1 主从复制-MySQL Replication
1.1 主从复制基础概念
主从架构
企业高可用标准:根据全年无故障率(非计划内故障停机)来评估;
如:99.9%、99.99%、99.999%
高可用架构方案:
- 负载均衡:有一定高可用,如LVS,Nignx
- 主备系统:有高可用,但需要切换,是单活的架构,如Keepalived、MHA、MMM
- 真正的高可用(多活系统):NDB Cluster、Oracle RAC、Sysbase cluster、InnoDB Cluster(MGR)、PXC、MGC
主从复制职责
- 搭建主从复制
- 主从原理熟悉
- 主从的故障处理
- 主从延时
- 主从架构的特殊架构的配置使用
- 主从架构的演变
主从复制介绍
- 主从复制基于binlog来实现的
- 主库发生新的操作,都会记录binlog
- 从库取得主库的binlog进行回放
-
1.2 主从复制架构部署
3307作为主库,3308为从库
构建主从大致思路: 2个或以上的数据库实例
- 主库需要二进制日志
- server_id要不同,区分不同的节点
- 主库需要建立专用的复制用户(专门的用户具备replication slave此权限)
- 从库应该通过备份数据完成主库历史数据的同步
- 告诉从库,谁是主库,怎么连?(告诉从库哪些信息如ip,port,user,password,二进制日志起点)
-
1.2.1 准备多实例
启动主库,重新初始化从库,使从库为一个新的环境
pkill mysqldsystemctl start mysqld3307rm -rf /data/mysql/instance-3308/data/*rm -rf /data/mysql/instance-3308/mysql-bin.*mysql --initialize-insecure --user=mysql --basedir=/app/mysql --datadir=/data/mysql/instance-3308/datasystemctl start mysqld3308mysql -S /data/mysql/instance-3308/mysql.sock -e "select @@port"mysql -uroot -pabc123.. -S /data/mysql/instance-3307/mysql.sock -e "select @@port"
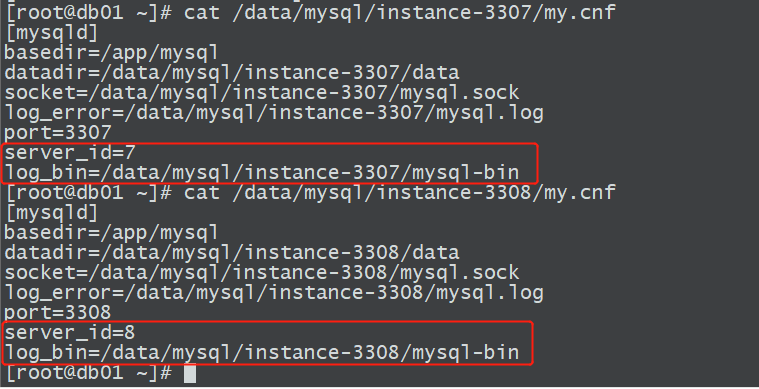
1.2.2 检查配置文件
检查主库和从库是否开启二进制日志,并保证server_id不同
1.2.3 主库创建复制用户
mysql -uroot -pabc123.. -S /data/mysql/instance-3307/mysql.sock -e "grant replication slave on *.* to repl@'10.0.0.%' identified by 'abc123..';"
1.2.4 主库备份
主库备份
mysqldump -uroot -pabc123.. -S /data/mysql/instance-3307/mysql.sock -A --master-data=2 --single-transaction -E -R --trigger >/tmp/full.sql
从库根据主库备份恢复数据
set sql_log_bin=0;source /tmp/full.sql;set sql_log_bin=1;
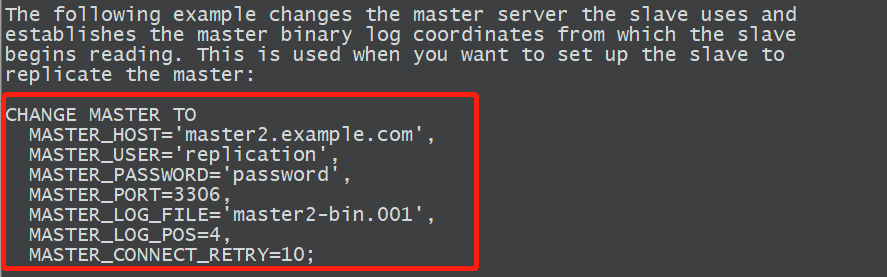
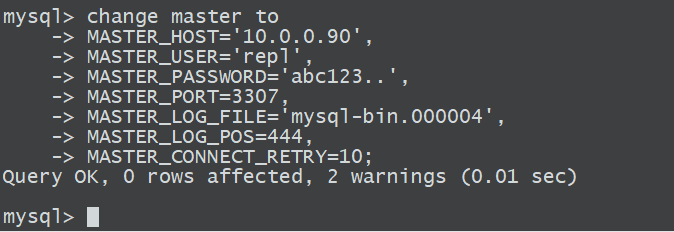
1.2.5 告诉从库主库的信息
mysql>help change master to
vim /tmp/full.sql
根据备份文件找到对应得binlog文件,以及起始位置
开始构建主从,告诉从库主库的信息change master toMASTER_HOST='10.0.0.90',MASTER_USER='repl',MASTER_PASSWORD='abc123..',MASTER_PORT=3307,MASTER_LOG_FILE='mysql-bin.000004',MASTER_LOG_POS=444,MASTER_CONNECT_RETRY=10;
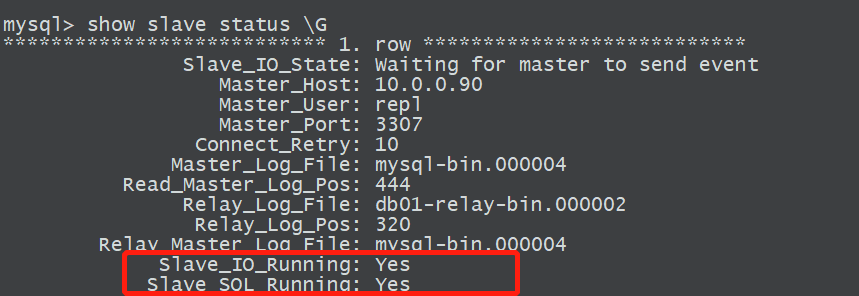
1.2.6 从库开启复制线程(IO,SQL)
start slave;

备注:如果信息输入错误,需要重新输入时,需要做以下步骤,然后重新change master to
stop slave;
reset slave all;1.2.7 从库检查主从复制的状态
2 主从复制原理
2.1 主从复制中涉及的文件
主库涉及的文件
binlog
从库涉及的文件
这三个文件一般存放在从库数据目录下
relay-bin 中继日志
master.info 主库信息文件
relay-log.info relaylog应用的信息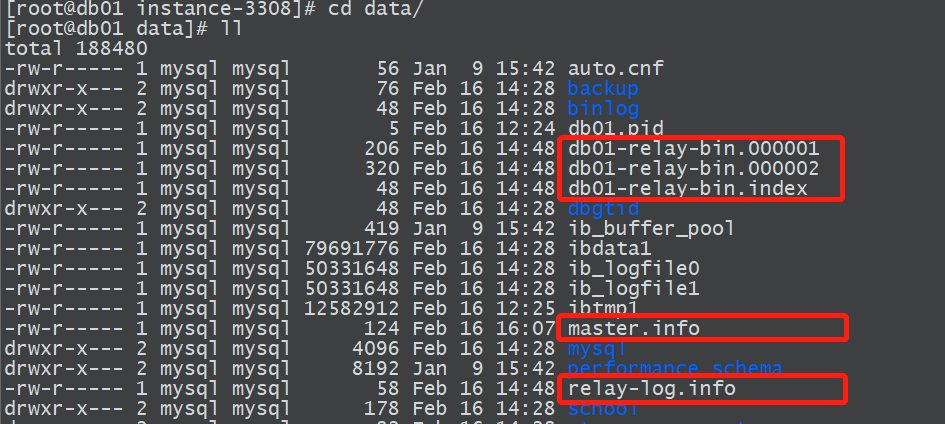
2.2 主从复制中涉及的线程
主库涉及线程
binlog_dump Thread :DUMP_T
从库涉及线程
SLAVE_IO_THREAD :IO_T
SLAVE_SQL_THREAD :SQL_T2.3 主从复制工作原理
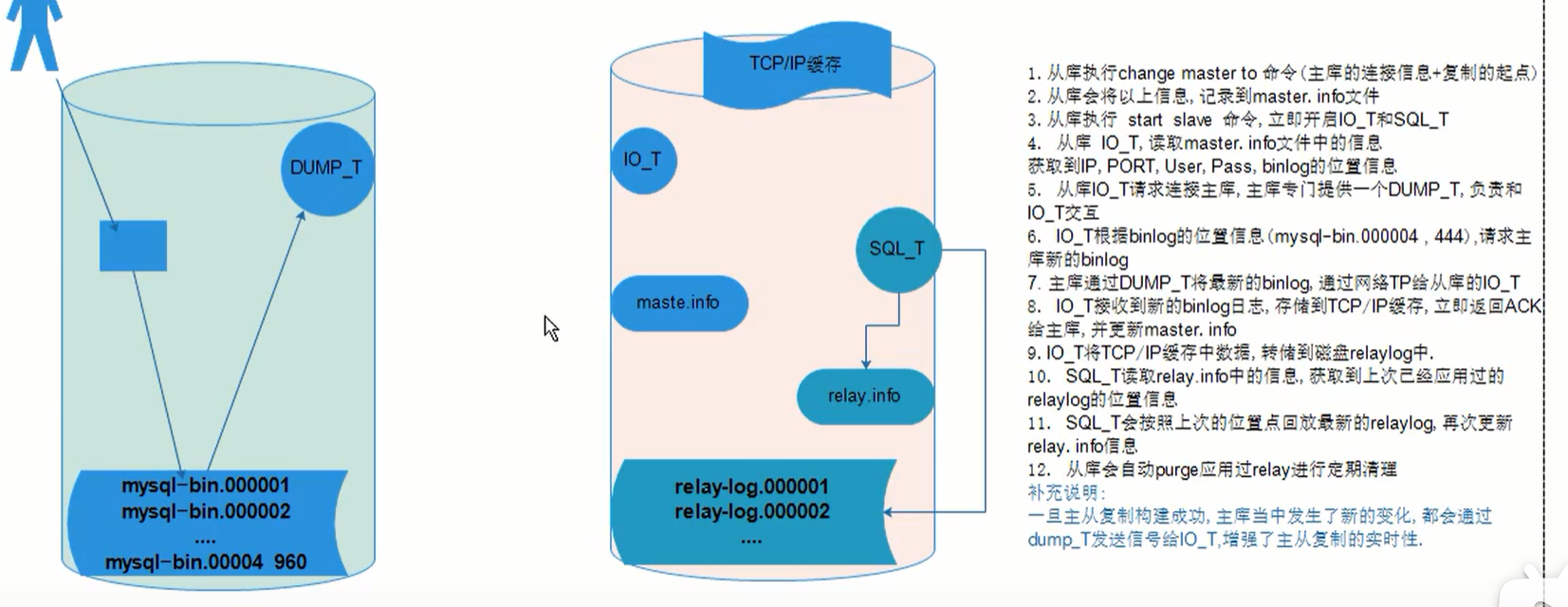
主从复制工作(过程)原理
01、从库执行change master to 命令(主库的连接信息+复制的起点)
02、从库会将以上信息,记录到master.info文件
03、从库执行start slave命令,立即开启IO_T和SQL_T
04、从库IO_T,读取master.info文件中的信息获取到IP,PORT,User,Password,binlog的位置信息
05、从库IO_T请求连接主库,主库专门提供一个DUMP_T,负责和IO_T交互
06、IO_T根据binlog的位置信息(mysql-bin.000004 , 444),请求主库新的binlog
07、主库通过DUMP_T将最新的binlog通过网络传输给从库的IO_T
08、IO_T接收到新的binlog日志,存储到TCP/IP缓存,立即返回ACK给主库,并更新master.info(master.info记录了最新的binlog位置点)
09、IO_T将TCP/IP缓存中数据转储到磁盘relay-bin中
10、SQL_T读取relay-log.info中的信息,获取到上次已经应用过的relay-bin的位置信息
11、SQL_T会按照上次的位置点回放最新的relay-bin,再次更新relay-log.info信息
12、从库会自动purge应用过relay-bin进行定期清理
补充说明:
一旦主从复制构建成功,主库当中发生了新的变化都会通过Dump_T发送信号给IO_T,增强了主从复制的实时性3 主从复制监控、及故障
3.1 主库监控
主库一般不需要监控,通过show processlist就可以看到连接的dump线程,只要主从一直开启,此线程一直存在;
3.2 从库监控
mysql> show slave status \G
show slave status \G输出说明
3.3 主从复制故障
3.3.1 从库IO 线程故障
我们可以通过分析IO线程在做哪几件事情来判断在这几个过程中可能出现的问题:连接主库、请求binlog、存储binlog到relayl-bin
1)连接主库:connecting状态
网络,连接信息错误或变更了,防火墙,连接数上限(mysql有连接上限设置)
排查思路:尝试使用复制用户手工登录
2)请求binlog
binlog没开、binlog损坏,不存在、主库执行reset master
注意:主库执行reset master之后,主从架构如何恢复
从库执行:
大致的思路是,主库执行了reset master之后,binlog从000001开始,且position可能存在变化,此时从库无法同步主库的binlog,主从断裂,因此需要重新开启主从;stop slave;reset slave all;#重新change master to告诉从库信息,主要是binlog文件和position号CHANGE MASTER TOMASTER_HOST='10.0.0.90',MASTER_USER='repl',MASTER_PASSWORD='abc123..',MASTER_PORT=3307,#查看主库binlog状态,根据状态更新该值MASTER_LOG_FILE='mysql-bin.000001',#查看主库binlog状态,根据状态更新该值MASTER_LOG_POS=154,MASTER_CONNECT_RETRY=10;start slave;
3)存储binlog到relay-bin
文件无法写入,可能是权限问题,一般不会出现此问题3.3.2 SQL线程故障
可能故障:
1、回放relay-bin时,因relay-bin文件损坏,回放失败,即执行sql语句失败;
2、以上的可能性较少,因为从库是同步主库的binlog信息,在主库都能够执行,说明binlog没什么问题,如执行失败,很有可能是在从库上面提前做了写操作,导致在回放binlog日志时,产生数据冲突,SQL语句执行失败。
解决方法一:stop slave ;set global sql_slave_skip_counter = 1;start slave ;#将同步指针向下移动一个,如果多次不同步,可以重复操作。start slave ;
解决方法二:
/etc/my.cnfslave-skip-errors = 1032 ,1062 ,1007常见错误代码:1007:对象己存在1032:无法执行DML1062:主键冲突,或约东冲突
但是,以上操作有时是有风险的,最安全的做法就是重新构建主从,把握一个原则,一切以主库为主。为了避免SQL线程故障,建议做以下操作
1)从库只读
2)使用读写分离中间件(生产中较为常用)
在主从库之前搭建中间件,由中间件来判断将数据丢给主库还是从库 atlas
- mycat
- ProxySQL
-
4 主从延时监控及原因
4.1 主库方面原因
1、binlog写入不及时
sync_binlog=1
2、默认情况下dump_t是串行传输binlog,在并发事务量大或大事务时,由于dump_t是串行工作的,导致传送日志较慢
如何解决:
必须开启GTID,使用group commit方式,可以支持DUMP_T并行传输
3、主库极其繁忙 慢语句
- 锁等待
- 从库个数
-
4.2 从库方面原因
1、传统复制(Classic)中
如果主库并发事务量很大,或者出现大事务,由于从库是单SQL线程,导致不管传的日志有多少,只能一次执行一个事务
解决办法: 5.6版本有了GTID,可以实现多SQL线程,但是只能基于不同库的事务进行并发回放(针对库级别的并发)
- 5.7版本中有了增强的GTID,增加了seq_no,增加了新型的并发SQL线程模式(logical_clock),MTS技术
2、主从硬件差异较大
3、主从的参数配置
4、主从索引不一致
5、版本差异
4.3 主从延时的监控
主库方面监控:检查主从的binlog文件以及position号是否一致,一致则说明传输binlog日志没有问题
主库执行>show master status;
从库执行>show slave status;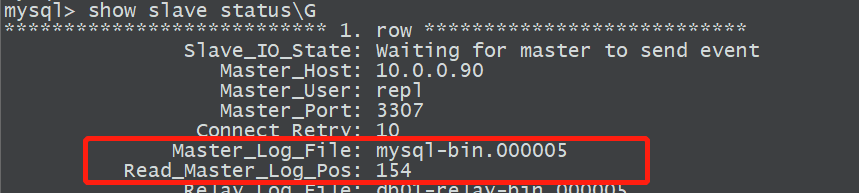
从库方面排查:检查同步一致以后,检查relaylog执行的LSN号与同步的号差异是否较大
从主库同步过来的binlog日志
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 154
从库的relay-bin日志
Relay_Log_File: db01-relay-bin.000005
Relay_Log_Pos: 367
已经执行的binlog
Exec_Master_Log_Pos: 154
Relay_Log_Space: 739
5 主从复制高级进阶
5.1 延时从库
5.1.1 介绍及配置
SQL线程延时:数据已经写入了relaylog中了,SQL线程”慢点”运行,一般企业建议3-6个小时,具体看公司运维人员对于故障的反应时间了
配置
stop slave;CHANGE MASTER TO MASTER_DELAY=300;start slave;show slave status \GSQL_Delay:300SQL_Remaining_Delay:NULL
5.1.2 延时从库处理逻辑故障
5.1.2.1 延时从库的恢复思路
1)监控到数据库逻辑故障
2)停从库的SQL线程,记录已经回放的位置点(截取位置起点)
stop slave sql_thread;show slave status \GRelay_Log_File:Relay_Log_Pos:
3)截取relaylog日志
起点:show slave status \GRelay_Log_File:Relay_Log_Pos:终点:drop之前的位置点show relaylog events in ' '进行截取
4)模拟SQL线程回放日志
从库 source
5)恢复业务
情况1:就一个库的话
从库替代主库工作
情况2:
从库导出故障库,还原到主库中
5.1.2.2 故障演练恢复
1)主库模拟数据和故障
create database delay charset utf8mb4;use delay;create table t1 (id int);insert into t1 values(1),(2),(3);commit;drop database delay;
2)停止从库sql线程
stop slave sql_thread;
3)找到relaylog截取的起点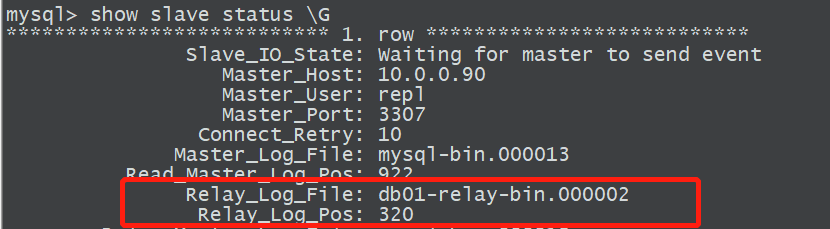
4)找到relaylog截取的终点
找到故障点之前的位置,这里左边的Pos代表relaylog的位置号,右边的End_log_pos代表的是与relaylog对应的binlog的位置点号;这里找到drop之前的位置点993;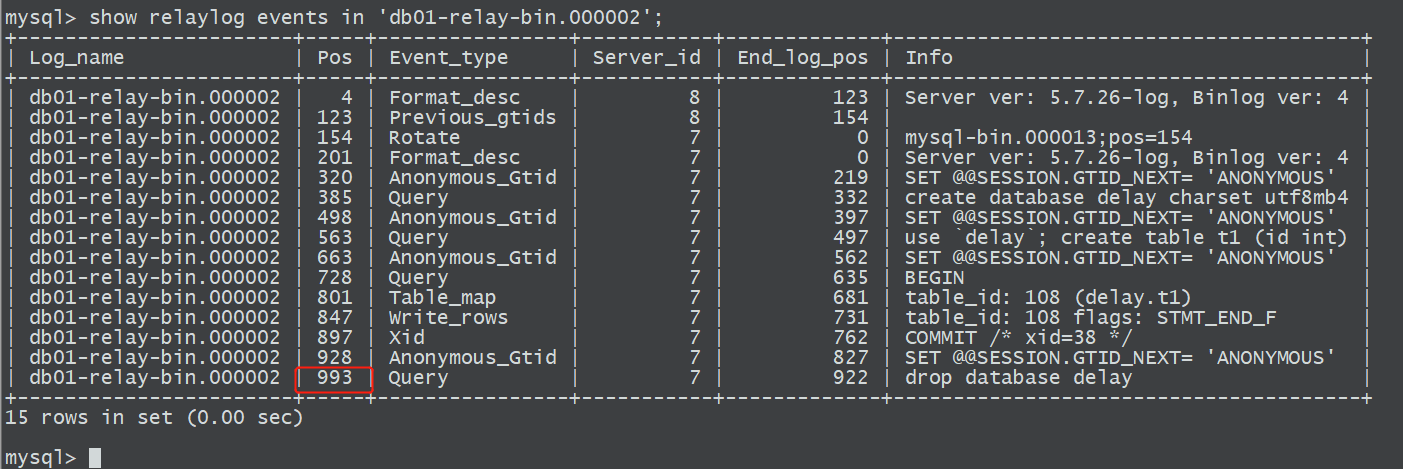
5)截取relaylog
]# cd /data/mysql/instance-3308/data/
]# mysqlbinlog —start-positon=320 —stop-position=993 db01-relay-bin.000002 >/tmp/relay.sql
6)恢复relay
set sql_log_bin=0;source /tmp/relay.sqlset sql_log_bin=1;
5.2 过滤复制
5.2.1 快速恢复上一步的环境至主从架构
1、从库执行
mysql> drop database delay;Query OK, 1 row affected (0.01 sec)mysql> stop slave;Query OK, 0 rows affected (0.01 sec)mysql> reset slave all;
2、主库执行:
reset master;
3、从库执行:
change master to master_host='10.0.0.90',master_user='repl',master_password='abc123..',master_port=3307,master_log_file='mysql-bin.000001' ,master_log_pos=154,master_connect_retry=10;start slave;
5.2.2 过滤复制
5.2.2.1 在主库记录binlog的时候进行过滤
此方法很少使用,不记录binlog日志还是比较危险的操作
show master status;
通过以下这两个参数进行控制,写到my.cnf配置文件中
binlog_do_db= #白名单,只记录在此处出现的数据库的binlog日志
binlog_ignore_db= #黑名单,不记录在此处出现的数据库的binlog日志
5.2.2.2 在从库上过滤
在从库上过滤的实现原理是通过在SQL线程在回放relaylog时进行过滤
replicate_do_db= #白名单
replicate_Ignore_db= #黑名单
示例:
vim /data/mysql/instance-3308/my.cnf
replicate_do_db=repl
systemctl restart mysqld-3308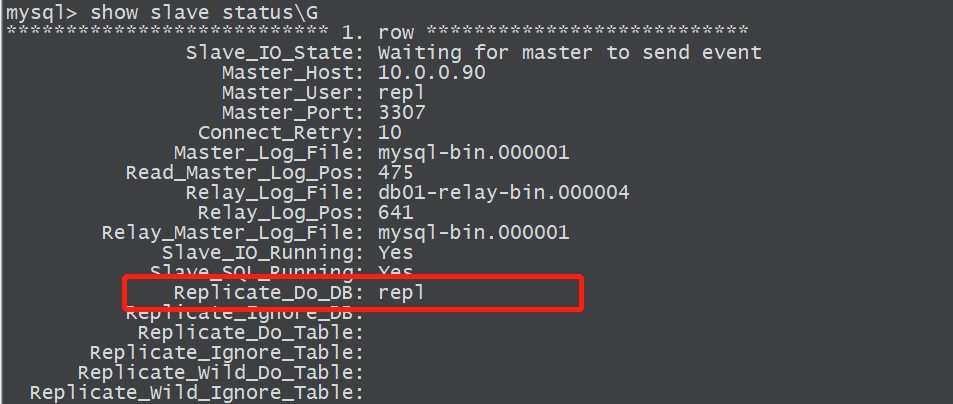
5.3 GTID复制
5.3.1 介绍
DTID是对于一个已提交事务的唯一的编号,并且是一个全局(主从复制)唯一的编号。它的官方定义如下:
GTID=source_id : transaction_id
什么是server_uuid,和server-id区别
核心特性:全局唯一,具备幂等性
5.3.2 GTID核心参数
gtid-mode=on ——启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true ——强制GTID的一致性
log-slave-updates=1 ——slave更新是否记入日志,强制从库更新二进制日志
5.3.3 搭建GTID复制,1主2从
准备单个数据库节点:
1)清理环境
pkill mysqld
rm -rf /data/mysql/instance01/
rm -rf /data/binlog/
2)准备配置文件
主库db01:
cat >/etc/my.cnf<<EOF[mysqld]basedir=/app/mysql/datadir=/data/mysql/instance-3306/data/socket=/data/mysql/instance-3306/mysql.sockserver_id=90port=3306secure-file-priv=/tmpautocommit=0log_bin=/data/mysql/instance-3306/binlog/mysql-binbinlog_format=rowgtid-mode=onenforce-gtid-consistency=truelog-slave-updates=1[mysql]prompt=db01 [\\d]>EOF
slave1(db02)
cat >/etc/my.cnf<<EOF[mysqld]basedir=/app/mysql/datadir=/data/mysql/instance-3306/data/socket=/data/mysql/instance-3306/mysql.sockserver_id=91port=3306secure-file-priv=/tmpautocommit=0log_bin=/data/mysql/instance-3306/binlog/mysql-binbinlog_format=rowgtid-mode=onenforce-gtid-consistency=truelog-slave-updates=1[mysql]prompt=db02 [\\d]>EOF
slave2(db03)
cat >/etc/my.cnf<<EOF[mysqld]basedir=/app/mysql/datadir=/data/mysql/instance-3306/data/socket=/data/mysql/instance-3306/mysql.sockserver_id=92port=3306secure-file-priv=/tmpautocommit=0log_bin=/data/mysql/instance-3306/binlog/mysql-binbinlog_format=rowgtid-mode=onenforce-gtid-consistency=truelog-slave-updates=1[mysql]prompt=db03 [\\d]>EOF
3)初始化数据
mysqld —initialize-insecure —user=mysql —basedir=/app/mysql —datadir=/data/mysql/instance-3306/data
4)启动数据库
systemctl start mysqld
5)构建主从(1主2从)
主库master:db01
从库slave:db02, db03
在主库上创建主从复制用户
grant replication slave on *.* to repl@'10.0.0.%' identified by 'abc123..';
在db01和db02从库上执行
change master to master_host='10.0.0.90',master_port=3306,master_user='repl',master_password='abc123..' ,master_auto_position=1;start slave;
5.3.4 GTID 复制和普通position号复制的区别
1、change master时参数的区别
非GTID:需要跟binlog文件和position号
MASTERLOG_FILE=’mysql-bin.000001 ‘,
MASTER_LOG _POS=444,
GTID:只需要跟一个参数即可
此参数表示,mysql会自动去定位GTID号;
MASTER_AUTO_POSITION=1;
0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover
1)外功能参数(3个)
2)change master to的时候不再需要binlog文件名和position号,MASTER_AUTO_POSITION=1;
3)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的GTID号
4)mysqldump备份时,默认会将备份中包含的事务操作,以以下方式告诉从库,我的备份中已经有以上事务,你就不用运行了,直接从下一个GTID开始请求binlog就行
_SET @@GLOBAL.GTID_PURGED=’8c49d7ec-7e78-11e8-9638-000c29ca725d:1’;5.4 半同步复制
解决主从复制数据一致性问题,性能较差,实际生产很少使用
在常规的主从复制过程中,当Dump_T线程把binlog日志通过网络传输给从数据库的IO_T线程后,此时数据保存到了TCP/IP内核缓存当中,当此时发生断电或者物理性等故障,可能会导致binlog日志并未写入到磁盘,mysql为了解决此问题,引入了半同步机制。
半同步为了解决此问题,主数据库生成了一个ACK_Revicer的线程,只有当确认从库relaylog写入到磁盘后,IO_T线程会返回一个ACK(此ACK是来自MySQL层面的ACK,并非TCP的ACK)给主库的ACK_Reciver进程,主库Dump_T收到此ACK后,主库的事务才能被提交commit,但是如果主库一直没有收到ACK,默认超过10s钟会切换为异步复制,即主库不等待了,继续提交事务,所以在半同步机制下,仍然存在丢失binlog日志的风险,且长时间的等待导致性能较差,实际生产环境中很少使用。6 MHA高可用
6.1 搭建MHA
延续上面GTID一主二从的环境继续执行如下步骤
1)配置关键程序软链接,三个节点都执行ln -s /app/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlogln -s /app/mysql/bin/mysql /usr/bin/mysql
2)配置三个节点间的互信
db01上执行如下操作
rm -rf /root/.sshssh-keygencd /root/.sshmv id_rsa.pub authorized_keysscp -r /root/.ssh 10.0.0.91:/root/scp -r /root/.ssh 10.0.0.92:/root/
验证3个节点是否是免用户和免密登录
ssh 10.0.0.90 datessh 10.0.0.91 datessh 10.0.0.92 date
3)安装软件包,三个节点都执行
yum install -y perl-DBD-MySQLrpm -ivh mha4mysql-node-0.57-0.el7.noarch.rpm
4)在db01主库中创建mha需要的用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'abc123..';
5)Manager软件安装(db03上执行)
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiResrpm -ivh mha4mysql-manager-0.57-0.el7.noarch.rpm
6)配置文件准备(db03上执行)
创建配置文件目录、和日志文件目录mkdir -p /etc/mha/mkdir -p /data/mysql/mhamkdir -p /var/log/mha/app1
编辑MHA配置文件
cat >/etc/mha/app1.cnf <<EOF[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binloguser=mhapassword=abc123..ping_interval=2repl_password=abc123..repl_user=replssh_user=root[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=3306EOF
7)状态检查(db03)
互信检查
masterha_check_ssh —conf=/etc/mha/app1.cnf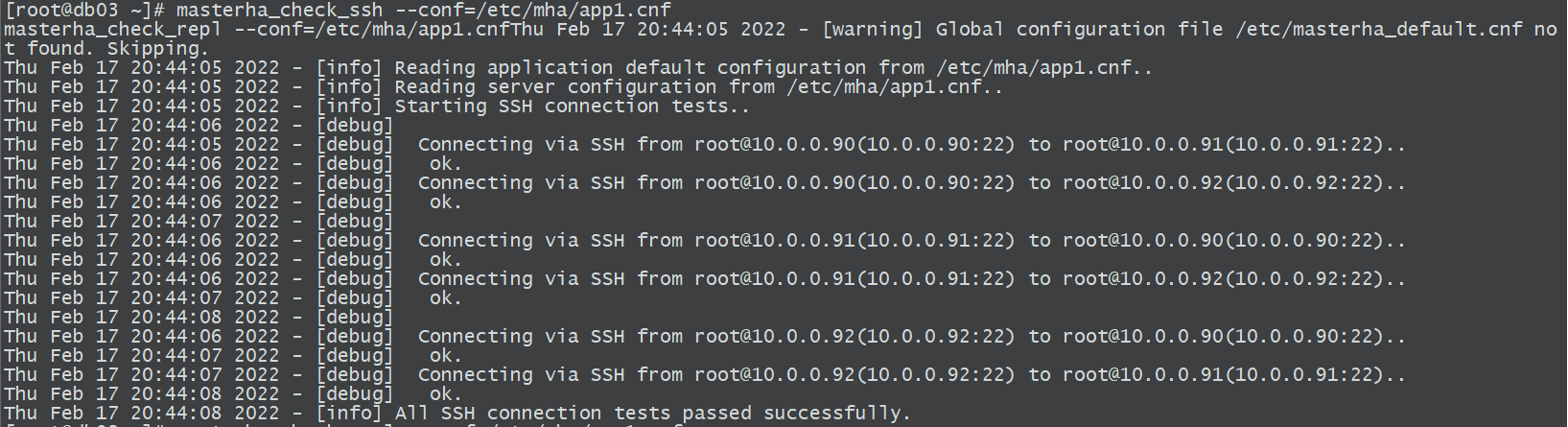
masterha_check_repl —conf=/etc/mha/app1.cnf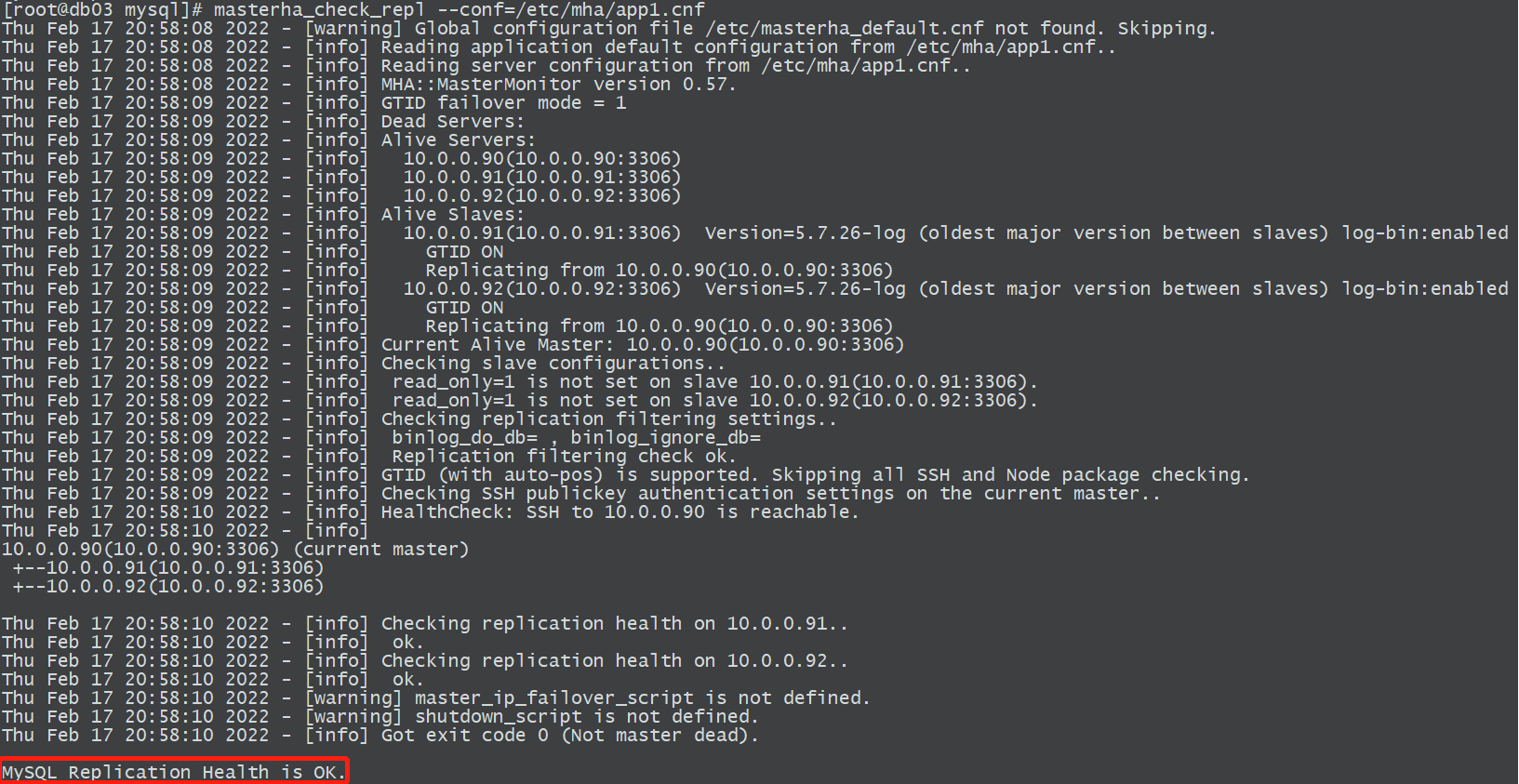
8)开启MHA(db03)nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
9)检查MHA状态
masterha_check_status --conf=/etc/mha/app1.cnf
6.2 MHA架构软件结构说明
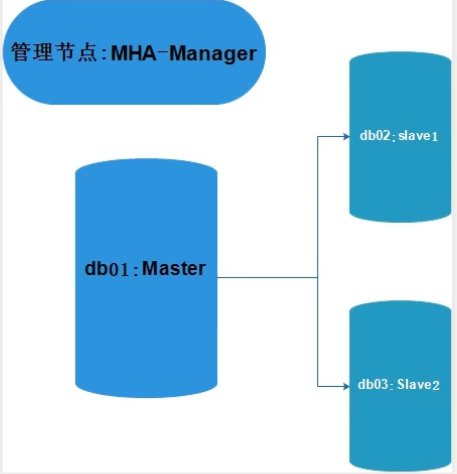
6.2.1 节点规划(不支持单节点多实例)
数据库节点,必须至少是1主2从独立实例,MHA管理节点,最好是独立一台机器
manager端:db03
-
6.2.2 MHA软件的构成(perl语言)
Manager工具包主要包括以下几个工具:mha4mysql-manager-0.57-0.el6.noarch.rpm
masterha_manger —启动MHA
- masterha_check_ssh —检查MHA的SSH配置状况
- masterha_check_repl —检查MysQL复制状况
- masterha_master_monitor —检测master是否宕机
- masterha_check_status —检测当前MHA运行状态
- masterha_master_switch —控制故障转移(自动或者手动)
- masterha_conf_host —添加或删除配置的server信息

Node工具包主要包括以下几个工具:mha4mysql-node-0.57-0.el7.noarch.rpm
这些工具通常由MHA Manager的脚本触发,无需人为操作
- save_binary_logs —保存和复制master的二进制日志
- apply_diff_relay_logs —识别差异的中继日志事件并将其差异的事件应用于其他的
purge_relay_logs —清除中继日志(不会阻塞SQL线程)
6.3 MHA配置过程细节说明
1、做软链接
为什么非得做软链接,因为MHA在调用这两个命令时,就是走的绝对路径/usr/bin/下面查找的,此时系统定义的环境变量无效
2、配置互信
在发生故障之后,三个节点之间可能会涉及到binlog日志的拷贝,需要通过网络传输
3、在db03上安装MHA Manager,为什么选择db03,通常建议用一台单独的节点
如果装在db01上面,由于db01作为主库业务压力较大,如果发生故障,MHA manager软件也就没法儿工作了,所以也就没法进行主从的切换了,为什么不安装在db02上面,因为MHA有一个机制,当发生主从切换时,其算法默认会按照server1—>server2…这样的顺序选择主库,所以如果没有单独的节点安装MHA manager,通常建议安装MHA manager到从库的最后一个节点上。
4、配置文件说明
MHA可以管理多个MySQL主从架构,每个不同的主从架构就通过配置文件做区分cat >/etc/mha/app1.cnf <<EOF[server default]# MHA运行的日志,后续如果MHA发生故障都得从此日志分析manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binloguser=mhapassword=abc123..ping_interval=2repl_password=abc123..repl_user=replssh_user=root[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=3306EOF
6.4 MHA Failover的实现
6.4.1 什么是failover?
故障转移,主库宕机一直到业务恢复正常的过程,解决物理故障的切换。
6.4.2 实现Failover的大致思路?
1) 快速监控到主库宕机
2) 选择新主
3) 数据补偿
4) 解除从库身份
5) 剩余从库和新主库构建主从关系
6) 应用透明
7) 故障节点自愈(待开发.. .)
8) 故障提醒(发送邮件)6.4.3 MHA的Failover如何实现
从启动—->故障—->转移—->业务恢复整个过程进行分析:
1)MHA通过masterha_manger 脚本启动MHA的功能
2)在manager启动之前,会自动检查ssh互信(masterha_check_ssh) 和主从状态(masterha_check_repl)
3)MHA-manager通过masterha_master_monitor脚本(每隔ping_interval秒)进行监控
4)当masterha_master_monitor探测到主库3次无心跳之后,就认为主库宕机了
5)进行选主过程算法一:
读取配置文件中是否有强制选主的参数?
candidate_master=1
check_repl_delay=0
- 算法二:
没有强制选主参数时,自动判断所有从库的日志量,将最接近主库数据的从库作为新主
- 算法三:
按照配置文件先后顺序的进行选新主.
- 扩展一下:
candidate_master=1应用场景?
1)MHA+KeepAlived VIP(早期MHA架构,KA提供VIP转移功能),因为VIP只能两个节点间做转移,可如果MHA根据算法选到第三个节点作为主,但是此时的VIP没有在该节点上,所以此时得强制选主,使用candidate_master=1参数
2)多地多中心,如两地三中心的场景,尽量切换到同一地方的另外一个数据中心
6)数据补偿
判断主库SSH的连通性
情况1:能连
调用save_binary_logs脚本,立即保存缺失部分的binlog到各个从节点,恢复
情况2:SSH无法连接
调用apply_diff_relay_logs脚本,计算从库的relaylog的差异,恢复到2号从库
6.1)提供额外的数据补偿的功能
7)解除从库身份
8)剩余从库和新主库构建主从关系
9)应用透明
10)故障节点自愈
11)故障提醒(发送邮件)
6.5 MHA应用透明配置(VIP虚拟IP)
1、VIP转移脚本
#!/usr/bin/env perluse strict;use warnings FATAL => 'all';use Getopt::Long;my ($command, $ssh_user, $orig_master_host, $orig_master_ip,$orig_master_port, $new_master_host, $new_master_ip, $new_master_port);my $vip = '172.16.1.55/24';my $key = '1';my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip";my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down";GetOptions('command=s' => \$command,'ssh_user=s' => \$ssh_user,'orig_master_host=s' => \$orig_master_host,'orig_master_ip=s' => \$orig_master_ip,'orig_master_port=i' => \$orig_master_port,'new_master_host=s' => \$new_master_host,'new_master_ip=s' => \$new_master_ip,'new_master_port=i' => \$new_master_port,);exit &main();sub main {print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if ( $command eq "stop" || $command eq "stopssh" ) {my $exit_code = 1;eval {print "Disabling the VIP on old master: $orig_master_host \n";&stop_vip();$exit_code = 0;};if ($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "start" ) {my $exit_code = 10;eval {print "Enabling the VIP - $vip on the new master - $new_master_host \n";&start_vip();$exit_code = 0;};if ($@) {warn $@;exit $exit_code;}exit $exit_code;}elsif ( $command eq "status" ) {print "Checking the Status of the script.. OK \n";exit 0;}else {&usage();exit 1;}}sub start_vip() {`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}sub stop_vip() {return 0 unless ($ssh_user);`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}sub usage {"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";}
2、脚本需要修改的地方
vim /root/master_ip_failover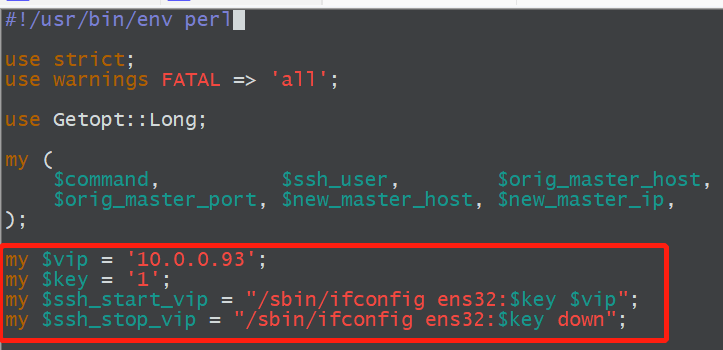
3、脚本中可能存在中文字符,可以使用dos2unix将中文字符转换为英文字符
yum install -y dos2unixdos2unix /usr/local/bin/master_ip_failover
4、将文件拷贝到指定路径并添加执行权限
cp /root/master_ip_failover /usr/local/bin/master_ip_failoverchmod +x /usr/local/bin/master_ip_failover
5、在MHA主配置文件中添加VIP配置
vim /etc/mha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binlogmaster_ip_failover_script=/usr/local/bin/master_ip_failoveruser=mhapassword=abc123..ping_interval=2repl_password=abc123..repl_user=replssh_user=root[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=3306
6、在db01手工添加VIP
ifconfig ens32:1 10.0.0.93/24
7、在db03上重启MHA
masterha_stop --conf=/etc/mha/app1.cnfnohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
6.6 故障模拟以及故障处理
MHA是一次性的高可用技术,一旦切换成功,MHA manager也就down了
6.6.1 MHA邮件提醒配置
1、做如下编辑并测试(将相应的字段改成自己邮箱信息)
email_2019-最新.zip
[root@db03 ~]# cp -r email/* /usr/local/bin/
[root@db03 ~]# cat /usr/local/bin/testpl
#!/bin/bash/usr/local/bin/sendEmail -o tls=no -f shichuan_xiang@163.com -t 505597482@qq.com -s smtp.163.com:25 -xu shichuan_xiang -xp AZDOWHMNVITZTVKC -u "MHA Waring" -m "YOUR MHA MAY BE FAILOVER" &>/tmp/sendmail.log
[root@db03 ~]# vim /etc/mha/app1.cnf
report_script=/usr/local/bin/send
[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binlogmaster_ip_failover_script=/usr/local/bin/master_ip_failoverreport_script=/usr/local/bin/senduser=mhapassword=abc123..ping_interval=2repl_password=abc123..repl_user=replssh_user=root[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=330
2)重启MHA
masterha_stop --conf=/etc/mha/app1.cnfnohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
6.6.2 额外的数据补偿
为了避免主库down掉之后,从库没有完整的binlog日志,MHA建议用一个专门的节点来保存binlog日志。
1、找一台额外的机器,必须要有5.6以上的版本,支持gtid并开启,我们直接用的第二个slave(db03)
2、创建必要的目录
mkdir -p /data/mysql/mha/binlog-buchang
chown -R mysql.mysql /data/
*3、编辑MHA配置文件,添加如下配置
vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=10.0.0.92
master_binlog_dir=/data/mysql/mha/binlog-buchang
[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binlogmaster_ip_failover_script=/usr/local/bin/master_ip_failoverreport_script=/usr/local/bin/senduser=mhapassword=abc123..ping_interval=2repl_password=abc123..repl_user=replssh_user=root[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=3306[binlog1]no_master=1hostname=10.0.0.92master_binlog_dir=/data/mysql/mha/binlog-buchang
3、拉取主库的binlog日志到binlog-server进行保存
cd /data/mysql/mha/binlog-buchang —->必须进入到自己创建好的目录
注意:拉取日志的起点,需要按照目前主库正在使用的binlog为起点,生产中不要从000001号文件开始
mysqlbinlog -R --host=10.0.0.90 --user=mha --password=abc123.. --raw --stop-never mysql-bin.000001 &
5、重启MHA
masterha_stop --conf=/etc/mha/app1.cnfnohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
6.6.3 故障恢复演练步骤
1、模拟db01数据库故障
systemctl stop mysqld
此时主库已经切换至db02了,且此时只有1主1从,包括VIP也迁移至db02了
2、恢复故障
1)启动故障节点,启动db01
systemctl start mysqld
2)恢复1主2从
将db01 CHANGE MASTER TO加入到主从架构,命令可以在db03上面查看
3)将db01加入主从架构
CHANGE MASTER TO MASTER_HOST='10.0.0.91', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='abc123..';start slave;
4)恢复配置文件
主从切换之后,原主库的配置在配置文件中会被清楚,恢复之后,需要手动将db01的配置加入
[binlog1]hostname=10.0.0.92master_binlog_dir=/data/mysql/mha/binlog-buchangno_master=1[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysql/mha/binlogmaster_ip_failover_script=/usr/local/bin/master_ip_failoverpassword=abc123..ping_interval=2repl_password=abc123..repl_user=replreport_script=/usr/local/bin/sendssh_user=rootuser=mha[server1]hostname=10.0.0.90port=3306[server2]hostname=10.0.0.91port=3306[server3]hostname=10.0.0.92port=3306
5)恢复binlog-server
#必须进入到自己创建好的目录cd /data/mysql/mha/binlog-buchangrm -rf ./*mysqlbinlog -R --host=10.0.0.91 --user=mha --password=abc123.. --raw --stop-never mysql-bin.000001 &
6)启动MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
6.6.4 恢复MHA故障思路
无论MHA什么故障都可以按照如下思路进行故障恢复
1、检查各个节点是否启动2、找到谁是主库3、恢复1主2从grep "CHANGE MASTER TO" /var/log/mha/app1/managerstart slave;4、检查配置文件补全节点信息5、检查VIP和binlogserver检查vip是否在主库上,如果不在,请手动更新在主库上6、启动binlogservermysqlbinlog -R --host=10.0.0.91 --user=mha --password=abc123.. --raw --stop-never mysql-bin.000001 &7、启动managernohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover </dev/null >/var/log/mha/app1/manager.log 2>&1 &
7 Atlas做读写分离
Atlas是一个数据库的中间件开源产品,是360基于原mysql-proxy基础上开发的,增加了一些新的功能特性,在读写分离架构上做的还不错,但是在未来的分布式架构上还有一定的欠缺,所以如果仅仅是需要做读写分离,Atlas是一个不错的选择,适用于中小型公司,但是从2016年开始该项目就停止更新了。
其它读写分离架构的产品:
MySQL-Router —-> 问ySQL官方
ProxySQL —->Percona
Maxscale —-> MariaDB
其部署架构就是在MHA的架构基础之上,安装一个Atlas即可,外部连接数据库直接连接到Atlas,然后由Atlas进行读写分离的判断和路由,另外Atlas也可以代理多套读写分离架构,也是通过不同的配置文件做区分
7.1 安装Atlas
1、正常的情况是一个单独的节点,这里仍然安装db03上
rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
2、编辑配置文件
vim /usr/local/mysql-proxy/conf/test.cnf
[mysql-proxy]admin-username = mhaadmin-password = abc123..#这里的93是MHA架构的VIPproxy-backend-addresses = 10.0.0.93:3306proxy-read-only-backend-addresses = 10.0.0.91:3306,10.0.0.92:3306pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098=daemon = truekeepalive = trueevent-threads = 8log-level = messagelog-path = /usr/local/mysql-proxy/logsql-log=ONproxy-address = 0.0.0.0:33060admin-address = 0.0.0.0:2345charset=utf8
3、启动Atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test start
4、查看运行状态
5、连接测试,通过33060端口进行连接
mysql -umha -pabc123.. -h 10.0.0.93 -P 33060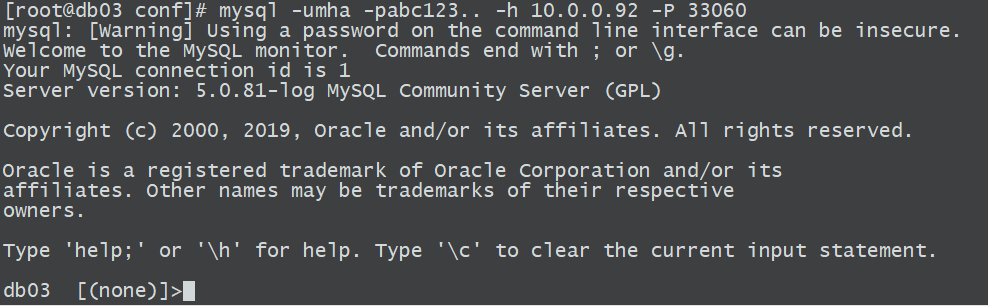
6、读写分离测试
测试读
根据配置,读的操作会落到两个从库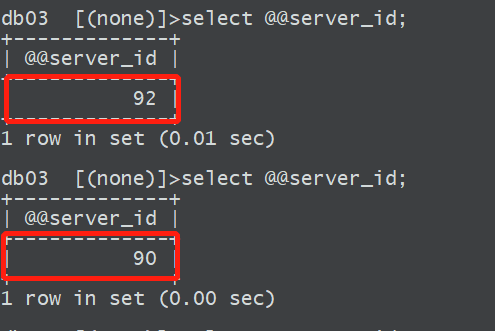
测试写
写操作会落到主库,这里通过一个事务来模拟的写操作,让atlas判断是一个写操作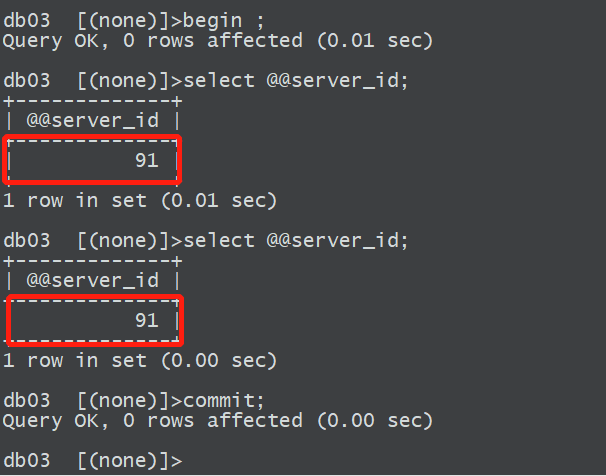
7.2 生产用户添加
开发人员申请一个应用用户app(select update insert) 密码123456,要通过10网段登录
1、在主库中,创建用户
grant all on . to app@’10.0.0.%’ identified by ‘abc123..’;
2、在atlas中添加生产用户
/usr/local/mysql-proxy/bin/encrypt abc123.. —->制作加密密码
vim /usr/local/mysql-proxy/conf/test.cnf
pwds = repl:v7mPeajaWeUa8s/oWZlMvQ==,mha:O2jBXONX098=,app:v7mPeajaWeUa8s/oWZlMvQ==
3、重启atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test restart
4、测试连接
mysql -uapp -pabc123.. -h 10.0.0.92 -P33060
7.3 Atlas基本管理连接管理接口
1、连接atlas管理端口进行管理
mysql -umha -pabc123.. -h127.0.0.1 -P2345
2、查看帮助
select from help;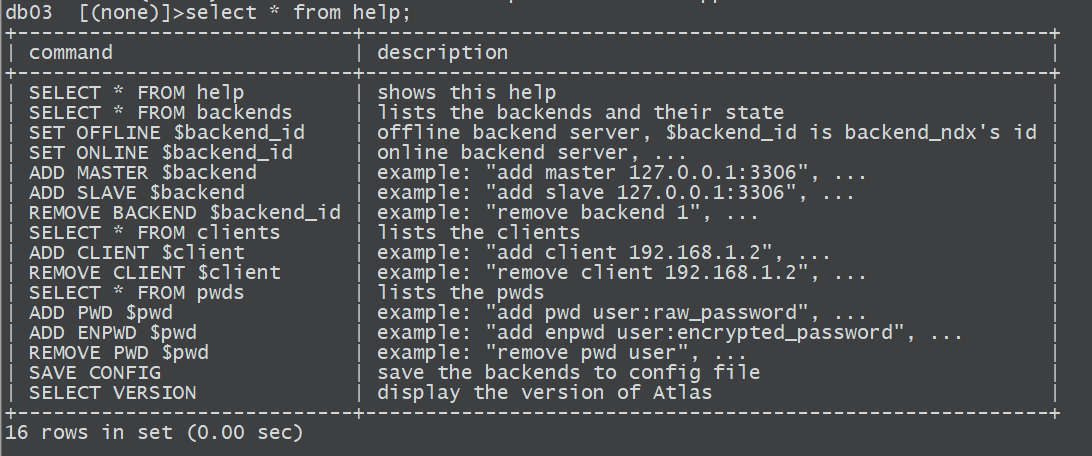
3、查看Atlas后端节点情况
SELECT FROM backends;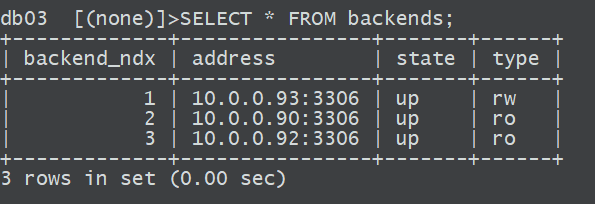
4、常用命令
- set offline 2; #下线节点,临时下线
- set online 2; #上线节点
- REMOVE BACKEND 3; #删除节点
- ADD SLAVE 10.0.0.90:3306; #添加从节点
- select * from pwds #查看用户
- ADD PWD xiang:abc123..; #添加用户
- save config; #保存配置到配置文件

若有收获,就点个赞吧
0 人点赞
