以key-value的形式存储数据,使用hash函数对真实的key或者关键字计算出一个hash_key,如:
hash_key = hash(x)
hash_key其实就是一个数字,通过将hash_key与数组下标建立映射关系,这样就可以使用数组的下标随机访问特性,因此,散列表是对数组的扩充。
技术点
散列函数
散列函数是散列表的关键:散列函数越复杂,对应散列表的性能越差;散列函数要确保尽可能保证值的均匀分布,减少散列冲突
装载因子
装载因子越大,说明散列表中的元素越多,那么相应的,散列冲突的概率就越大,相反的,装载因子越小,说明散列表中的数据越分散,空间利用率不高。对于一个动态的散列表,如Golang的map,可以在装载因子达到一定的阈值(过高或过低)时,启动扩容(增量或收缩),以提升散列表的性能。
散列冲突
散列函数无法根治散列冲突的情况,那么,可以利用开放寻址法或链表法解决遇到散列冲突时,数据的存放问题
使用场景
对10万条Url访问日志,按访问次数排序
可以将10万条访问日志存入散列表,其中key为URL,value初始值为0。 当第一条URL存入散列表,再有相同的URL存入会产生散列冲突。此时,再比较key是否相同。如果key相同,则是同一个URL,将相应的value++;如果key不相同,则存入链表下一个位置。 可以在外部将最大值K给记录下来。插入完成以后,就可以取得当前URL的出现次数的范围即0-K。 根据K的大小选取相应的算法。如果K值不大,可以采用桶排序。如果K值很大,可采用快排。 为什么使用散列表进行存储: 散列表存储完成以后,已经对URL完成了去重操作,同时拿到了最大次数K,根据K选择合适的排序算法。 时间复杂度分析: 10万条URL存入散列表,时间复杂度为O(n)。 桶排序,时间复杂度为O(n)。 快排,时间复杂度为O(nlogn)。
散列表配合链表使用
LRU
散列表中key为哈希后的时间戳:
key = hash(timestamp)
value为对应时间戳的缓存数据,相同key的使用链表记录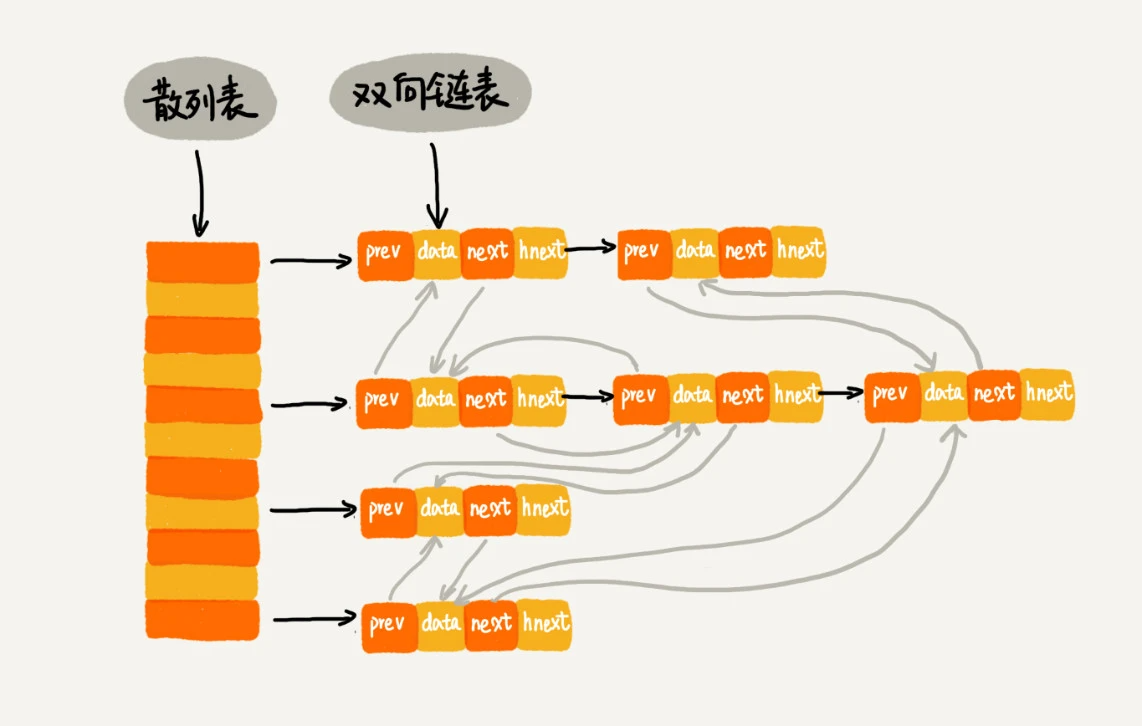

若有收获,就点个赞吧
0 人点赞
