三级缓存架构
众所周知,为了缓解内存和 CPU 之间速度不匹配的矛盾,引入了高速缓存这个东西,它的容量比内存小很多,但是交换速度却比内存要快得多。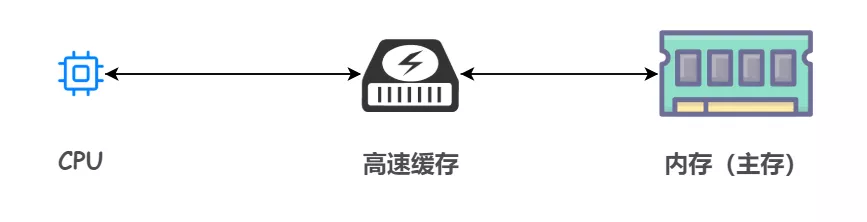
分级存储体系结构: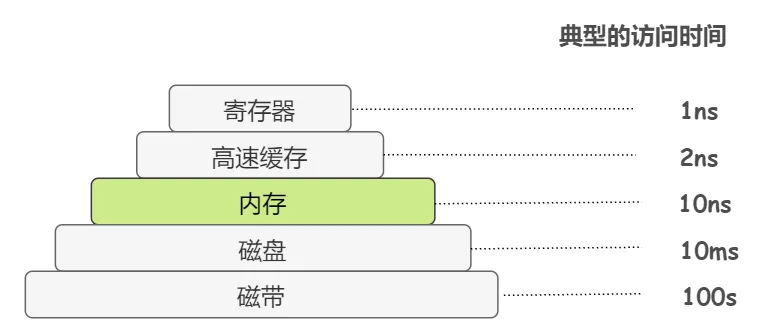
https://gitee.com/veal98/images/raw/master/img/20210415105520.png
事实上,高速缓存仍然存在细分,也称为三级缓存结构:一级(L1)缓存、二级(L2)缓存、三级(L3)缓存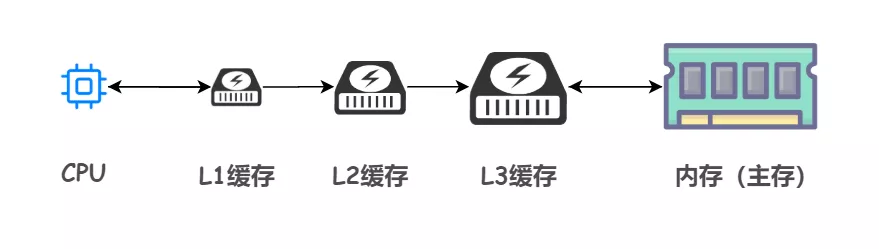
越靠近 CPU 的缓存,速度越快,容量也越小。所以 L1 缓存容量最小但是速度最快;L3 缓存容量最大同时速度也最慢
当 CPU 执行运算的时候,它会先去 L1 缓存查找所需的数据、如果没有找到的话就再去 L2 缓存、然后是 L3 缓存,如果最后这三级缓存中都没有命中,那么 CPU 就要去访问内存了。
显然,CPU 走得越远,运算耗费的时间就越长。所以尽量确保数据存在 L1 缓存中能够提升大计算量情况下的运行速度。
需要注意的是,CPU 和三级缓存以及内存的对应使用关系:
- L1 和 L2 都是只能被一个单独的 CPU 核心使用
- L3 可以被单个插槽上的所有 CPU 核心共享
- 内存由全部插槽上的所有 CPU 核心共享
如下图所示: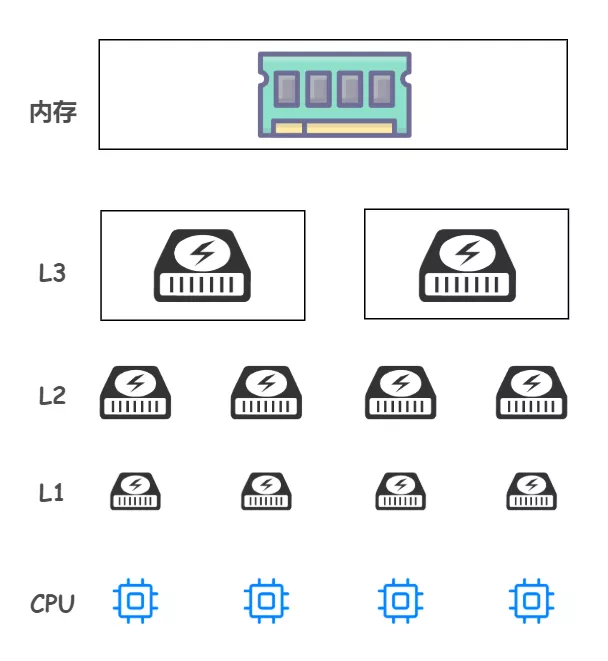
另外,这三级缓存空间中的数据是如何组织起来的呢?换句话说,数据在这三级缓存中的存储形式是什么样的呢?
Cache Line(缓存行)!
缓存中的基本存储单元就是 Cache Line。
每个 Cache Line 通常是 64 字节,也就是说,一个 Java 的 long 类型变量是 8 字节,一个 Cache Line 中可以存 8 个 long 类型的变量。
缓存中的数据并不是按照一个一个单独的变量这样存储组织起来的,而是多个变量会放到一行中。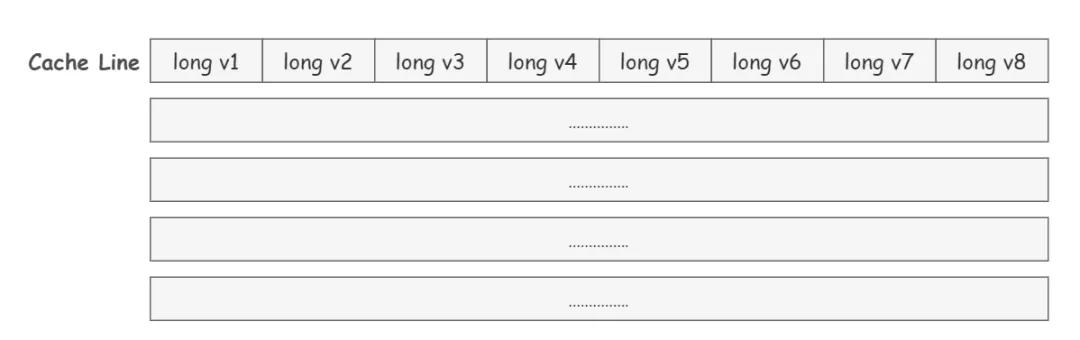
伪共享问题 False Sharing
在程序运行的过程中,由于缓存的基本单元 Cache Line 是 64 字节,所以缓存每次更新都会从内存中加载连续的 64 个字节。
如果访问的是一个 long 类型数组的话,当数组中的一个值比如 v1 被加载到缓存中时,接下来地址相邻的 7 个元素也会被加载到缓存中。(这也能解释为啥数组总是能够这么快,像链表这种离散存储的数据结构,就无法享受到这种红利)。
但是,这波红利很可能带来无妄之灾。
举个例子,如果定义了两个 long 类型的变量 a 和 b,他们在内存中的地址是紧挨着的,会出现什么问题?
如果想要访问 a 的话,那么 b 也会被存储到缓存中来。
这有什么问题吗,看起来似乎没有什么毛病,多么好的特性。
直接上个例子
回想下上文提到的 CPU 和三级缓存以及内存的对应使用关系,设想这种情况,如果一个 CPU 核心的线程 T1 在对 a 进行修改,另一个 CPU 核心的线程 T2 却在对 b 进行读取。
当 T1 修改 a 的时候,除了把 a 加载到 Cache Line,还会享受一波红利,把 b 同时也加载到 T1 所处 CPU 核心的 Cache Line 中来,对吧。
根据 MESI 缓存一致性协议,修改完 a 后这个 Cache Line 的状态就是 M(Modify,已修改),而其它所有包含 a 的 Cache Line 中的 a 就都不是最新值了,所以都将变为 I 状态(Invalid,无效状态)
这样,当 T2 来读取 b 时,发现他所处的 CPU 核心对应的这个 Cache Line 已经失效了,它就需要花费比较长的时间从内存中重新加载了。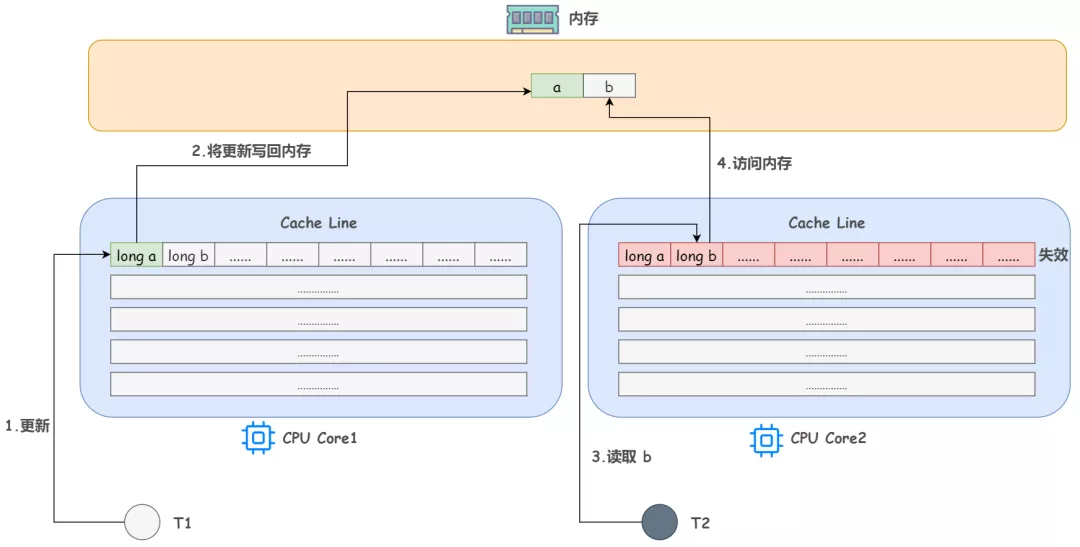
问题已经显而易见了,b 和 a 没有任何关系,每次却要因为 a 的更新导致他需要从内存中重新读取,拖慢了速度。这就是伪共享
表面上 a 和 b 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
用更书面的解释来定义伪共享:当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,导致无法充分利用缓存行特性,这就是伪共享。
伪共享解决方案
先来举个例子看看一段伪共享代码的耗时,如下所示,定义一个 Test 类,它包含两个 long 的变量,分别用两个线程对这两个变量进行自增 1 亿次,这段代码耗时 5625ms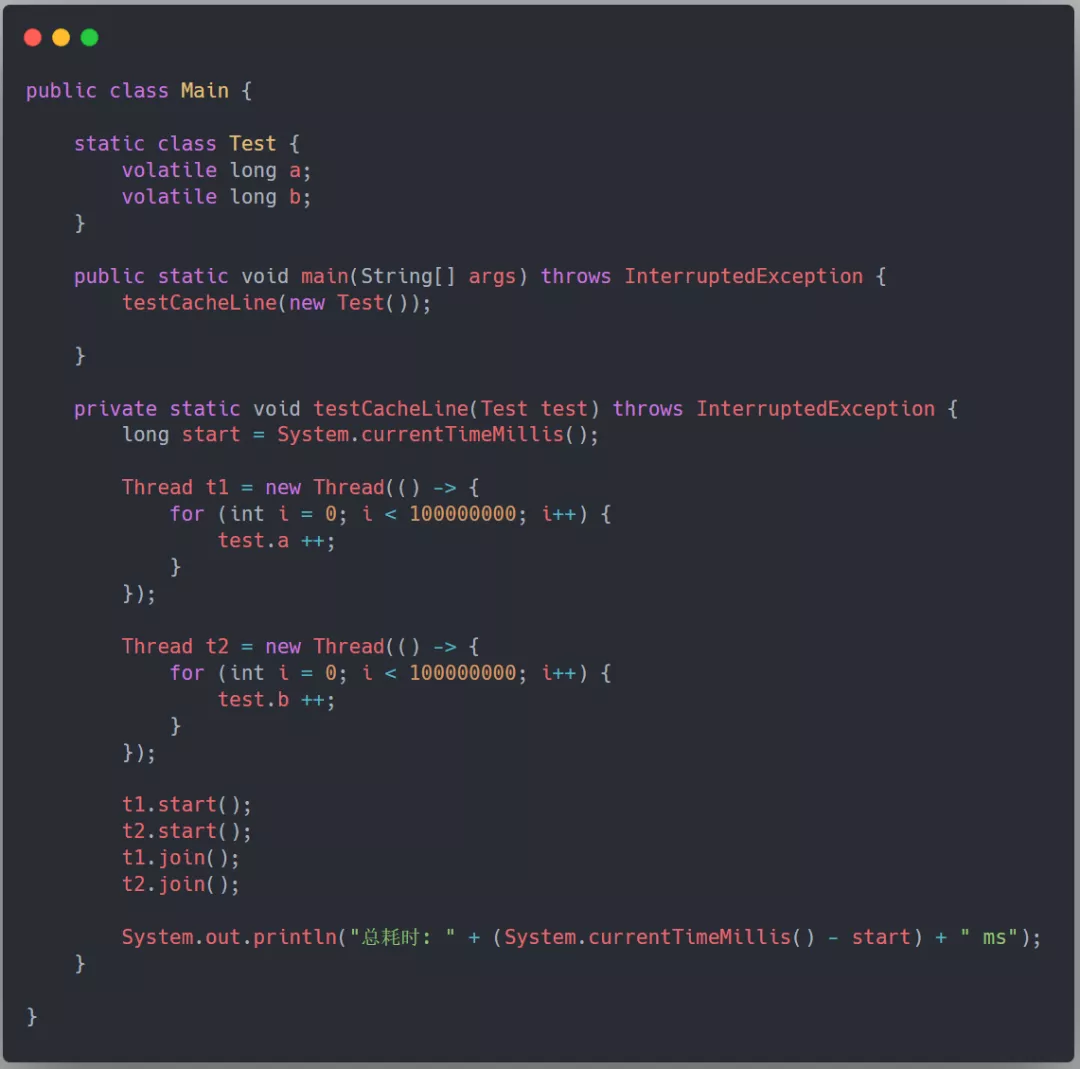
对于伪共享,一般有两种方法,其实思想都是一样的:
1)padding:就是增大数组元素之间的间隔,使得不同线程存取的元素位于不同的缓存行上,以空间换时间
上面提到过,一个 64 字节的 Cache Line 中可以存 8 个 long 类型的变量,在 a 和 b 这两个 long 类型的变量之间再加 7 个 long 类型,使得 a 和 b 处在不同的 Cache Line 上面: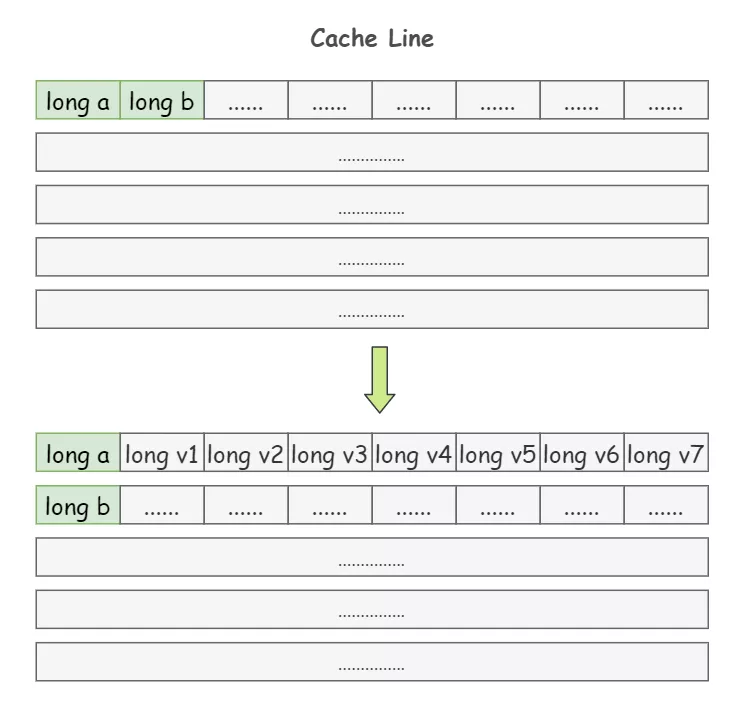
class Pointer {volatile long a;long v1, v2, v3, v4, v5, v6, v7;volatile long b;}
再次运行程序,会发现输出时间神奇的缩短为了 955ms
2)JDK1.8 提供了 **@Contended** 注解:就是把手动 padding 的操作封装到这个注解里面了,这个注解可以放在类上也可以放在字段上
class Test {@Contendedvolatile long a; // 填充 avolatile long b;}
需要注意的是,默认使用这个注解是无效的,需要在 JVM 启动参数加上 XX:-RestrictContended 才会生效
🥸 面试官:讲一下伪共享问题
伪共享问题其实是由于高速缓存的特性引起的,三级高速缓存中的数据并不是一个变量一个变量单独存放的,它的基本存储单元是 Cache Line,一般一个 Cache Line 的大小是 64 字节,也就是说,一个 Cache Line 中可以存下 8 个 8 字节的 long 类型变量
那由于高速缓存的基本单元是 64 字节的 Cache Line,所以呢,缓存从内存中一次读取的数据就是 64 字节。换句话说,如果 cpu 要读取一个 long 类型的数组,读取其中一个元素的同时也会把接下来的其他相邻地址的七个元素也加载到 Cache Line 中来。
这就会导致一个问题,举个例子,定义了两个 long 类型的变量 a 和 b,他们没有关系,但是他们在内存中的地址是紧挨着的,如果一个 CPU 核心的线程 T1 在对 a 进行修改,另一个 CPU 核心的线程 T2 却在对 b 进行读取。
那么当 T1 修改 a 的时候,除了把 a 加载到 Cache Line,还会把 b 同时也加载到 T1 所处 CPU 核心的 Cache Line 中来,对吧。
根据 MESI 缓存一致性协议,修改完 a 后这个 Cache Line 的状态就是 M(Modify,已修改),而其它所有包含 a 的 Cache Line 中的 a 就都不是最新值了,所以都将变为 I 状态(Invalid,无效状态)
这样,当 T2 来读取 b 时,他就会发现,他所处的 CPU 核心对应的这个 Cache Line 已经失效了,这样他就需要花费比较长的时间从内存中重新加载了。
也就是说,b 和 a 没有任何关系,每次却要因为 a 的更新导致他需要从内存中重新读取,拖慢了速度。这就是伪共享
对于伪共享,一般有两种方法,其实思想都是一样的:
1)padding:就是增大数组元素之间的间隔,使得不同线程存取的元素位于不同的缓存行上,以空间换时间。比如在 a 和 b 之间再定义 7 个 long 类型的变量,使得 a 和 b 不在一个 Cache Line 上,这样当修改 a 的时候 b 所处的 Cache Line 就不会受到影响了
2)JDK 1.8 提供了 @Contended 注解,就是把手动 padding 的操作封装到这个注解里面了,把这个注解加在字段 a 或者 b 的上面就可以了

若有收获,就点个赞吧
0 人点赞

{kind=link}