模式说明
装饰模式实际上也是为了更好的履行组合优于继承的原则,以组合的方式对被装饰类进行二次加工,但装饰模式存在一定的局限性,就是需要经常扩展装饰类新方法或被装饰的方法太多都不适合使用装饰模式。每一个被装饰的方法都需要被透明处理,什么是透明处理?就是 B.decorate(A),A 并不需要知道被 B 装饰。
装饰者模式的优点是避免过多的类继承,将核心类和装饰类有效分离及独立扩展。而缺点则是使得类代码的调试变得困难,甚至提高了理解源码的难度。
应用场景
装饰者模式的类关系可以参考下图 1 所示,重点需要关注的是装饰类与抽象类/接口的关系,一般般是以 1:1 的组合方式,再次强调一次,装饰者模式是对被装饰类的二次加工,如新增功能或删减数据。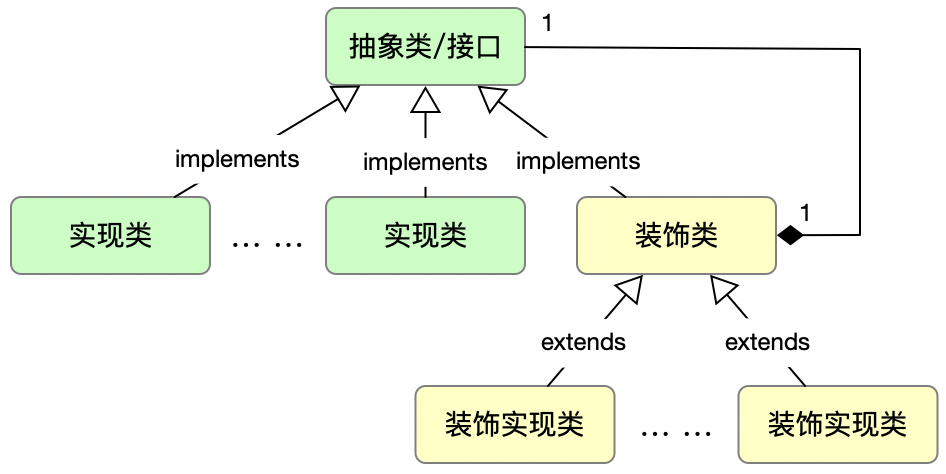
图 1
在 Java 中经典的实现非 IO Stream 类库莫属了,InputStream / OutputStream 都是通过装饰者模式设计并实现,其具体的类架构图,请参考如下图 2 所示。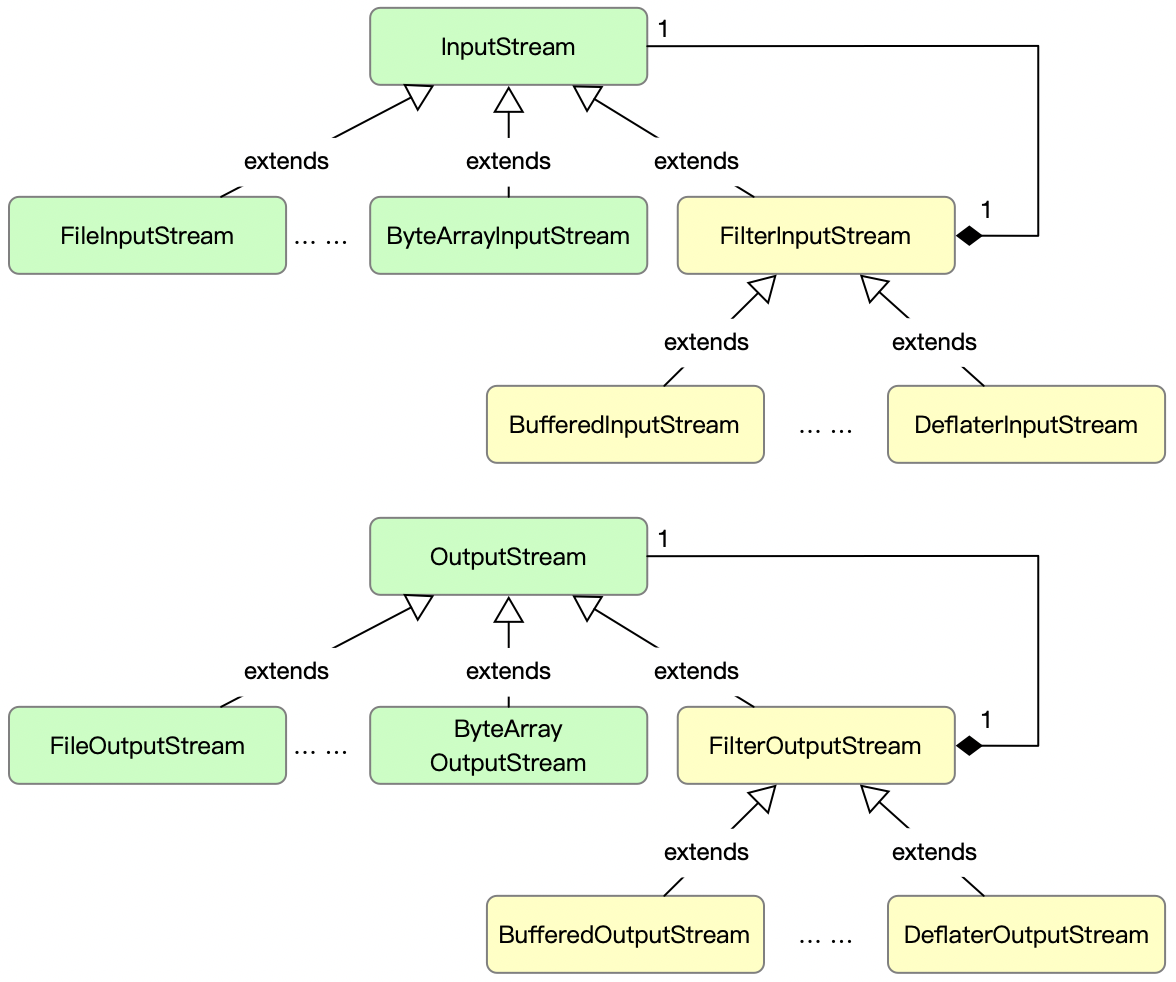
图 2
InputStream / OutputStream 的设计简直就像是复制的一样,值得一提的是都与图 1 的类关系图一致,其实除了 InputStream / OutputStream,还有 Reader / Writer 的也是通过装饰者模式设计实现。
那么我们通过 Java IO 类库的设计来倒推装饰者模式在尝试要解决什么问题,首先,我们先尝试着使用 IO 类库,正常的读取一个文本文件,如下代码所示。
try (InputStream fin = new FileInputStream("~/file.txt");BufferedInputStream bin = new BufferedInputStream(fin)) {// bin.read(...)}
现在,我们将 ~/file.txt 经过压缩后再读取出来,如下代码所示。
try (InputStream fin = new FileInputStream("~/file.txt");
InputStream din = new DeflaterInputStream(fin);
BufferedInputStream bin = new BufferedInputStream(din)) {
// bin.read(...)
}
Java IO 类库使用起来实在太啰嗦了,能否直接点,如直接有一个类,名为 FileDeflaterBufferedInputStream,那么客户端的代码就可以作化简如下了。
try (InputStream in = new FileDeflaterBufferedInputStream("~/file.txt")) {
// in.read(...)
}
别忘了,还有 FileBufferedInputStream,一个带缓存的 File 数据流。
try (InputStream in = new FileBufferedInputStream("~/file.txt")) {
// in.read(...)
}
方便了客户端使用之后,类的关系,应该就如下图 3 所示。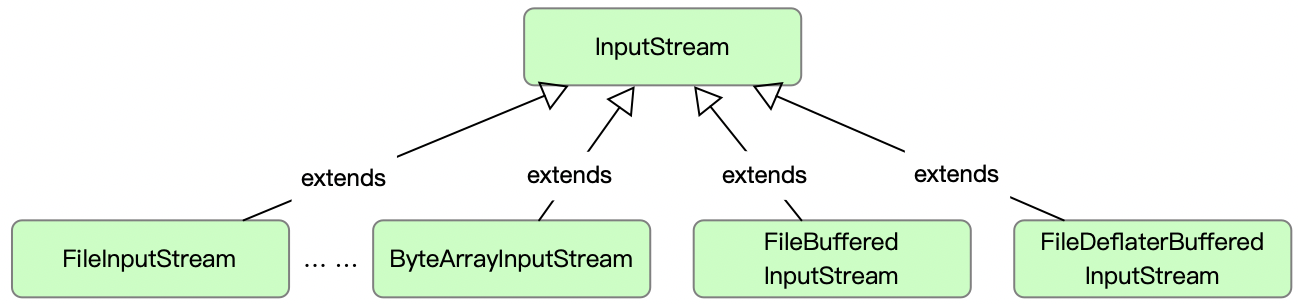
图 3
明显的问题就是,对于扩展,将会使得子类膨胀得非常厉害,也不利于代码的复用,所以装饰者模式就是为了解决因功能扩展而导致的继承类暴增的设计痛点,同时为了增加代码的可复用性。那我们能否既能够使得客户使用方便,又保留装饰者模式设计的优势呢?针对这个问题,我们可以尝试使用静态工厂来满足常用的 IO 流的初始化,代码参考如下。
public class IOUtil {
private IOUtil(){}
public static InputStream newFileBufferedInputStream(String filePath) {
InputStream fin = new FileInputStream(filePath);
return BufferedInputStream bin = new BufferedInputStream(fin);
}
public static InputStream newFileDeflaterBufferedInputStream(String filePath) {
return new DeflaterInputStream(newFileBuffered(filePath));
}
}
try (InputStream in = IOUtil.newFileDeflaterBufferedInputStream("~/file.txt")) {
// in.read(...)
}
try (InputStream in = IOUtil.newFileBufferedInputStream("~/file.txt")) {
// in.read(...)
}
不过即使是静态工厂也看上去不尽人意,所以,装饰者模式对于客户端代码是非常不友好,冗长的装饰使得实现并不优雅,而且增加了追踪调试的难度,因为你很多时候不知道组合引用的具体实现。
代码实现
不清楚大家是否听说过 Http Chunked Data 的不定长报文协议,如果之前不了解,则参考我分享的 HTTP 数据包传输方式#不定长报文体,现在,为了解析出 ChunkedData 中真正的 payload 数据,我们可以通过实现 ChunkedInputStream 对 Chunked 类型的 HTTP 信息体进行处理,代码如下。
import cn.icuter.directhttp.utils.IOUtils;
import java.io.FilterInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
public class ChunkedInputStream extends FilterInputStream {
enum ReadingState {
/** reading chunk-size that indicates the chunk-data size */
SIZE,
/** reading chunk-data */
DATA,
/** found the ending characters of "0\r\n" and read the chunk trailer */
TRAILER,
/** finished reading */
DONE
}
private ReadingState state = ReadingState.SIZE;
private int remainingChunkDataSize;
private volatile boolean closed;
private boolean eos; // end of stream
private byte[] temp = new byte[1];
public ChunkedInputStream(InputStream in) {
super(in);
}
@Override
public int read() throws IOException {
int read = read(temp, 0, 1);
return read <= 0 ? -1 : temp[0] & 0xff;
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
if (closed) {
throw new IOException("Stream closed!");
}
if (eos) {
return -1;
}
if (!prepareChunkDataReading()) {
eos = true;
return -1;
}
int read = in.read(b, off, Math.min(len, remainingChunkDataSize));
if (read > 0) {
remainingChunkDataSize -= read;
} else {
eos = true;
remainingChunkDataSize = 0;
state = ReadingState.DONE;
}
return read;
}
private boolean prepareChunkDataReading() throws IOException {
if (state == ReadingState.DATA && remainingChunkDataSize == 0) {
// the chunk body ending line
readCRLF();
state = ReadingState.SIZE;
}
if (state == ReadingState.SIZE) {
// read chunk size representing the chunk body size
int chunkSize = readChunkSize();
state = chunkSize == 0 ? ReadingState.TRAILER : ReadingState.DATA;
}
if (state == ReadingState.TRAILER) {
state = ReadingState.DONE;
// TODO ignore trailer bytes
}
if (state == ReadingState.DONE) {
// TODO logging
}
// return false if ReadingState is DONE
// return true if ReadingState is NOT DONE
return state != ReadingState.DONE;
}
private int readChunkSize() throws IOException {
byte[] chunkSizeBytes = IOUtils.readLine(in);
if (chunkSizeBytes.length <= 0) {
throw new IllegalStateException("Illegal chunked http response message body !");
}
// read the line of chunk-size, but discard the chunk-extensions
// last-chunk = 1*("0") [ chunk-extension ] CRLF
remainingChunkDataSize = getChunkDataSize(chunkSizeBytes);
return remainingChunkDataSize;
}
private int getChunkDataSize(byte[] chunkSizeBytes) {
for (int i = 0; i < chunkSizeBytes.length; i++) {
if (chunkSizeBytes[i] == ' ' || chunkSizeBytes[i] == ';') {
return Integer.parseInt(
new String(chunkSizeBytes, 0, i, StandardCharsets.ISO_8859_1), 16);
}
}
return Integer.parseInt(new String(chunkSizeBytes, StandardCharsets.UTF_8), 16);
}
private void readCRLF() throws IOException {
int b = in.read();
if (b != '\r') {
throw new IOException("Invalid chunk-data end char \"" + b + "\" !");
}
b = in.read();
if (b != '\n') {
throw new IOException("Invalid chunk-data body end char \"" + b + "\" !");
}
}
@Override
public void close() throws IOException {
in.close();
closed = true;
}
}
上述代码是通过一个 ReadingState 来判断现阶段读取数据的属于哪一个状态,状态的说明请参考下面表格所示。
| ReadingState | 状态 | 说明 |
|---|---|---|
| SIZE | 分片报文大小 | 正在读取单片报文的数据大小 |
| DATA | 分片报文数据 | 正在读取单片报文的数据 |
| TRAILER | 尾部 Header | 这里是被忽略处理了,只是为了说明 HTTP Chunked Data 的协议规范 |
| DONE | 完成 | 所有分片数据都已经被读取 |

若有收获,就点个赞吧
0 人点赞
