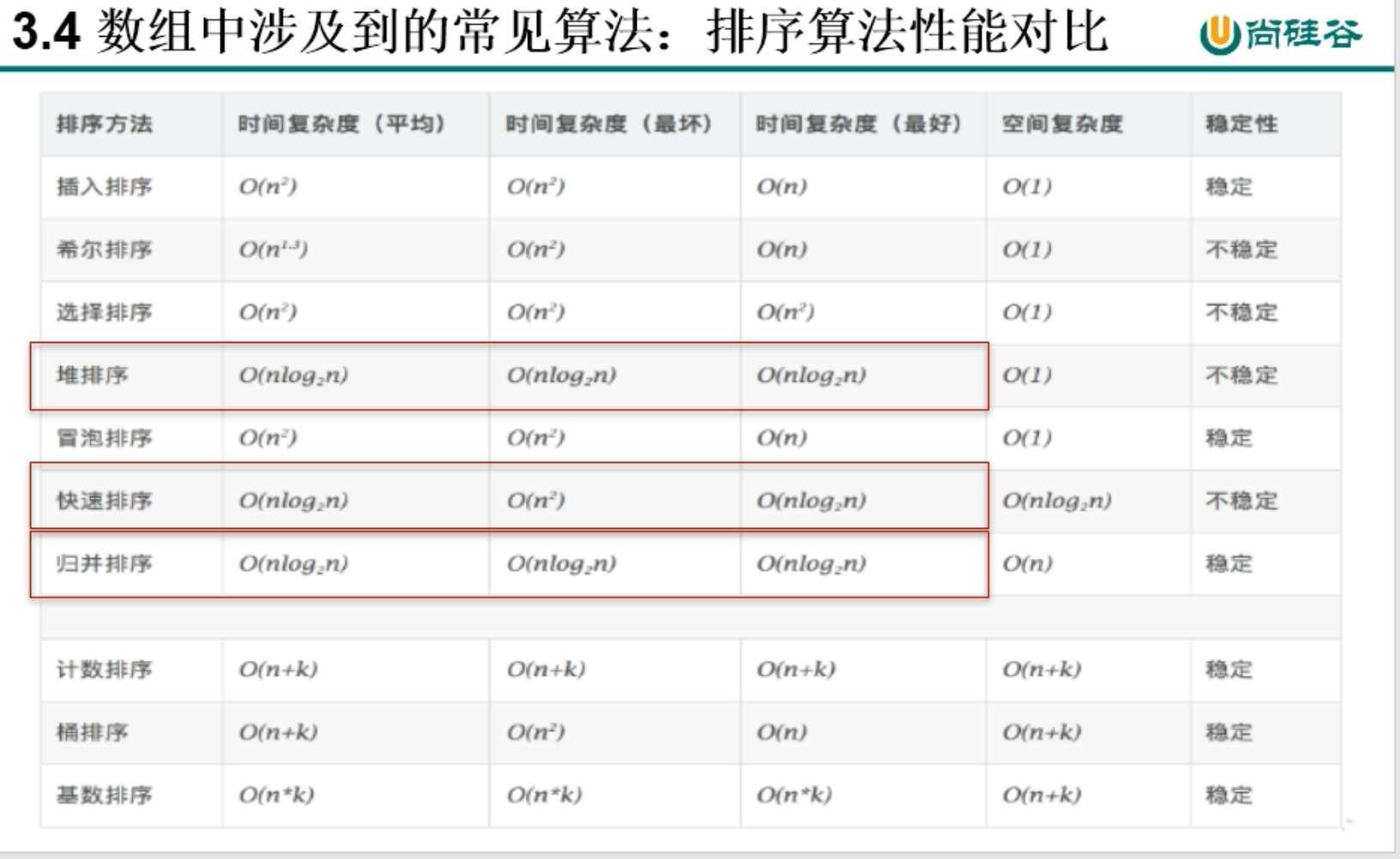
- 二分查找的前提是所查找的数组必须有序(递归实现和非递归实现),java.util.Arrays源码用的是非递归实现
//二分查找方式一:用非递归方式实现二分查找public static int binarySearch1(int[] a, int dest) {int low = 0;int high = a.length-1;while(low <= high) {int mid = (low + high)/2;if(a[mid] == dest) {return mid;//返回dest在数字a中的数组下标}else if(dest > a[mid]) {low = mid + 1;}else if(dest < a[mid]) {high = mid - 1;}}return -1;//没有找到返回-1}//二分查找方式二:用递归方式实现二分查找public static int binarySearch2(int[] a, int low, int high, int dest) {//if(dest < a[low] || dest > a[high]) {// return -1;//}if(low > high){return -1;}int mid = (low+high)/2;if(dest > a[mid]) {return binarySearch2(a, mid + 1, high, dest);}else if(dest < a[mid]) {return binarySearch2(a, low, mid - 1, dest);}else {return mid;}}




若有收获,就点个赞吧
0 人点赞
