1 索引
1.1 基本概念
索引的作用
类似于一本书的目录,起到优化查询的作用
索引的分类(算法)
BTree 默认使用的索引类型
R树
Hash
FullText 全文索引
GTS 地理位置索引
BTREE索引算法演变
从二叉树发展而来,查找任何一个数据所花的时间是相同的,从B-tree——>B+tree——>Btree,B+tree是在原来B-tree索引的基础上在叶子节点上增加了指针,这样就可实现从一个叶子节点直接到下一个叶子节点,无需再从根再次便利,Btree又是再B+tree的基础上,在枝节点上增加了索引,进一步优化了查找的性能。
叶子节点:存放数据,每一个节点所在的大小为16K,即一个页的大小。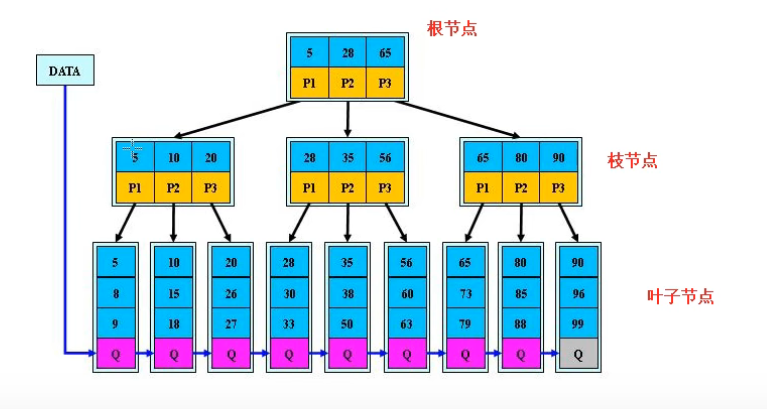
Btree索引功能上的分类
1.1 索引的分类
创建索引大致过程
1、管理员选择一个列创建辅助索引
2、MySQL会自动将此列的值取出来
3、将此列值进行自动排序
4、将排好序的数据,均匀的存储到索引的叶子节点
5、生成枝节点和根节点
1.1.1 辅助索引
1、提取索引列的所有值,进行排序
2、将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点
3、在叶子节点中的值,都会对应存储主键ID
辅助索引细分
a、单列辅助索引,即一个列来做索引;
b、联合索引(覆盖索引),即多个列来做索引,比较重要,不好理解;
c、唯一索引,建索引的列是唯一的unique;
1.1.2 聚集索引
1、MySQL会自动选择主键作为聚集索引列,没有主键会选择唯一键,如果都没有会生成隐藏的主键
2、在MySQL进行存储数据时,会按照聚集索引列值的顺序,有序的存储数据行
3、将聚集索引直接将原表的数据页作为叶子节点,然后提取聚集索引列向上生成枝节点和根
1.1.3 辅助索引和聚集索引的区别
1)表中的任何一个列都可以创建辅助索引,在你有需要的时候,只要名字不同即可
2)在一张表中,聚集索引只能有一个,一般是主键
3)辅助索引,叶子节点只存储索引列的有序值+聚集索引列值
4)聚集索引,叶子节点存储的是有序的整行数据
5)MySQL的表数据存储的是聚集索引组织表
1.2 索引数高度
索引树高度应当越低越好,一般维持在3-4最佳
哪些情况会影响索引的高度:
1、数据行数较多
分表:partion用的比较少了
分片,分布式架构,分库分表
2、字段长度
业务允许的情况下,尽量选择字符长度短的列作为索引列
业务不允许,采用前缀索引
3、数据类型
char和varchar,当对char和varchar列进行创建索引时,建议使用varchar列,因为char是定长类型的数据,存储数据时可能有空字符做填充,因此在创建索引时空值也会被拿来创建索引,效率较低,且浪费存储空间;
enum,因为枚举类型的数据可以通过数字下标获取数据,因此更易创建索引,效率较高;
1.3 索引的命令操作
1、查询索引
desc 表;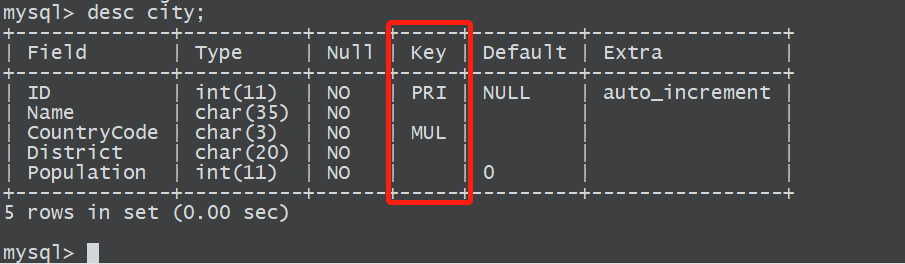
PRI —>主键索引,即聚集索引
MUL—>辅助索引
UNI —>唯一索引
mysql> show index from city;
2、创建索引
单列的辅助索引:
mysql>alter table city add index idx_name(name);
3、多列联合索引
mysql>alter table city add index idx_c_p(countrycode,population);
4、唯一索引
mysql>alter table city add unique index uidx_dis(district); 此方法还可查看此列是否存在重复值;
mysql>select count(distinct district) from city;
5、前缀索引
只取前多少个字符进行创建索引
mysql>alter table city add index idx_dis(district(5));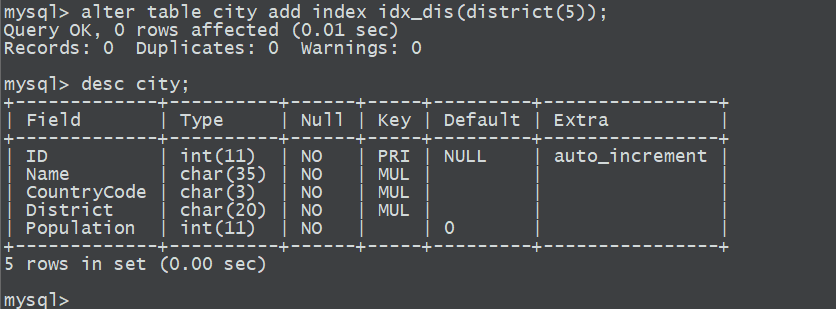
6、删除索引
mysql>alter table city drop index idx_name;
1.4 压力测试
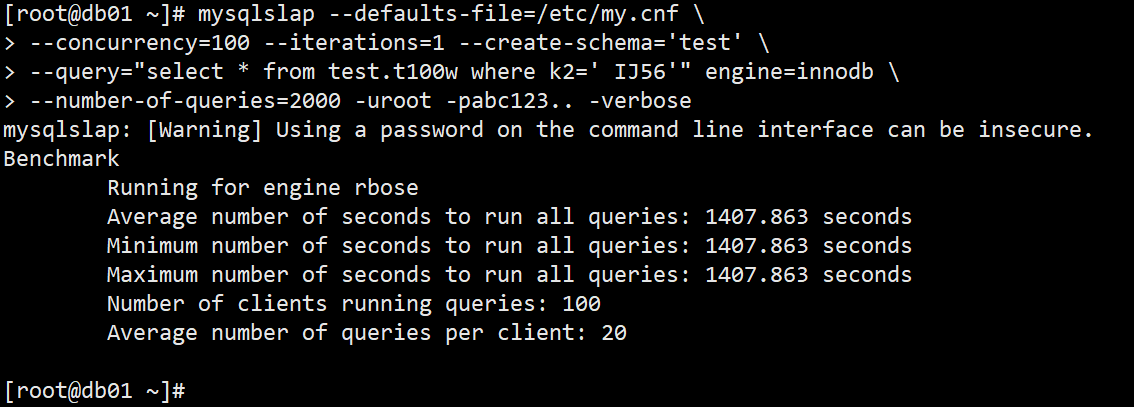
1.4.1 未做优化之前的测试
模拟100个用户,做了两千次查询;
mysqlslap —defaults-file=/etc/my.cnf \
—concurrency=100 —iterations=1 —create-schema=’test’ \
—query=”select * from test.t100w where k2=’ IJ56’” engine=innodb \
—number-of-queries=2000 -uroot -pabc123.. -verbose
1.4.2 优化后
1)对k2列创建索引
mysql> use test
mysql> alter table t100w add index idx_k2(k2);
2)执行压测:结果比不优化前快了将近2500倍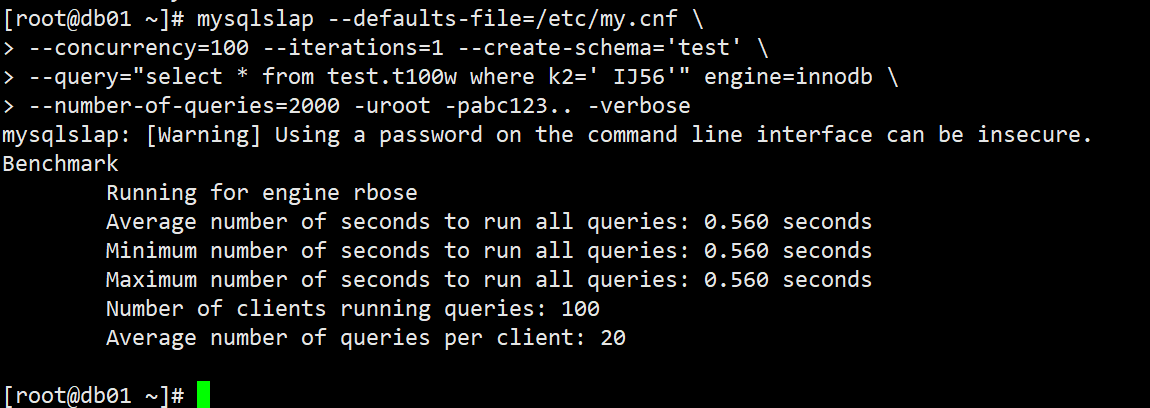
2 执行计划分析
将优化器,选择后的执行计划,截取出来,便于管理判断语句的执行效率
获取执行语句
desc SQL语句
explain SQL语句
mysql>desc select from test.t100w where k2=’IJ56’;
mysql> explain select from test.t100w where k2=’IJ56’;
2.1 table

2.2 type
查询的类型:
全表扫描 : all
索引扫描 : index,range,ref,eq,const(system),null(从左往右性能依次更好)
1)index:全索引扫描
>desc select countrycode from city;
2) range:索引范围扫描(< > <= >= between and or in like)
mysql> desc select from city where id>2000;
mysql> desc select from city where countrycode like “CH%”;
对于辅助索引来讲,!=和not in等不等值语句是不走索引的
对于主键列索引来讲,!=和not in等语句是走range,其余都是all
对于like “%CH%”这种也是不走索引的,全表扫描
mysql> desc select from city where countrycode=’CHN’ or countrycode=’USA’;
mysql> desc select from city where countrycode in (‘CHN’,’USA’);
一般改写为union all
desc select from city where countrycode=’CHN’
union all
select from city where countrycode=’USA’;
3)ref:辅助索引等值查询
desc select from city where countrycode=’CHN’
union all
select from city where countrycode=’USA’;
4)eq_ref:多表连接时,子表使用主键列或唯一列作为连接条件
A join B on A.x=B.y
mysql> desc select city.name,country.name from city join country on city.countrycode=country.code where city.population<100;
5)const(system):主键或者唯一键的等值查询
>desc select from city where id=100;
*6)null 所查询的数据在表中不存在
前提:经个人测试,必须是主键或者唯一键,否则type为all
2.3 possible_key

2.4 key
查询时实际上真正选择了哪个索引
alter table city add index idx_c_p(countrycode,population)
2.5 key_len
作用:索引覆盖长度
联合索引
varchar(x) 长度说明 utf8mb4编码
1、能存x个任意字符
2、不管存储的是字符,数字,中文,1个字符最大预留的最大长度是4个字节
3、对于中文,一个字占用4个字节
4、对于数字和字母,1个字符占用1个字节
select length() from test;
联合索引 add index idx(a,b,c,d)
原则:唯一值多的列放在最左侧性能更佳
索引长度计算:
说说下面为什么索引长度为60字节,当列属性没有定义为not null时,会占用一个字节来说明是否为空,同时varchar类型数据会额外占用2个字节来定义起始和结束位置,所以在下图key_len是这样算出来的(24+1)+(44+1+2)+(34+1)+(44+1+2)=60,这里为什么是乘4,跟编码有关,上面有做解释。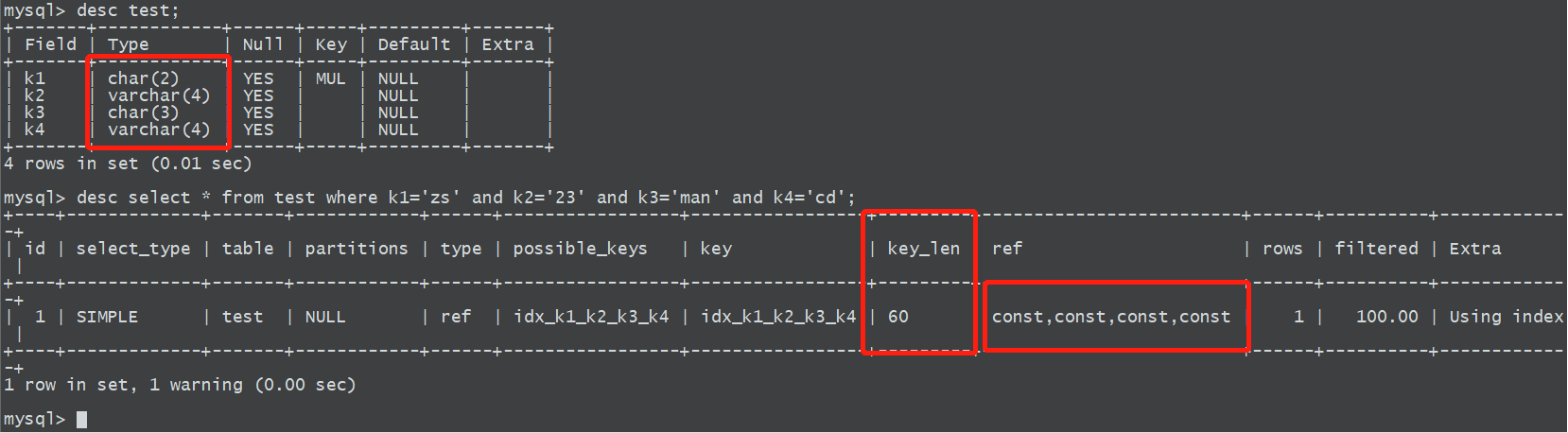
1、只要所有的查询,都是基于索引列的等值查询条件,那么在书写查询时与列值的顺序无关
如存在一张列名为k1,k2,k3,k4的表test,对其创建了联合索引alter table test add index idx(k1,k2,k3,k4);
以下两种方式的查询性能是一样的:因为优化器会自动做查询条件的排序
>desc select from test where k1=’01’ and k2=’zhangsan’ and k3=’f’ and k4=’文科’;
>desc select from test where k2=’zhangsan’ and k3=’f’ and k4=’文科’ and k1=’01’;

2、不连续的部分条件
下面这种方式虽然创建联合索引,但是在查询时索引的覆盖长度只会覆盖到k1,因为没有了k2,条件不连续了
>desc select from test where k1=’01’ k3=’21’ and k4=’89’;如出现k1,k2,k4则会覆盖到k1和k2。
3、在where查询中如果出现> < >= <= like
当出现不等值查询时,尽量将条件放在最后面,并按照这种顺序创建相应的索引,因为索引只会覆盖到不等值查询处;如k1>’0002’ and k2=’zhangsan’ and and k3=’f’ and k4=’理科’;此时索引长度只会覆盖到k1,而不是k1和k2。
1)select from test where k2=’zhangsan’ and k3=’f’ and k4=’理科’ and k1>’0002’;
所以以上查询建议这样创建索引:add index idx(k2,k3,k4,k2);
4、多子句查询,应用联合索引
按照子句的条件顺序创建联合索引即可,如下示例:
>desc select from test where k1=’0001’ order by k2;
>alter table test add index idx(k1,k2);
2.6 extra

重点关注当出现using filesort时,说明在查询中有关排序的条件列时没有合理的应用索引,当出现以下的一些排序操作时,通常会涉及到排序问题,此时应关注key_len应用的长度,分析联合索引的覆盖长度,然后调整索引创建顺序
1、order by
2、group by
3、distinct
4、union
2.7 explain (desc)使用场景(面试题)
你做过哪些优化?你用过什么优化工具?你对索引这块怎么优化的?
题目意思:我们公司业务慢,请你从数据库的角度分析原因
mysql出现性能问题,我总结有两种情况:
1)应急的慢:突然夯住
应急情况:数据库hang(卡了,资源耗尽)处理过程
a、show processlist;获取到导致数据库hang的语句
b、explain分析SQL的执行计划,有没有走索引,索引的类型情况
c、建索引,改语句
2)—段时间慢(持续性的):
a、记录慢日志slowlog,分析slowlog
b、explain分析SQL的执行计划,有没有走索引,索引的类型情况
c、建索引,改语句
3 索引应用规范
3.1 建立索引的原则(DBA运维规范)
1)必须要有主键,如果没有可以做为主键条件的列,创建无关列
2)经常做为where条件列order by group by join on,distinct 的条件
3)最好使用唯一值多的列作为联合索引前导列
4)列值长度较长的索引列,我们建议使用前缀索引
5)降低索引条目,一方面不要创建没用索引,不常使用的索引清理,perconatoolkit(xxxxx)(因为在创建索引时会存在锁表的问题,同时在插入新的数据时,也会维护更新索引,导致性能影响)
6)索引维护要避开业务繁忙期
7)小表不建索引
3.2 不走索引的情况(开发规范)
1)没有查询条件,或者查询条件没有建立索引,如select _ from city; _select from city where 1=1;
2)查询结果集是原表中的大部分数据,应该是25%以上
3)索引本身失效,统计数据不真实
面试题:同一个查询语句突然变慢?
统计信息过旧,及频繁的数据更新,导致的索引未及时更新,导致索引失效,导致查询时未走索引
4)查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,,/,!等)
如select from city where id-99=1;
5)隐式转换导致索引失效
如当我们定义的列为字符串类型时,但是我们插入的数据类似12,23,35…等数值类型,其实数据库在保存时也是以字符串类型保存,但是在查询时性能有差异,如select from k1=’12’;select * from k1=12这两种查询方式,第一种方式会走索引,第二种方式数据库会默认先把12转为字符串类型(及隐式转换),然后再做查询,导致性能较低
6) <>,not in不走索引(辅助索引)
7)likeli%aa””百分号在最前面不走
8) 联合索引(及本章节第二部分讲的即便创建了联合索引也不走的情况)

若有收获,就点个赞吧
0 人点赞
