stream流回顾
stream流 jdk8 的新特性 简化对集合的查询、过滤、映射、等操作
流是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行
stream 的操作三个步骤
1.创建流 :对于集合和数组对象 .stream()
2.中间操作:.filter() sorted() map() 等等
3.终止操作:foreach() collect(Collectors.joining(“,”))//收集成字符串用逗号拼接
自媒体文章文章管理
1.自媒体文章列表查询
功能说明:自媒体前端用户在操作内容列表的时候,要实现一些功能,如分页查询,根据文章状态查询,创建时间查询等等
大致流程:校验参数->根据需求构建查询条件->执行查询->按要求设置返回数据并返回
操作资源:自媒体数据库的文章表
涉及技术:mybitsPlus,spring
BUG总结:利用工具测试成功后,前端无法正常显示//原因: host参数未设置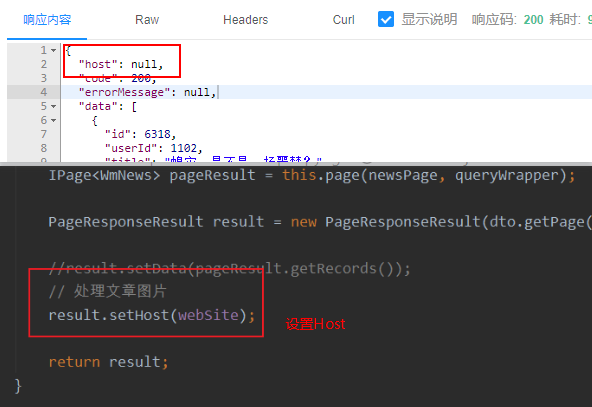
2.频道列表展示
功能说明:文章展示列表页面打开的时候,默认自动加载频道列表数据进行展示,就是查询所有频道数据
大致流程:在admin服务里新增一个查询全部频道的接口 用MP的.list()查询即可获得,无需去业务层编写;
操作资源:运营端数据库的频道表
涉及技术:网关路由,在配置中心 的 自媒体网关配置文件里添加 admin服务的路由
一个网关可以配置多个微服务路由 , 一个微服务的路由信息可以被多个网关配置
BUG总结:无
3 自媒体文章-发布、修改、保存草稿
功能说明:自媒体用户 编辑或修改文章,添加文本或图片,生成封面,提交或保存草稿。
大致流程:需要用到三张表 素材表(查询),文章表(做保存和修改),文章素材关联表(保存文章和素材的关系)
操作资源:自媒体数据库中的 文章表、素材表、文章素材关系表
涉及技术:解析文本(JSON、Stream),性能优化(动态SQL foreach标签 批量查询,批量修改)
BUG总结:自动生成的封面在前端无法显示出来 //在自动生成封面的逻辑代码里 没有设置文章的type属性并修改保存
4 自媒体文章-根据id查询
功能说明:
大致流程:
操作资源:
涉及技术:
BUG总结:
5 自媒体文章-删除 (实战练习)
功能说明:先删除关联关系表,再删文章表
大致流程:
操作资源:
涉及技术:
BUG总结:
6 自媒体文章-上架、下架 (实战练习)
功能说明:对已经上下架的文章进行上下架操作
大致流程:判断文章的状态,根据传入的参数id查询文章,修改状态值,保存修改
操作资源:文章表
涉及技术:。。。。
BUG总结:无
面试热点
JDK Stream流的使用方式
获取流对象:
对于集合 : 集合对象.Stream()
数组 : 数组对象.Stream() 自动生成 Arrays.stream(数组对象)
几个元素 Stream.of()
执行中间操作 : 过滤,映射,截取,忽略,去重,排序等等
终结操作 :收集/遍历/规约
发布文章的流程(业务流程,涉及表,具体实现)
具体实现
1.校验参数,判断用户登陆状态
2.处理特殊字段,文章的封面类型的值 -1 不可以保存改为NULL,images需要从集合转成字符串(json,strem进行操作)
3.初步保存数据到文章表中
4.判断是否为草稿 ,草稿直接返回
5.解析内容获取图片路径的集合(json,strem进行操作)
6
保存内容图片与素材id的 关联关系
.图片路径的集合去素材表查对应的ID集合 ,优化后的方法 自定义一个查询方法,用foreach标签批量查询
用获取的素材ID集合,文章ID,引用类型(0内用引用 1封面引用)作为参数 批量插入到素材文章关系表中
7.保存封面图片和素材id的关联关系
判断封面类型 1 单图 3 三图 0无图 -1自动
单图 和 三图 直接从参数里获取 经过 stream()处理得到图片路径集合,执行步骤6中的保存方法
无图 不需要保存
自动 根据内容中的图片判断保存封面的模式,并更新文章表中的type(封面类型)字段

若有收获,就点个赞吧
0 人点赞
