我们先总结一下虚拟内存的作用:
- 第一,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的。这就解决了多进程之间地址冲突的问题。
第二,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
内存分配的过程
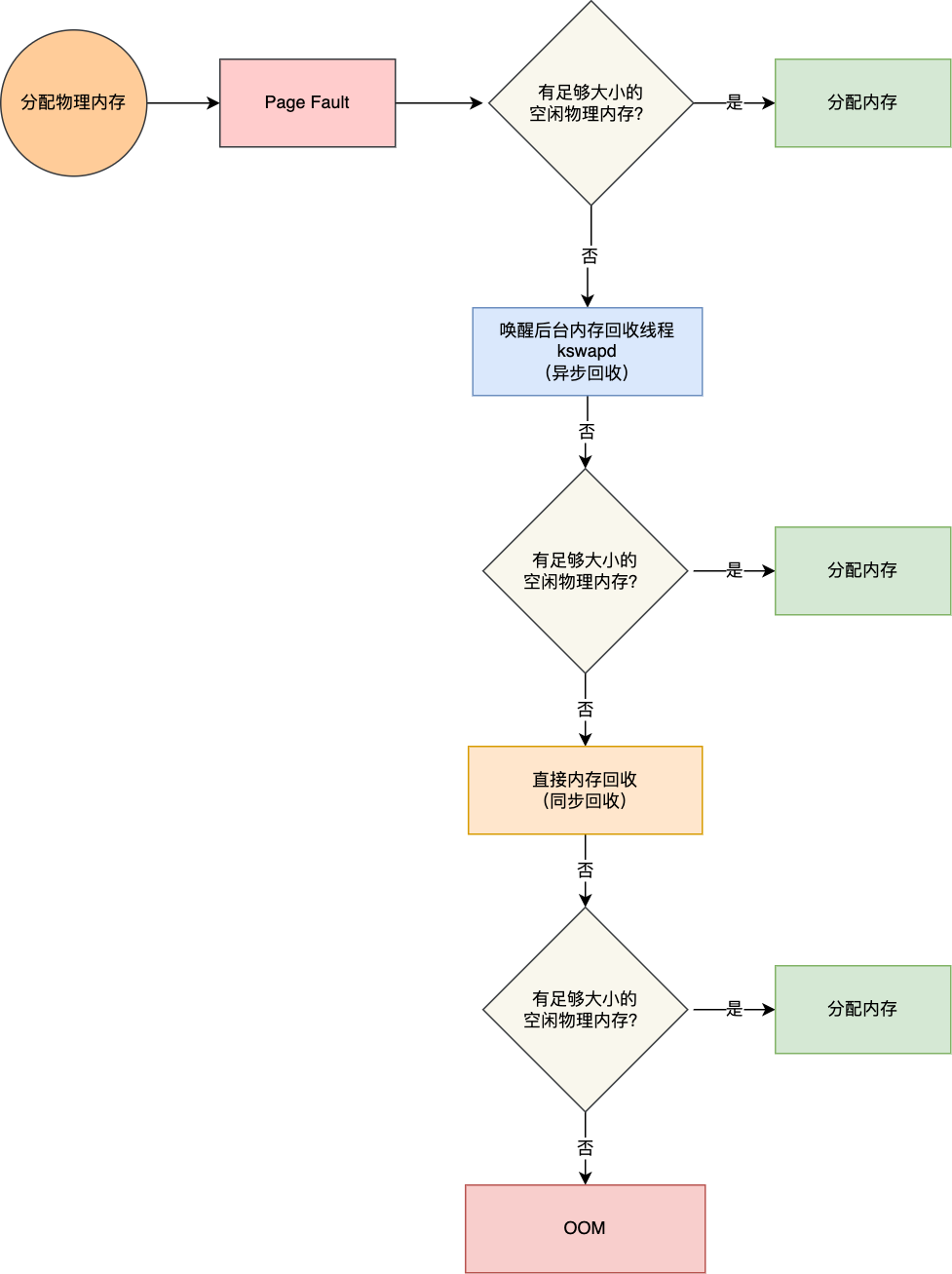
后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
那些内存是可以回收的呢
主要有两类内存可以被回收,而且它们的回收方式也不同。
文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
- 匿名页(Anonymous Page):这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如堆、栈数据等。这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active_list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
inactive_list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
回收内存带来的影响?如何解决?
在前面我们知道了回收内存有两种方式。
一种是后台内存回收,也就是唤醒 kswapd 内核线程,这种方式是异步回收的,不会阻塞进程。
- 一种是直接内存回收,这种方式是同步回收的,会阻塞进程,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起系统负荷飙高。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
可以看到,回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能,整个系统给人的感觉就是很卡。
解决方案:
- 调整文件页和匿名页的回收倾向,回收干净页是不会发生磁盘IO的,所以尽可能多的回收文件页
- 尽早出发kswapd内核线程异步回收内存
何时出发kswapd内核线程回收内存呢?
内核定义了三个内存阈值(watermark,也称为水位),用来衡量当前剩余内存(pages_free)是否充裕或者紧张,分别是:
- 页最小阈值(pages_min);
- 页低阈值(pages_low);
- 页高阈值(pages_high);
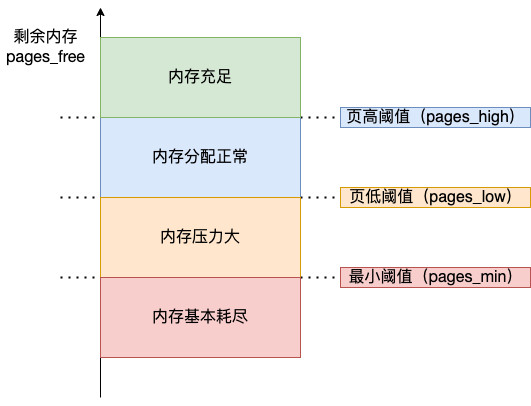
kswapd 会定期扫描内存的使用情况,根据剩余内存(pages_free)的情况来进行内存回收的工作。
- 图中绿色部分:如果剩余内存(pages_free)大于 页高阈值(pages_high),说明剩余内存是充足的;
- 图中蓝色部分:如果剩余内存(pages_free)在页高阈值(pages_high)和页低阈值(pages_low)之间,说明内存有一定压力,但还可以满足应用程序申请内存的请求;
- 图中橙色部分:如果剩余内存(pages_free)在页低阈值(pages_low)和页最小阈值(pages_min)之间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值(pages_high)为止。虽然会触发内存回收,但是不会阻塞应用程序,因为两者关系是异步的。
- 图中红色部分:如果剩余内存(pages_free)小于页最小阈值(pages_min),说明用户可用内存都耗尽了,此时就会触发直接内存回收,这时应用程序就会被阻塞,因为两者关系是同步的。
NUMA架构下的内存回收策略
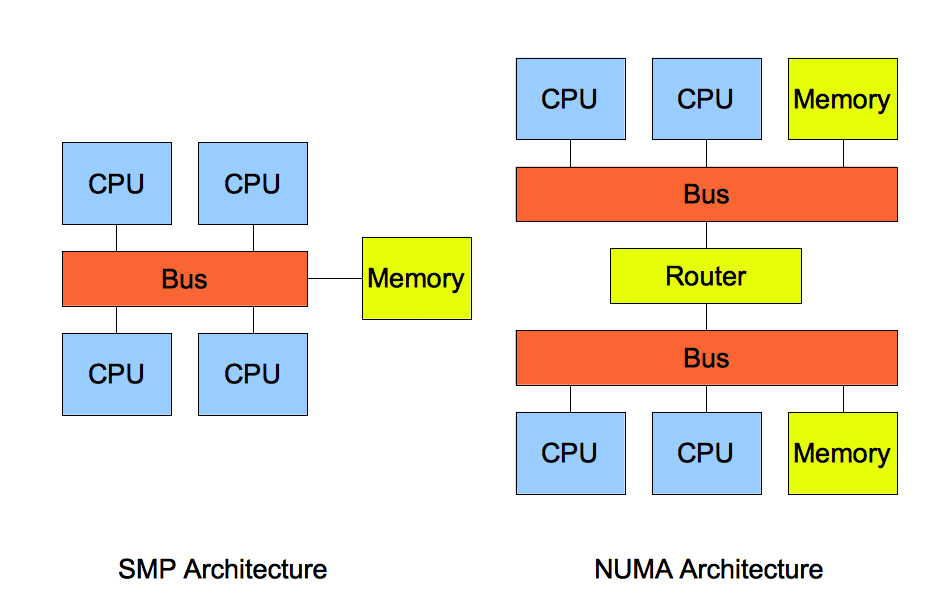
SMP 指的是一种多个 CPU 处理器共享资源的电脑硬件架构,也就是说每个 CPU 地位平等,它们共享相同的物理资源,包括总线、内存、IO、操作系统等。每个 CPU 访问内存所用时间都是相同的,因此,这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
随着 CPU 处理器核数的增多,多个 CPU 都通过一个总线访问内存,这样总线的带宽压力会越来越大,同时每个 CPU 可用带宽会减少,这也就是 SMP 架构的问题。
为了解决 SMP 架构的问题,就研制出了 NUMA 结构,即非一致存储访问结构(Non-uniform memory access,NUMA)。
NUMA 架构将每个 CPU 进行了分组,每一组 CPU 用 Node 来表示,一个 Node 可能包含多个 CPU 。每个 Node 有自己独立的资源,包括内存、IO 等,每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存。但是,访问远端 Node 的内存比访问本地内存要耗时很多。
在 NUMA 架构下,当某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。
具体选哪种模式,可以通过 /proc/sys/vm/zone_reclaim_mode 来控制。它支持以下几个选项:
- 0 (默认值):在回收本地内存之前,在其他 Node 寻找空闲内存;
- 1:只回收本地内存;
- 2:只回收本地内存,在本地回收内存时,可以将文件页中的脏页写回硬盘,以回收内存。
- 4:只回收本地内存,在本地回收内存时,可以用 swap 方式回收内存。
在使用 NUMA 架构的服务器,如果系统出现还有一半内存的时候,却发现系统频繁触发「直接内存回收」,导致了影响了系统性能,那么大概率是因为 zone_reclaim_mode 没有设置为 0 ,导致当本地内存不足的时候,只选择回收本地内存的方式,而不去使用其他 Node 的空闲内存。

若有收获,就点个赞吧
0 人点赞
