概述
前面章节只使用了一台机器做了伪分布式集群,只有一台机器hadoop101,下面将使用hadoop102、hadoop103三台机器实现真正的分布式集群,一主二从的形式,Hadoop101为主节点,102、103为从节点
环境要求
- JDK安装
- 免密登录:参考机器配置,需要实现hadoop101可以免密登录本机以及102、103
- 环境变量配置:参考配置Hadoop章节
修改hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
修改为
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:50090</value>
</property>
</configuration>
- dfs.replication:表示复本的数量为2
- dfs.namenode.secondary.http-address:第二namenode位置
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
修改为
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
</configuration>
增加了yarn.resourcemanager.hostname配置
配置从节点works
进入配置文件目录:$HADOOP_HOME/etc/hadoop
cd $HADOOP_HOME/etc/hadoop编辑hdfs-site.xml文件:vi works
- 添加以下配置信息:
102、103为从节点hadoop102 hadoop103
分发安装包
- 将配置好的hadoop安装包复制到hadoop102、hadoop103机器上
scp -rq hadoop-3.2.1/ hadoop102:/usr/local/ scp -rq hadoop-3.2.1/ hadoop103:/usr/local/
启动集群
- 在主节点机器上启动所有节点
- 执行脚本start-all.sh
[root@hadoop101 hadoop]# start-all.sh Starting namenodes on [hadoop101] 上一次登录:日 1月 12 01:52:13 CST 2020pts/1 上 Starting datanodes 上一次登录:日 1月 12 01:54:36 CST 2020pts/1 上 hadoop103: WARNING: /home/data/hadoop/logs does not exist. Creating. hadoop102: WARNING: /home/data/hadoop/logs does not exist. Creating. Starting secondary namenodes [hadoop101] 上一次登录:日 1月 12 01:54:39 CST 2020pts/1 上 Starting resourcemanager 上一次登录:日 1月 12 01:54:43 CST 2020pts/1 上 Starting nodemanagers 上一次登录:日 1月 12 01:54:51 CST 2020pts/1 上
验证结果
查看hadoo101进程
[root@hadoop101 hadoop]# jps
11970 ResourceManager
12323 Jps
11512 NameNode
11722 SecondaryNameNode
查看hadoop102进程
[root@hadoop102 hadoop]# jps
2453 Jps
2349 NodeManager
2255 DataNode
查看hadoop03进程
[root@hadoop103 hadoop]# jps
11186 Jps
11082 NodeManager
10989 DataNode
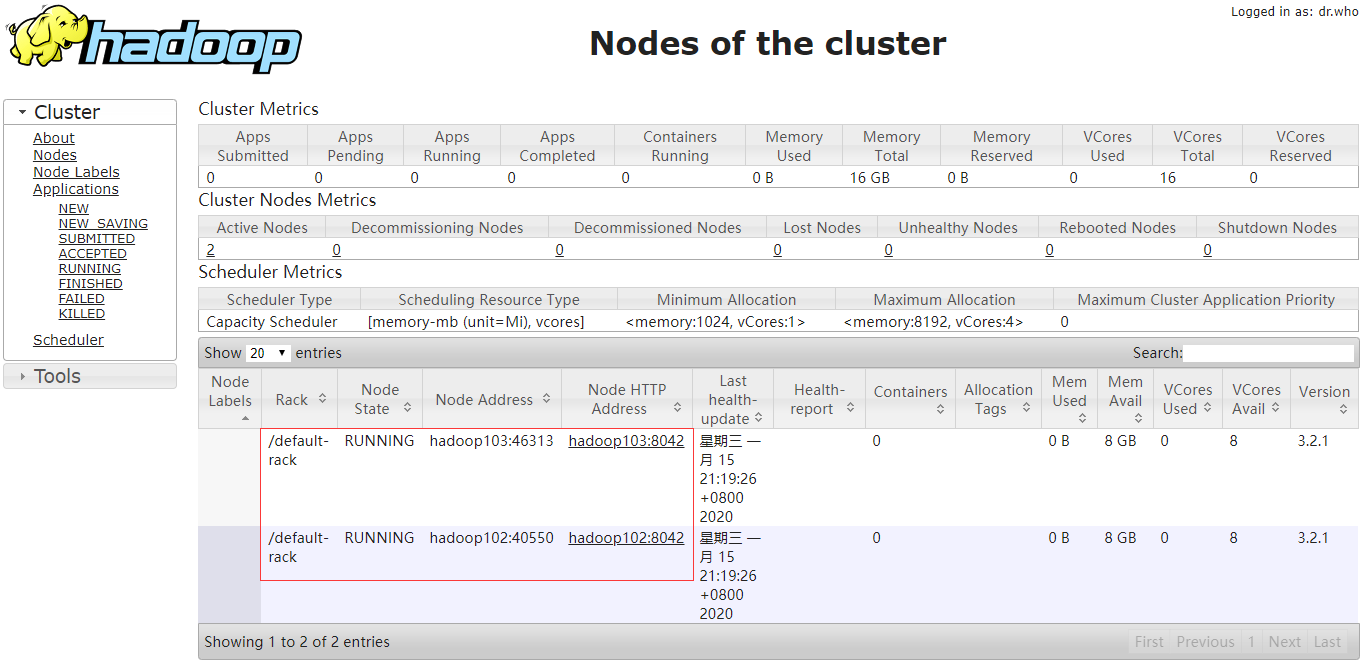
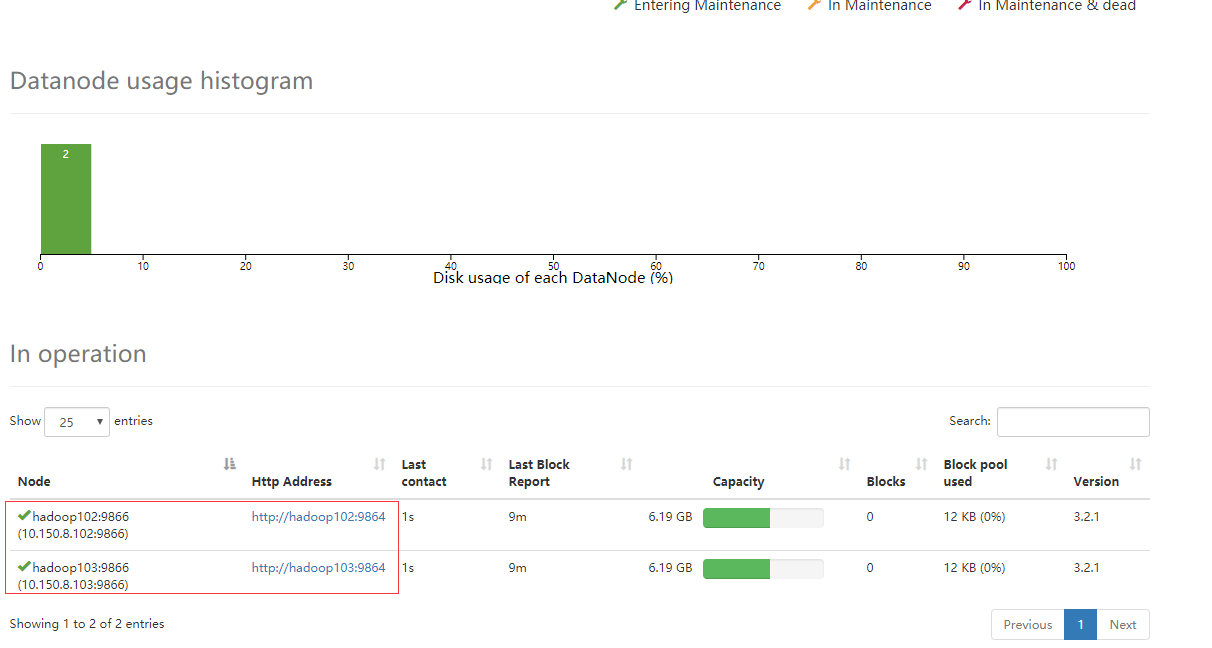
通过网页查看
如果已经正确启动,确无法访问,请检查服务器防火墙是否关闭

若有收获,就点个赞吧
0 人点赞
