In Flink there is no cross-task communication.
这句话归根结底是由于Flink的编程模型决定的。flink底层使用了Akka,也就是Actor模型,这是一种无共享编程模型,actor与actor之间只有消息传递。这种编程模型牺牲了共享(也就是communication)能力,最大化了吞吐量。具体到flink实现层面体现在:(运行时)- 不同的task也就是不同的算子之间无法共享state
- state只有fault tolerant的能力,没有在逻辑算子上共享状态的能力,算子的每一个物理体现也就是subtask都有自己的state,这些subtask的所有state的串联才是一个算子逻辑上的state。
flink能提供的最大限度的运行时state共享是connect(BroadcastStream)时,BroadcastStream能携带一个状态,这个状态对connect广播流的那条流的所有并行实例都是一致的,但只对BroadcastStream开放读写权限,另外一条流只有只读权限。
Ps:通过Accumulator也能提供一个全局累加器,但是这个累加器只是在job完成以后合并多个并行累加结果返回给客户端。
Flink stateful operator和exactly-once的基石: https://zhuanlan.zhihu.com/p/113612578 Chandy-Lamport算法
- job的每一个算子在runtime时表现为多个subtask(取决于并行度), 每个subtask都是独立的,他们在不同的线程中执行,甚至可能在不同的机器或者容器中
- Stream数据传递分两种模式:one-to-one和redistribute。one-to-one就是典型的forward传递,且能保证顺序。redistribute比较典型的是keyBy,broadcast, rebalance, window。下面的图之前存在误区,map之后的keyBy并不会导致并行度变为1.
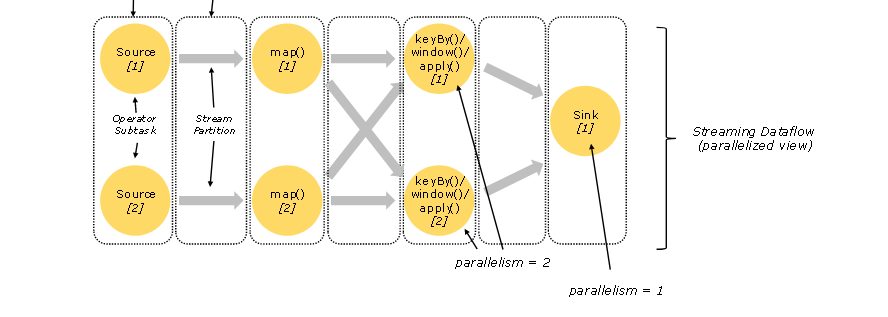
- 为了保证flink应用的高吞吐和低延迟,每个subtask算子上的状态都保存在本地(这个subtask所在的jvm heap或者机器磁盘上)
- 通过state checkpoint和stream replay,flink可以实现fault tolerant和exactly-once语义。
- flink keyBy会导致network shuffle以及由于网络通信带来的序列化和反序列化开销,是比较昂贵的操作。keyBy过后流变成多个并行的处理流,每一个负责部分key。
- flInk state分为keyed state和普通的opeartor state,以及broadcast state
- 关于operator state很重要的一点是:operator 的每一个并行实例都绑定有一个opreator state,在运行时每个并行operator subtask之间的state是独立的。但当并行度改变时,支持在所有的并行subtask之间重新分发状态,并且分发方式可以是多样的。context.getOperatorStateStore().getListState()每个并行subtask随机获得state的一部分。getUnionListstate()每个并行subtask都会获得完整的state。
- keyedState分为Map , List和Value,每个key都有自己的state,但是这是隐式的,看上去共用一个
- broadcast state是一种特殊的operator state,只用于存在广播流的情况。广播流是为了把一个stream的record同时发送给下游所有的subtask(不同于普通的并行operator每个都有自己的分区且是one-to-one传递)。广播流可以附带一个broadcast state,并且在处理广播流的record的时候可以access广播状态。
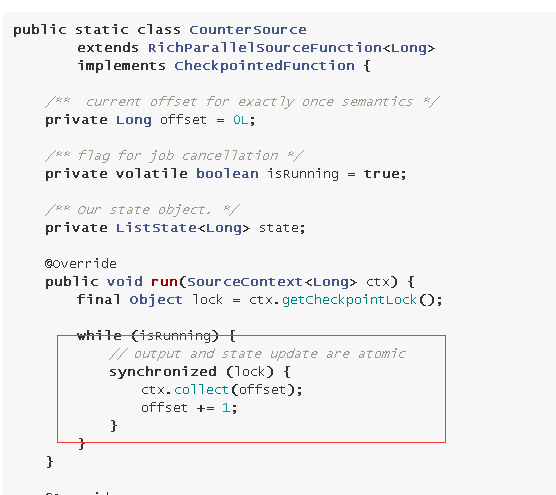
- 在实现有状态的source时需要特别注意,如果需要提供exactly-once语义,我们必须保证state的更新和output collect是一个事务操作,为此需要借助context lock.
- state TTL(time-to-live)可以指定state中的条目什么时候过期。state中的每一个条目都可以独立地被cleanup。
- StateTtlConfig builder的参数是过期时间,setUpdateType指定state TTL存活时间如何刷新,setStateVisibility设置状态的能见度(过期即不可见还是被真正回收以后才不可见)

- state中的过期值删除有两种方式:
- 在读取时会显式删除(比如ValueState.value()方法),这是默认的方式
- 如果state backend支持的话可以在后台周期性的GC掉。
PS:默认情况会导致state中的entry存留更长时间,backgroud删除可以更快的回收。并且可以通过disableCleanupInBackgroud()关闭后台清理只保留显式删除。
- 截至到1.11版本,heap state backend依赖增量清理,RocksDB backend采用压缩过滤器进行后台清理。
- 另外还可以在对state进行快照的时候进行清理工作,使用cleanupFullSnapShot()打开就可以。但是如果采用RocksDB的增量checkpoint时此配置无效,因为增量checkpoint每次都是局部快照。
- 清理工作也可以是增量的,在每次state access时清理部分过期数据,另外还可以设置设否在每次record process时触发cleanup操作。

cleanupcrementally第一个参数的意思是每次state access触发清理操作时老化的entry数量。第二个参数表示是否开启per-record触发清理。如果不使用cleanupIncrementally()指定,默认情况下每次清理5个并且不开启per-record cleanup。
很不幸,如果没有state access行为或者没有record,那么过期state不会被清理。增量cleanup会增加处理延迟。目前增量清理只适用于heap state backend
- state在运行时可以设置为queryable的,在job运行时我们就可以查询state的内容。https://nightlies.apache.org/flink/flink-docs-release-1.11/dev/stream/state/queryable_state.html
- 如果使用了RocksDB backend那么可以指定cleanupInRocksdbCompactFilter.
- 各种state Backend的区别
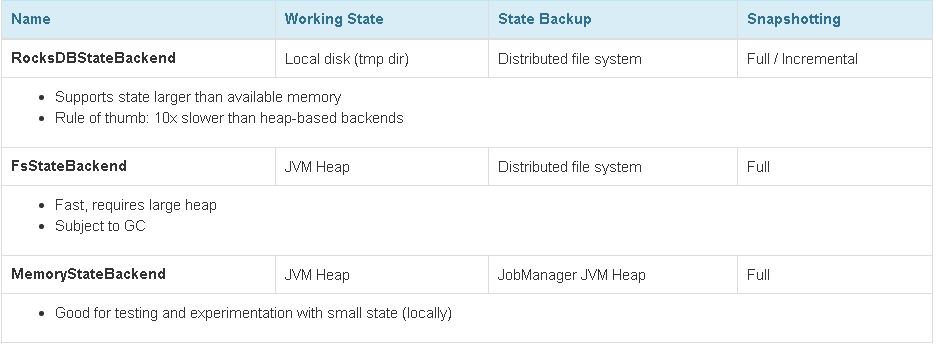
- RocksDBStateBackend每次都需要从磁盘序列化和反序列化,总体相较于其他两种比较昂贵,但是支持增量的checkpoint
- 使用RocksDBstateBackend时尽量使用ListState和MapState,ListState不需要序列化,MapState可以很快的access和update
- 利用ProcessFunction的OnTimer定期删除或者设置state的TTL可以避免state过度膨胀
- checkpint由flink自动触发,checkpoint可以是增量的,并且持久化被优化地很快。
- 正常情况下,保存起来的checkpoint用户是不能操作的,并且flink只保存n个最新的checkpoint点(n可配)。一旦job被cancel, flink会删除这个job所有已保存的checkpoint,但我们可以通过enableExternalizedCheckpoint保存flink生成的checkpoint并手动利用保存下来的checkpoint恢复job。
- flink可提供给用户随时持久化state的手段,即savepoint。Savepoint是有状态作业重新部署、升级、扩缩容的利器,并且flink对它进行了优化。savepoint实际上就是由用户触发的对齐的checkpoint。
- checkpoint和savepoint的设计目标不一样:checkpoint被设计成尽量轻量,尽量快,用于在job故障时进行自动恢复(通常恢复前后job的代码不会有任何改变),并且在job执行完成或cancel以后会自动删除checkpoint;savepoint被设计成面向用户,用于有计划地、手动地备份和恢复,能提供对整个job生成一致性快照的能力,并且支持rescale。savepoint的设计目标更多地倾向于可移植性、对作业修改的兼容性,代价是产生savepoint和恢复的代价会比checkpoint昂贵一点。
- 关于savepoint的若干问题:https://nightlies.apache.org/flink/flink-docs-release-1.11/ops/state/savepoints.html
- flink提供了三种Checkpoint模式即:Default、At-Least-Once、Exactly-once。
- Default情况下,checkpoint关闭,不能保证事件对state的影响不丢失。
- flink提供的exactly-once指保证每一个事件对state只产生一次影响,但是不保证同一个input事件只产出一个output事件。如果需要端到端的exactly-once就需要事件源可重放(注意不是source算子,当然你可以自定义带重放功能的source)且sink支持transaction或者幂等。(flink做checkpoint时会保存当前operator的state和这个checkpoint时间点之后上游发过来的事件。同时为了性能,采用了copy-on-write机制,因此处理流不会被卡住,当前算子继续处理barrier后面的事件并且照常发送给下游,上游过来的barrier之后的事件对state的影响会施加在一个新的state副本上。当checkpoint持久化完成之后,老的state会被GC掉)。流在做checkpoint的时候不会卡住,就意味着无法避免事件被重复计算。
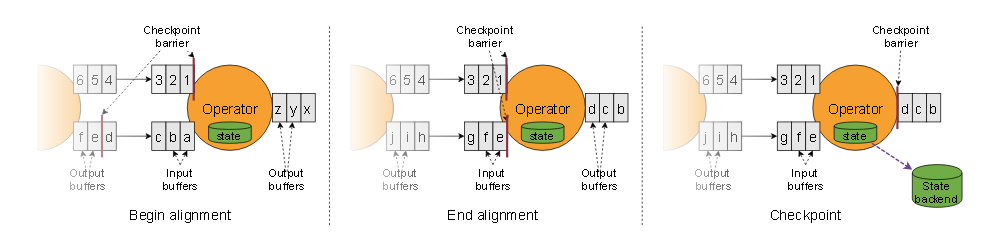
- Exactly-Once做checkpoint时会进行barrier alignment,即屏障对齐:只有在checkpoint之前的所有上游事件已处理并且已经持久化以后才会往下游发送barrier,副作用会导致这些特殊算子有一定的处理延迟。对于普通的one-to-one算子来说,两种模式没什么区别,且处理延迟差不多;对于需要network shuffle的算子(multi-input是一种特例)则可能会造成一定的延迟。
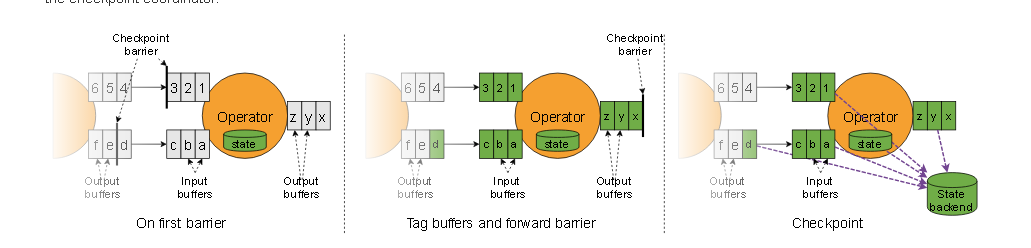
- 下面这张图就是带barrier alignment的checkpoint过程。Operator之前是两个并行的流,到了Operator这里,并行度变成1,发生shuffle,因此两个并行流需要对齐。这里就不介绍multi-input的算子了,图画出来其实是一样的。
- 从Flink1.11以后checkpoint就可以不带对齐地checkpoint。下面这张图就是不带barrier alignment的checkpoint过程。我们可以看到是没有barrier对齐的过程的,步骤也比带对齐的checkpoint复杂,步骤如下:
- 只要operator的其中一个input buffer中出现了barrier,立刻开始checkpoint
- 先把barrier立刻放到output buffer队列的队尾,同时进行第三步
- 异步保存被跳过的record并生成state的snapshot.
注意这里有一个特别需要注意的地方,就是下面图里的record d。opreator要持续追踪自己的input buffer并一直异步保存过来的record直到另一个并行流同一个id的barrier到达。这应该是为什么需要先进行步骤b的原因,出于性能考虑,让下游算子尽快进入checkpoint。但是带来的副作用就是I/O压力变大了,因为要额外保存records。
我们可以看到在下面的图中当checkpoint n的其中一个barrier到达时,Operator并不会等待checkpoint N的其他barrier一起到来,它会继续处理后续事件。这种做法会导致有一些对state产生过影响的事件被存储。恢复时这些事件会再次产生一次影响。在反压比较严重数据堆积的情况下,才推荐使用未对齐的checkpoint,如果仍然使用对齐的checkpoint会造成checkpoint过程持续时间显著变长。
- At-Least-Once模式下(即开启了checkpoint),通过stream重放,保证事件至少产生一次影响。但该模式其实就是没有屏障对齐的checkpoint。Exactly-once就是带barrier aglinment的checkpoint。
- 注意barrier对齐只在那些multi-input的或者上游算子发生了repartitioning/shuffle的算子上才会发生。因此即便在at-least-once模式下,那些one-to-one算子也能提供exactly-once语义。
- 使用CheckpointListener接口可以在整个job完成一次checkpoint时让我们可以感知到,从而进一步处理。
- Flink支持三种时间概念:Processing time, Event time, Ingestion time。
- 使用Processing Time时处理延迟很低,但会面临以下限制:1.不能正确处理历史数据 2. 不能处理事件乱序 3.窗口等聚合操作的结果是非确定的
- Event time保证每次处理历史数据时得到一致的值。但相应的由于事件乱序存在边界难以确定导致必须延迟处理。延迟的越久数据的完备性就越好,但完备性的问题可以通过另外的办法额外保证,比如保存迟到数据(sideoutput),并基于这些迟到数据对已经得到的处理结果进行修正。总的来说 Latency和Completeness是一对必须权衡的矛盾。
- watermark是一个周期性最高水位线,是一个更新周期内当前处理流中最新的那个事件的时间(通过Extractor从事件上获取)。watemark经常与一个迟到时间t联系在一起,假设当前的watermark是T,那么事件时间小于T-t的事件就认为是迟到事件。算子上有一个event time时间其实就是上游传下来的watermark, 并且event time只能递增不能回退,正如时间无法倒流那样。watermark emission周期通过setAutoWatermarkInterval(long milliseconds)可调。
- 但是如果两个并行流进行union或者key()或者partition()操作时,取watermark较小的那个流的watermark作为算子的event time。
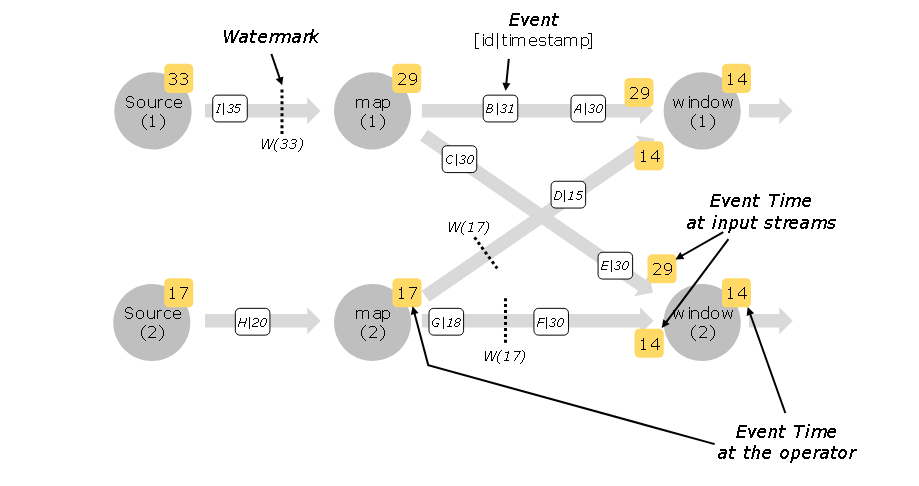
- 一个算子(task)可能会有多个并行流(subtask),每个并行流都有自己的分区。如果其中一个分区的再也没有数据了,因为水印推进是取watermark比较小的那个,所以整个task的水印再也不会推进。这个问题可以通过设置流的idle时间来解决WatermarkStrategy.withIdleness(),当其中一条流的idle时间超过设置的值的时候,这条流就不再影响watermark的推进。(尤其是kafka consumer)
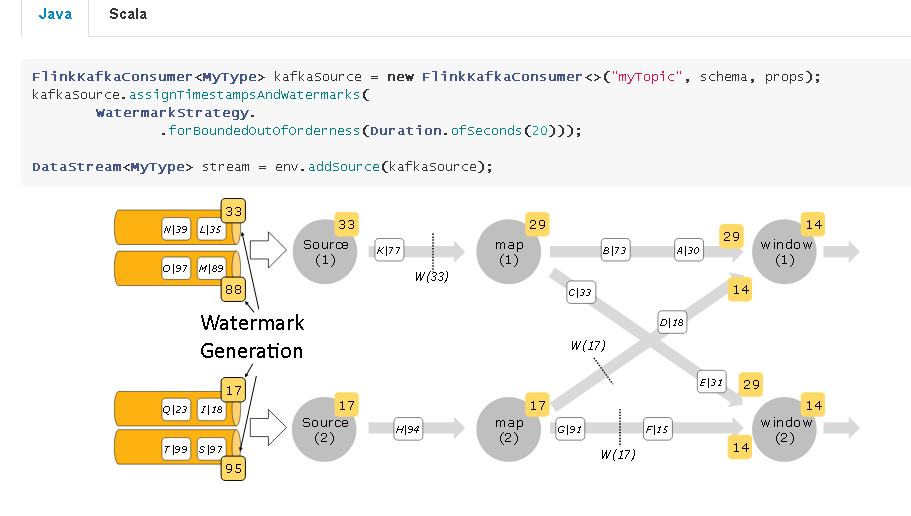
- Watermark生成一般有两种风格:periodic和punctuated。periodic周期性生成可以基于event time也可以基于processing time。punctuated基于事件流中的特殊事件触发水印emit。https://nightlies.apache.org/flink/flink-docs-release-1.11/dev/event_timestamps_watermarks.html
- 特别的,flink的kafka connector可以给一个topic生成per-partiton的watermark,从而保证每个partition的事件有序。
- 一般情况下,watermark只起到推进流的event time的作用,仅此而已。除非你自己拿watermark干别的事。
- 关于窗口有一些需要注意的地方:
- 滑动窗口每滑动一次就会产生一个window object,并且每个window object都会获得所辖事件的一份拷贝。比如一个步长为15min,长度为24h的滑动窗口,每一个事件会被拷贝到 24*(1hour/15min)=96个窗口
- 窗口边界总会取整,比如5min的窗口,边界是固定的,00:05 - 00:10 - 00:15。且窗口聚合出的事件时间是窗口的结束时间
- 窗口挨着窗口时必须保证后一个窗口的长度是前一个窗口的整数倍。
- flink总是事件驱动的,窗口也不例外,在事件时间下,事件迟到也到导致窗口merge延迟。
- window function支持两种状态,一种是基于整个key的keyedState,是跨window的。另一种是专属某一个已触发的窗口的windowState。

- event time窗口的触发是根据watermark是否超过窗口的结束时间来确定的,如果设置了allowLateness,则只有在watermark > window_end + allowLateness才会窗口触发。如果窗口设置了allowLateness,那么每一条迟到数据就会导致EventTimeTrigger的重新触发,也就是说会产生同一个窗口的多个重复输出,需要我们自己去处理。另一种允许迟到数据的方式是使用BoundedOutOfOrdernessTimestampExactor,这种方法通过推迟水印的emit来允许延迟数据,因此不会产生多余的输出,但这种方法延迟必须是固定的且只产生一次窗口输出,完备性无法保证。
- 一旦你觉得使用flink预定义的算子让你觉得很别扭,那么你应该去看看ProcessFunction。你想要的ProcessFunction几乎都能给你,如果不能那就看看KeyedProcessFunction,如果还是不行请你再看看CoProcessFunction。ProcessFunction提供了对event,state,timer的所有access入口。有一点注意timer是checkpoint的一部分,如果timer过多会影响checkpoint的效率。
- —backpress选项——-debug job性能神器
- JobManager由三部分组成:
- ResourceManager: 分配和管理slot
- Dispatcher: 提供一个Rest接口,可以用来提交job和创建job的Master,并且也提供了关于job执行信息的查询接口
- JobMaster: 管理JobGraph的执行,每个job都有自己的JobMaster
- Taskmanger用来管理Task slot,slot只是用来隔离flink的 managed memory。Slot分配以job为单位,一个job的slot不与其他job共享。但同一个job里不同task的subtask可以共享一个slot,因此一个slot可能包含job的整个pipeline所需的内存。
- Flink部署有三种模式:
- Flink session cluster: a persistent cluster service any session connecting it, and do anything whate they want
- Flink job cluster: service for job, die with job’s termination
- Flink application cluster: service for a paricular application within a single jar( may have one or more jobs)
Job cluster和application cluster的区别在于:job cluster模式下job的main方法是在客户端执行的,生成了execution grahp并把相关的依赖打包成二进制提交给cluster直接执行;而application cluster模式下直接提交jar包给cluster并且指定Jar包的main方法入口,main方法是在cluster集群上的,后续生成job graph都是在cluster上执行。
- 算子与算子之间的数据传递不是一个接一个的,为了提高吞吐量,一般都会缓存一部分以后批量发给下游。但是缓存数据必然导致处理延迟,我们可以通过env.setBufferTimeout(timeoutMillis)设置buffer的超时时间来控制延迟的大小。当然缓存大小也是可以配置的。
- 在keyBy时尽量使用KeySelector函数,其他方式可能会产生额外的开销
- 对于一些长期运行的服务,通常这些服务也会迭代,可能会修改内部的数据格式,这些服务就必须具有可演化性,保证能够adapt新的改动。https://nightlies.apache.org/flink/flink-docs-release-1.11/dev/stream/state/schema_evolution.html
- Pojo格式的state是支持可演化的(新增或删除字段),在checkpoint restore过程中会自动读取老的state映射成改动后的state。这个不需要任何配置,只要保证state是Pojo的就可以(版本必须是1.8.0以后)。除此之外Avro类型也支持可演化性。
- 除了flink内部就支持的Pojo,Avro可演化,我们也可以自定义具备可演化性的serializer。为了实现可演化的serializer除了需要我们实现TypeSerializerSnapshot来序列化并保存checkpoint时state使用的serializer。当数据格式发生了演化,即flink检测到同一个state的TypeSerializer发生了变化,那么就会触发migration:将state先按已保存的老serializer反序列化,然后调用新的serializer重新序列化成新的格式的数据。这个migration的迁移方式需要我们自己定义,方法是重写TypeSerializerSnapshot.resolveSchemaCompatibility(TypeSerializer<T> newSerializer)方法。
- 在某些情况下,通过将 MapFunction 扩展到非常高的并行度来提高吞吐量也是可能的,但通常会带来非常高的资源成本:拥有更多的并行 MapFunction 实例意味着更多的任务、线程、Flink 内部网络连接、网络连接 到数据库、缓冲区和一般内部簿记开销。要平衡平行度提高带来的优点和缺点。
- flink原生支持异步I/O算子,也就是RichAsyncFunction。但需要注意在 Runtime的时候,用户自定义的RichAsyncFunction不会每个上游Recod到来都是并发调用的。对于上游到来的每个事件,按照事件到来的顺序调用RichAsyncFunction,因此在RichAsyncFunction中一定不能出现可能会导致RichAsyncFunction被阻塞的操作,阻塞操作尽量托管到其它的线程池中,比如利用CompletableFuture。
- flink on yarn:yarn是hadoop resourceManager.
- 在任意RichFunction中都可以自定义算子的metric指标,预定的有Counter, gauge, histogram, meter,也可以自定义四种metric的实现
 、
、
- metric是有scope的:user scope和system scope,system scope指明了某个具体的指标是受哪个jobmanager管理的哪个job运行在哪个taskmanger上的哪个算子的哪个subtask。user scope则指定是哪个metric。例如
. . . . - 通过在flink-conf.yaml中配置metrics.reporter可以指定将某个scope范围内的metric暴露给外部系统。
- 除了作业中的自定义metric,我们也可以采集flink内部指标,例如jobmanager/taskmanager的CPU,内存,线程,垃圾回收,网络,集群,可用性,checkpoint,IO等等。除此之外我们还可以采集jobmanager和taskmanager所在机器的系统指标(默认关闭,通过metrics.system-resource开启)。
- 如果你在算子中打开了任何没有超时的外部链接,你应该使用RichFunction,并且重写close()方法,并在close方法中关闭这些链接

若有收获,就点个赞吧
0 人点赞
