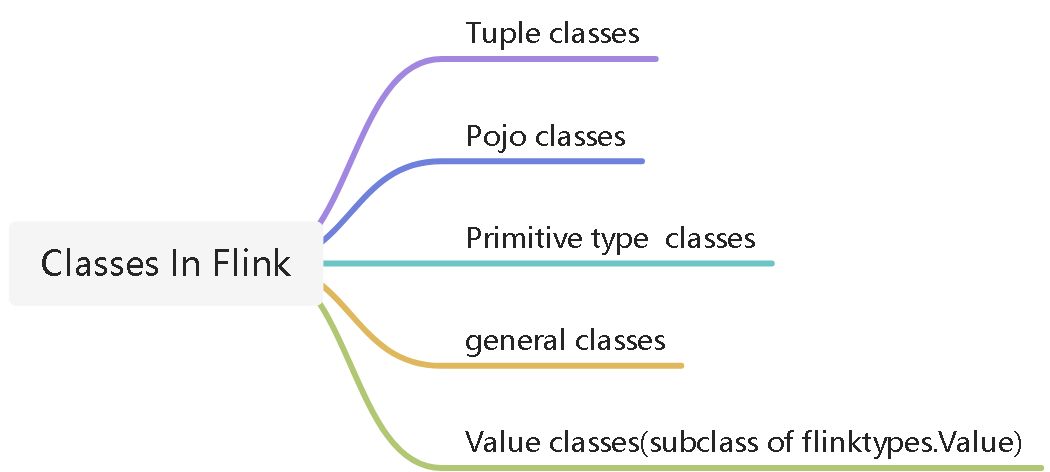
注意这篇文档里提到的type的意思是 类的类型。flink按照类的类型将class分为几种type.
flink 会尽可能推断类型信息,flink 对类型信息了解的越多,序列化就越高效,并且flink内部的内存布局也就越好,更节约内存空间。并且将用户从序列化框架中解放出来。
Tuple类型
多字段复合类型,flink提供了tuple1-tuple25, tuple内部可叠加嵌套tuple
Pojo
flink pojo类定义
- class必须是public的
- 必须包含一个无参的构造函数
- 所有的成员变量都必须是public或者包含getter和setter方法。
- 成员变量的类型必须可以被已注册的serializer(默认的或者自定义的或者flink生成的)序列化
flink类型信息系统使用PojoTypeInfo表示一个pojo类的类型信息,使用专用的PojoSerializer类进行序列化。但有一个例外情况,如果Pojo类是由avro生成,那么该pojo类会被表示为AvroTypeInfo并使用AvroSerializer序列化。
Flink会分析Pojo类型的结构,也就是说也会分析Pojo的成员变量的类型。相比于普通类型,Flink能更高效地处理Pojos。
Primitive types
flink支持所有java原生类型的classes,比如Integer,String, Double
General class types 一般类类型
flink支持绝大多数java类型,包含不可序列化字段的class不允许作为DataStream的类型参数。
所有不能被识别为pojo的类型一律按照 一般类类型处理。
Value classes
Value类型的类 所有序列化和反序列化都必须自己来实现。独立于flink序列化框架,通过重写write和read来实现序列化。只有当flink序列化框架无法高效地序列化时才需要完全自定义。
举个例子,假如有一个用array存储稀疏向量的data type。稀疏向量里面绝对部分元素都是重复的0,我们可以在序列化时对非0元素使用特定的编码,从而避免序列化array里面那些占大多数的无用的0元素。
flink内部提供了一些Vaule的实现类,ByteValue、ShortValue、IntValue、LongValue、FloatValue、DoubleValue、StringValue、CharValue、BooleanValue,相比如primitive type,这些value class可以反复重用,值是可变的。从而减轻垃圾收集器的压力。
但是这种需要使用对象池进行管理,处理回收和再分配,避免出现并发问题。
类型擦除和类型推断
java代码编译成字节码后,会丢掉大部分泛型类型信息(类型擦除)。也就是说在运行时,一个object是不知道它的泛型类型的,举个例子,DataStream
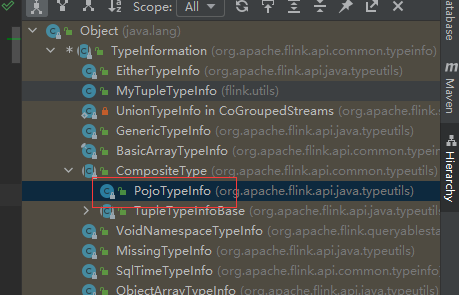
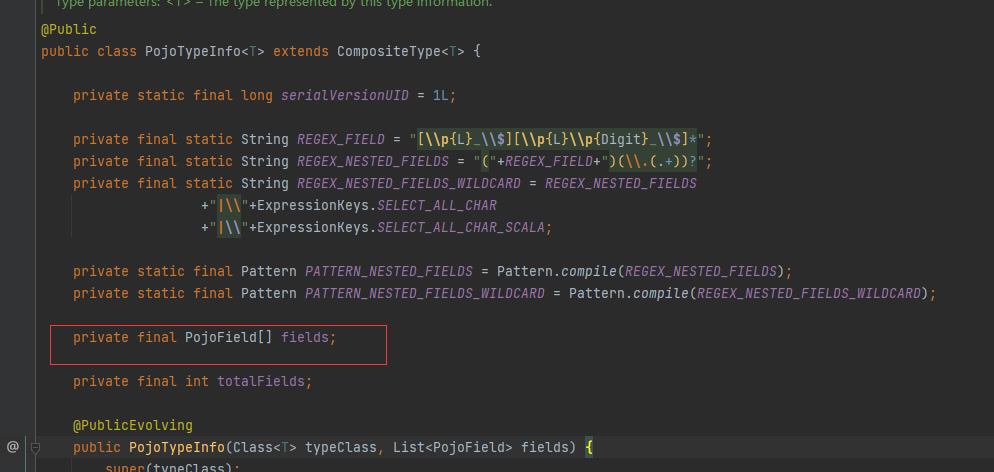
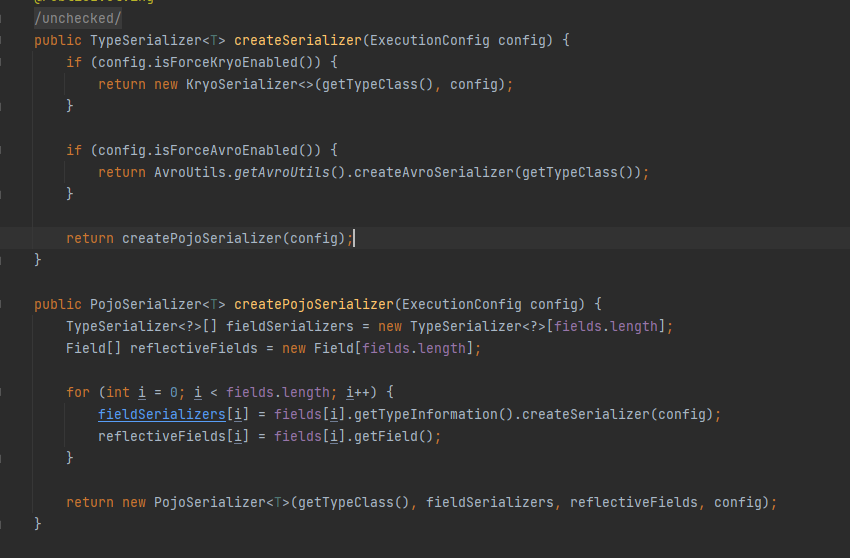
Flink必须在运行之前就知道类型信息,从而决定类型的对象如何被序列化。flink会尽力重构类型信息并将类型信息存储在operator里面,从而可以通过DataStream.getType直接获取类型信息,该方法返回TypeInformation的一个实例。TypeInformation是flink内部用来表示type的方式,比如说一个operator的返回值是一个Pojo type的类,那个这个operator内部会存储一个PojoTypeInfo(这是TypeInformation的一个实现),从下面的图可以看到PojoTypeInfo存储了类内部所有成员变量的具体信息。并且给出了自定义的PojoSerializer。
Flink虽然会尽力重构类型信息,比如根据输入推断。但是类型推断有时候有一些限制,需要我们的协助。比如env.fromCollection(),可以通过传入一个描述类型信息的TypeInfomation作为参数。泛型function例如MapFunction
我们也可以通过实现ResultTypeQueryable接口来显式指定operator 的返回值类型。而operator 的输入类型通常可以由上游算子的返回值类型推断得到
most freqent issue
大多数情况下,用户不需要与flink类型信息系统打交道,flink会自己推断。
但是以下几种情况,需要用户的协助:
实际类型是返回值类型的子类型。
比如用户自定义了一个算子MapFunction<In,OutType>,但是在实现map函数的时候实际返回类型是OutType的子类型。这时候就需要明确地告诉flink这个实际子类型的信息,比如通过register来告知flink这个类型的信息
遇到无法被kryo序列化的通用类类型(general class type)
例如一些google guava集合类kryon不能很好的处理,这个时候我们就要自己定义该类型的默认kryo序列化器,StreamExecutionEnvironment.getConfig().addDefaultKryoSerializer(clazz, serializer)

若有收获,就点个赞吧
0 人点赞
