1 加载包
library(dplyr)(starwars <- starwars[, 1:10]) # starwars后 3 列数据位列表,为便于操作,仅选取前 10 列
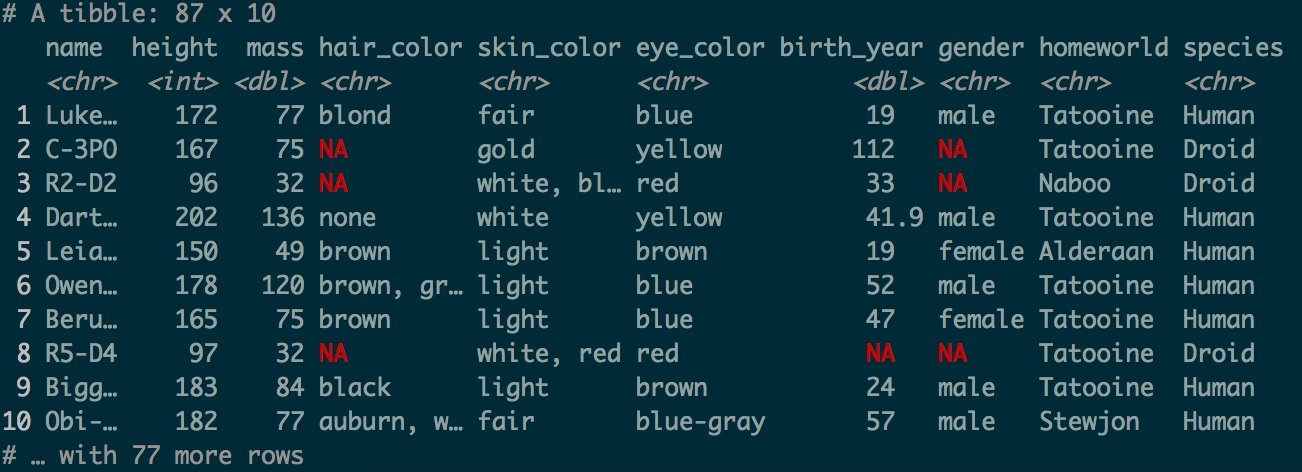
2 缺失值所在行
# 显示缺失值总数starwars %>% is.na() %>% sum()# 显示缺失值占比starwars %>% is.na() %>% mean()# 显示含缺失值的行总数sum(!complete.cases(starwars))# 显示含缺失值的行占比mean(!complete.cases(starwars))# 识别含缺失值的行号which(is.na(starwars))# 筛选出含缺失值的行starwars[!complete.cases(starwars),]# 根据含缺失值的某列筛选对应含缺失值的行starwars %>% filter(is.na(gender))
3 缺失值所在列
3.1 自定义函数
na.test <- function(df){i <- 1:ncol(df)df[i[sapply(i, function(x){sum(is.na(df[x])) > 0})]] %>% colnames()}starwars %>% na.test

3.2 inspect包
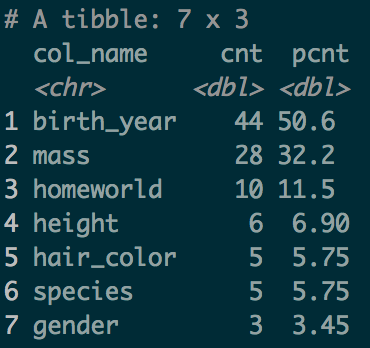
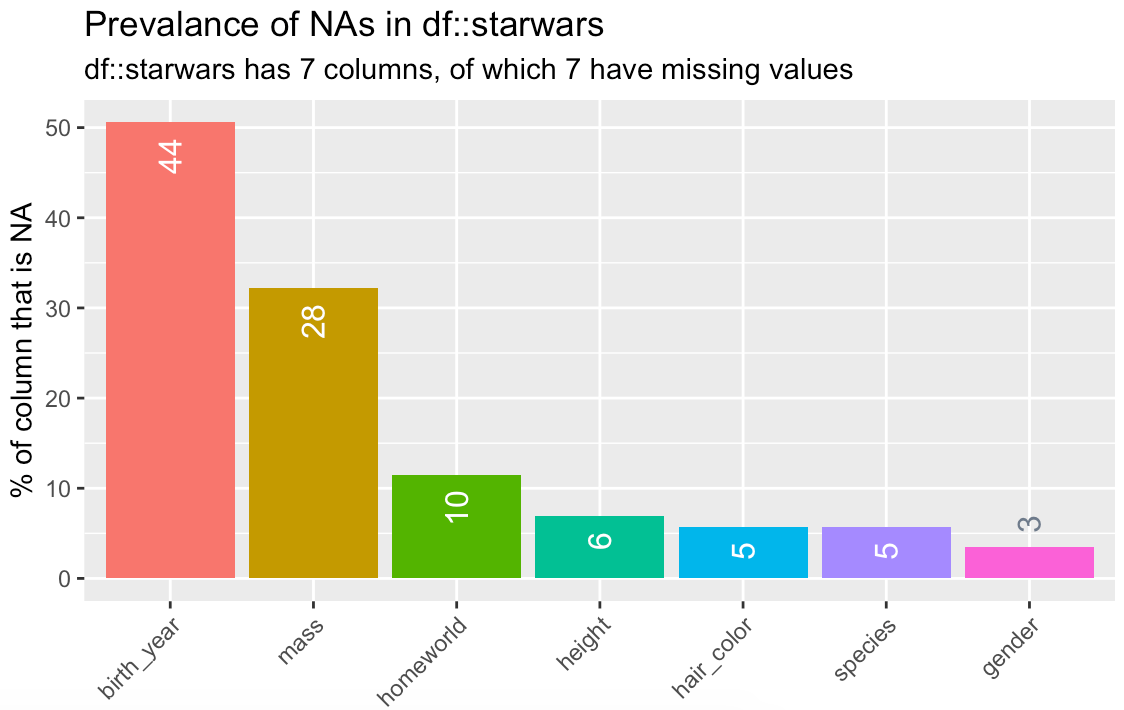
library(inspectdf)starwars %>% inspect_na() %>% filter(cnt != 0)starwars %>% inspect_na() %>% filter(cnt != 0) %>% show_plot
4 应用案例
新建一个贷款合同报表。
contract <- tibble(姓名 = c('张三', '李四', '王五'),年龄 = c(41, NA, 35),学历 = c(NA, '本科', '硕士'),省份 = c('湖北省', '江苏省', '新疆维吾尔族自治区'),日期 = c('20190101', '20190223', '20190518'),首付比例 = c(0.3, NA, 0.4),期限 = c(12.00, 24.00, 36.00),贷款金额 = c(50000, 60000, 70000),车型 = c('Q3', NA, 'Q7'),合同编号 = c('N1', 'N2', 'N3'))contract %>% View()

利用自定义的na.test函数查找含缺失值的列字段名。
contract %>% na.test

发现年龄、学历、首付、车型 4 个字段中存在缺失值。
# 年龄缺失值以平均年龄替换contract$年龄 %<>% replace_na(mean(ct$年龄, na.rm = TRUE))# 学历缺失值以“其他”替换ct$学历 %<>% replace_na('其他')# “0”首付产品比例缺失,替换为 0contract$首付比例 %<>% replace_na(0)# 查询原始表信息,发现合同编号 N2 对应的车型为 Q5contract %>% filter(is.na(车型)) %>% select(合同编号)# 将合同编号为N2的合同对应的缺失车型重编码为 Q5contract$车型[ct$合同编号 == 'N2'] <- 'Q5'

若有收获,就点个赞吧
0 人点赞
