- 柱状图中最大的矩形">84. 柱状图中最大的矩形
- 最大矩形">85. 最大矩形
- 分隔链表">86. 分隔链表
- 扰乱字符串">87. 扰乱字符串
- 合并两个有序数组">88. 合并两个有序数组
- 格雷编码">89. 格雷编码
- 子集 II">90. 子集 II
- 解码方法">91. 解码方法
- 反转链表 II">92. 反转链表 II
- 复原 IP 地址">93. 复原 IP 地址
- 二叉树的中序遍历">94. 二叉树的中序遍历
- 不同的二叉搜索树 II">95. 不同的二叉搜索树 II
- 不同的二叉搜索树">96. 不同的二叉搜索树
- 交错字符串">97. 交错字符串
- 验证二叉搜索树">98. 验证二叉搜索树
- 恢复二叉搜索树">99. 恢复二叉搜索树
- 相同的树">100. 相同的树
84. 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图中,能够勾勒出来的矩形的最大面积。
输入:heights = [2,1,5,6,2,3] 输出:10 解释:最大的矩形为图中红色区域,面积为 10
- 分治法:先找到数组中最小高度的整数,将其分成两部分,分别求两个数组里面的最大面积和当前数组 * 最小高度 得到的面积进行比较,得到最大值
- 当数组中最小和最大值一样的时候,可以直接返回矩形面积
单调栈:对每个整数,只要找到它左边第一个小于它的整数以及右边第一个小于它的整数,就可以计算出以这个整数为中心的矩形的最大面积,因此只要计算出每个整数左右两边第一个小于它的整数,就可以遍历一次得到最大的矩形面积
- 找到每一个整数右边第一个小于它的整数位置:
- 维护一个单调栈,栈里面存放这整数的位置,保证栈里面的所有整数依次增长
- 从右向左遍历,则判断当前遍历的值,是否小于栈顶值,如果小于它,弹出栈顶值,直到该值大于栈顶值(这里可以给栈维护一个哨兵值,可以设置为-1,保证最小)
- 此时可以设置该位置上的右边第一个小于它的整数,就是栈顶值(如果是哨兵值,其实就是没有小于它的整数)
- 此时就可以在
O(n)时间内完成计算(栈里面的数据出栈的时候,其实可以认为出栈的位置左边第一个小于它的位置就是遍历的位置,这样只要一次遍历就可以完成左右最小值的计算)85. 最大矩形
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
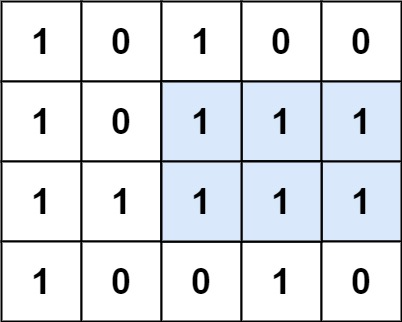 输入:matrix = [[“1”,”0”,”1”,”0”,”0”],[“1”,”0”,”1”,”1”,”1”],[“1”,”1”,”1”,”1”,”1”],[“1”,”0”,”0”,”1”,”0”]]
输出:6
解释:最大矩形如上图所示。
输入:matrix = [[“1”,”0”,”1”,”0”,”0”],[“1”,”0”,”1”,”1”,”1”],[“1”,”1”,”1”,”1”,”1”],[“1”,”0”,”0”,”1”,”0”]]
输出:6
解释:最大矩形如上图所示。
- 找到每一个整数右边第一个小于它的整数位置:
维护一个二维数组,里面的值为以该位置为终点,该行连续的包含 1 的个数,此时求解最大矩形的问题,就变成了每一列上面计算 问题 84 上的最大矩形
将每一行连续的 1,抽象为一条边,因此通过遍历一次,就可以得到每一行上的边了,这样遍历每一行上的每条边,寻找以这条边为顶的矩形的最大面积
- 寻找的时候记录长度,遍历下一行的所有边,如果两条边直接存在交集关系,那么找出交集的边,继续向下遍历
- 此时可以取得当前宽度和长度的最大值和递归的值进行比较
86. 分隔链表
给你一个链表的头节点 head 和一个特定值_ _x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你应当 保留 两个分区中每个节点的初始相对位置。
- 此时可以取得当前宽度和长度的最大值和递归的值进行比较
- 寻找的时候记录长度,遍历下一行的所有边,如果两条边直接存在交集关系,那么找出交集的边,继续向下遍历
维护一个新的哨兵节点
dummy,遍历当前的链表,如果节点 大于或等于 x ,那么将其移动到哨兵节点所在的数组里面,最后将当前链表的尾节点指向新的dummy.next- 维护两个节点指针指向新老节点,在使用一个新
lastNode节点指向原来节点遍历后的上一个节点,这样可以移除节点的时候直接将上一个节点的next指向移除的节点的next87. 扰乱字符串
使用下面描述的算法可以扰乱字符串 s 得到字符串 t :
- 如果字符串的长度为 1 ,算法停止
- 如果字符串的长度 > 1 ,执行下述步骤:
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串 s ,则可以将其分成两个子字符串 x 和 y ,且满足 s = x + y 。
- 随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,s 可能是 s = x + y 或者 s = y + x 。
- 在 x 和 y 这两个子字符串上继续从步骤 1 开始递归执行此算法。
给你两个 长度相等 的字符串 s1 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回 true ;否则,返回 false 。
- 维护两个节点指针指向新老节点,在使用一个新
递归+缓存:对于需要比较的两个字符串,可以先通过判断长度、字符是否重合这样来判断是否满足扰乱字符串规则
- 如果满足的情况下,使用
index遍历字符串的长度,在每一个index里面试图分割字符串,递归处理交换和不交换的情况88. 合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
- 如果满足的情况下,使用
可以在
nums1数组里面从右向左遍历,依次从尾部开始处理nums1和nums2,按照合并排序的规则来匹配89. 格雷编码
格雷编码是一个二进制数字系统,在该系统中,两个连续的数值仅有一个位数的差异。 给定一个代表编码总位数的非负整数 n,打印其格雷编码序列。即使有多个不同答案,你也只需要返回其中一种。 格雷编码序列必须以 0 开头。
分析葛雷编码的规律,可以得到每一阶段其实可以算作是
0 + grayCode(n - 1) + 2^(n - 1) + (倒叙)grayCode(n - 1)
public List<Integer> grayCode(int n) {List<Integer> res = new ArrayList<>();if (n == 0) {res.add(n);return res;}int currentNum = 0;List<Integer> childs = grayCode(n - 1);for (int num : childs) {res.add(currentNum + num);}currentNum = (int) Math.pow(2, n - 1);for (int i = childs.size() - 1; i >= 0; i--) {res.add(currentNum + childs.get(i));}return res;}
90. 子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
和 78 方案类似,但是使用的时候先排序,在每次回溯这个值后,判断下个值是否重复,如果重复需要循环去掉
91. 解码方法
一条包含字母 A-Z 的消息通过以下映射进行了 编码 : ‘A’ -> 1 ‘B’ -> 2 … ‘Z’ -> 26 要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,”11106” 可以映射为:
- “AAJF” ,将消息分组为 (1 1 10 6)
- “KJF” ,将消息分组为 (11 10 6)
注意,消息不能分组为 (1 11 06) ,因为 “06” 不能映射为 “F” ,这是由于 “6” 和 “06” 在映射中并不等价。 给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。 题目数据保证答案肯定是一个 32 位 的整数。
动态规划:
f(n) = previous + previous2,其中- 当
nums[n] != '0'的时候,previous = nums[n - 1]; - 当
nums[n - 1] == '1' or (nums[n - 1] =='2' and nums[n] <= '6')的时候,previous2 = nums[n - 2];92. 反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
- 当
遍历链表,并且维护一个递增计数
index- 当计数小于
left的时候,记录start = currentNode,这样最后反转链表完成后,这个start就是 - 当计数等于
left的时候,此时记录当前节点,作为反转链表的尾节点 - 当计数大于等于
left且小于等于right的时候,开始反转链表,将currentNode.next = lastNode- 其中
lastNode记录为上一个节点,初始为null
- 其中
- 当计数等于
right的时候,反转结束,此时将记录的尾节点指向遍历节点的下一个节点,并且将start.next = currentNode- 如果反转是从根节点开始,那么将跟节点置为
currentNode93. 复原 IP 地址
给定一个只包含数字的字符串,用以表示一个 IP 地址,返回所有可能从 s 获得的 有效 IP 地址 。你可以按任何顺序返回答案。 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。 例如:”0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但是 “0.011.255.245”、”192.168.1.312” 和 “192.168@1.1” 是 无效 IP 地址。
- 如果反转是从根节点开始,那么将跟节点置为
- 当计数小于
回溯+剪枝:在给与的字符串里面,做出四次选择,每次选择1~3 位字符作为 IP 地址的一部分
- 每次选择的时候,可以先判断,余下的字符串里面是否超过了有效
IP地址的个数,例如,选最后一位数字的时候,余下的字符串位数是 4 - 当前位置上的字符为 0 的时候,一定要选择这个字符,继续回溯下去
- 此时,可以选择,选一个字符,在挑选两个字符,加入字符前三位小于等于 255 的时候,还可以选择三个字符,三次回溯递归下去
- 最终选中 4 为数字,并且长度满足的时候就是最终的选择
94. 二叉树的中序遍历
给定一个二叉树的根节点 root ,返回它的 中序 遍历。
- 每次选择的时候,可以先判断,余下的字符串里面是否超过了有效
简单的递归即可
堆栈模拟:先将 root 压栈,开始循环判断栈是否为空
- 出栈一个节点,按照
node.right, node, node.left的顺序依次压栈,并且记录node以及被出栈过 - 此时当出栈的节点被出栈过,就可以输出这个节点,否则继续按照
node.right, node, node.left,并且标记当前节点出栈过95. 不同的二叉搜索树 II
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。
- 出栈一个节点,按照
开始计算
[1...n]生成的所有二次搜索树- 遍历这个数组,index = 1~n,将这个数组分成两部分
[1...index - 1],[index+1...n],递归计算这两个部分的二叉搜索树 - 此时将这两个子树列表组成笛卡尔积,以
index为根节点,分成设置左右节点 - 当二叉搜索树不存在的时候,返回一个默认的
[null]96. 不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
- 遍历这个数组,index = 1~n,将这个数组分成两部分
和 95 算法一样,只是组成笛卡尔积的时候,可以直接将结果相乘
- 这个时候可以通过缓存来缓存每次递归的结果数据
97. 交错字符串
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。 两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
- s = s1 + s2 + … + sn
- t = t1 + t2 + … + tm
- |n - m| <= 1
- 交错 是 s1 + t1 + s2 + t2 + s3 + t3 + … 或者 t1 + s1 + t2 + s2 + t3 + s3 + …
提示:a + b 意味着字符串 a 和 b 连接。
- 这个时候可以通过缓存来缓存每次递归的结果数据
动态规划:维护一个二维数组,
res[i][j]表示 字符串s1[0...i]、s2[0...j]是否能够交错组成s3[0...i + j]res[i][j] = (res[i - 1][j] && s1[i] == s3[i + j]) || (res[i][j - 1] && s2[j] == s3[i + j])- 可以提前设置
res[0][j]和res[i][0]的边界值98. 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
递归:对于每个节点,需要验证它的左节点小于当前值,右节点大于当前值,并且递归的时候还需要维护一个上下限制范围,例如判断
root.left节点是否是二叉搜索树的时候,它里面所有节点的值不能大于root.val里面的值中序遍历:在中序遍历的时候,可以判断左右节点是否满足
left.val < node.val < right.val```java // 顺序 public boolean isValidBST(TreeNode root) { Dequestack = new LinkedList (); double inorder = -Double.MAX_VALUE; while (!stack.isEmpty() || root != null) {
while (root != null) {stack.push(root);root = root.left;}root = stack.pop();// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树if (root.val <= inorder) {return false;}inorder = root.val;root = root.right;
} return true; }
// 递归 private boolean isValidBST2(TreeNode node) { if(node == null) return true; boolean l = inorder(node.left); if(node.val <= pre) return false; pre = node.val; boolean r = inorder(node.right); return l && r; } ```
99. 恢复二叉搜索树
给你二叉搜索树的根节点 root ,该树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。 进阶:使用 O(n) 空间复杂度的解法很容易实现。你能想出一个只使用常数空间的解决方案吗?
中序遍历:中序遍历的时候,可以判断前一个值和后一个值是否满足递增关系,如果不满足那么就认为这两个节点可能是交换节点,将其放入交换节点列表里面
- 如果第一次出现不满足的节点,将两个节点都放在里面,后续出现的话,只需要放后面一个节点就可以了
- 因为存在相邻节点相互交换的问题,此时只放入一个结点的话,没法处理这种情况
- 当遍历完成后,将交换节点列表的第一个和最后一个节点交换
100. 相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
- 如果第一次出现不满足的节点,将两个节点都放在里面,后续出现的话,只需要放后面一个节点就可以了
广度、深度优先搜索:对于每一个节点,只要它的节点的值是一样的话,就可以递归处理它的子节点
- morris遍历

若有收获,就点个赞吧
0 人点赞
