场景说明: 统计HDFS中文本文件中每个单词出现的次数,并输出到结果文件中
新建Maven工程
新建普通的maven工程
<groupId>cn.faury.demo.hadoop.word.count</groupId><artifactId>hadoop-word-count</artifactId><version>1.0-SNAPSHOT</version>
pom文件基础配置
配置maven属性
<properties> <java.version>1.8</java.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties>配置阿里云仓库
<!-- pull私服配置 --> <repositories> <!--<repository>--> <!--<id>nexus</id>--> <!--<name>zbiti nexus</name>--> <!--<url>http://192.168.103.223:8081/repository/maven-public/</url>--> <!--<releases><enabled>true</enabled></releases>--> <!--<snapshots><enabled>true</enabled></snapshots>--> <!--</repository>--> <repository> <id>public</id> <name>aliyun nexus</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> </repository> </repositories> <pluginRepositories> <!--<pluginRepository>--> <!--<id>nexus</id>--> <!--<name>zbiti nexus</name>--> <!--<url>http://192.168.103.223:8081/repository/maven-public/</url>--> <!--<releases><enabled>true</enabled></releases>--> <!--<snapshots><enabled>true</enabled></snapshots>--> <!--</pluginRepository>--> <pluginRepository> <id>public</id> <name>aliyun nexus</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </pluginRepository> </pluginRepositories>
添加Hadoop依赖
配置hadoop-client依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
<!--Hadoop集群中有-->
<scope>provided</scope>
</dependency>
</dependencies>
创建单词计数Mapper类
- 新建类:cn.faury.demo.hadoop.word.count.WordCountMapper
- 继承Hadoop的特定Mapper类,4个泛型参数依次为:
- KEYIN:LongWritable,表示输入的文件行号
- VALUEIN:Text,表示输入的文件对应行的内容
- KEYOUT:Text,表示统计输出的单词
- VALUEOUT:LongWritable,表示统计输出的单词出现的次数
- 重载map方法,map方法的参数依次为:
- LongWritable key:输入文件的行号
- Text value:输入文件对应行的内容
- Context context:Hadoop上下文
- 实现map方法
- 先将输入的每行内容按照空格进行分割,得到字符串数组
- 按照Hadoop的Map-Reduce格式输出每个单词出现1次到上下文中
- 完整代码如下所示 ```java package cn.faury.demo.hadoop.word.count;
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
- 自定义Mapper类:
- K1:行号
- V2:每行的内容
- K2:单词
- V2:次数 *
- @author Fanyc
- @date 2020/2/3 15:29
/
public class WordCountMapper extends Mapper
- 实现Map函数 *
- @param key 输入的k1,每行的行号
- @param value 输入的v1,每行的内容
- @param context 上下文
- @throws IOException 异常
- @throws InterruptedException 异常
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 把每行内容按照空格进行切分
String[] words = value.toString().split(“ “);
// 迭代切割出来的单词数据
for (String word : words) {
} } } ``` 注意:父类为org.apache.hadoop.mapreduce.Mapper类Text k2 = new Text(word); LongWritable v2 = new LongWritable(1L); // 输出结果 context.write(k2, v2);
创建单词计数器Reducer类
- 新建类:cn.faury.demo.hadoop.word.count.WordCountReducer
- 继承Hadoop的Reducer类,4个泛型参数依次为:
- KEYIN:Text,表示Map阶段输出的单词
- VALUEIN:LongWritable,表示Map阶段输出的单词出现的次数
- KEYOUT:Text,表示Reduce之后输出的单词
- VALUEOUT:LongWritable,表示Reduce之后输出的单词所有出现的次数
- 重载reduce方法,reduce方法的参数依次为:
- Text key:Map阶段输出的单词
- Iterable
values:Map阶段输出的单词出现的次数,按照同单词聚合成数组 - Context context:Hadoop上下文
- 实现reduce方法
- 将不同的map输出的单词次数进行累加
- 输出单词对应的累加后出现总次数到Hadoop上下文中
- 完整代码如下所示 ```java package cn.faury.demo.hadoop.word.count;
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
- 自定义Reduce类 *
- @author Fanyc
- @date 2020/2/3 15:30
/
public class WordCountReducer extends Reducer
- 分组后的数据 *
- @param key 输入的K2,单词
- @param values 输入的V2,每个单词在map阶段出现的次数列表
- @param context 上下文
- @throws IOException 异常
- @throws InterruptedException 异常
*/
@Override
protected void reduce(Text key, Iterable
values, Context context) throws IOException, InterruptedException { // 累加同一个key的次数 Long sum = 0L; for (LongWritable value : values) {
} // 组装结果 Text k3 = key; LongWritable v3 = new LongWritable(sum); // 输出结果 context.write(k3, v3); } } ``` 注意:父类为org.apache.hadoop.mapreduce.Reducersum = sum + value.get();
创建单词计数Job类
- 新建类:cn.faury.demo.hadoop.word.count.WordCountJob
- 创建main方法用于配置和执行job
main函数需要2个参数:
- 参数1:用于指定统计的文件或文件夹路径
- 参数2:用于指定输出统计结果文件夹路径
// 至少两个参数,参数1:输入文件路径,参数2:输出文件路径 if (args == null || args.length < 2) { System.exit(0); }
获取默认Job配置对象:
// job的配置参数 Configuration configuration = new Configuration();注意:Configuration类为org.apache.hadoop.conf.Configuration
创建Job实例:
// 创建一个Job Job job = Job.getInstance(configuration);注意:Job类为org.apache.hadoop.mapreduce.Job
配置Job运行的类
// 指定Job类 job.setJarByClass(WordCountJob.class);配置输入输出路径
// 指定输入路径 FileInputFormat.setInputPaths(job, new Path(args[0])); // 指定输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1]));注意:
- FileInputFormat类为org.apache.hadoop.mapreduce.lib.input.FileInputFormat
- FileOutputFormat类为org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
配置Map信息
// 指定Map类 job.setMapperClass(WordCountMapper.class); // 指定K2的类型 job.setMapOutputKeyClass(Text.class); // 指定V2的类型 job.setMapOutputValueClass(LongWritable.class);注意:此处的WordCountMapper为前面自定义的Mapper类,key、value的类型要与类中一致
配置Reducer信息
// 指定Reducer类 job.setReducerClass(WordCountReducer.class); // 指定输出K3的类型 job.setOutputKeyClass(Text.class); // 指定输出V3的类型 job.setOutputValueClass(LongWritable.class);注意:此处的WordCountReducer为前面自定义的Reducer类,key、value类型要与类中一致
提交Job到Hadoop执行
// 提交job job.waitForCompletion(true);完整代码如下所示 ```java package cn.faury.demo.hadoop.word.count;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
- 单词计数
- 需求:读取hdfs上的test.txt文件,计算文件中每个单词出现的次数
- *
- @author Fanyc
@date 2020/2/3 11:25 */ public class WordCountJob {
/**
组装Job = Mapper + Reduce */ public static void main(String[] args) { // 至少两个参数,参数1:输入文件路径,参数2:输出文件路径 if (args == null || args.length < 2) {
System.exit(0);}
// job的配置参数 Configuration configuration = new Configuration(); try {
// 创建一个Job Job job = Job.getInstance(configuration); // 指定Job类 job.setJarByClass(WordCountJob.class); // 指定输入路径 FileInputFormat.setInputPaths(job, new Path(args[0])); // 指定输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1])); // 指定Map类 job.setMapperClass(WordCountMapper.class); // 指定K2的类型 job.setMapOutputKeyClass(Text.class); // 指定V2的类型 job.setMapOutputValueClass(LongWritable.class); // 指定Reducer类 job.setReducerClass(WordCountReducer.class); // 指定输出K3的类型 job.setOutputKeyClass(Text.class); // 指定输出V3的类型 job.setOutputValueClass(LongWritable.class); // 提交job job.waitForCompletion(true);} catch (IOException | InterruptedException | ClassNotFoundException e) {
e.printStackTrace();} } } ```
配置打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!--配置生成源码包-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
打包jar
在Maven Projects面板中,选择clean+compile+package,再执行打包
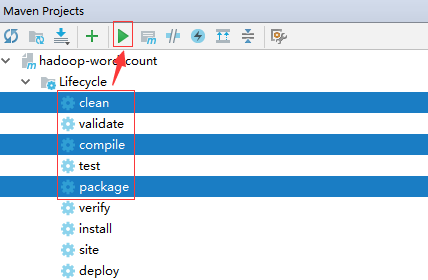
在工程目录下target中找到打包好的jar包
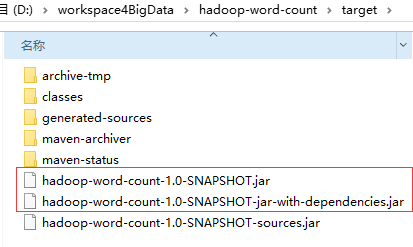
注:如果有第三方依赖的使用下面的dependencies.jar
测试程序
- 上传jar包到Hadoop集群某个节点或者客户端上
编辑测试文件并上传到HDFS中
[root@hadoop101 soft]# cat test.txt hello fanyc hello china hello world成功上传测试文件
[root@hadoop101 soft]# hdfs dfs -ls / Found 2 items drwxr-xr-x - root supergroup 0 2020-02-03 10:37 /data -rw-r--r-- 2 root supergroup 36 2020-02-03 15:07 /test.txt执行Job程序
hadoop jar ${jar文件} ${Job类全路径} ${输入文件} ${输出目录}
[root@hadoop103 jars]# hadoop jar hadoop-word-count-1.0-SNAPSHOT.jar cn.faury.demo.hadoop.word.count.WordCountJob /test.txt /out
2020-02-03 15:07:56,013 INFO client.RMProxy: Connecting to ResourceManager at hadoop101/10.150.8.101:8032
......
2020-02-03 15:07:58,932 INFO mapreduce.Job: Running job: job_1580693126708_0001
2020-02-03 15:08:10,395 INFO mapreduce.Job: Job job_1580693126708_0001 running in uber mode : false
2020-02-03 15:08:10,396 INFO mapreduce.Job: map 0% reduce 0%
2020-02-03 15:08:18,709 INFO mapreduce.Job: map 100% reduce 0%
2020-02-03 15:08:26,929 INFO mapreduce.Job: map 100% reduce 100%
2020-02-03 15:08:26,944 INFO mapreduce.Job: Job job_1580693126708_0001 completed successfully
2020-02-03 15:08:27,046 INFO mapreduce.Job: Counters: 54
......
再次查看HDFS目录
[root@hadoop101 soft]# hdfs dfs -ls / Found 4 items drwxr-xr-x - root supergroup 0 2020-02-03 10:37 /data drwxr-xr-x - root supergroup 0 2020-02-03 15:08 /out -rw-r--r-- 2 root supergroup 36 2020-02-03 15:07 /test.txt drwx------ - root supergroup 0 2020-02-03 15:07 /tmp其中:/out为计算结果输出目录
查看/out目录结果
[root@hadoop101 soft]# hdfs dfs -ls /out Found 2 items -rw-r--r-- 2 root supergroup 0 2020-02-03 15:08 /out/_SUCCESS -rw-r--r-- 2 root supergroup 32 2020-02-03 15:08 /out/part-r-00000查看统计结果
[root@hadoop101 soft]# hdfs dfs -cat /out/part-r-00000 2020-02-03 15:09:04,764 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false china 1 fanyc 1 hello 3 world 1其中:第2行为安全提示信息,3-6为统计结果
至此,完成了Hadoop的单词统计程序示例。

若有收获,就点个赞吧
0 人点赞
