- Introduction To Devops
- DevOps With Containers
- Getting Started with Kubernetes
- 管理有状态的工作负载(Managing Stateful Workloads)
Introduction To Devops
- 软件交付方式是如何变迁的?
- 瀑布流式开发流程和静态交付
- 敏捷开发和数字交付
- 基于云的软件交付
- 持续集成
- 持续交付
- 配置管理
- 代码即架构
- 编排(Orchestration)
- 持续交付
- 什么是微服务架构,微服务为什么会成为当前的主流架构?
- 什么是DevOps,它是如何让软件系统变得更灵活和弹性?
DevOps With Containers
Understanding Containers
- Key Concepts related to containers
- 资源隔离(isolation)
| 虚拟化技术 | 原理 |
|---|---|
| VMs | 过Hypervisor实现基于硬件层的完全虚拟化 |
| Docker/Linux | 基于Linux的基础实现,在其上实现虚拟化支持 |
- Linux Containers
- Key Concept
- namespaces:实现了对系统资源的的逻辑隔离,比如挂载点、进程号、网络等资源。尽管不同namespace下的进程之间无法感知,但对于像内存等公共资源还是共用的,如果不加控制,不同namespace的进程之间还是会互相干扰。
- control groups(cgroups):可以实现进程对公共资源的使用限制。
可控制的资源可通过ls /sys/fs/cgroup查看。
- 容器的优势:
- 容器的配置信息可通过VCS管理,容器的依赖可被打到一个镜像中,而这个镜像在部署中是不变的,因此开发人员可从部署的环境依赖困境中抽身;
- 因为只需要把应用本身及相关依赖打包到镜像中,因此镜像相比VM轻量很多;
- 因为镜像中运行的进程和在宿主机中运行的进程相比并无额外的开销,因此没有性能损耗。
- 因此通过容器,可以对应用及其基础设备实现很好的责任分离。
- 安装docker
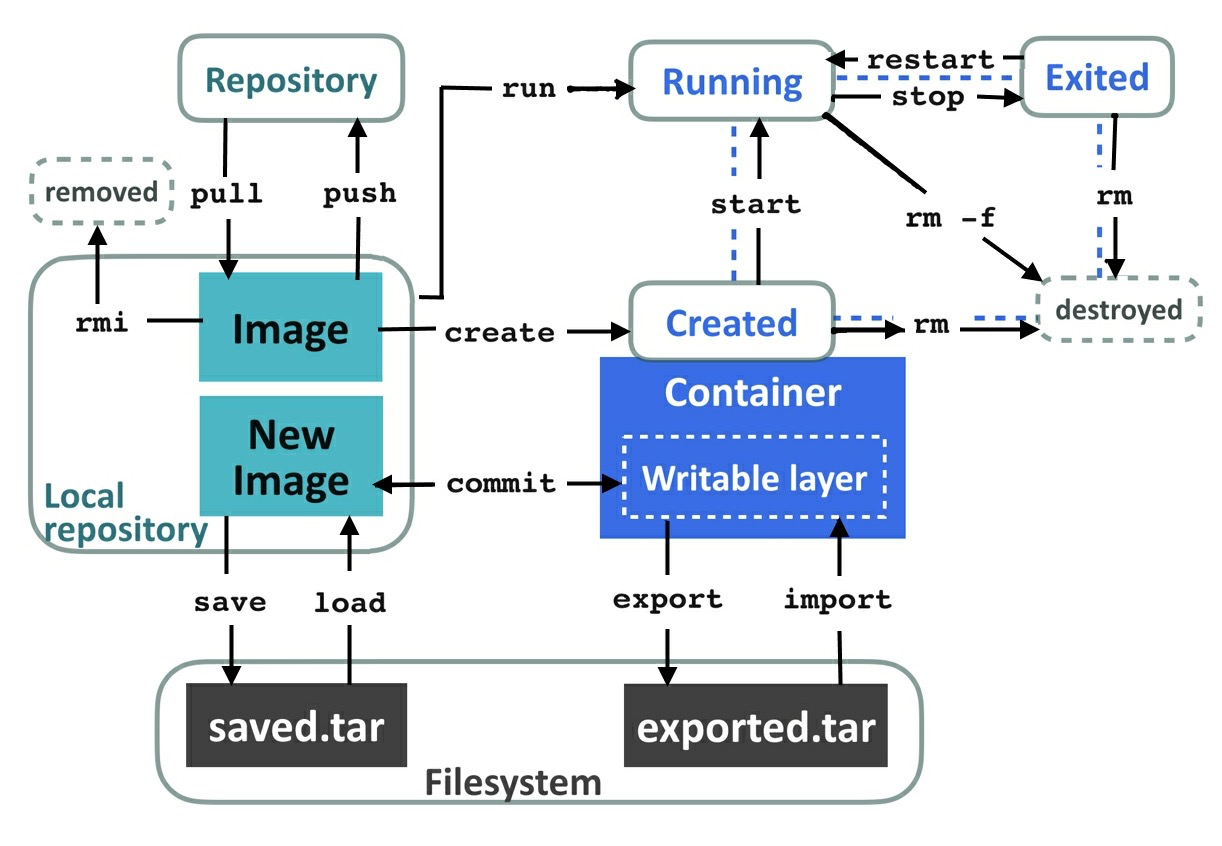
Install Docker Using the Repository - 容器的生命周期(Life Cycle)
当执行类似docker run image_name ls命令时,docker在内部做了以下几件事:- 在本地查找image_name镜像,如果找不到则从Docker的公共仓库查找并加载存储到本地
- 解析镜像内容并创建一个相应的容器
- 执行命令中指定的镜像的entry point,也就是docker run命令中docker_name后面的参数。如果不指定,在Linux版的Docker中默认执行
/bin/sh -c - 当entry point执行结束后,容器将退出
- 镜像(IMAGE):是代码、类库、配置以及任何我们想放进去的数据包(通过
docker inspect IMAGE查看镜像说明) - 容器(Container):则是镜像的实例,是运行时处于执行状态(通过
docker inspect CONTAINER查看容器说明)
通过docker run加载的镜像都属于前台应用,可通过-d选项声明为后台运行模式。
如果到运行的容器上执行命令,需要使用-it选项(—interactive and —-tty)。
如果需要和一个后台运行模式的容器交互,可以使用exec和attach命令。
可以通过docker ps -a查看已停止的容器,通过docker rm CONTAINER_ID清理容器。通过docker system prune可以用来清理已停止的容器并释放相关资源。
- Layers, Images, Containers, Volumes
- Layer: 文件系统上的文档和目录的集合,Layer可以被多个Image共享
- Image: Layer的集合
docker history imagename用来查看image使用的层。 - Container: 运行的Image,当Container被创建时,会在其基础镜像之上再创建出一层很轻量,并可被写入的writable layer。一旦有基础镜像中的数据需要被修改,实际是先把被修改的数据复制到新创建的writable layer中,并修改它。
docker diff [CONTAINER_ID]可以查看指定镜像中是否有数据修改。当Container停止时,writable layer也将随之销毁。如果需要保持数据,则需要基于这个新的容器层来创建一个新的镜像(使用docker commit [image_name]),或者把 data volume挂截到容器中。 - Volume: 提供了一种机制,让容器可以绕过Docker的文件系统来读取或写入数据,被操作的数据可以在宿主机上,也可以是其他的分布式存储系统,Docker对此不做限制。可以在
docker run或docker create命令中通过-v选项指定在容器中的挂载位置。
- 分发镜像(Distributing Images)
- Docker仓库
- docker images:查看本地镜像
- docker rmi [IMAGE]:删除本地镜像
- Image命名规则:[registry/]name[:tag]
- registry:仓库地址,如果未指定则默认为Docker Hub
- name:中可有多个”/”
- tag:版本号或标签,如果未指定则使用最新版本镜像
- docker tag local_image_name repository/image_name:tag
基于本地的镜像,在指定仓库中创建一个新镜像 - docker push repository/imagename:tag
- docker commit [CONTAINER]:基于镜像的改动生成一个新的镜像
- docker save —output [filename] IMAGE1 IMAGE2 …,保存镜像到tar压缩包
- docker load -i [filename]:Loads a tar压缩包中的镜像到本地仓库
- docker export —output [filename] [CONTAINER]:把镜像的文件系统导致出tar包
- docker import —output [filename] IMAGE1 IMAGE2:导入TAR压缩包
- Key Concept
Connection containers
docker提供了三种方式用于容器与宿主机之间的连接:bridge, host和none。通过docker nnetwork ls可以查看相关信息。- bridge:默认情况下,每个容器在创建时便连接到了bridge网络,在这种模式下,每个容器关联了一个虚拟接口及私有IP,容器上的数据传输被桥接到宿主机的
docker0接口上。同一个网桥上的容器之间可以通过私有IP进行通信。可以在启动容器时通过--expose把端口暴露出来。另外还可以通过-p(--publish)[host]:[container]指定宿主机与容器的端口绑定关系。
另外,还可以通过自定义的网桥网络把一组容器做网络分组。通过docker network create [NW-NAME]创建一个网络,并通过--network [NW-NAME]为容器指定关联的网络。还可以通过--net-work-alias为容器指定网络名称。 - host:顾名思义,每个容器都共享宿主机的网络设置,因此每个容器也丢失了网络资源的隔离。
none:指定网络为none的容器处于逻辑隔离状态,因此没有网络接口,所以容器变得独立。
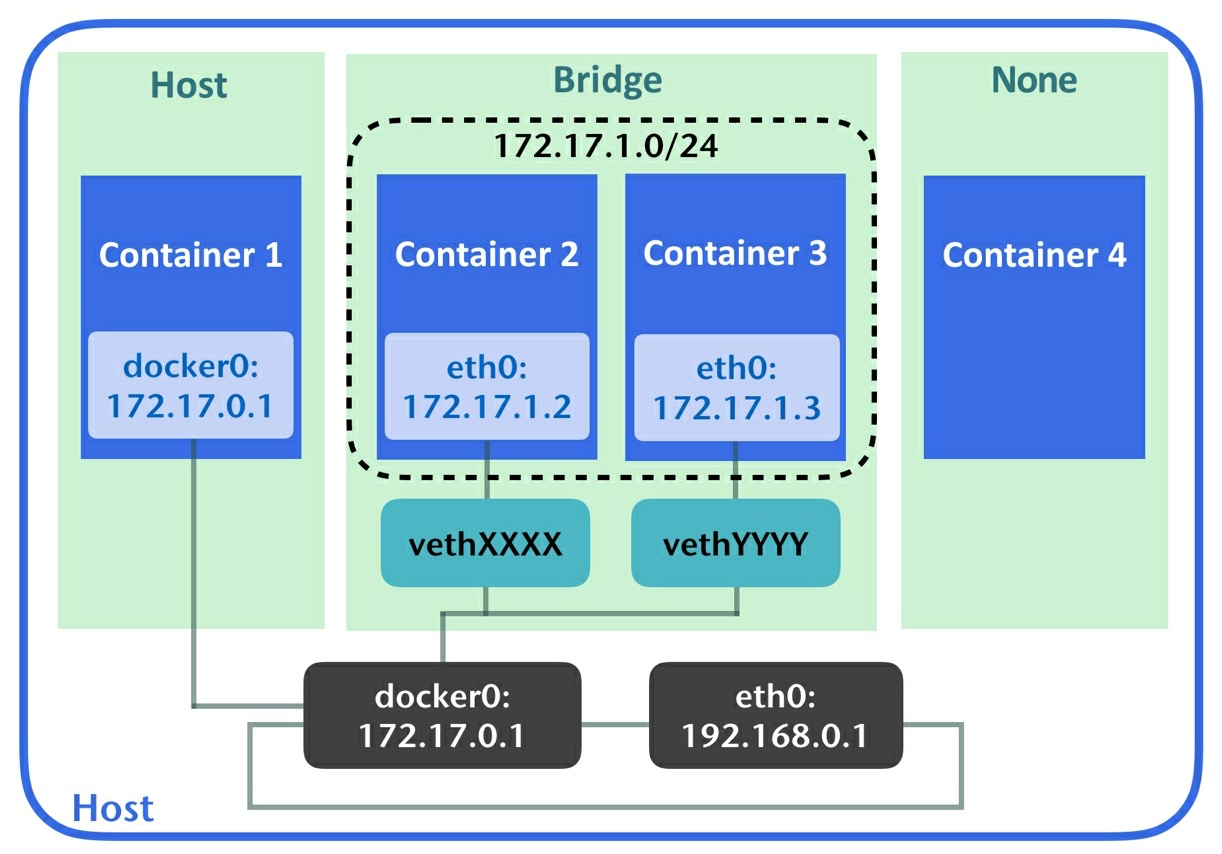
- bridge:默认情况下,每个容器在创建时便连接到了bridge网络,在这种模式下,每个容器关联了一个虚拟接口及私有IP,容器上的数据传输被桥接到宿主机的
Working with a Dockerfile
dockerfile是以代码的形式来表示镜像的构建过程,以减少镜像构建过程的难度。通过docker build命令,就可以根据dockerfile构建一个全新的镜像。
- Dockerfile文件语法
- FROM
[:TAG][@DIGEST]:指定当前定义镜像所依赖的基础镜像。
FROM语句在dockerfile中不可缺失。 - RUN:在当前镜像层运行命令,并产出新层。
- Shell格式:RUN
,将以 /bin/sh -c <commands>的形式对当前行进行执行,并能计算命令中的shell变量 - exec格式:RUN [“executable”, “params”, “more params”],直接执行当前行的命令
- Shell格式:RUN
- CMD
- CMD [“executable”, “params”, “more params”]:exec格式
- CMD [“param1”, “param2”]:exec格式
- CMD command param1 param2 …:shell格式
- FROM
cmd作为构建镜像的默认命令,在镜像构建过程中并不会被执行。如果在执行docker fun时指定了参数,则dockerfile里的CMD命令将被忽略。在dockerfile中可以定义多个CMD命令,但只有最后一个才有意义,其他的不会生效。CMD命令同时也可以与ENTRYPOINT命令配合使用,见下文描述。
- ENTRYPOINT
- ENTRYPOINT [“executable”, “params”, “more params”]:exec格式
- ENTRYPOINT command param1 param2…:shell格式
作为entry point, 容器启动后将会运行 ENTRYPOINT 中配置的命令。但当 ENTRYPOINT 和 CMD 及docker run参数同时出现时,将会有不同的规则:
- 如果ENTRYPOINT以shell格式出现,则CMD及docker run的参数将不生效- 如果ENTRYPOINT以exec格式出现,并且指定了docker run的参数,则CMD配置将失效,则命令将以 `entry_cmd entry_params run_arguments` 的形式运行- 如果ENTRYPOINT以exec格式出现,并且配置了CMD命令,则命令将以的 `entry_cmd entry_params CMD_exec CMD params` 或 `entry_cmd entry_params /bin/sh -c CMD_cmd CMD_params` 形式运行
- ENV
- ENV key value:单值定义
- ENV key1=value1 key2=value2…,多值定义,value支持双引号
ENV指令用于定义适用于构建文件的环境变量。
- ARG key[=
]:定义并可接收和传递docker build的 --build-arg参数作为构建命令的环境变量。如果在ENV和ARG中定义了同名的变量,则ARG的定义将不生效。另外dockerfile中也预定义了一些参数:HTTP_PROXY, http_proxy, HTTPS_PROXY, https_proxy, FTP_PROXY, ftp_proxy, NO_PROXY, no_proxy,在dockerfile中可以无须通过ARG声明,直接引用。 - LABEL key1=value1 key2=value2…:
- EXPOSE
[ …]:与docker run/create命令中的—expose选项的效果一致 - USER:指定接下来的执行的CMD及ENTRYPOINT等命令的用户。如果指定用户在镜像中不存在,需要先提交创建用户。
- WORKDIR
:指定接下来的ENV命令生效的目录,类似于工作在Dockerfile中的cd命令。 - COPY [—chown=
: ] … :把上下文中的文件或目录复制到目标文件或目录,被复制的文件不能是被 .dockerignore的。 - ADD [—chown=
: ] … :不同于COPY,ADD命令可以从URL中下载文件到目标位置或者把源位置的压缩文件解压到目标目录 - VOLUME mnt_point_1 mnt_point2…:用于在指定的挂载点创建volume。
- ONBUILD [other directives]:允许指定的指令推迟到后续的继承镜像构建时执行
Organizing a Dockerfile
Dockerfile作为镜像构建过程的脚本,在编写Dockerfile时需要考虑构建过程的效率、容器的安全性和镜像的稳定性;作为构建文档,需要保持文档的清晰易读易维护。
组织Dockerfile的常规建议:
- 保持容器功能简单,一个容器只做一件事
- 不要把非必需的文件打包到镜像,以提高镜像构建、分发效率
- 在COPY或ADD把目录添加到镜像时,使用.dockerignore过滤不必要文件
- 向镜像中添加文件或目录时,优先使用COPY而非ADD指令,除非是需要解压或下载类的文件
- 因为在构建镜像过程中, Docker Engine会复用已构建出的层以节省时间。为了从构建缓存层中受益,优先运行执行频率低的指令。
- 因为任何的ADD,RUN,COPY等指令都会创建layer,即便在后面的指令中删除了前置layer中创建的文件,但这些文件依然会占用镜像layer,所以可以通过压缩RUN指令,把多个要运行的命令打包成一个RUN指令以节约layer。
- 虽然ADD指令可以从网络下载文件,但为了节约layer创建,可以通过RUN指令搭配wget/crul,并配合RUN指令打包来提高性能。
- 编写易维护、功能稳定的Dockerfile建议:
- 使用WORKDIR指令替换RUN cd,并使用绝对路径
- 显示暴露端口
- 指定FROM镜像的tag
- Separate and sort packages line by line
- 使用exec格式的指令来加载应用:因为shell格式未必能恰当的停止并清理容器中的应用。因为shell格式的指令实际上是会在容器中执行/bin/sh -c,运行的是sh命令,而非应用本身。在Docker 守护进程向容器发送SIGTERM及SIGKILL信号时,shell格式启动的进程未必会把信号传递到子进程中,从而导致应用停止和清理失败。
- Multi-stage builds,多阶段构建镜像
上面介绍的Dockerfile编写建议主要是为了提高镜像的构建效率并保持最终生成的镜像小巧。除了上面的方式,还可以通过先编写构建脚本架,并把其复制到另外一个镜像中,并在后一个镜像构建过程中运行脚本架中的依赖并最终生成合理的镜像。在构建脚本架时无需考虑太多减少镜像layer的优化,但在最后生成镜像的脚本中还是需要考虑的。在一个Dockerfile文件中(从Docker CE 17.05)开始,可以通过指定多个FROM语句,把镜像的构建过程分段,并通过FROM ... AS ...为每段脚本取名字。在最后的FROM构建过程中,通过把前面阶段的镜像复制进来即可。在最终的构建结果中,仅包含了最后阶段的Layer,而被复制进来的构建阶段仅以二进程的形式存在(即前置被依赖的阶段仅以中间结果的形式被最终的构建使用,而其中的逻辑不会输出到最终镜像的layer中),因此最终的输出结果会较小。下面是一个示例:
FROM golang:1.11 AS builderARG GOOS=linuxARG GOARCH=amd64ARG CGO_ENABLED=0WORKDIR /go/src/appCOPY main.go .RUN go get .RUN go build -a -tags netgo -ldflags '-w -s -extldflags "-static"'FROM scratchCOPY --from=builder /go/src/app/app .ENTRYPOINT ["/app"]CMD ["--help"]
Multi-container orchestration
假如我们需要一个简单的票务系统kiosk,架构图如下: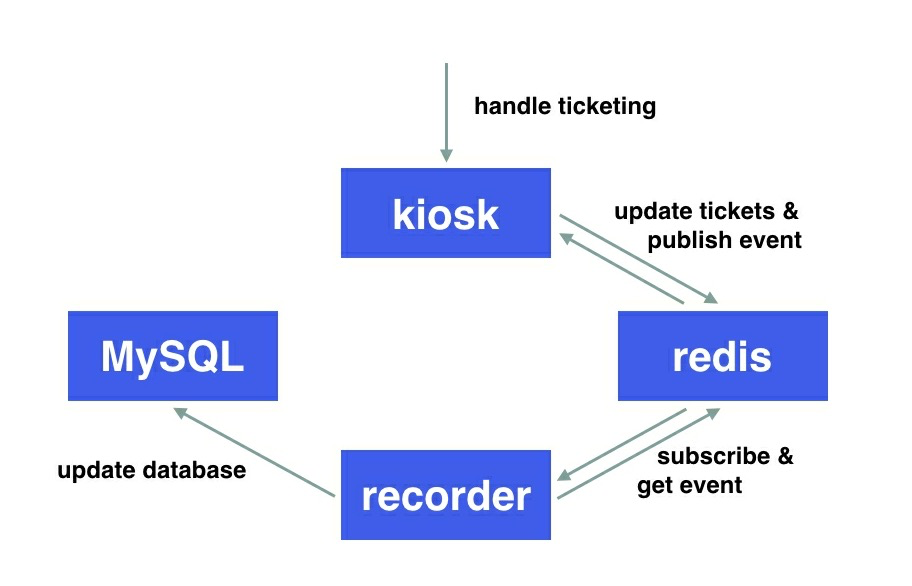
其中 kiosk 作为用户接口,接收售票请求,并把售票事件发布到redis channel中,应用recorder接收redis事件并把数据记录到mysql中。
这个简单的系统涉及到四个应用:kiosk、redis、recorder、mysql,分别定义在四个不同的镜像中。
启动这几个容器的命令如下:
docker create network kioskdocker run -d --network-alias lcredis --network=kiosk redisdocker run -d --network-alias lmysql -e MYSQL_ROOT_PASSWORD=$MYPS \--network=kiosk mysql:5.7docker run -d -p 5000:5000 \-e REDIS_HOST=lcredis --network=kiosk kiosk-exampledocker run -d -e REDIS_HOST=lcredis -e MYSQL_HOST=lmysql \-e MYSQL_ROOT_PASSWORD=$MYPS -e MYSQL_USER=root \--network=kiosk recorder-example
通过分别执行上面几条命令,将会分别在四个容器中运行redis/msql/kiosk-example/recorder-example。但因为四个容器分别启动,各容器中的应用启动速度又各不相同,可能会出现被依赖的服务未启动而自己已启动的情况,从而导致自身的请求处理失败,因此需要考虑容器的启动顺序问题。而Docker compose则是一种能简化处理多个容器运行的工具。
- Docker compose
docker compose 通过把容器启动命令及依赖关系定义到docker-compose.yml(或.yaml)文件中,并通过 docker up 来启动。
docker compose文件有几部分组成:
- version:指定版本号
- networks:定义网络
- serviers:定义应用信息
- volumes:定义 volume信息
前台四个容器通过docker compose的管理脚本如下:
version: '3'services:kiosk-example:image: kiosk-examplebuild: ./kioskports:- "5000:5000"environment:REDIS_HOST: lcredisdepends_on:- lcredisrecorder-example:image: recorder-examplebuild: ./recorderenvironment:REDIS_HOST: lcredisMYSQL_HOST: lmysqlMYSQL_USER: rootMYSQL_ROOT_PASSWORD: mysqlpassdepends_on:- lmysql-l credislredis:image: redisports:- "6379"lmysql:image: mysql:5.7environment:MYSQL_ROOT_PASSWORD: mysqlpassMYSQL_DATABASE: dbMYSQL_USER: userMYSQL_PASSWORD: passvolumes:- mysql-vol:/var/lib/mysqlports:- "3306"volumes:mysql-vol: {}
Docker compose作为简单的容器编排工具,只能执行同一个宿主机上的容器,因此也限制了它的使用场景。在很多时候我们需要支持分布式部署的编排工具,如 Kubernetes, Docker Swarm, Mesos (with Marathon or Aurora), Nomad 等将会是更好的选择。
Getting Started with Kubernetes
Understanding Kubernetes
kubernetes是一个用于管理跨主机的容器集群的平台,为基于容器的应用提供自动扩展(auto-scaling),rolling deployments, 以及计算和存储资源的管理。kubernetes的核心功能包含以下几个部分:
- Container deployment
- Persistent storage
- Container health monitoring
- Computer resource management
- Auto-scaling
High availability by cluster federation
Kubernetes components
kubernetes包含两大类角色,Masters和Nodes。
Masters:kubernetes的心脏,控制和调度集群内的所有对象
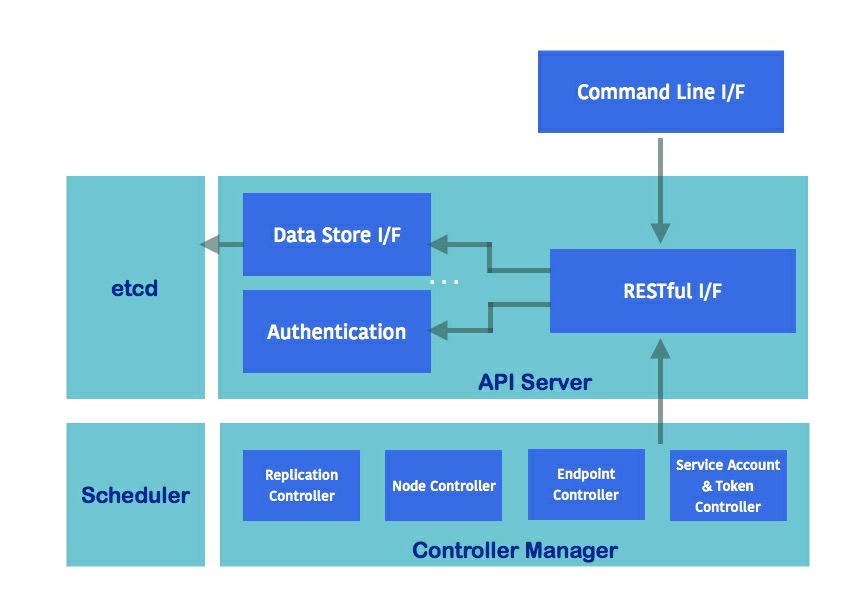
- API Server(kube-apiserver):在Master节点中,通过HTTP/HTTPS server为集群中的组件提供RESTful API。通过这些api可以创建、获取和更新资源。API server的数据信息存储在ectd中。
- Controller Manager(kube-controller-manager):通过监听API server的变化,使得集群处于RESTful api的期望状态。
- Scheduler(kube-scheduler):用于决策和选择适合的节点用于运行容器
- ectd:一款开源且可靠的分布式key-value存储数据库,Kubernetes把所有RESTful API对象都存储在etcd中。
作为Master的组件,以上几个部分可以分别运行在集群的多个宿主机上。
- Nodes:用于运行容器的节点,Node Component运行在每个节点上,并向Master上报节点的运行状态。
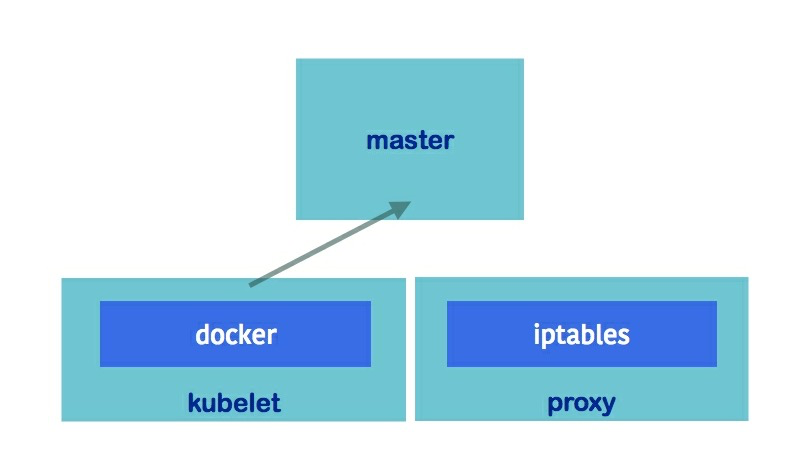
- kubelet:kubelet是nodes上比较重要的进程,用于周期性地上报pod health\node health\liveness probe等信息到kube-apiserver。
- proxy(kube-proxy):用于处理pod负载均衡器(或service)到pods的路由,也提供外部网络到services的路由功能。提供了三种proxy模式:
- userspace:在内核空间与用户空间切换时有罗大的开销
- iptables:最新版本的默认模式,通过改变iptables NAT (Network Address Translation)实现TCP和UDP数据包的跨容器路由。
- ipvs:IP Virtual Servers用于解决大集群(比如1000+ services)时的性能下降问题。它运行在一个主机上,并承担负载均衡的职责,把连接传递到真实的servers上。
- docker:kubernetes把docker作为默认的容器引擎,除此之外还支持如rkt和runc等容器
Getting started with kubernetes
使用 minikube在本地单机上安装kubernetes:
可以通过minikube工具在本地安装kubernetes平台。首先需要在本地安装一个虚拟机(VirtualBox或其他),然后通过brew cask install minikube安装即可。因为kubernetes运维需要依赖kubectl,所以安装minikube时,会自动把该工具安装进来。
安装好后,使用minikube start就可开始启动并部署一个kubenetes集群。
启动日志中会看到执行的一系统动作:
- download kubelet:第一次启动会下载kubelet
- kubeadm:第一次启动会下载kubeadm工具,通过kubeadm可以构建出一个kubernetes集群。
- pull images:拉取镜像
- launch kubernetes:装载kubernetes
- verify:验证kubernetes组件:apiserver, proxy, ectd, scheduler, controller, dns
看到输出`日志后,就表示kubernetes已启动功能。然后可以通过minikube status查看状态,或通过minikube dashboard` 打开浏览器查看集群信息。
在minikube start 过程中同时会创建kubeconfig,在kubeconfig中定义了集群的上下文及权限认证配置。通过 kubectl config view 可以查看当前的使用的kubeconfig;另外如果有多个config, 也可能通过 kubectl config 强制指定用的config。
kubernetes集群的命令行管理工具kubectl
语法:kubectl [command] [type] [name] [options]
- command:表示代想要的操作,可通过
kubectl help查看支持的操作列表 - type:表示资源类型
- name: 表示资源的名称,为资源提供清晰且有意义的名称很重要
- options: 表示命令执行的选项,可通过
kubectl options查看支持的选项列表kubernetes resources
kubernetes objects
kubernetes object作为集群的entry,存储在etcd,代表着集群期望的状态。通过objectspec来描述对象的要求,并可通过kubectl发送给API server,kubernetes会尽力满足需求并更新相应的对象状态。objectspec可通过YAML或JSON描述,在kubernetes的世界里,YAML更为通用。object spec语法格式如下:
apiVersion: Kubernetes API versionkind: object typemetadata:spec metadata, i.e. namespace, name, labels and annotationsspec:the spec of Kubernetes objects
Namespace
Kubernetes 通过 namespace 来保证多个虚拟集群的隔离。不同集群内的object互相不可见。在Kubernetes也有一些资源(如nodes和namespace本身)并不属于任何一个namespace。Kubernetes有三个namespace:
- default:如果我们在访问一个namespace下的资源时,如果未指定namespace,则使用当前context的namespace。如果我们从未添加过任何一个namespace,则将使用
default作为namespace。 - kube-system:Kubernetes系统创建的对象将使用
kube-system作为namespace,例如系统插件,这些pods及services等对象实现了对kubernetes的功能扩展,例如dashbaord。 - kube-public:作为1.6版本加入的新namespace,被
BootstrapSigner使用,把打标了的集群定位信息放入该namespace中,可被授权及未授权用户访问。
因为Kubernetes平台使用namespace实现对象隔离,所以当需要操作对象时需要通过#### namespace相关命令:kubectl get namespaces # 查看平台中已定义的namespace列表kubectl namespace create test # 创建名为test的namespacekubectl namespace delete test # 删除名为test的namespace
-n或--namespace指定namespace,否则将使用当前context关联的namespace;如果当前context未指定namespace,则使用defaultnamespace。如果需要查看所有集群中的对象,可通过指定--all-namespaces选项实现。Name
kubernetes平台中的每个object都有一个名字,且在同一个namespace中名称不可重复。Kubernetes使用object name作为API server中的资源URL的一部分,因此只能使用小写字母、短横线(-)和点号(.)定义,且长度不超过254位。此外kubernetes也还为每个对象定义了一个UID(Unique ID)用于跟踪所有出现过的资源。Label and selector
label是作用于kubernetes object上的一系列具有辨识度且含义明确的key/value对集合。通常用于标识微服务、环境、软件版本等,并可通过label selector实现对满足条件的object的过滤。
label定义spec如下:
labels:$key1: $value1$key2: $value2
label selector 配合label使用,可以实现对象的过滤。label selector支持两种模式的匹配:
- 相等匹配:支持等于和不等于运算符
===和!=。 - 包含匹配:实现包含和不包含运算,
innotin和exists(只支持key的exists判断)Annotation
用户自定义的key-value对,用于标识未识别的metadata,效果类似于常规的标签。[困惑]Pods
pod是kubernetes的最小部署单元。一般一个pod中放置一个容器,也有例外,像sidecar containers等多个容器可共存于同一pod中。同一pod内的容器共享context、nodes、网络和数据卷。pod也有生命周期,如果一个pod出现意外,其自身不会重启和恢复,相反pod的创建和管理受kubernetes controllers控制。
可以使用kubectl explain <resource>查看资源的详细描述,例如kubectl explain pods。根据资源描述,可以编写资源创建的yaml文件:
apiVersion: v1kind: Podmetadata:name: example-podspec:containers:- name: web-containerimage: nginx- name: centos-containerimage: centoscommand: ["/bin/sh", "-c", "while : ;do curl http://localhost:80/; sleep 10; done"]
`kubectl create -f create_pod.yaml —reocrd=true--record=truekubectl get kubectl get podkubectl logs kubectl describe <resourcetype> <resourcename>kubectl describe pod example-pod````bash
Name:
Namespace:
Priority:
PriorityClassName:
Node:
StartTime:
Labels:
Annotations:
Status:
IP:
Containers:
container-name:
Container ID:
Image:
Image ID:
Port:
Host Port
State:
Started:
Ready:
Restart Count:
Environment:
Mounts:
Conditions:
Type
Initialized
Ready
ContainersReady
PodScheduled
Volumes:
default-token-vsqdg:
Type:
SecretName:
Optional:
QoS Class:
Node-Selectors:
Tolerations:
Events:
<br />`service account``service account``token controller``kubectl get serviceaccounts``Tolerations``Events````bashEvents:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 7m22s default-scheduler Successfully assigned default/example-pod to minikubeNormal Pulling 7m21s kubelet, minikube Pulling image "nginx"Normal Pulled 7m2s kubelet, minikube Successfully pulled image "nginx"Normal Created 7m2s kubelet, minikube Created container web-containerNormal Started 7m2s kubelet, minikube Started container web-containerNormal Pulling 7m2s kubelet, minikube Pulling image "centos"Normal Pulled 6m29s kubelet, minikube Successfully pulled image "centos"Normal Created 6m28s kubelet, minikube Created container contos-containerNormal Started 6m28s kubelet, minikube Started container contos-container
ReplicaSet
因为pod的生命周期受kubernetes controller管理和控制,其自身没有故障恢复的能力,因此为了保持Kubernetes平台中始终有某干个运行的pod,Kubernetes平台引入了 ReplicaSet(RS) 。如果某个pod故障崩溃,ReplicaSet将会请求并创建一个新的pod。
根据 kubectl explain rs 编写创建rs的yaml文档示例如下:
apiVersion: apps/v1kind: ReplicaSetmetadata:name: nginx-rsspec:replicas: 2selector:matchLabels:project: chapter3matchExpressions:- {key: version, operator: In, values: ["0.1", "0.2"]}template:metadata:name: nginx-rs-podlabels:project: chapter3service: webversion: "0.1"spec:containers:- name: nginx-containerimage: nginxports:- containerPort: 80
再通过 kubectl create -f create_rs.yaml 命令,kubernetes便将开始创建指定的rs。
在yaml的sepc部分,可以看到通过 replicas 指定了将创建的副本数为2。
因为ReplicaSet是通过selector来管理pods,因此在定义中声明了selector的规则如下:
selector:matchLabels:project: chapter3 // rs中的pods需要满足label中的 project=chapter3matchExpressions: // 以及label中的version包含在(0.1和0.2)中- {key: version, operator: In, values: ["0.1", "0.2"]}
如果我们的pod的定义中声明的labels不满足rs selector的条件,则rs创建将失败。rs创建完成后,如果我们又自定义创建了能满足rs selector条件的pod,因为rs创建时指定了replicas为2,自创建的pod虽然能满足selector的要求,但不满足replicas的要求,因此自定义的pod亦将不会被纳入到rs。可通过 kubectl describe rs rs_name 的Event查看执行记录,及通过 kubectl get pods 查看当前的pod数量。
前面介绍过的 kubectl get <resource_type> kubectl describe <resource_type> <resource_name> 及 kubectl delete <resource_type> <resource_name> 操作对rs依然有效。
Deployments
Deployments是Kubernetes平台最基本的软件管理和部署方式,通过Deployments可以部署pods,实现软件的滚动更新及相关的ReplicaSet配置。通过Deployments部署软件的yaml文件格式示例如下:
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploy-testspec:selector:matchLabels:run: nginx-testreplicas: 2template:metadata:labels:run: nginx-testspec:containers:- name: nginx-containerimage: nginx:1.12.0ports:- containerPort: 80---kind: ServiceapiVersion: v1metadata:name: nginx-svclabels:run: nginx-testspec:selector:run: nginx-testports:- protocol: TCPport: 80targetPort: 80name: http
通过以上yaml定义文件,创建了一个包含replicas为2的ReplicaSet的Deployment及一个Service。同时可以看到Pod,ReplicaSet和Deployment之间的关系,如图:
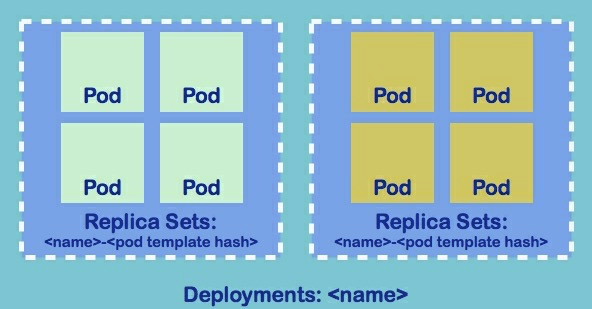
通过 kubectl get <resource_type> 可分别查看已创建出来的Deployment, ReplicaSet, Pod及Service。上面的定义中,通过定义Service,把 Deployment的端口暴露了出来。Service的定义也可以通过 kubectl expose deployment nginx-deploy-test --port=80 --target-port=80 来快速创建。
为了实现滚动升级(Rolling update),在定义Deployment时还可以声明rolling update策略,这里有三个参数用于控制rolling update:
| 参数 | 描述 | 默认值 |
| —- | —- | —- |
| minReadySeconds | 该参数用于指定warm-up时间,即用于确认一个新创建的pod到可用状态的时间。默认值表示Kubernetes认为一个pod成功装载后就已处理可用状态。 | 0 |
| maxSurge | 该参数用于标识在rolling update过程中最大扩充的pod比例或数量(用于替换update过程中下掉的pod) | 25% |
| maxUnavailable | 在rolling update过程中,不可用pod数占replicaset定义的pod数的比例或数量,如果maxSurge为0,则maxUnavailable不可为0 | 25% |
在上面的deployment定义文件中未声明rolling update策略,可通过更新操作 kubectl edit deployments <resource_name> 进行修改,如 kubectl edit deployments nginx-deploy-test ,然后把如下语句添加到deployment的spec部分:
minReadySeconds: 3stratety:type: RollingUpdaterollingUpdate:maxSurge: 1maxunavailable: 1
除了使用 kubectl edit 操作,还可以通过 kubectl replace -f create_deploy.yaml 来更新deployment的配置。
配置好更新策略后,现在就可以通过 kubectl set image deployment <deployment_name> <container_name>=<image_name:version> 来实现rolling up或rolling back了。比如更新上述定义的deployment内的容器中的镜像版本到1.13.1: kubectl set image deployment nginx-deploy-test nginx-container=nginx:1.13.1 ,如果需要再把1.13.1退回到1.12.0: kubectl set image deployment nginx-deploy-test nginx-container=nginx:1.12.0 。在发送 kubectl set image 命令后,可通过kubectl get pods查看当前的pod变化;通过kubectl describe deployment nginx-deploy-test查看Event记录。
Services
在Kubernetes平台中,Service作为一个抽象层,用于把流量路由给一组pod。通过Service,我们就不再需要跟踪每个pod的IP地址。通常Service通过label selector来选择一组需要统一路由的pod,不过有些特殊场景在定义Service有意不指定selector。通过Service可以实现微服务的解耦及通信。目前Service支持TCP、UDP和SCTP协议。
Service不在乎pod的创建方式,只关心匹配相关label的pod,所以即便属于不同ReplicaSet的pods也可以关联到同一个Service上。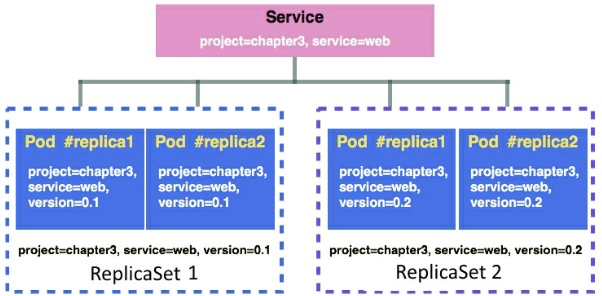
在Kubernetes中,Service有四种类型:ClusterIP, NodePort, LoadBalancer和ExternalName。其中ClusterIP、NodePort和LoadBalancer在特性上有一定的包含关系: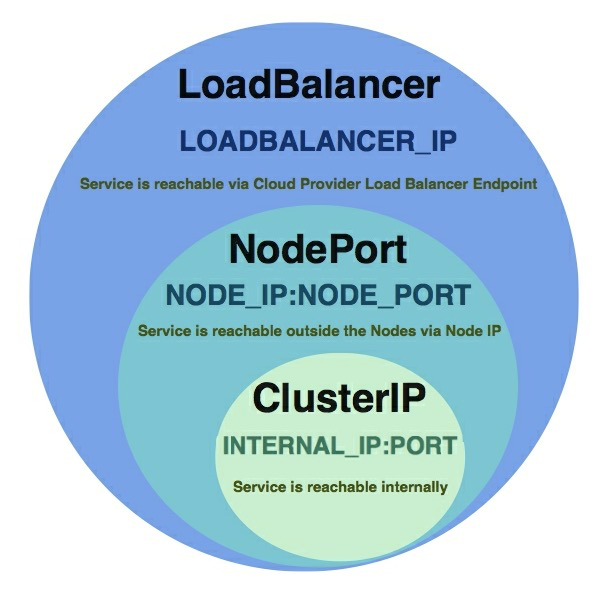
- ClusterIP
ClusterIP是默认的Service类型,通过ClusterIP可以把Service以集群内部IP的形式暴露出来。集群内的pod可以通过IP地址(IP Address)、环境变量(Environment variables)或DNS的形式去访问Service。ClusterIP类型的Service定义参考Deployments 部分的yaml代码。 创建好Service后,可通过 kubectl describe svc <svc_name> 来查看Service信息。其中主要包含的几个信息如下:
- Type:Service类型,当前为 ClusterIP
- IP:Cluster internal IP
- Endpoints:Service关联的pods的IP列表
在创建Service的同时,Kubernetes也同时创建了一个 endpoints 对象,可通过 kubectl get endpoints 和 kubectl describe endpoints <endpoint_name> 查看相关信息。在endpoints对象里保存并维护满足label select的pod地址,作为路由目标提供给Service使用。
另外,Kubernetes也会为每个Service暴露7个环境变量,其中前2个通常被 kube-dns 插件用来执行服务发现:
- ${SVC_NAME}_SERVICE_HOST
- ${SVC_NAME}_SERVICE_PORT
- ${SVC_NAME}_PORT
- ${SVCNAME}_PORT${PORT}_${PROTOCAL}
- ${SVCNAME}_PORT${PORT}_${PROTOCAL}_PROTO
- ${SVCNAME}_PORT${PORT}_${PROTOCAL}_PORT
- ${SVCNAME}_PORT${PORT}_${PROTOCAL}_ADDR
在同一集群的不同pod中,通过kube-dns插件可以直接使用 ${SVC_NAME}_SERVICE_HOST 来访问其他pod上的服务。
Kubernetes本身还集成了 DNS server ,开启后,相同cluster和namespace下的pod可以以Services的形式通过他们的DNS records来访问其他的Services。DNS serverc通过监听Kubernetes API请求,为新创建的Service创建DNS记录。DNS的表示的cluster IP格式: $svc_name.$namespace ,端口格式为 _$portname_$protocol.$svc_name.$namespace ,根据这个格式可以通过类似 http://nginx-service.default:_http_tcp.nginx-service.default/ 的形式去访问服务。
- NodePort
如果服务是NodePort类型,Kubernetes将为每个节点分配一个端口(从限定的端口范围内选择)。任何请求到节点该端口上的流量都将被路由到Service端口上。同时NodePort包含了ClusterIP的特性,为Service会分配一个集群内 IP。如果使用了iptables代理模式,则 kube-proxy 将监听Service及相应endpoints的变化并去更新相应的iptable rule。
- LoadBalancer
LoadBalance只能配合云服务使用(如Kubernetes on AWS, Kubernetes on GCP, Kubernetes on Azure)。
- ExternalName
可能通过ExternalName创建CNAME,用于提供给外部服务作为endpoints使用。(要求 kube-dns >= 1.7)
- Service without selectors
前面已经知道,通常定义Service时需要指定label Selectors,但有时你需要为Kubernetes cluster和其他namespace、cluster或外部资源之间提供一个代理,这种情况就可以通过Service without selectors 来实现。
首先定义一个无selector的Service,然后需要为该Service手动创建endpoint(因为未指定selector,所以Kubernetes不知道创建什么样的endpoints,所以需要自己创建),如下:
kind: EndpointsapiVersion: v1metadata:name: google-proxy ## 需要与Service同名subsets:- addresses:- ip: 108.177.9.104 ## 被代理的地址ports:- port: 80protocol: TCP
Volumes
因为容器是有生命周期的,所以容器的磁盘也会随容器而创建或消失。但我们可以使用 docker commit [CONTAINER] 命令或把数据卷挂载到容器。但在Kubernetes平台中,因为pod可以运行在任意node中,所以数据卷的管理变得重要,况且还有些处在同一pod中的多个容器需要共享相同的文件。Managing Stateful Workloads 将单独介绍Volumen的管理细节。
Secrets
以key/value格式保存私密数据的对象,用于向pod提供敏感信息,如密码、access key及token。Secret并不存储在磁盘上,而是存储每个节点上的 tmpfs 文件系统上,由Kubelete创建,用于存储Secret对象。因为文件系统的设计,Secret的最大限制是1M。
可以通过文件、目录或明确的字符值来创建Secret。在Kuberntes中有三种类型的Secret,分别为:
- generic(or opaque, if encoded):应用通常使用这种类型、
## 通过文件创建secret对象kubectl create secret generic <secret_name> --from-file=[secret_key=]xxxxxx
docker registry:存储私有docker仓库的证书,在拉取镜像时使用,又称作 imagePullSecrets 类型。
kubectl create secret docker-registry <registry_name> \--docker-server=<docker_server> \--docker-username=<docker_username> \--docker-password=<docker_password> \--docker-email=<docker_email>
TLS:存储集群管理所需要的CA证书
创建好的Secret有两种途径可以传递给pod:通过文件和通过环境变量。
- Retrieving secrets via files :这种方式通过Volume来实现,需要在容器的spec部分增加
volumeMounts
apiVersion: v1kind: Podmetadata:name: secret-access-podspec:containers:- name: centos-containerimage: centoscommand: ["/bin/sh", "-c", "while : ; do cat /secret/password-example; sleep 10; done"]volumeMounts:- name: secret-volmountPath: /secretreadOnly: truevolumns:- name: secret-volsecret:secretName: mydirpasswditems:- key: password1path: password-example
- Retrieving secrets via environment variables
通过环境变量是另外一种传递secret的方法,并且是一种更为灵活方法的传递简短信息的方式。容器内的应用可以通过环境变量的方式获取数据库密码等私密信息。
apiVersion: v1kind: Podmetadata:name: secret-access-envspec:containers:- name: centos-containerimage: centoscommand: ["/bin/sh", "-c", "while : ; do echo $MY_PASSWORD; sleep 10; done"]env:- name: MY_PASSWORDvalueFrom:secretKeyRef:name: mydirpasswdkey: password2
ConfigMap
- Using ConfigMap via volume
Using ConfigMap via environment variables
示例小程序
管理有状态的工作负载(Managing Stateful Workloads)
当你开始通过Kubernetes部署容器,你就必要考虑容器中应用数据的生命周期及CPU/内存等相关的资源管理。下面会就以下的内容做详情的讨论:
容器如何使用数据卷(volume)
- Kubernetes的数据卷功能
- Kubernetes持久卷(Persistent volume)最佳实践与糟糕用法
- 提交一个短暂的应用作为Kubernetes Job
Kubernetes 数据卷管理
默认情况下,Kubernetes和Docker都使用本地磁盘作为数据存储的媒介,只要宿主机有足够的磁盘空间并且应用有必要的权限,在容器的存活期内,应用就可以在容器内随意的存储数据。一旦容器被中止、退出、崩溃等,容器内的数据也将被随之销毁。在Kubernetes系统里,一旦一个pod被重启,pod内容器的数据也将随之消息。在同一个pod的不同容器间共享数据卷
尽管同一个pod内的容器可以共享相同的pod Ip地址、网络端口及IPC,容器内的应用可通过本地网络互相通信,即便如此,不同容器间的文件系统却是隔离的。然而有些应用系统却需要在不同的容器中共享目录或文件。
不需要在磁盘卷上保存数据;即便会在数据卷上写入数据,但数据丢失不会对应用造成影响,这类应用称为无状态应用(Stateless)。但有些应用,比如数据库或ElasticSearch的数据分片,必须通过持久化的数据卷保证数据的状态,这类应用称为有状态应用(Stateful)。
- 应用在不同容器间共享数据和目录,例如:通过同一pod上的logstash收集tomcat的日志
使用持久化数据卷技术实现有状态应用,例如:ElasticSearch集群的数据分片
Kubernetes’ persistent volume and dynamic provisioning(Kubernetes的持久卷和动态配置)
Kubernetes支持多种持久化的数据卷
公有云存储(例如:AWS EBS, GPD(google persistent disk)等)
- 分布式文件系统(例如:NFS, GlusterFS, Ceph等)
-
Abstracting the volume layer with a persistent volume claim
从容器管理的视角看,pod的定义中应避免与具体的持久化卷方案耦合,以减少pod与具体基础设施(如AWS EBS或GPD等)的绑定。理想的pod定义应具有灵活性,从具体的基础设施中抽象出来,只需要关注数据卷名称和挂载点。而Kubernetes提供了PVC(Persistent Volume Claim)方案来实现持久卷的抽象。
使用PVC的流程: 定义PersistentVolume
- 定义PersistentVolumeClaim
- 定义pod的volumes,并引用PVC
Dynamic provisioning and StorageClass
StorageClass是Kubernetes用于定义persistent volume动态配置的资源对象,用于降低预分配Persistent Volume对象的资源消耗(包括经济利益)。PVC向StorageClass要求动态分配persistent volume并把它联到PVC上。Problems with ephemeral and persistent volume settings
如果persistent volume只支持RWO(read write once, only one pod can write), 在Deployment管理的pod上挂载该persistent volume,在扩展pod时会因为每个新pod都试图挂载相同的persistent volume而面临扩展失败的问题。通常只有第一个pod能成功挂载到persistent volume上,后续的pod在发现不能挂载时会放弃并阻塞。
即便persistent volume支持RWX(read write many),在使用时依然需要考虑多个应用实例是否能使用相同的目录或文件(是否会带来写冲突)。
在面临以上文件时,就需要考虑把数据卷替换成数据库或其他BaaS方案。Replicating pods with a persistent volume using StatefulSet
StatefulSet用于非中心化场景的persistent volume,即同一个Deployment中不同pod的persistent volume相互独立,并随pod的创建或销毁而创建或销毁。
即便某个pod意外中止,Deployment在创建替换pod时,依然能使用刚刚中止的pod的persistent pod。向Kubernetes提交Job
前面介绍使用Deployment来部署应用,但Deployment更适用于以守护进程方式长期运行的应用。如果需要完成short-lived的功能(即提交一个请求,并等它完成,然后退出,与运行时间的实际长短无关),则需要使用Job。Kubernetes提供了四种Job类型,其使用方式又各不相同。
提交单个Job
apiVersion: batch/v1kind: Jobmetadata:name: package-checkspec:activeDeadlineSeconds: 60template:spec:containers:- name: package-checkimage: ubuntucommand: ["dpkg-query", "-l"]restartPolicy: Never
activeDeadlineSeconds 设定任务的最大运行时长,如果超时将自动中止;restartPolicy设定任务重启策略,这里设置的Never,即便失败也不会重启;另外还可以设置为OnFailure,如果任务失败,Kubernetes将尝试重新提交Job,直到Job成功完成。
提交任务后,系统将自动创建一个Job资源和一个Pod资源;通过kubectl get job 可以查看job的运行状态及运行持续时长;即便Job结束后,Pod资源依然存在,其状态新变为Completed。
提交可重复Job
创建脚本类似于单个Job,不过在spec下需要多配置一个completions 参数,启动脚本后,Kubernetes将按completions的设置依次创建多个pod来分别执行任务。但需要注意的是repeat Job在的多个任务是顺序执行的,即前面的Pod执行完成后,后面的Pod开始创建并执行任务。
提交并行Job
创建脚本类似于单个Job,但需要额外在spec下配置一个parallelism 参数来指定并发量。
使用CronJob进行周期性处理
使用CronJob可以创建需要周期性定时执行的Job。创建CronJob时需要通过schedule 参数设置以下几个信息:
- Minutes: 0-59
- Hours: 0-23
- Days of the month: 1-31
- Months: 1-12
- Days of the week: 0(Sunday)-6(Saturday)
创建CronJob脚本:
apiVersion: batch/v1beta1kind: CronJobmetadata:name: package-check-schedulespec:schedule: "*/5 * * * *"concurrencyPolicy: "Forbid"jobTemplate:spec:template:spec:containers:- name: package-check-scheduleimage: ubuntucommand: ["dpkg-query", "-l"]restartPolicy: Never
注意CronJob的Kind为CronJob,并通过schedule指定任务周期;concurrencyPolicy来指定并发策略,即上一次任务未结束时,下一次任务的处理策略,可用值有:Allow, Forbid, Replace;另外还可以分别指定successfulJobsHistoryLimit及failedJobsHistoryLimit用于设定成功或失败执行任务的pod资源数量,超过设置数值后的pod将被销毁。

若有收获,就点个赞吧
0 人点赞
