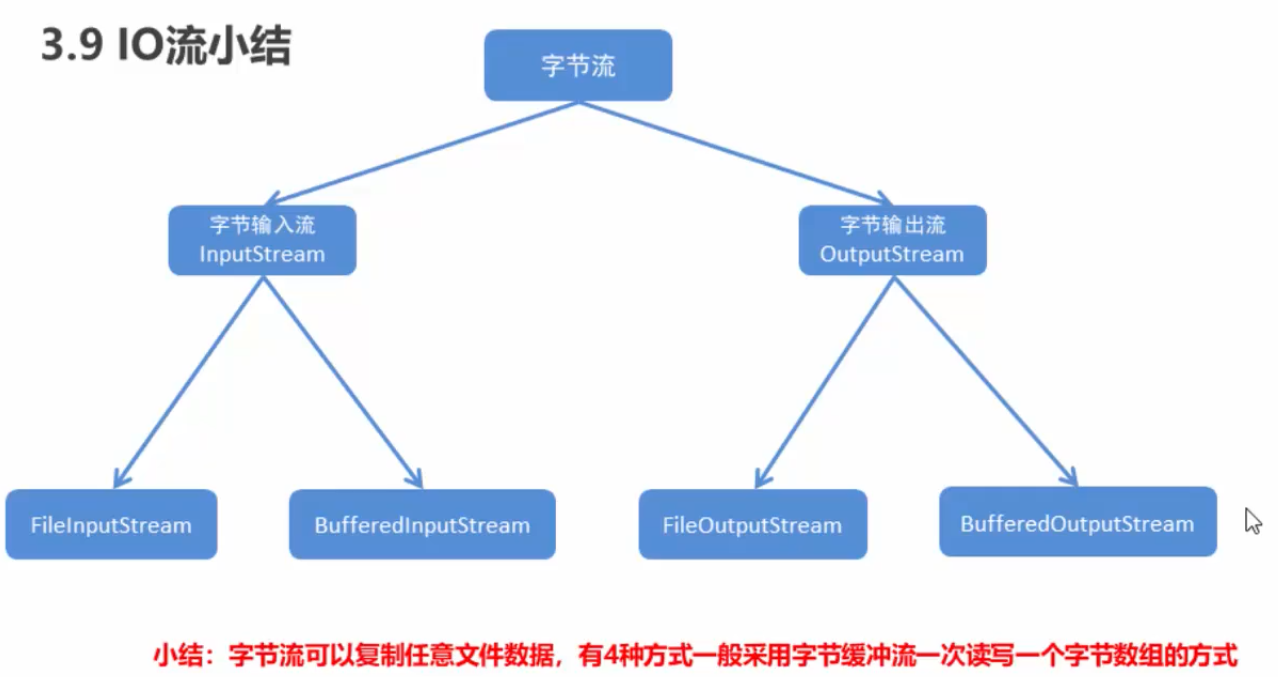
IO流概述和分类
IO流分类
- 按照数据的流向
- 输入流:读数据
- 输出流:写数据
- 按照数据类型来分
- 字节流
- 字节输入流;字节输出流
- 字符流
- 字符输入流;字符输出流
- 字节流
一般来说,我们说io的分类时按照数据类型来分的
那么什么情况下使用?
如果数据通过window自带的记事本软甲打开,我们可以读懂里面的内容,就是用那个字符流否则就是用字节流。如果不知道就是用字节流
字节流写数据
字节流抽象类
InputStream:这个抽象类是表示字节输入流的所有类里的超类
- OutputStream:这个抽象类表示字节输出流的所有类的超类
- 子类名特点:子类名称都是以其父类名作为子类名的后缀
FileOutputStream:文件输出流用于将数据写入File
- FileOutputStream(String name): 创建文件输出流已制定的名称写入文件
使用字节输出流写数据的步骤:
- 创建字节输出流对象(调用系统功能创建了文件,创建字节输出流对象,让字节流对象指向文件)
- 调用字节输出流的写数据方法
-
字节流写数据的3种方式
字节流写数据的两个小问题
字节流写入数据如何实现换行?
window:\r\n
- linux:\n
- mac:\r

如何实现追加写入数据?
- public fileOutput Stream(stringname,boolean,append)
- 创建文件输出流已制定得到名称写入文件,如果第二个参数为true,则字节写入文件的末尾而不是开头
字节流写数据加异常处理
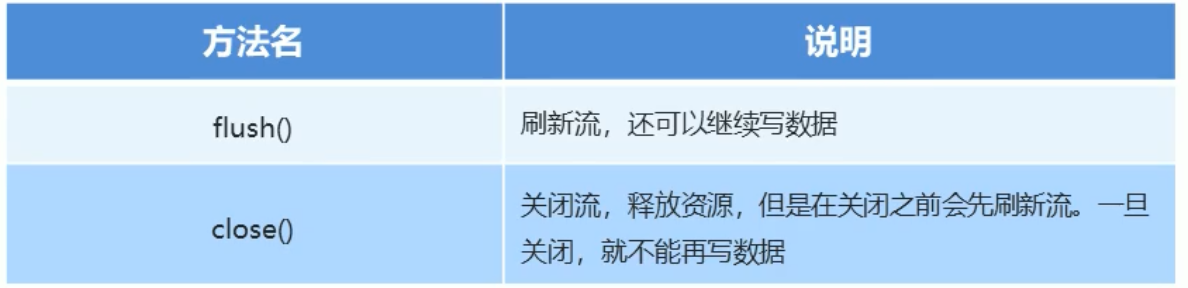
finally:在异常处理时提供finally块来执行所有清除操作,比如说IO六i中的的释放资源
特点:被finally控制的语句一定会执行,除非JVM退出
字节流读数据
File Input Stream(String name):通过打开与实际文件的连接来创建一个File Input Stream,该文件由文件系统中的路径名name命名
使用字节输入流读取的步骤:
- 创建输入流对象
- 调用字节输入流对象的读取方法
-
字节流复制文本文件
复制文本文件,其实就是把文本文件的内容从一个文件中读取出来(数据源),然后写到另一个文件中(目的地)

Buffer Output Stream:该类实现缓冲输出流。通过设置这样的输出流,用于程序可以向底层输出流写入字节,而不必为写入的每个字节大致底层系统的调用
- Buffer Input Stream:创建Buffer Input Stream将创建一个内部缓冲数组,当从流中读取或跳过字节是,内部缓冲区将根据需要从所包含的输入流中重新填充,一次很多字节
构造方法
- 字节缓冲输出流:Buffer Output Stream(OutputStream out)
- 字节缓冲输入流:Buffer Input Stream(InputStrean in)
为什么构造方法需要的是字节流,而不是具体的文件或者路径?
用字节流复制文本文件时,文本
- 汉字在存储的时候,无论选择哪种编码存储,第一个字节都是负数
编码表
基础知识:
- 计算机中存储的信息都是二进制数表示的;我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果
按照某种规则将字符存储到计算机中,成为编码,反之,将存储在计算机中的二进制数按照某种规则解析显示出来,成为解码。这里强调一下:按照哪个编码存储,就比寻按照哪个编码解析,这样显示正确的文本符号,否则就会乱码。
是一个系统支持的所有字符的集合,包括个国家文字、标点符号、图形符号、数字等
- 计算机要准确的存储和识别各种字符集符号,就要进行字符编码,一套字符集必然至少有一套字符编码。
常见的字符集由ASCll字符集,GBXXX字符集,Unicode字符集等
ASCll字符集
ASCll(American standard code for information interchange,美国信息交换标准代码):是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、推个、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)
基本的ASCll字符集,使用7位表示一个字符,共128媳妇,ASCll的扩展字符使用8位表示一个字符,共256字符,方便支持欧洲常用字符,十一i个系统支持的所有字符的集合,包括个国家文字、标点符号、图形符号、数字等
GBXXX字符集
GB2312:简体中文码表,一个小与127的字符的用于与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号,罗马希腊的字母、日文的假名都编进去了,连在ASCll里本来就有的数字、标点、字母都统统重新编写了两个字节长的编码,这就是常说的“全角”字符,而原来在127号 以下的那些就叫“半角”字符了
- GBK:最常用的中文码表,是在GB2312便准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2132标准,同时支持繁体汉字以及日韩汉字等
- GB18030:最新的中文码表。收录了70244个,采用多字节编码,每个字可以由个、2个或4个自己就而组成。支持中国国内少数民族的文字,同时支持繁体汉字及日韩汉字等
Unicode字符集:
- 为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码,标准玩过吗。他最多使用4个字节的数字来表达每个字母、符号、或者文字。有三种编码方案UTF-8、UTF-16、UTF32,最为常用的UTF-8编码
- UTF-8编码:可以用来表示Unicode标准中的热议字符,它是电子邮件存储或者文字的应用中,优先采用的编码,互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。它使用一至四个字节为每个字符编码
- 编码规则:
- 128个US-ASCll字符,只需以恶搞 字符
- 拉丁文等字符,需要2个字节编码
- 大部分常用字(含汉字),使用3个字节编码
- 其他极少使用的Unicode辅助字符,使用4个字节编码
- 编码规则:
小结:采用何种规则编码,就要采用对应的规则解码,否则就会出现乱码
字符串中的编码解码问题
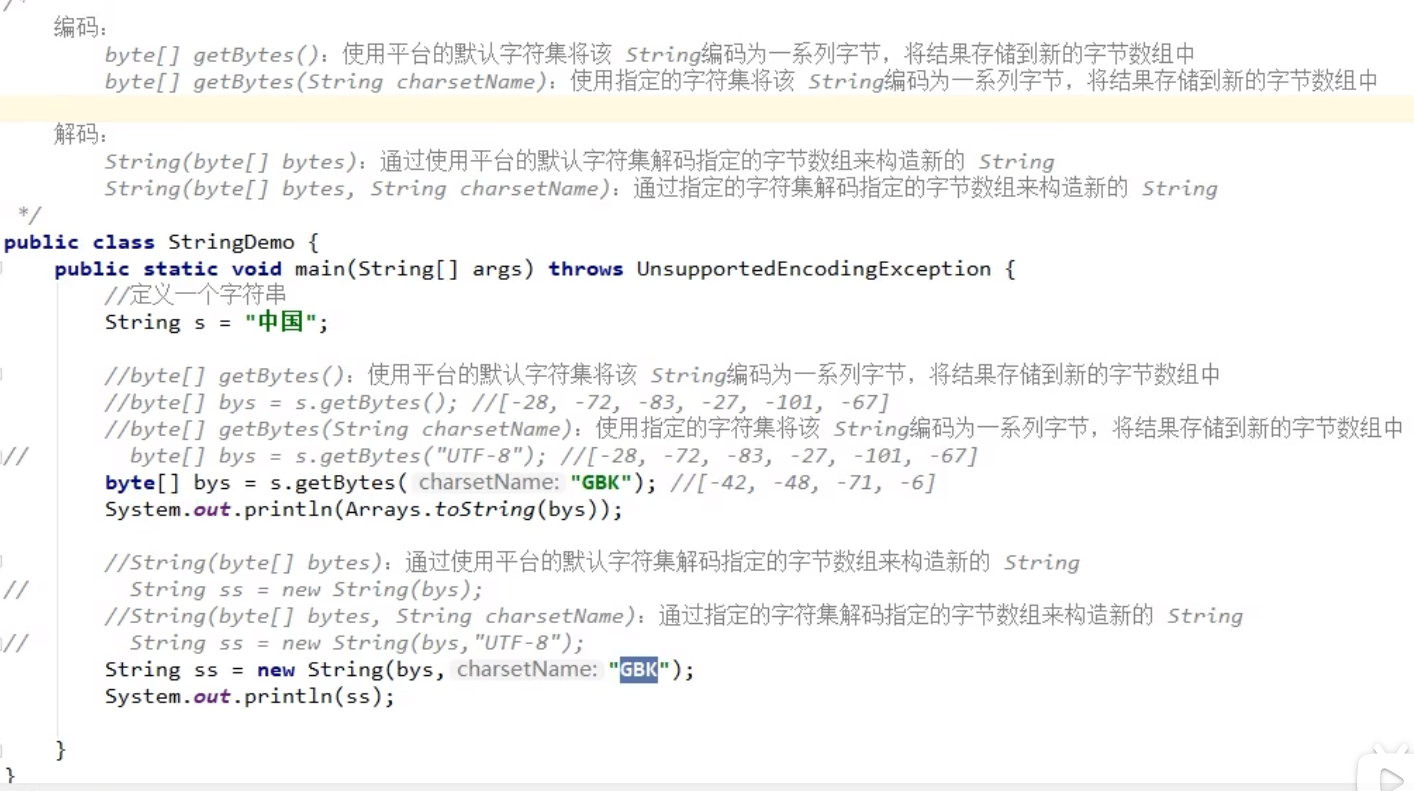
编码:
- byte[]getBytes():使用平台默认的字符集将该string编码为一系列字节,将结果存储到新的字节数组中
- byte[]getBytes(String charsetName):使用指定的字符集将该string编码为一系列字节,将结果存储到新的字节数组中
解码:
- String(byte[]bytes):通过使用平台的默认字符集解码指定的字节数组来构造新的string
- String(byte[]bytes,String charsetName):通过指定的字符集解码指定的字节数组来构造新的string
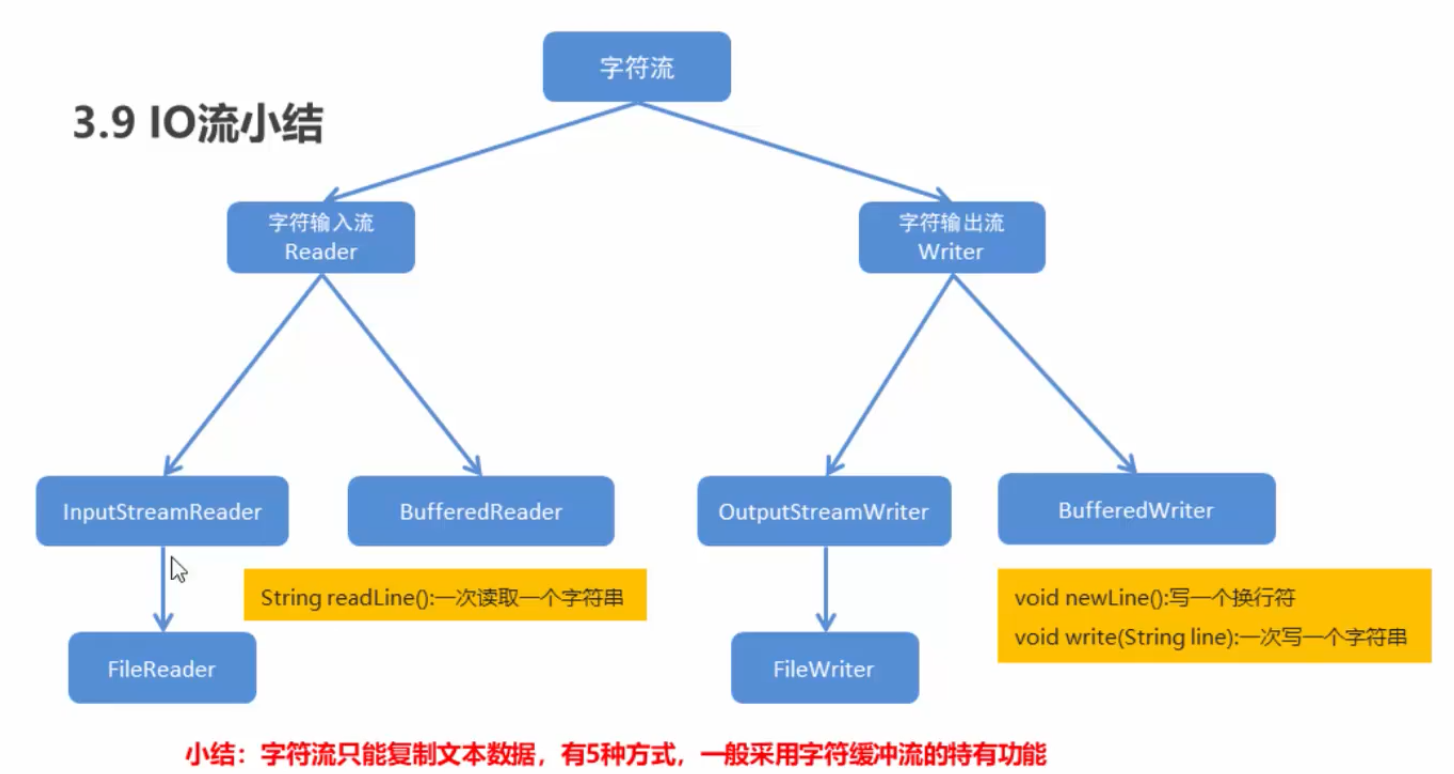
字符流中的编码解码问题
字符流抽象基类
- Reader:字符输入流的抽象类

- Writer:字符输出流的抽象类

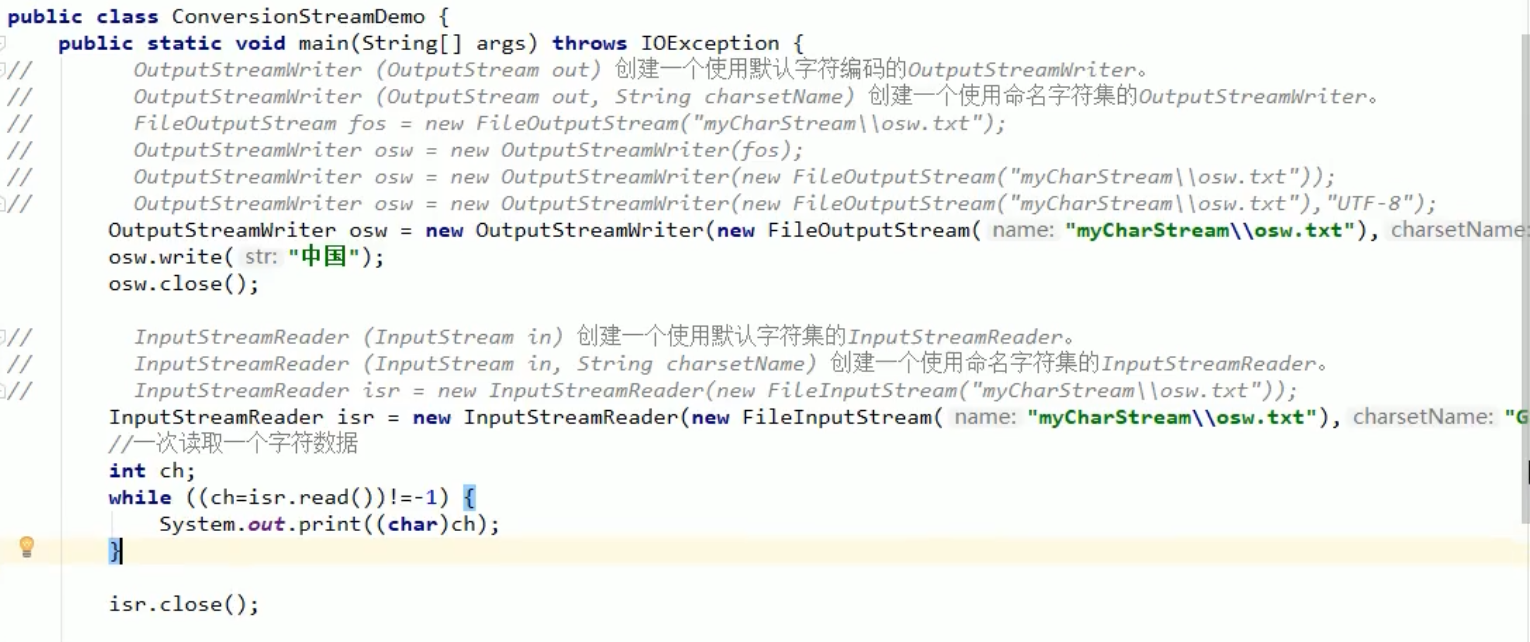
字符流中的编码解码问题相关的两个类
- Input Stream Reader
- Output Stream Writer
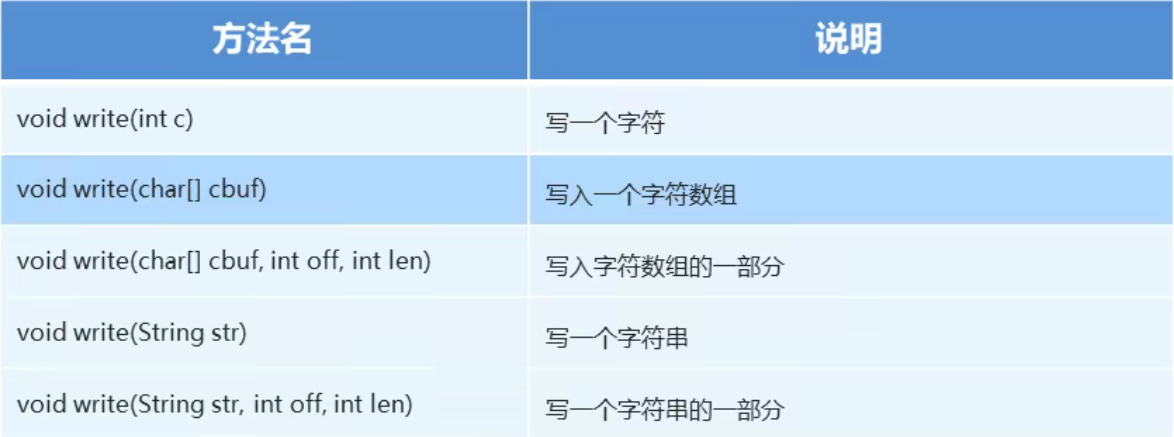
字符流写数据的5种方式
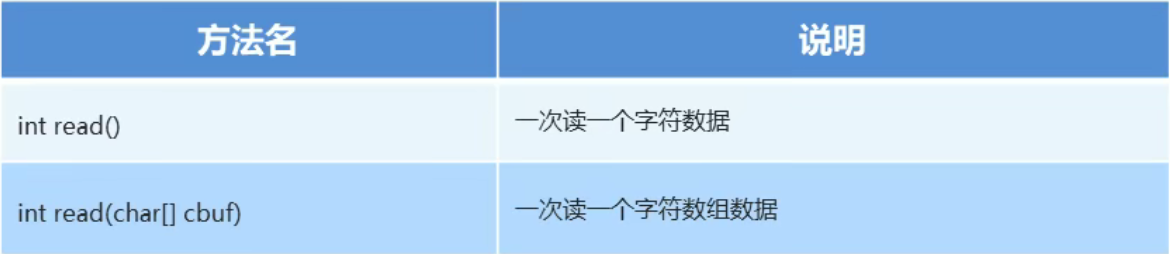
字符流读数据的2种方式
字符缓冲流
字符缓冲流
- BufferedWriter:将文本写入字符输出流,缓冲字符,以提供单个字符,数组和字符串的高效写入,可以指定缓冲区大小,或者可以接受默认大小,默认值足够大,可用于大多数用途。
- BufferedReader:从字符输入流读取文本,缓冲字符,以提供字符,数组和行的高效读取,可以指定缓冲区大小,或者可以使用默认大小,默认值足够大,可用于大多数用途。
构造方法
- 字符流

若有收获,就点个赞吧
0 人点赞
