一 大端序与小端序
1.1 什么是字节序?
- 字节序,又称端序或尾序(英语中用单词:Endianness 表示),在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。
- 在几乎所有的平台上,多字节对象都被存储为连续的字节序列。例如在 Go 语言中,一个类型为
int的变量x地址为0x100,那么其指针&x的值为0x100。且x的四个字节将被存储在内存的0x100, 0x101, 0x102, 0x103位置。 - 大端序(
Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。 - 小端序(
Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。 - 高字节与低字节: 在编程语言中,字符一般是占16位,8位为一字节,所以有高位字节和低位字节。一个16进制数有两个字节组成,例如:A9。高字节就是指16进制数的前8位(权重高的8位),如上例中的A。低字节就是指16进制数的后8位(权重低的8位),如上例中的9。
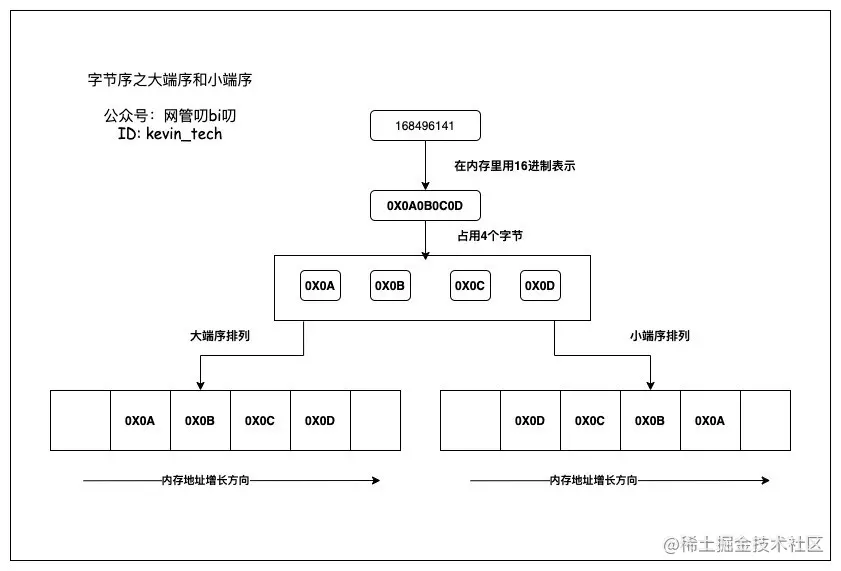
很多人会问,为什么会有字节序,统一用大端序不行吗?答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
1.2 Java中高低位字节的运用
1、不同端模式的处理器进行数据传递时必须要考虑端模式的不同(因主机CPU不同,不同的机器会出现高、低两种字节序问题)。
2、在网络上传输数据时,由于数据传输的两端对应不同的硬件平台,采用的存储字节顺序可能不一致。所以在TCP/IP协议规定了在网络上必须采用网络字节顺序,也就是大端模式。对于char型数据只占一个字节,无所谓大端和小端。而对于非char类型数据,必须在数据发送到网络上之前将其转换成大端模式。接收网络数据时按符合接受主机的环境接收。int value = 515;int big = (value & 0xFF00) >> 8;int little = value & 0xFF;System.out.println(big);System.out.println(little);
十六进制文字0xFF是一个相等的int(255)。
- 0xFF是16进制的表达方式,F是15;十进制为:255,二进制为:1111 1111
-
1.2.1 原码
原码:一个整数,按照绝对值大小转换成的二进制数,称为原码。
比如 00000000 00000000 00000000 00000101 是 5的 原码。
1.2.2 反码
反码:将二进制数按位取反,所得的新二进制数称为原二进制数的反码。
- 取反操作指:原为1,得0;原为0,得1。(1变0;0变1)
- 比如:将00000000 00000000 00000000 00000101每一位取反,得11111111 11111111 11111111 11111010。
反码是相互的,所以也可称:11111111 11111111 11111111 11111010 和 00000000 00000000 00000000 00000101 互为反码。
1.2.3 补码
补码:反码加1称为补码。
- 也就是说,要得到一个数的补码,先得到反码,然后将反码加上1,所得数称为补码。
- 比如:00000000 00000000 00000000 00000101 的反码是:11111111 11111111 11111111 11111010。
那么,补码为:11111111 11111111 11111111 11111010 + 1 = 11111111 11111111 11111111 11111011
1.2.4 解释
首先我们要都知道, &表示按位与,只有两个位同时为1,才能得到1, 0x代表16进制数,0xff表示的数二进制1111 1111 占一个字节.和其进行&操作的数,最低8位,不会发生变化
- 例如:java socket通信中基于长度的成帧方法中,如果发送的信息长度小于65535字节,长度信息的字节
定义为两个字节长度。这时候将两个字节长的长度信息,以Big-Endian的方式写到内存中
out.write((message.length>>8)&0xff);//取高八位写入地址out.write(message.length&0xff);//取低八位写入高地址中
- 例如,有个数字 0x1234,如果只想将低8位写入到内存中 0x1234&0xff,0x1234 表示为二进制 0001001000110100,0xff 表示为二进制 11111111,两个数做与操作,显然将0xff补充到16位,就是高位补0,此时0xff 为 0000000011111111,与操作 1&0 =0 1&1 =1 这样 0x1234只能保留低八位的数 0000000000110100 也就是 0x34。
我们只关心二进制的机器数而不关注十进制的值,那么byte &0xff只是对其最低8位的复制,通常配合逻辑或 ‘’|’’使用,达到字节的拼接,但不保证其十进制真值不变
public static void main(String[] args) {byte b = -127;//10000001int a = b;System.out.println(a);a = b&0xff;System.out.println(a);}//输出结果-127,129
乍一看,b是8位的二进制数,在与上0xff(也就是 11111111),不就是其本身吗,输出在控制台结果为什么是129呢?
- 首先计算机内的存储都是按照补码存储的,-127补码表示为 1000 0001,int a = b;将byte 类型提升为int时候,b的补码提升为 32位,补码的高位补1,也就是1111 1111 1111 1111 1111 1111 1000 0001
- 负数的补码转为原码,符号位不变,其他位取反,在加1,正数的补码,反码都是本身结果是 1000 0000 0000 0000 0000 0000 0111 1111表示为十进制 也是 -127
- 也就是 当 byte -> int 能保证十进制数不变,但是有些时候比如文件流转为byte数组时候,我们不是关心的是十进制数有没有变,而是补码有没有变,这时候需要&上0xff
- 本例子中,将byte转为int 高24位必将补1,此时补码显然发生变化,在与上0xff,将高24重新置0,这样能保证补码的一致性,当然由于符号位发生变化,表示的十进制数就会变了
[1111 1111 1111 1111 1111 1111 1000 0001&0000 0000 0000 0000 0000 0000 1111 1111结果是0000 0000 0000 0000 0000 0000 1000 0001
](https://blog.csdn.net/i6223671/article/details/88924481)
[
](https://blog.csdn.net/xmc281141947/article/details/74740061)

若有收获,就点个赞吧
0 人点赞
