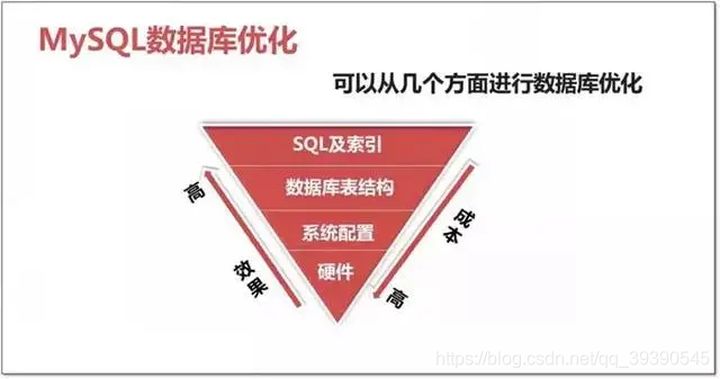
优化成本:硬件>系统配置>数据库表结构>SQL及索引。
优化效果:硬件<系统配置<数据库表结构
- 减少数据访问: 设置合理的字段类型,启用压缩,通过索引访问等减少磁盘IO
- 返回更少的数据: 只返回需要的字段和数据分页处理 减少磁盘io及网络io
- 减少交互次数: 批量DML操作,函数存储等减少数据连接次数
- 减少服务器CPU开销: 尽量减少数据库排序操作以及全表查询,减少cpu 内存占用
- 利用更多资源: 使用表分区,可以增加并行操作,更大限度利用cpu资源
总结到SQL优化中,就三点:
- 最大化利用索引;
- 尽可能避免全表扫描;
-
一、查询SQL优化策略
where条件优化
1、条件查询,当数据量大时,避免使用where 1=1的条件
优化方式:用代码拼接sql时进行判断,没 where 条件就去掉 where
2、尽量避免在where条件中等号的左侧进行表达式、函数操作
可以将表达式、函数操作移动到等号右侧。如下:-- 全表扫描不走索引SELECT * FROM T WHERE score/10 = 9-- 走索引SELECT * FROM T WHERE score = 10*9
3、where条件包含符合索引顺序
如下:复合(联合)索引包含key1,key2,key3三列,但SQL语句没有包含索引前置列”key1”,按照MySQL联合索引的最左匹配原则,不会走联合索引。
select col1 from table where key2=1 and key3=2
4、调整Where字句中的连接顺序
MySQL采用从左往右,自上而下的顺序解析where子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。1、 尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE '%你%'
优化方式:尽量在字段后面使用模糊查询。如下:
SELECT * FROM t WHERE username LIKE '你%'
2、数据类型匹配(mysql会隐式转换,这个也是函数(cast),使用了函数会导致索引失效)
隐式类型转换规则:
如果一个或两个参数都是NULL,比较的结果是NULL,除了NULL安全的<=>相等比较运算符。对于NULL <=> NULL,结果为true。不需要转换
- 如果比较操作中的两个参数都是字符串,则将它们作为字符串进行比较。
- 如果两个参数都是整数,则将它们作为整数进行比较。
- 如果不与数字进行比较,则将十六进制值视为二进制字符串
- 如果其中一个参数是十进制值,则比较取决于另一个参数。 如果另一个参数是十进制或整数值,则将参数与十进制值进行比较,如果另一个参数是浮点值,则将参数与浮点值进行比较
- 如果其中一个参数是TIMESTAMP或DATETIME列,另一个参数是常量,则在执行比较之前将常量转换为时间戳。
-
3、尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT FROM t WHERE score = 04、order by 条件要与where中条件一致,否则order by不会利用索引进行排
对于上面的语句,数据库的处理顺序是:
第一步:根据where条件和统计信息生成执行计划,得到数据。
- 第二步:将得到的数据排序。当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看order by 的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则重新进行排序操作。
- 第三步:返回排序后的数据。
当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。
这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by 、union 、distinct等。
5、尽量使用覆盖索引
一条查询语句符合覆盖索引条件时,sql只需要通过覆盖索引就可以返回查询所需要的数据,避免回表操作,减少I/O提高效率。
6、避免出现select *
select 操作在任何类型数据库中都不是一个好的SQL编写习惯。
使用select 优化器无法完成索引覆盖扫描这类优化,会影响优化器对执行计划的选择,也会增加网络带宽消耗,更会带来额外的I/O,内存和CPU消耗
7、避免出现不确定结果的函数
使用如now()、rand()、sysdate() 产生的SQL语句无法利用query cache。
8、多表关联查询时,小表在前,大表在后。
在MySQL中,执行 from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表
9、 使用表的别名
这样就可以减少解析的时间并减少哪些友列名歧义引起的语法错误。
10、分页优化(使用非聚集索引来优化)
— 分页 age 有索引 平均0.3秒 select * from fds_test_copy1 where age > ‘9’ limit 100000, 10
— 分页优化 age 有索引 平均0.14
select * from (select b.id as innerId from fds_test_copy1 b where b.age > ‘9’ limit 100000, 10) c left join fds_test_copy1 a on a.id = c.innerId
回到MySQL索引如何设计索引中有提及到:MySQL数据库的查询优化器是采用了基于代价的,而查询代价的估算是基于CPU代价和IO代价。如果MySQL在查询代价估算中,认为全表扫描方式比走索引扫描的方式效率更高的话,就会放弃索引,直接全表扫描。
这就是为什么在大分页的SQL查询中,明明给该字段加了索引,但是MySQL却走了全表扫描的原因。
二、建表sql优化
1、在表中建立索引,优先考虑where、order by使用到的字段。
2、尽量使用数字型字段(如性别,男:1 女:2),若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
3、用varchar/nvarchar 代替 char/nchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些

若有收获,就点个赞吧
0 人点赞
