堆 Heap
堆是一种特殊的树,需要满足如下两点:
- 是一个完全二叉树
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
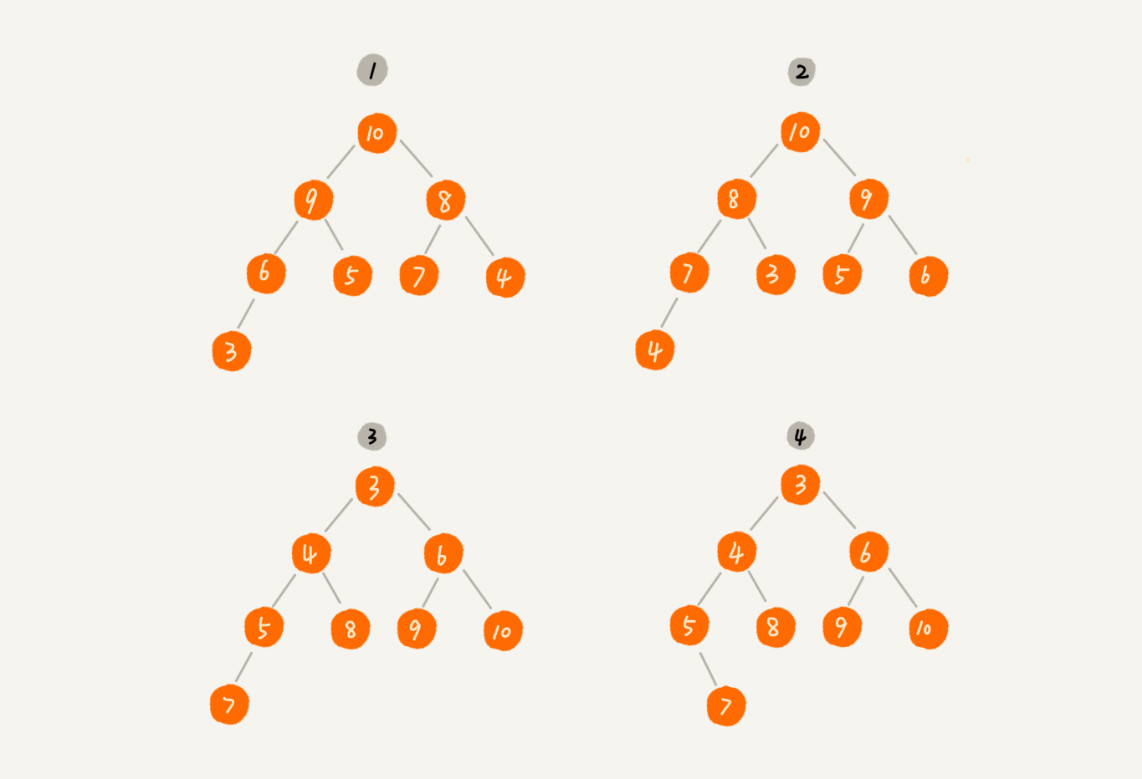
上图中1和2为大顶堆,3和4为小顶堆
- 使用数组存储堆元素
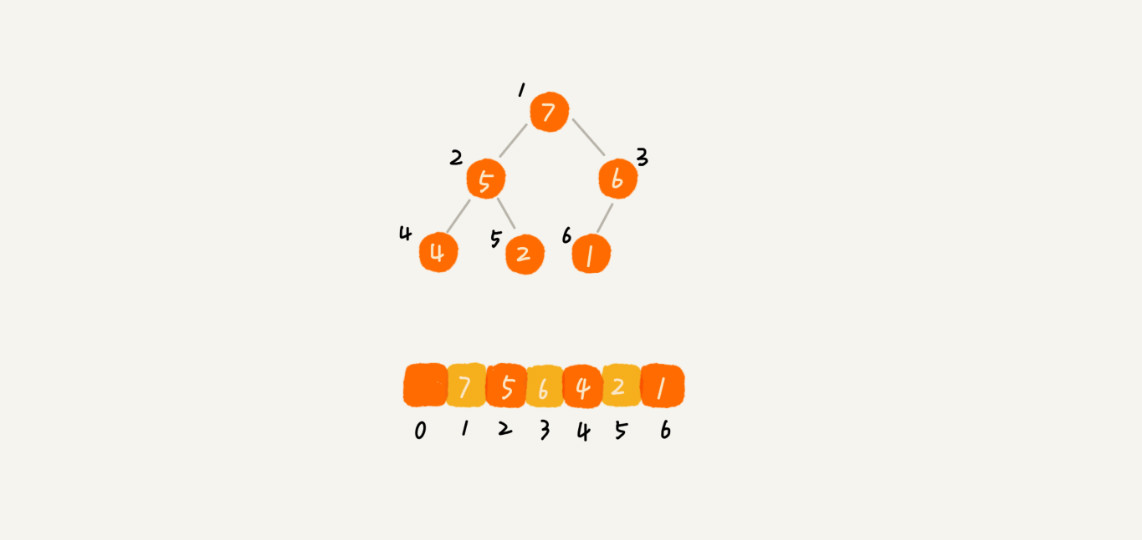
可以看出,数组中下标为 的元素,其左子节点为下标为
的元素,其左子节点为下标为 的节点,右子节点就是下标为
的节点,右子节点就是下标为 的节点,父节点就是下标为
的节点,父节点就是下标为 的节点。
的节点。
堆支持的操作
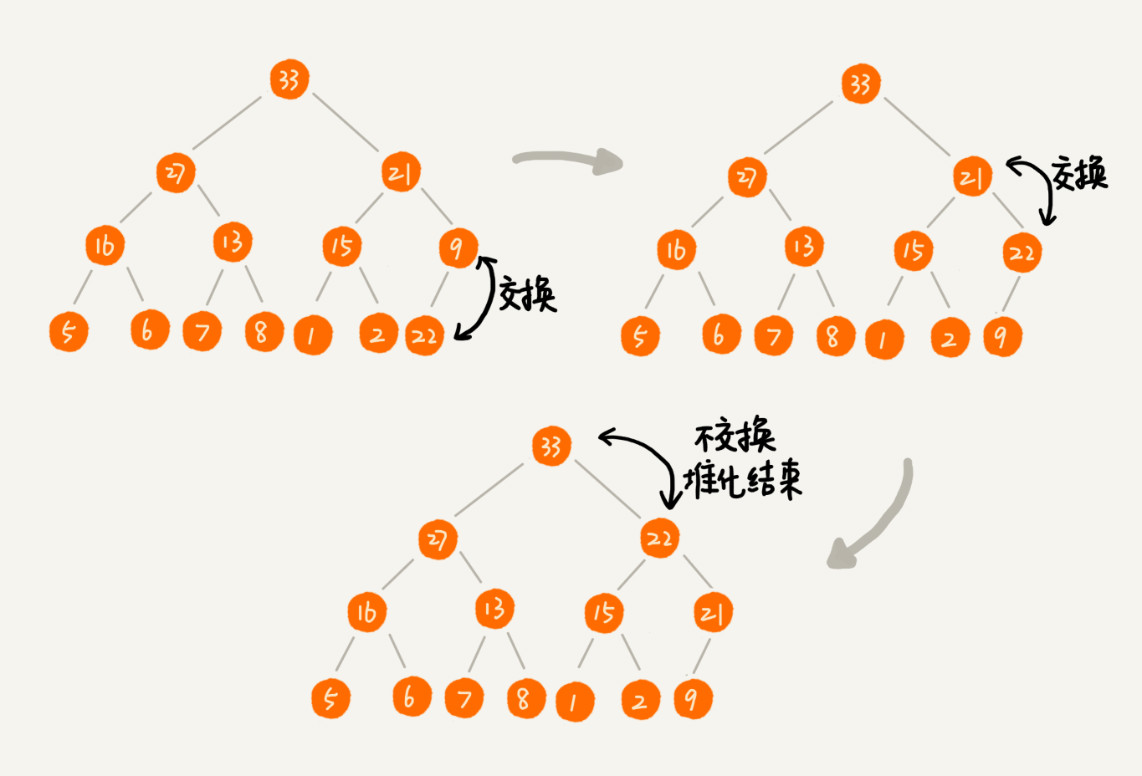
1. 插入元素
时间复杂度为
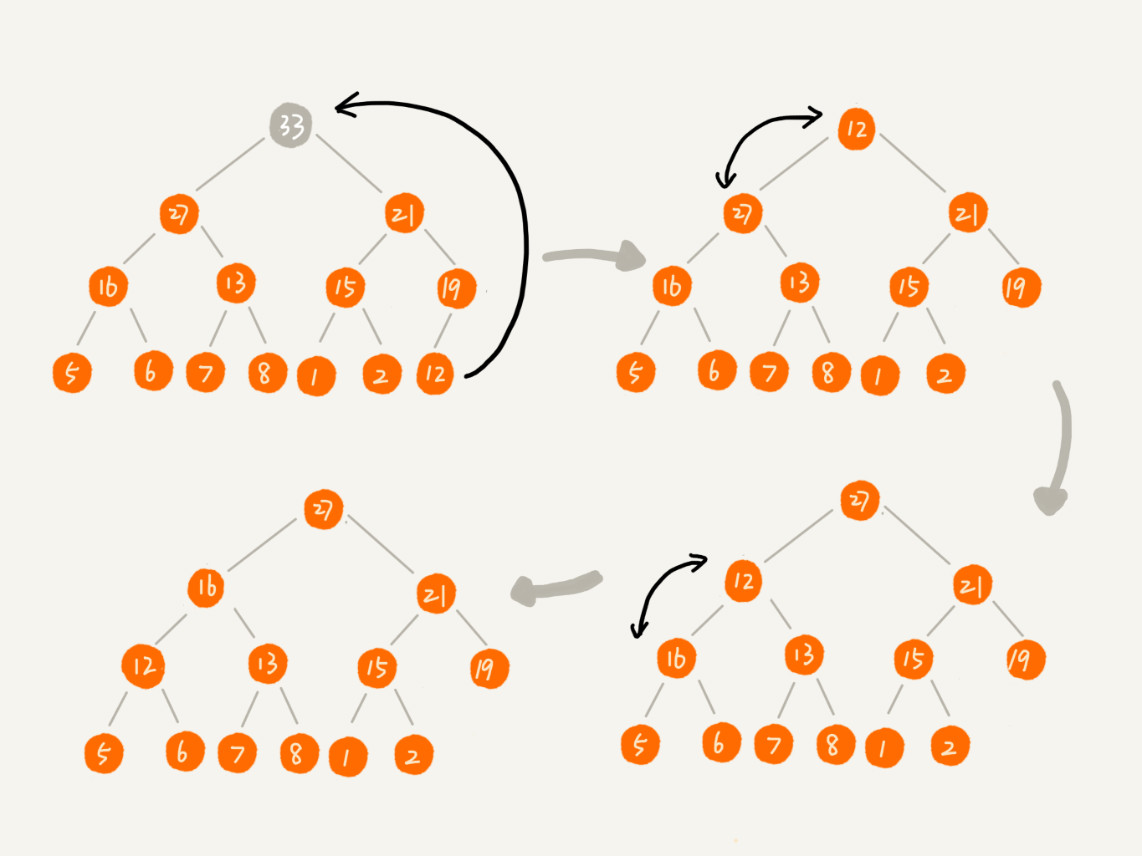
2. 删除堆顶元素
将堆中最后一个元素与堆顶元素替换
然后逐层比较,直到原始堆尾元素被移动到其满足完全二叉树条件的位置
这是从上往下的堆化方法
时间复杂度为
3. 借助堆进行堆排序
堆排序的过程可以总结为两大步骤:建堆和排序
- 建堆
这里需要注意,堆数组从下标为1开始
func buildHeap(nums []int, n int) {for i := n / 2; i > 0; i-- {heapify(nums, n, i)}}func heapify(nums []int, n, i int) {for {maxPos := iif i*2 <= n && nums[i] > nums[i*2] {maxPos = i * 2}if i*2+1 <= n && nums[maxPos] > nums[i*2+1] {maxPos = i*2 + 1}if maxPos == i {break}nums[i], nums[maxPos] = nums[maxPos], nums[i]i = maxPos}}
- 排序
基本思路是,将堆顶元素与下标为n的元素位置互换,然后将数组中前n-1个元素重新建堆,如此往复,那么就将元素按从小到大的顺序进行了排列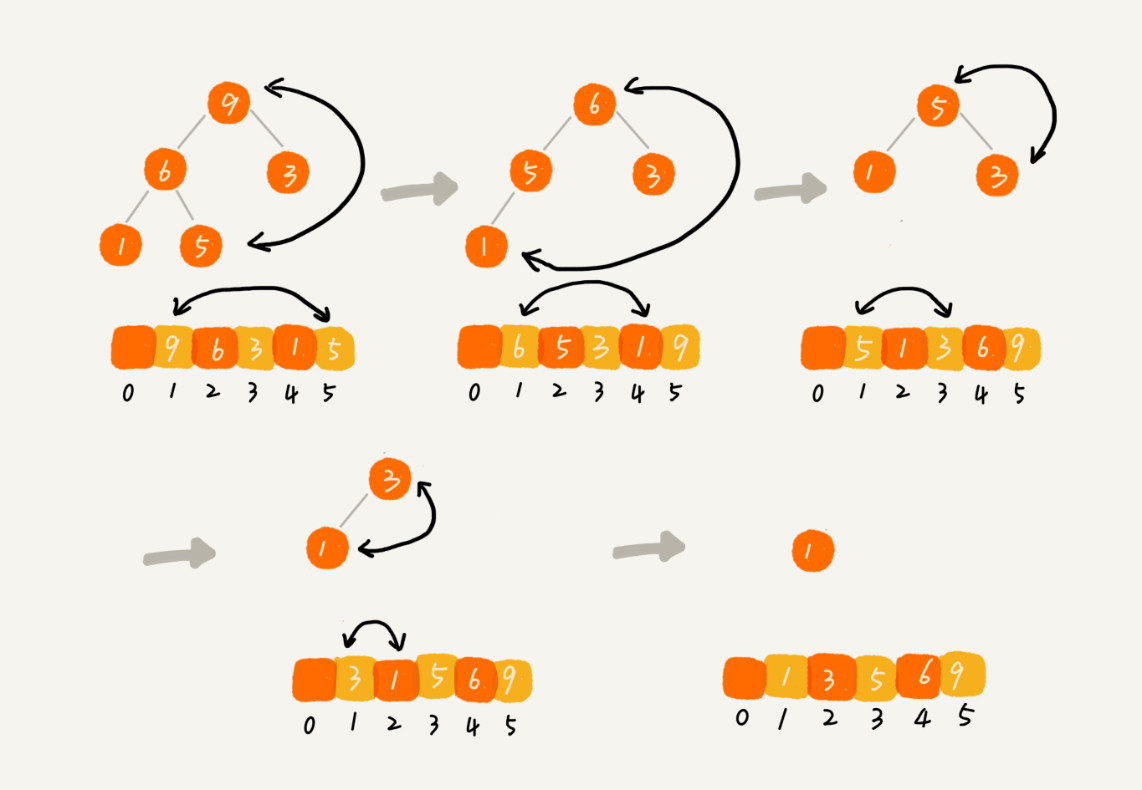
func sort(nums []int) {
n := len(nums)
buildHeap(nums)
k := n
for k>1{
nums[1], nums[k] = nums[k], nums[1]
k--
heapify(nums,k,1)
}
}
堆的应用场景
优先级队列
- 合并有序小文件
例如将100个小文件合并成一个大文件,每个小文件中的字符串有序,合并后的大文件中字符串也需要有序
可以从每个文件取一个字符串,组合成小顶堆,堆顶元素放到大文件中,然后定位该堆顶元素的源文件,再从该文件中取下一个字符串放入到小顶堆中重新构造小顶堆,再取堆顶元素放入到大文件中,如此往复
- 高性能定时器
多个定时任务,按照执行时间点构造成小顶堆,定时器只需要每次拿堆顶的任务,计算时间间隔,到时候执行堆顶任务即可,而不用每隔一定时间全量扫描任务列表。
利用堆求Top K
维护一个大小为K的小顶堆,遍历数组,如果元素比小顶堆中堆顶元素大,则删除当前堆顶元素,并将该元素插入到小顶堆中,如此遍历完数组,则小顶堆中的元素即为前K大数据。
利用堆求中位数
这个场景可以转化为求n%位数
将原始数据划分为一个大顶堆和一个小顶堆,大顶堆中存放数组排序后的前n%个数,小顶堆中存放剩余的数
当插入一个新元素时,新元素的值与两个堆的堆顶元素相比,大于等于大顶堆的堆顶元素的,则将新元素插入到小顶堆中,反之插入到大顶堆中
数据插入后,重新计算两个堆中的元素数量是否满足n%的关系,不满足,则将多余的元素移动到另一个堆中
如此,大顶堆的堆顶元素,始终是n%位数

若有收获,就点个赞吧
0 人点赞
