- 公有云的Serverless平台
- 私有云快速支持Serverless能力的工具
- AWS Lambda
- Azure Functions
- 容器技术基础
- Kubernetes基础:
- Kubernetes 常用命令
- 以下命令中的 serverless 为自定义的namespace名称,httpd及centos为deployment名称
- 查看当前kubernetes的节点数据
- 创建命名空间
- 在上面定义的命名空间中,启动docker镜像,并指定部署名称为httpd
- 查看命名空间下的所有资源信息
- 查看指定命名空间的pod信息
- 查看命名空间下的deployment信息
- 查看命名空间下的replicaset信息
- 查看命名空间下的service信息
- 查看pod描述信息
- get pod -o wide
- 基于已定义的名称和命名空间,把集群节点扩展到2个
- 获取 httpd 的deployment信息
- expose 把deployment名为httpd下的所有实例创建为一个服务Service对象
- 获取和描述服务信息
- 启动一个centos 镜像 pod
- 到上面启动的centos 镜像中执行命令
- 同一个kubernetes集群内可通过server的名字发现服务的调用地址
- 如在centos机器上可通过 Service名.命名空间.svc.集群域 访问服务
- 列出各资源的标签
- 筛选特定标签的对象,筛选出的对象包含Pod, Deployment及ReplicaSet三类对象
- 通过标签删除一次部署所产生的所有对象
- 为节点打”web=true”的标签
- 容器调度,编辑容器的部署配置
- 查看容器实例的关联事件
公有云的Serverless平台
- AWS Lambda
- Azure Functions
- Google Cloud Functions
- 阿里云
- 腾迅云
私有云快速支持Serverless能力的工具
- OpenWhisk
- Fission
- Kubeless
- OpenFaaS
AWS Lambda
AWS Lambda 重要组件:
- 函数:可执行的业务逻辑代码
- 事件源:触发函数执行的触发方
- 事件:描述了触发函数的原因
AWS IAM
- 用户:
- 组:
- 角色:是IAM权限的一种组织方式。可以将若干个定义好的策略规则赋予某个角色,然后再将该角色赋予某个用户或组,例如用户可以为一个特定的权限需求定义一个角色,然后将该角色赋予若干个有着相同权限需求的Lambda函数。
- 策略:定义了权限的所有者可以对什么服务的什么资源进行什么操作
编程模型
- Handler:一函数的执行入口,AWS Lambda会执行Handler定义的函数,并将上下文对象Context传递给该函数。
- 执行上下文:
- 日志输出:
- 异常处理:
无状态:
事件驱动
事件源
- 触发模式:
- 推模式(Push):比如文件系统里添加一个新文件,并主动通知Lambda服务。
- 拉模式(Pull):比如用户向DB中插入数据,持续监控DB服务的Lambda服务将会获取到事件并触发Lambda函数。(困惑)
配置与部署
容器技术基础
- 容器:隔离的虚拟环境,通过Linux系统中的namespace使得资源得以相互隔离,通过cgroups对进程的CPU/内存/存储及IO资源的使用进行限制和管控。
- 容器镜像:是Docker对应用进行打包的一个格式。通过镜像可以加速应用的部署速度,通过容器镜像的分层可以提高镜像的重用性。
- 镜像仓库:
- 容器编排:管理大量主机上的容器的技术手段
- 容器与Serverless
- 容器环境和镜像为FaaS函数应用提供了一种可以适配各类编程语言的运行环境和部署格式
- 为Serverless FaaS函数实例的运行提供隔离和可控的环境
- 容器编排平台为Serverless应用的弹性扩展提所需的各类计算资源
- Vagrant:虚拟机管理工具,可以帮助用户快速启动和配置VirtualBox, VMWare等虚拟化工具的虚拟机实例。
- vagrant version
- vagrant init ubuntu/xenial64
- vagrant up
- vagrant suspend/vagrant halt
- vagrant ssh
- 通过vagrant ssh 登陆到虚拟机上之后,为ubuntu系统安装 docker:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"sudo apt-get updateapt-cache policydocker-cesudo apt-get install -y docker-ce
- 启动docker:
sudo systemctl start dockersudo systemctl enable docker
# 更改用户权限,免去使用sudo执行docker命令sudo usermod -aG docker ${USER}exitvagrant ssh# docker版本检查docker version# 运行dockerdocker run -d --name web httpd:2.4# -d:以后台进程运行# --name web 以"web"的名称运行# httpd:2.4 运行的镜像的名称及版本号# 查看系统正在运行的容器列表docker ps# 在容器内执行命令docker exec -it web bash# web 为刚才创建的docker进程名称# bash 为要执行的名称为web的docker容器内的命令# 停止docker实例docker stop web# 重启docker实例docker restart web# 删除已停止的容器实例docker rm web# 查看已下载到本地的镜像列表docker images# 创建镜像docker build -t my-httpd:1.0 dir# my-httpd:1.0 镜像名称及版本号# dir 为被build进镜像的目录,其中需要包含 dockerfile# docker分享docker tag my-httpd:1.0 repository.com/my-httpd:1.0docker push repository.com/my-httpd:1.0docker pull repository.com/my-httpd:1.0
Kubernetes基础:
Kubernetes是Google推出的开源容器编排平台。一个完整的Kubernetes架构是一个计算集群,包含若干台主机,这些主机有两种角色:Master及Node,在其上运行着不同种类的组件。
- Master:是Kubernetes中的控制节点,包含各类管理组件,如Api Server及Controller Manager,它们负责集群状态的控制。为了高可用,可有多个Master。Master之间通过底层数据库etcd实现状态同步。
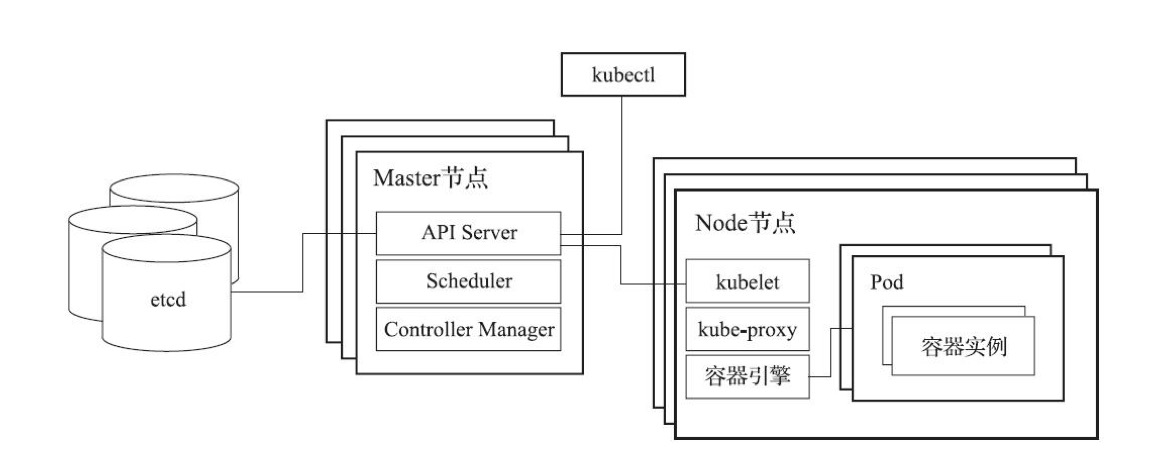
- Node:是Kubernetes中的计算节点,负责运行具体的容器实例,向Master上报状态并接受调度指令。
- Api Server:Node节点通过Api Server的API与Master进行通信,用户命令行通过与Api Server的通信实现对Kubernetes集群的操作。
- Controller Manager:运行在Master节点上。在K中,各种功能都是通过独立的Controller实现,C M 实现对各类Controller的管理。
- Scheduler:为运行在Master节点上的调度器,负责容器应用的部署调度,如寻找满足容器应用部署所需要的集群节点。
- ectd:开源的分布式kv数据库,集群的状态和资源都定义在etcd数据库集群中。
- kubelet:运行在Node节点上的组件,负责监控Node节点及其上容器的状态并汇报给Master。
- kube-proxy:运行在Node节点上的组件,负责对Service组件的管理。
- 容器引擎:运行在Node节点上,负责容器的生命周期管理。
- 命名空间:对资源进行组织,用来分隔不同资源。
- Pod:Kubernetes定义的一种特殊的容器,用户运行的容器应用可以认为是运行在Pod这种特殊容器之中。一个Pod可包含一个或多个容器,并共享该Pod的网络和容器资源。通常一个Pod内只会包含一个容器。Pod是Kubernetes的调度和扩展的基本单元。
- Service:作为Pod实例的前端,实现流量的负载均衡及集群内的服务发现。
- Deployment:描述容器部署信息的资源对象,记录用户需要部署的容器的镜像地址、实例数量及配置信息,以YAML或JSON格式表示。
- ReplicaSet:负责监控容器实例状态的资源对象,保证实际运行的容器数量与用户定义的容器实例数量相符。
- 网络:Kubernetes与多种软件定义网络(SDN)方案集成,为集群中的容器提供虚拟网络。每个容器都会获取一个虚拟IP地址,相同集群内可通过IP地址进行通信。
- Ingress:将集群内部服务对外发布的一种方式,作用类似于反向代理,使得集群外部的主机通过Ingress可访问Kubernetes内部容器的服务。
- Ingress对象:描述了流量转发规则
- Controller对象:规则的执行者,根据Ingress对象定义的规则,对请求进行转发,可通过Nginx或HAProxy等反向代理软件实现。
- 交互工具:
- kubectl
- Web界面
- 资源组织:在K集群中可以为对象添加标签,通过标签可以对对象进行批量操作。标签是K的一种有效的资源组织方式。
- 资源调度:K可以根据容器部署配置的需求将容器调度到满足条件的集群节点上运行,确保节点上有足够的CPU、内存等资源;此外,用户也可以通过在部署中设置节点选择器(Node Selector)的方式让容器部署到指定的集群节点上。(通过kubectl editor可编辑容器的部署配置。)
```bash
Kubernetes 常用命令
以下命令中的 serverless 为自定义的namespace名称,httpd及centos为deployment名称
查看当前kubernetes的节点数据
kubectl get nodes
创建命名空间
kubectl create namespace serverless
在上面定义的命名空间中,启动docker镜像,并指定部署名称为httpd
kubectl run httpd —image=httpd:2.4 —port 80 -n serverless
查看命名空间下的所有资源信息
kubectl get all -n serverless
查看指定命名空间的pod信息
kubectl get pod -n serverless
查看命名空间下的deployment信息
kubectl get deployment -n serverless
查看命名空间下的replicaset信息
kubectl get replicaset -n serverless
查看命名空间下的service信息
kubectl get service -n serverless
查看pod描述信息
kubectl describe pod -n serverless
get pod -o wide
kubectl get pod -o wide -n serverless
基于已定义的名称和命名空间,把集群节点扩展到2个
kubectl scale —replicase=2 deployment/httpd -n serverless
获取 httpd 的deployment信息
kubectl describe deployment httpd -n serverless
expose 把deployment名为httpd下的所有实例创建为一个服务Service对象
kubectl expose deployment/httpd -n serverless
获取和描述服务信息
kubectl get svc -n serverless kubectl describe svc -n serverless
启动一个centos 镜像 pod
kubectl run centos —image=centos:7 -n serverless —command — bash -c ‘sleep 3d’
到上面启动的centos 镜像中执行命令
kubectl exec -it centos-pod-id -n serverless bash
同一个kubernetes集群内可通过server的名字发现服务的调用地址
如在centos机器上可通过 Service名.命名空间.svc.集群域 访问服务
curl httpd.serverless.svc.cluster.local
其中cluster.local为集群域名(默认域名为:k8s.local),可自行修改后通过vagrant reload生效
/etc/systemd/system/kubelet.service /etc/kubernetes/manifests/kube-dns.yml
查看cluster.local是否生效
ps aux | grep cluster.local
label 相关
列出各资源的标签
kubectl get all -n serverless —show-labels
筛选特定标签的对象,筛选出的对象包含Pod, Deployment及ReplicaSet三类对象
kubectl get all -l run=centos -n serverless
通过标签删除一次部署所产生的所有对象
kubectl delete all -l run=centos -n serverless
为节点打”web=true”的标签
kubectl label node nodeip web=true
容器调度,编辑容器的部署配置
kubectl edit deployment httpd -n serverless -o json
在打开的配置信息中,可添加”nodeSelector”: {“web”:”true”},来表示httpd窗口需要运行在带有标签web=true的机器节点上。
查看容器实例的关联事件
kubectl describe pod pod实例id -n serverless | tail -5
<a name="hkhTM"></a>#### OpenWhisk基础OpenWhisk是一套开源的Serverless平台工具,基于OpenWhisk,IBM推荐了商用的Serverless公共云服务[IBM Cloud Functions](https://console.bluemix.net/openwhisk)。OpenWhisk本质上是一个事件驱动平台,各类事件源向平台发送事件消息。- 事件(Feed)- 触发器(Trigger):事件到达平台后触发触发器- 规则(Rule):平台根据规则触发相应的动作- 动作(Action):是用户定义的函数逻辑- 调用链(Sequence):多个动作可以构成调用链用户在各种动作中调用其他外部服务以完成最终的任务。- 逻辑构架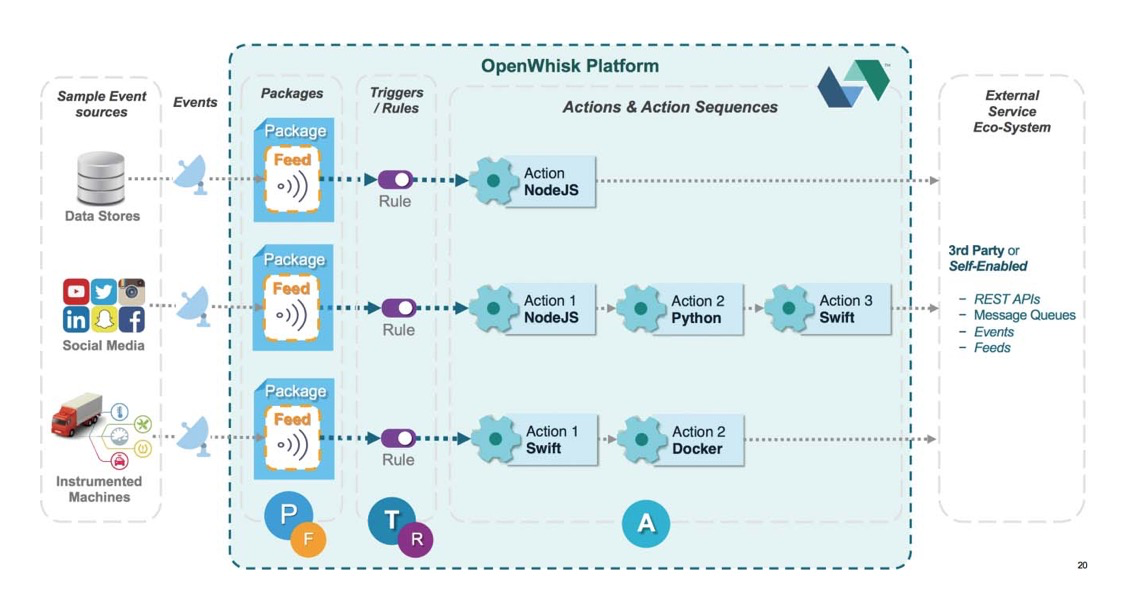<br />OpenWhisk的逻辑架构- Namespace:是OpenWhisk组织资源的方式,可以将相关的各类资源收纳于同一个Namespace中。在OpenWhisk中存在一个名为default的Namespace。系统还内置一个名为/whisk.system的Namespace,用于存放系统默认对象。- Package:同样用于组织对象,同一个Namespace中可包含多个Package。Package还是资源共享和重用的重要方式。用户可以将自己的Package共享给其他用户,或通过Package导入其他用户贡献的功能。- 通过 `wsk package list` 命令可以查看Namespace中的Package列表。如 `wsk package list /whisk.system`- 通过 `wsk package get` 查看Package里的内容,如`wsk package get /whisk.system/github`- Action:用户定义的函数- wsk action create hello hello.js:可以创建一个名为hello的Action。- wsk action list: 查看action列表- wsk action invoke hello --blocking -r:以同步的形式调用hello函数,默认是异步调用并返回一个activationid- wsk activation get activationid:通过activationid查看异步执行的结果- Activation:异步执行action返回的活动对象- 查看activation日志:wsk activation log activationid- 查看结果:wsk activation result activationid- Sequence- wsk -i action create splitAndSort --sequence /whisk.system/utils/split,/whisk.system/utils/sort:通过split和sort两个函数定义一个新的调用链函数:splitAndSort- wsk action invoke splitAndSort -p payload 'abc,bef,agb,bad,cde' -p separator ',' -r:执行splitAndSort函数- Feed:事件和事件源是事件驱动架构中的核心概念,Feed(消息)是OpenWhisk中代表事件源发送来的事件的流(Stream)。OpenWhisk支持获取事件的三种模式:- 被动接收:提供可被外部访问的Web Hook地址,事件源在事件发生时通过该地址把事件发送至OpenWhisk- 主动轮询:在OpenWhisk中定义一个周期性的Action,通过调用目标系统的API查询并获取事件- 长连接:在OpenWhisk外运行独立程序,该程序负责与目标源事件系统建立长连接并获取事件通知OpenWhisk。- Trigger:被看作事件的管道,一端为事件源,另一端为函数Action。- 创建(未关联action的)Trigger:wsk trigger create peopleShowUp- 触发Trigger:wsk trigger fire peopleShowUp -p name nico,通过-p指定参数- 创建Trigger,并指定在收到特定Feed时触发:wsk trigger create everyOneMinutes --feed /whisk.system/alarms/alarm -p cron '*/1 * * * *'- Rule:描述Trigger与Action的对应关系的对象,可以在规则中定义逻辑条件,并当条件满足时触发Action。- 创建rule: wsk rule create checkCheck(rule name) peopleShowUp(trigger name) hello(action name)。- 查看规则列表:wsk rule list- 系统架构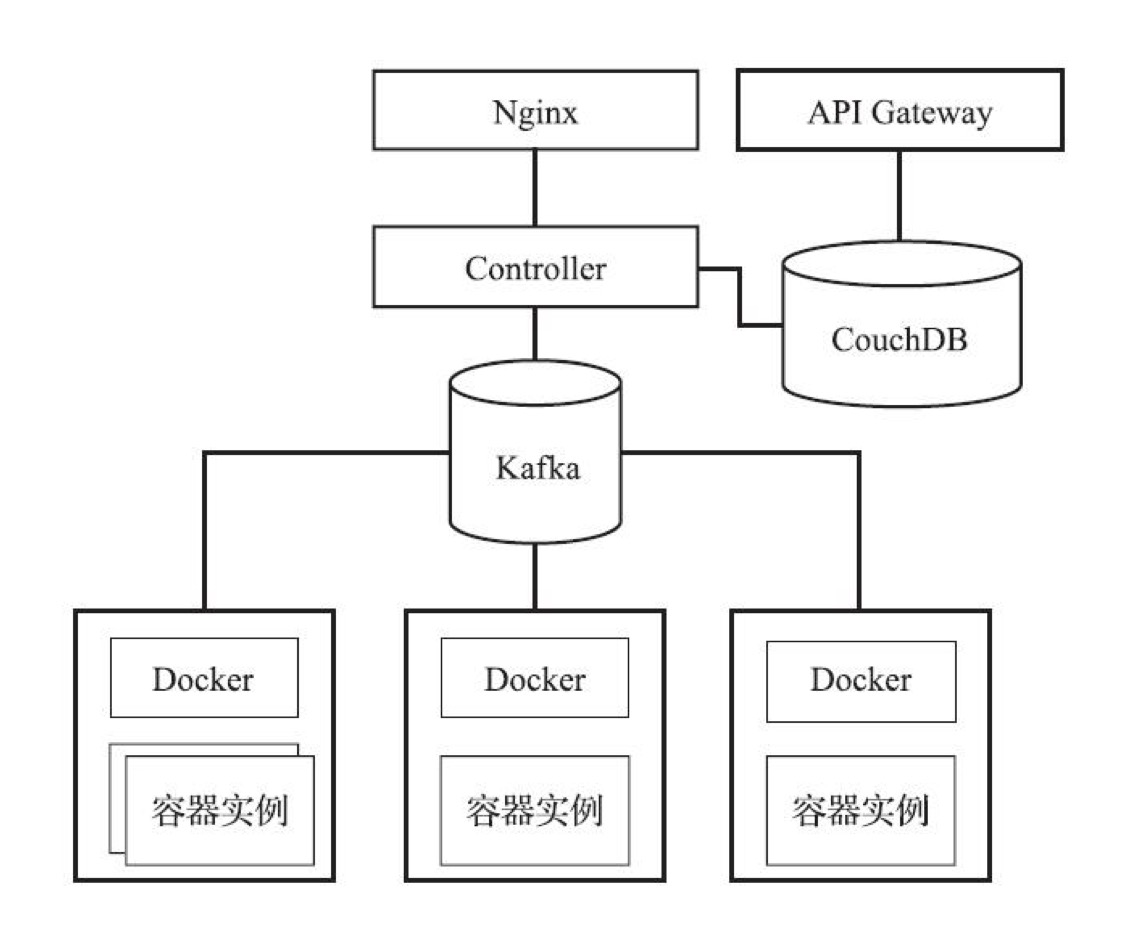- 反向代理:通过Nginx作为集群的反射代理。- Controller:OpenWhisk的逻辑核心,wsk执行的命令最终都会通过Controller进行分析和处理。- 数据库:存储了OpenWhisk中绝大部分信息,包括用户信息、Package、Trigger、Rule及Action等资源对象。- Kafka:通过Kafka实现Controller与函数执行的解耦,解决高并发场景的性能问题。- Invoker:负责函数的调用的组件。Invoker负责管理OpenWhisk集群节点的容器引擎,根据Controller发送的指令启动和管理容器实例,执行函数代码。支持Docker和Kubernetes两种服务接口实现。- Docker:函数最终的执行环境。- API Gateway:负责Action与外界的通信。- 手工在Kubernetes上部署OpenWhisk- <br />- 基于Helm在Kubernetes上部署OpenWhisk<a name="YdrYz"></a>#### Kubeless基础完全基于Kubernetes的的Serverless FaaS框架。通过Kubernetes的Horizontal Pod Autoscaler对函数实例进行弹性扩展。- 系统架构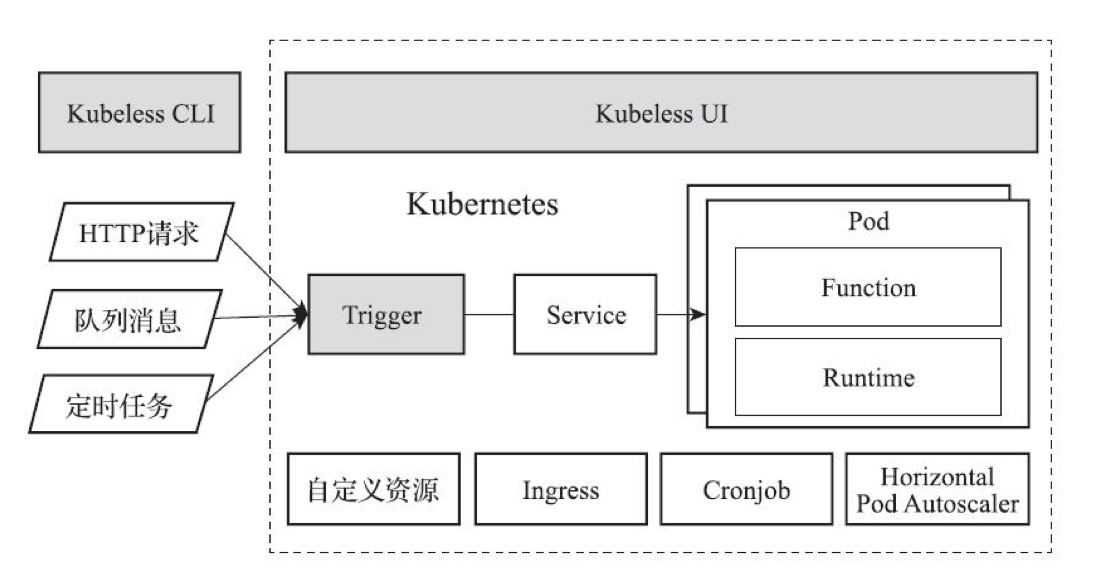- Function为用户定义的Serverless函数- Runtime为函数运行所需要的运行时环境,以容器镜像的形式存在- Trigger为函数触发条件的定义,定义了函数触发的规则- Kubeless CLI 和UI 是交互工具- 通过Kubernetes的Service实现函数调用入口- 通过Kubernetes的Ingress实现函数的HTTP Trigger- 通过Kubernetes的Cronjob实现定时函数的Cronjob Trigger- 创建于Kubernetes中的Kubeless Controller Manager容器是Kubeless的控制中枢。- 基于vagrant实验kubeless```bash# 初始化并安装已包含kubernetes环境的虚拟机vagrant init flixtech/kubernetes --box-version 1.10vagrant upvagrant ssh# 创建一个kubernetes命令空间:kubelesskubectl create ns kubeless# 部署Kubelesskubectl create -f https://github.com/kubeless/kubeless/releases/download/$RELEASE/kubeless-non-rbac-vxxxx.yaml# 查看pod容器kubectl get pods -n kubeless# 查看自定义资源(自定义资源定义是(CRD)Kubernetes重要的扩展手段,Kubeless借助Kubernetes的CRD创建了几个资源定义,# 并完全可能通过kubernetes的标签API来访问这些自定义资源)kubectl get customresourcedefinition## cronjobtriggers.kubeless.io## functions.kubeless.io 通过该资源,用户可以通过Kubernetes默认命令行工具直接操作Kubeless的Function对象## httptriggers.kubeless.io## 安装kubeless命令行工具kubeless,kubeless默认读取kubectl命令的用户配置文件~/.kube/config获取对Kubenetes集群的操作权限。cp /etc/kubeconfig.yml ~/.kube/config## 部署函数kubeless function deploy get-python --runtime python2.7 --from-file test.py --handler test.foobar --cpu 1 --memory 1Gi## get-python 为函数名## runtime:运行环境## test.py:函数文件## handler:指定处理方法## cpu: 非必填,限制该函数使用的计算能力## memory:非必填,限制该函数使用的内存空间## 函数部署后,会在kunernetes中生成一个与函数同名的deployment资源,可通过如下命令查看kubectl describe deployment get-python -n default# 查看函数kubeless fuction ls [函数名]# 查看日志kubectl logs -n kubeless -l kubeless=controller -c kubeless-function-controller# 查看函数可有哪些操作kubeless function -h## 自动扩展,使用了kubernetes的水平扩展器(Horizontal Pod Autoscaler, HPA)实现。kubeless autoscale create get-python --max 5 --min 1 --metric cpu --value 50# 查看扩展配置kubeless autoscale lskubectl get hpa -n default
- Trigger:Kubeless的事件响应机制是通过触发器Trigger实现的,Kubeless通过定义Trigger将事件源与函数进行关联。
- HTTP Trigger:创建一个函数可被外部访问的途径,HTTP Trigger的实现依赖于Kubernetes的Ingress机制。
kubeless trigger http create get-python-trigger \--function-name get-python \ ## 指定关联的函数 get-python--hostname get-py.example.com \ ## 指定关联函数调用的域名--path echo \ ## 指定关联函数调用的路径--gateway nginx ## 指定前端Ingress Controller使用的Nginx# 查看已定义的http triggerkubeless trigger http ls## 因为每一个http trigger创建的同时,Kubeless都会去创建一个Kubernetes Ingress对象,所以查看相应的Ingress信息kubectl describe ingress get-python-trigger -n default
- Cronjob Trigger:适用于需要定时执行的函数实例。
# 创建cronjob triggerkubeless trigger cronjob create every-5-min-trigger --function get-python --schedule '*/5 * * * *'## every-5-min-trigger为trigger名称## function:指定了执行函数## schedule:指定了定时执行规则## cronjob Trigger创建的同时,Kubeless也会创建一个与之对应的Kubenetes的Cronjob对象kubectl get cronjob
- Kafka Trigger
-
Fission基础
Fission是基于Kubernetes的Serverless框架,增强了K8s的能力,并把函数和事件驱动的计算模式引入到K8s平台。Fission在K8s的基础上引入了FaaS平台的概念,并为用户屏蔽了容器和容器平台底层的细节。
逻辑构架
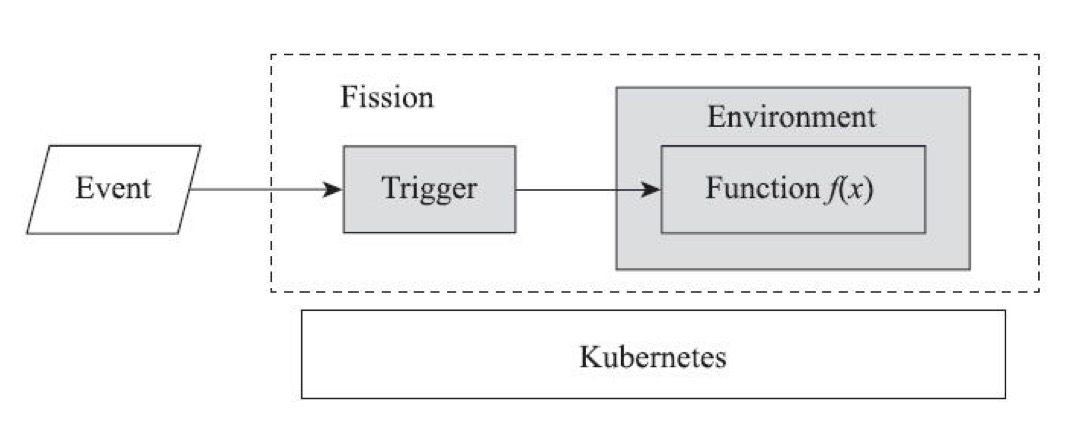
- Function为用户定义的函数
- Environment为用户定义的函数所运行的环境
- Trigger定义了触发函数的事件源,支持HTTP、定时及消息队列
- 系统架构
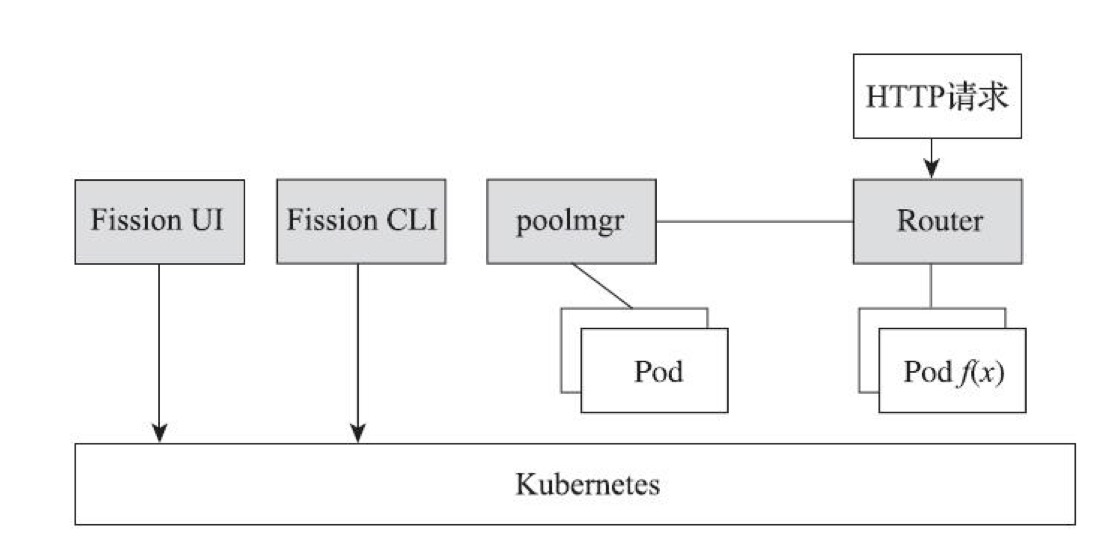
Fission在k8s平台上引入了poolmgr及Router等组件实现FaaS的事件驱动和按需执行等关键特性。
- poolmgr:负责管理预先启动的容器资源池,以缩短函数冷启动所用的时间
- Router:负责HTTP请求的分发,是外界调用函数的入口
- Fission提供了命令行工具和Web控制台作为用户交互客户端
- 部署Fission
可以通过Helm将Fission部署到k8s上。
- 深入Fission
Fission引入的Environment、Function及Trigger等概念最终都在K8s中以自定义资源定义(CRD)形式存在,通过kubectl命令 kubectl get crd 可以查看Fission在部署时创建的自定义资源列表。Fission扩展了k8s中的逻辑概念,使得通过原生k8s api和命令就可以操作Fission对象。Fission对象也会被存储在K8s的etcd数据库中,无须额外的数据持久化处理。
Environment
# 创建一个环境,默认在fission-function命名空间中fission env create --name nodejs --image fission/node-env:0.7.2# 通过fission命令查看环境列表fission env list# 通过kubectl命令查看环境kebuctl describe environment nodejs# 查看pod信息kebuctl get pod -n fission-function
Function
# 创建functionfission function create --name hello --env nodejs --code hello.js# 查看functionfission function list# 查看函数详情信息kubectl describe function hello# 创建packagefission package create --env nodejs --deploy echo.js# 查看fission列表fission package list# 基于package创建functionfission function create --name echo --pkg echo-js-gfp1
Trigger
- HTTP Trigger
- Time Trigger
- Message Queue Trigger
- 执行模式
- Pool-based:基于poolmgr组件实现,由poolmgr负责管理一个容器资源池,该资源池中的容器并不含有具体函数代码的Environment容器实例,当用户调用函数时,Fission将函数注入到容器池的空闲实例中,该过程称为Specialized。当函数容器实例空闲一段时间后,Fission将清除该容器实例,回收相应的计算资源。由于存在一个预先准备的容器资源池,因此Pool-based模式函数冷启动时间较短。
- New Deploy:当用户创建函数时,Fission将直接创建一个对应的K8s的Deployment对象部署特定函数的容器实例。通过K8s的弹性扩展特性(HPA),函数的Deployment实现按需的特性伸缩。
- OpenFaaS技术栈

若有收获,就点个赞吧
0 人点赞
